LiveCodeBench
1.0.0
该论文的官方存储库“ livecodebench:大型语言模型的整体和污染免费评估”
?主页•数据•?排行榜
LiveCodeBench提供了LLMS的编码功能的整体和无污染评估。特别是,LiveCodebench不断从三个竞争平台(Leetcode,atcoder和codeforces)的比赛中不断收集新问题。接下来,LiveCodeBench还专注于更广泛的代码相关功能,例如自我修复,代码执行和测试输出预测,而不是代码生成。目前,LiveCodebench在2023年5月至2024年3月之间发表了四百个高质量的编码问题。
您可以使用以下命令克隆存储库:
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBench我们建议使用诗歌来管理依赖关系。您可以使用以下命令安装诗歌和依赖项:
pip install poetry
poetry install默认设置不安装vllm 。要安装vllm ,您可以使用:
poetry install --with with-gpu我们为不同的代码功能方案提供基准
由于LiveCodeBench是一个不断更新的基准,因此我们提供了数据集的不同版本。特别是,我们提供数据集的以下版本:
release_v1 :数据集的初始版本,其中包含400个问题的2023年5月至2024年3月之间发布的问题。release_v2 :数据集的更新版本,其中包含511个问题的2023年5月至2024年5月之间发布的问题。release_v3 :数据集的更新版本,其中包含612个问题的2023年5月至2024年7月之间发布的问题。release_v4 :数据集的更新版本,其中包含713个问题的2023年5月至2024年9月之间发布的问题。您可以使用--release_version标志来指定要使用的数据集版本。特别是,您可以使用以下命令在release_v2数据集上运行评估。发行版本默认为release_latest 。
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2我们使用vllm使用开放模型进行推断。默认情况下,我们使用tensor_parallel_size=${num_gpus}在所有可用的GPU上并行推理。可以根据需要使用--tensor_parallel_size标志进行配置。
要运行推理,请根据./lcb_runner/lm_styles.py文件提供model_name 。场景(此处codegeneration )可用于指定模型的方案。
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration此外,可以使用--use_cache标志来缓存生成的输出, --continue_existing标志可用于使用现有的转储结果。如果您希望从本地路径使用模型,则可以提供模型路径的--local_model_path标志。我们使用n=10 , temperature=0.2进行生成。请检查./lcb_runner/runner/parser.py文件以获取有关标志的更多详细信息。
对于封闭的API模型,可以使用--multiprocess Flag将查询与API服务器并行化(可根据速率限制调节)。
我们计算pass@1 ,并pass@5指标进行模型评估。我们使用使用apps基准发布的Checker的修改版本来计算指标。特别是,我们确定了原始检查器中的一些未经处理的边缘案例,并根据收集的数据集修复了检查器,并简化了检查器。要运行评估,您可以添加--evaluate标志:
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate请注意,时间限制可能会导致pass@1和pass@5指标的通行证计算中的轻微( < 0.5 )点。如果您观察到性能的显着差异,请将--num_process_evaluate标志调整为较低的值或增加--timeout标志。请在此处报告由于超时不当而引起的特定问题。
最后,要获得不同时间窗口的分数,您可以使用./lcb_runner/evaluation/compute_scores.py文件。特别是,您可以提供--start_date和--end_date标志(使用YYYY-MM-DD格式)以在指定的时间窗口上获得分数。在我们的论文中,为了应对DeepSeek模型的污染,我们仅报告2023年8月以后发布的问题的结果。您可以使用以下方式复制这些评估。
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01注意:我们已经从原始基准测试了大量测试用例,并创建了code_generation_lite ,该测试用例设置为默认基准标准,可更快地提供相似的性能估计。如果您想使用原始基准测试,请使用--not_fast标志。我们正在使用此更新设置更新排行榜分数。
注意:V2更新:要运行更新LiveCodeBench,请使用--release_version release_v2 。此外,如果您具有release_v1的现有结果,则可以添加--continue_existing或更好--continue_existing_with_eval flags以分别重复使用旧的完成或评估。
为了进行自我维修,您需要提供一个额外的--codegen_n标志,该标志映射到代码生成过程中生成的代码数量。此外, --temperature标志用于解决必须在output目录中存在的旧代码生成评估文件。
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supported如果您在基准的较小子集或版本上具有结果,则可以使用--continue_existing和--continue_existing_with_eval flags重复使用旧计算。特别是,您可以运行以下命令以从现有生成的解决方案中继续。
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existing请注意,这只会重复使用生成的样本和重新评估。要重复使用旧评估,您可以添加--continue_existing_with_eval标志。
对于运行测试输出预测方案,您可以简单地运行
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluate对于运行测试输出预测方案,您可以简单地运行
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluate此外,我们支持COT设置
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluate另外,您可以使用lcb_runner/runner/custom_evaluator.py直接评估自定义文件中的模型世代。该文件应包含一个模型输出列表,该列表以基准问题的顺序进行标准的格式进行评估。
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}特别是以以下格式排列输出
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]为了增加对新模型的支持,我们已经实施了一个可扩展的框架来添加新模型并自定义提示。
步骤1:将新模型添加到./lcb_runner/lm_styles.py文件中。特别是,扩展LMStyle类以添加新的模型家族并将模型扩展到LanguageModelList阵列。
步骤2:由于我们使用指令调整模型,因此我们允许为每个模型配置指令。修改./lcb_runner/prompts/generation.py文件以在format_prompt_generation函数中为模型添加新提示。例如, DeepSeekCodeInstruct模型系列的提示如下
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt 要将模型提交给排行榜,您可以填写此表格。您将需要填写模型详细信息,并为生成的评估文件提供模型世代,并通过@1分。我们将审查提交并相应地将模型添加到排行榜中。
我们在errata.md文件中维护已知问题和更新的列表。特别是,我们记录了有关错误测试和不适合自动化的问题的问题。当我们更新LiveCodeBench时,我们一直在使用此反馈来改善问题选择启发式方法。
LiveCodeBench可用于评估不同时间播放的LLM的性能(使用问题发布日期来过滤模型)。因此,我们可以在评估过程中检测和防止潜在的污染,并在新问题上评估LLM。
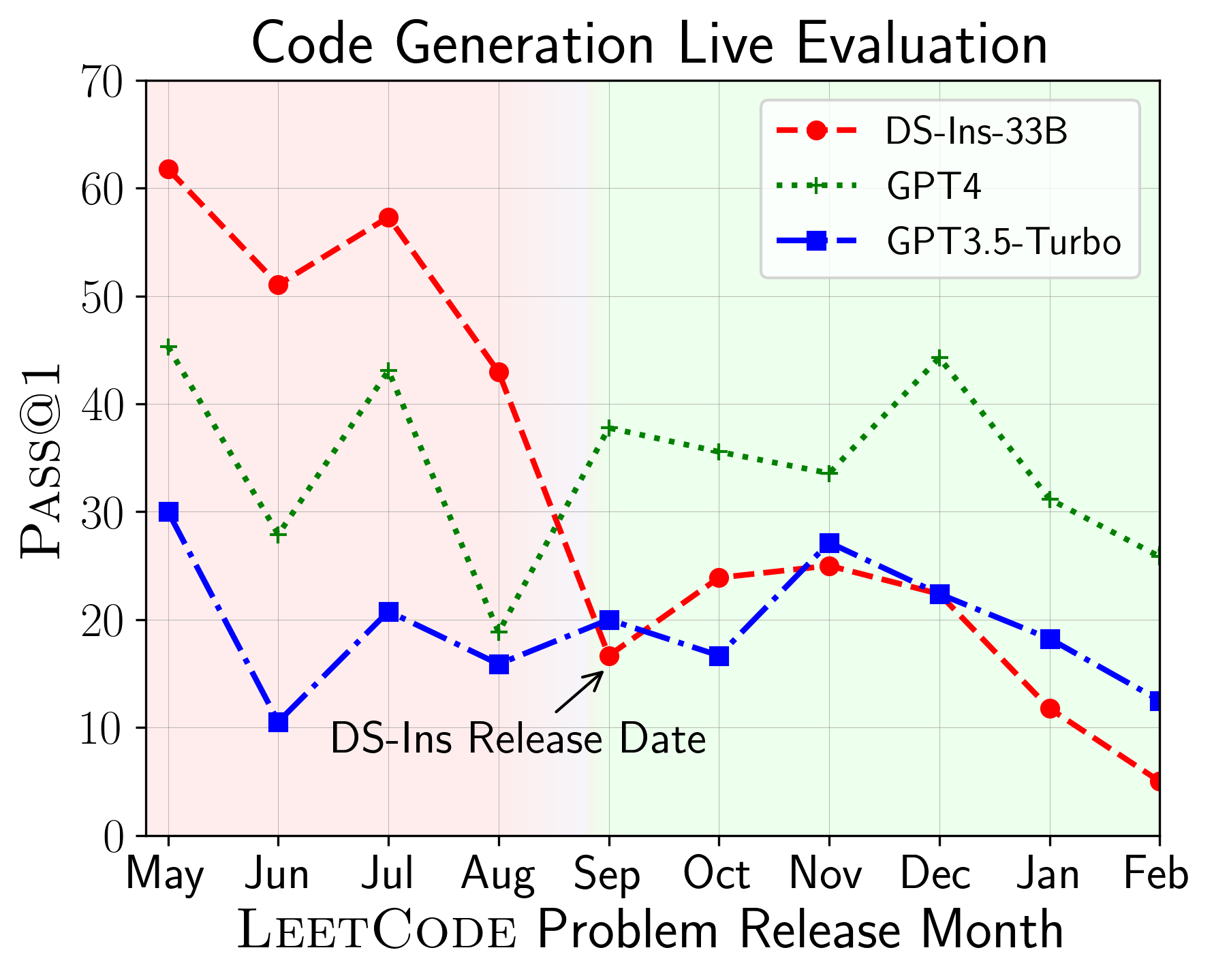
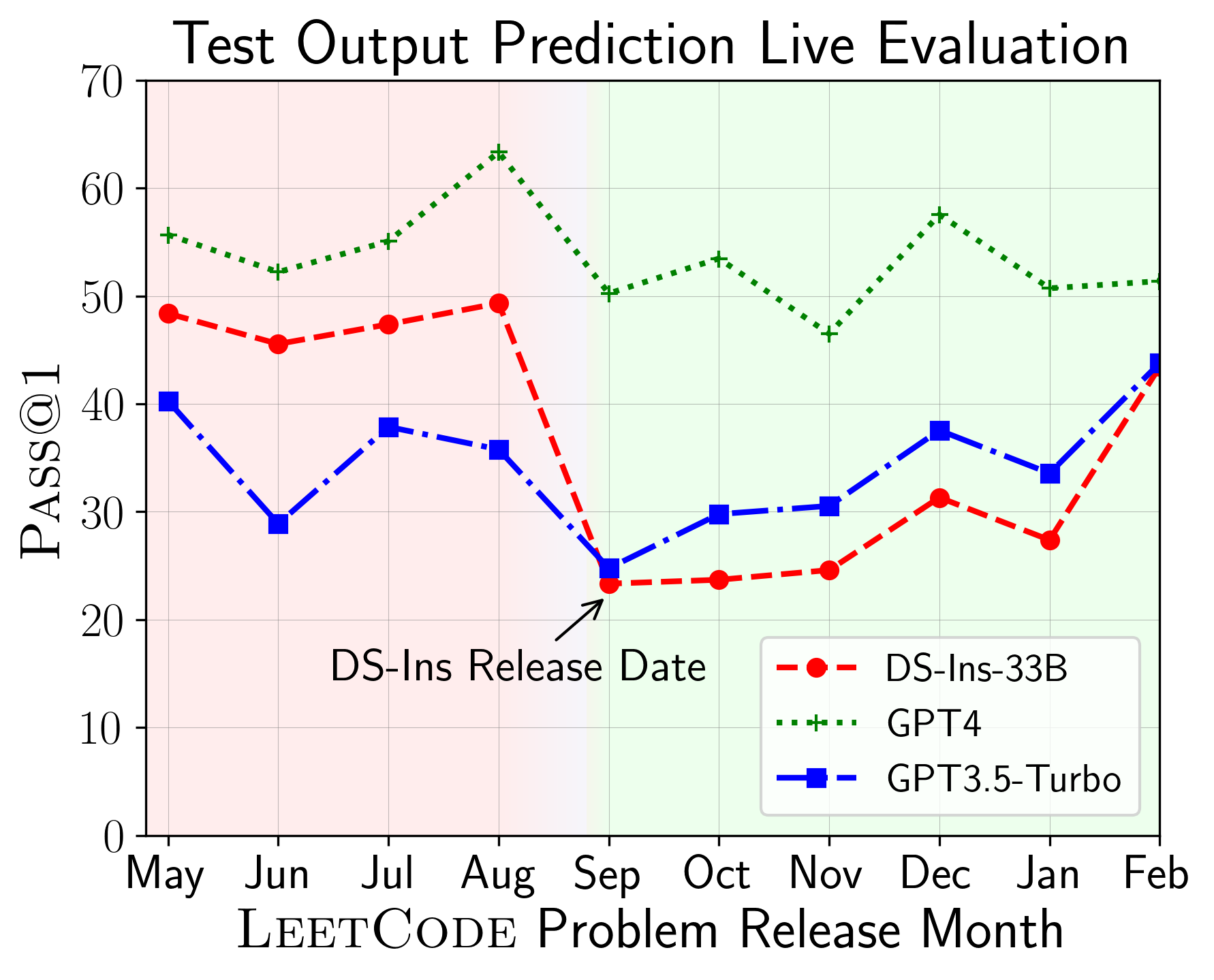
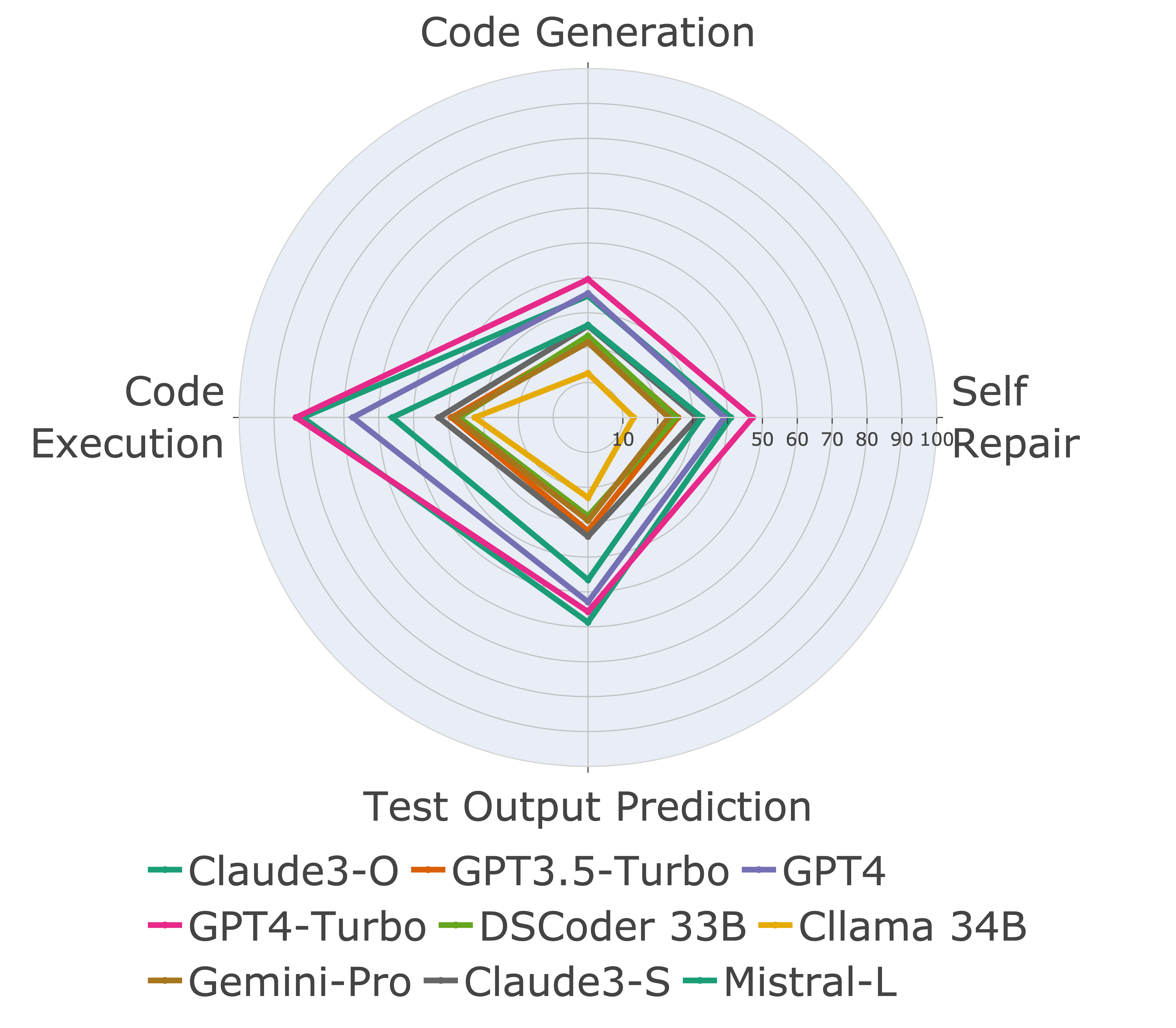
接下来,我们对不同代码功能进行评估模型,并发现模型的相对性能确实在任务上发生了变化(左)。因此,它强调了对代码LLM的整体评估的需求。
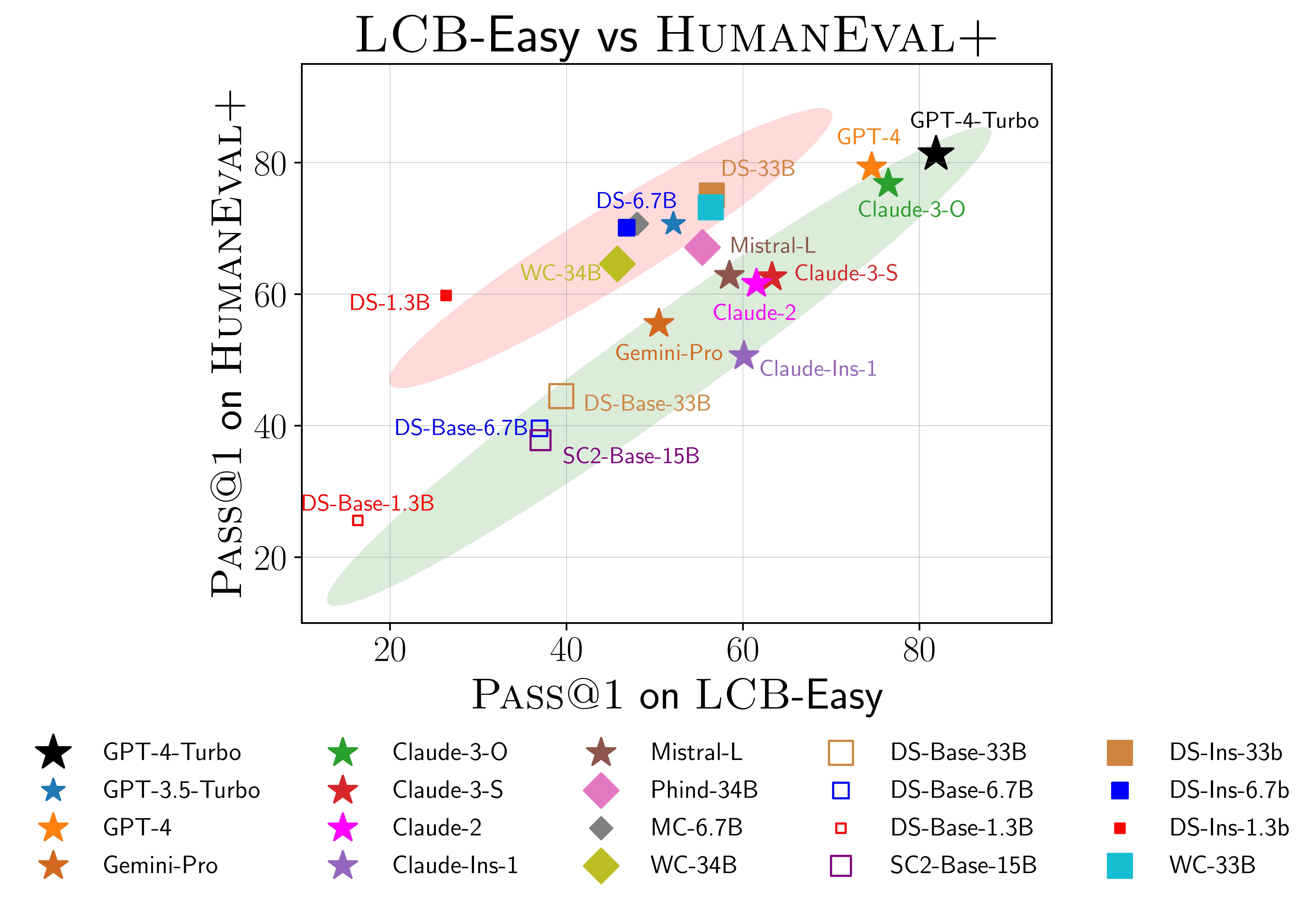
我们还发现证据表明人类事件(Righaneval)可能过度拟合(右)。特别是,在人类事件上表现良好的模型不一定在livecodebench上表现良好。在上面的散点图中,我们发现模型被聚集成两组,以红色和绿色为阴影。红色组包含在人类事件上表现良好但在livecodebench上表现不佳的模型,而绿色组则包含在两者效果良好的模型。
有关更多详细信息,请参阅我们的网站livecodebench.github.io。
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

