LiveCodeBench
1.0.0
Repositori resmi untuk makalah "LiveCodebench: Evaluasi Holistik dan Kontaminasi Gratis dari Model Bahasa Besar untuk Kode"
? Halaman Beranda • Data •? Papan peringkat
LiveCodeBench memberikan evaluasi holistik dan kontaminasi bebas dari kemampuan pengkodean LLMS. Khususnya, LiveCodebench terus -menerus mengumpulkan masalah baru dari waktu ke waktu dari kontes di tiga platform kompetisi - LeetCode, Atcoder, dan Codeforces. Selanjutnya, LiveCodeBench juga berfokus pada kisaran kemampuan terkait kode yang lebih luas, seperti perbaikan diri, eksekusi kode, dan prediksi output tes, di luar pembuatan kode yang adil. Saat ini, Livecodebench menyelenggarakan empat ratus masalah pengkodean berkualitas tinggi yang diterbitkan antara Mei 2023 dan Maret 2024.
Anda dapat mengkloning repositori menggunakan perintah berikut:
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBenchKami merekomendasikan penggunaan puisi untuk mengelola dependensi. Anda dapat menginstal puisi dan dependensi menggunakan perintah berikut:
pip install poetry
poetry install Pengaturan default tidak menginstal vllm . Untuk menginstal vllm juga Anda dapat menggunakan:
poetry install --with with-gpuKami memberikan tolok ukur untuk skenario kemampuan kode yang berbeda
Karena LiveCodebench adalah tolok ukur yang terus diperbarui, kami menyediakan versi dataset yang berbeda. Khususnya, kami menyediakan versi dataset berikut:
release_v1 : Rilis awal dataset dengan masalah yang dirilis antara Mei 2023 dan Mar 2024 yang berisi 400 masalah.release_v2 : Rilis dataset yang diperbarui dengan masalah yang dirilis antara Mei 2023 dan Mei 2024 berisi 511 masalah.release_v3 : Rilis yang diperbarui dari dataset dengan masalah yang dirilis antara Mei 2023 dan Jul 2024 yang berisi 612 masalah.release_v4 : Rilis dataset yang diperbarui dengan masalah yang dirilis antara Mei 2023 dan Sep 2024 yang berisi 713 masalah. Anda dapat menggunakan flag --release_version untuk menentukan versi dataset yang ingin Anda gunakan. Khususnya, Anda dapat menggunakan perintah berikut untuk menjalankan evaluasi pada dataset release_v2 . Rilis versi default ke release_latest .
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2 Kami menggunakan vllm untuk inferensi menggunakan model terbuka. Secara default, kami menggunakan tensor_parallel_size=${num_gpus} untuk memparalelkan inferensi di semua GPU yang tersedia. Ini dapat dikonfigurasi menggunakan flag --tensor_parallel_size sesuai kebutuhan.
Untuk menjalankan inferensi, berikan model_name berdasarkan file ./lcb_runner/lm_styles.py. Skenario (di sini codegeneration ) dapat digunakan untuk menentukan skenario untuk model.
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration Selain itu, -bendera --use_cache dapat digunakan untuk menangani output yang dihasilkan dan --continue_existing flag dapat digunakan untuk menggunakan hasil yang sudah dibuang yang ada. Jika Anda ingin menggunakan model dari jalur lokal, Anda juga dapat menyediakan --local_model_path bendera dengan jalur ke model. Kami menggunakan n=10 dan temperature=0.2 untuk generasi. Silakan periksa file ./lcb_runner/runner/parser.py untuk detail lebih lanjut tentang bendera.
Untuk model API tertutup, -Bendera --multiprocess dapat digunakan untuk memparalelkan kueri ke server API (dapat disesuaikan sesuai dengan batas laju).
Kami menghitung pass@1 dan pass@5 metrik untuk evaluasi model. Kami menggunakan versi modifikasi dari checker yang dirilis dengan Benchmark apps untuk menghitung metrik. Khususnya, kami mengidentifikasi beberapa kasus tepi yang tidak ditangani dalam pemeriksa asli dan memperbaikinya dan juga menyederhanakan pemeriksa berdasarkan dataset yang dikumpulkan. Untuk menjalankan evaluasi, Anda dapat menambahkan --evaluate bendera:
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate Perhatikan bahwa batas waktu dapat menyebabkan sedikit ( < 0.5 ) titik variasi dalam perhitungan metrik pass@1 dan pass@5 . Jika Anda mengamati variasi kinerja yang signifikan, sesuaikan flag --num_process_evaluate ke nilai yang lebih rendah atau tingkatkan bendera --timeout . Harap laporkan masalah khusus yang disebabkan oleh batas waktu yang tidak tepat di sini.
Akhirnya, untuk mendapatkan skor dari jendela waktu yang berbeda, Anda dapat menggunakan file ./lcb_runner/evaluasi/compute_scores.py. Khususnya, Anda dapat menyediakan --start_date dan --end_date flags (menggunakan format YYYY-MM-DD ) untuk mendapatkan skor di atas jendela waktu yang ditentukan. Dalam makalah kami, untuk melawan kontaminasi dalam model Deepseek, kami hanya melaporkan hasil pada masalah yang dirilis setelah Agustus 2023. Anda dapat mereplikasi evaluasi tersebut menggunakan:
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01 CATATAN: Kami telah memangkas sejumlah besar kasus uji dari tolok ukur asli dan membuat code_generation_lite yang ditetapkan sebagai patokan default yang menawarkan estimasi kinerja yang serupa jauh lebih cepat. Jika Anda ingin menggunakan tolok ukur asli, silakan gunakan flag --not_fast . Kami sedang dalam proses memperbarui skor papan peringkat dengan pengaturan yang diperbarui ini.
CATATAN: V2 UPDATE: Untuk menjalankan pembaruan livecodebench, silakan gunakan --release_version release_v2 . Selain itu, jika Anda memiliki hasil yang ada dari release_v1 Anda dapat menambahkan --continue_existing atau lebih baik --continue_existing_with_eval flags untuk menggunakan kembali penyelesaian atau evaluasi lama masing -masing.
Untuk menjalankan perbaikan diri, Anda perlu memberikan bendera --codegen_n tambahan yang memetakan jumlah kode yang dihasilkan selama pembuatan kode. Selain itu, bendera --temperature digunakan untuk menyelesaikan file eval generasi kode lama yang harus ada di direktori output .
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supported Jika Anda memiliki hasil pada subset atau versi yang lebih kecil dari tolok ukur, Anda dapat menggunakan --continue_existing dan --continue_existing_with_eval flags untuk menggunakan kembali perhitungan lama. Khususnya, Anda dapat menjalankan perintah berikut untuk melanjutkan dari solusi yang dihasilkan yang ada.
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existing Perhatikan bahwa ini hanya akan menggunakan kembali sampel yang dihasilkan dan evaluasi ulang. Untuk menggunakan kembali evaluasi lama, Anda dapat menambahkan bendera --continue_existing_with_eval .
Untuk menjalankan skenario prediksi output tes Anda cukup
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluateUntuk menjalankan skenario prediksi output tes Anda cukup
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluateSelain itu, kami mendukung pengaturan COT dengan
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluate Atau, Anda dapat menggunakan lcb_runner/runner/custom_evaluator.py untuk secara langsung mengevaluasi generasi model dalam file khusus. File harus berisi daftar output model, diformat dengan tepat untuk evaluasi dalam urutan masalah benchmark.
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}Khususnya, atur output dalam format berikut
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]Untuk menambahkan dukungan untuk model baru, kami telah menerapkan kerangka kerja yang dapat diperluas untuk menambahkan model baru dan menyesuaikan petunjuk dengan tepat.
Langkah 1: Tambahkan model baru ke file ./lcb_runner/lm_styles.py. Khususnya, memperluas kelas LMStyle untuk menambahkan keluarga model baru dan memperluas model ke array LanguageModelList .
Langkah 2: Karena kami menggunakan model yang disetel instruksi, kami memungkinkan mengonfigurasi instruksi untuk setiap model. Ubah file ./lcb_runner/promppts/generation.py untuk menambahkan prompt baru untuk model dalam fungsi format_prompt_generation . Misalnya, prompt untuk keluarga model DeepSeekCodeInstruct terlihat sebagai berikut
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt Untuk mengirimkan model ke papan peringkat, Anda dapat mengisi formulir ini. Anda perlu mengisi detail model dan memberikan file evaluasi yang dihasilkan dengan generasi model dan lulus skor@1. Kami akan meninjau pengajuan dan menambahkan model ke papan peringkat yang sesuai.
Kami memelihara daftar masalah dan pembaruan yang diketahui dalam file errata.md. Khususnya, kami mendokumentasikan masalah tentang tes yang keliru dan masalah yang tidak dapat dilakukan untuk autograding. Kami terus menggunakan umpan balik ini untuk meningkatkan heuristik pemilihan masalah kami saat kami memperbarui LiveCodebench.
LiveCodeBench dapat digunakan untuk mengevaluasi kinerja LLM pada windows waktu yang berbeda (menggunakan tanggal rilis masalah untuk memfilter model). Dengan demikian kita dapat mendeteksi dan mencegah kontaminasi potensial dalam proses evaluasi dan mengevaluasi LLM pada masalah baru .
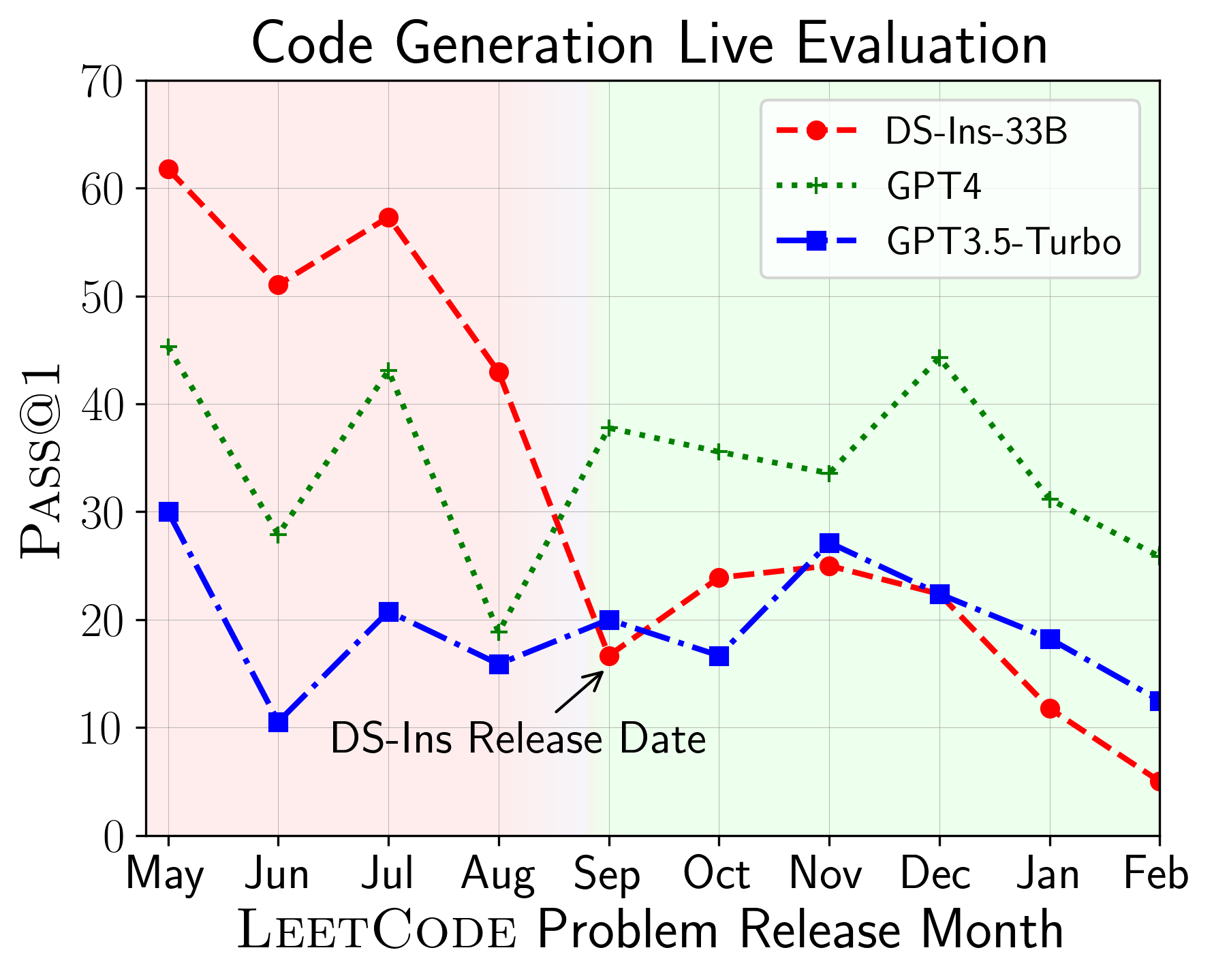
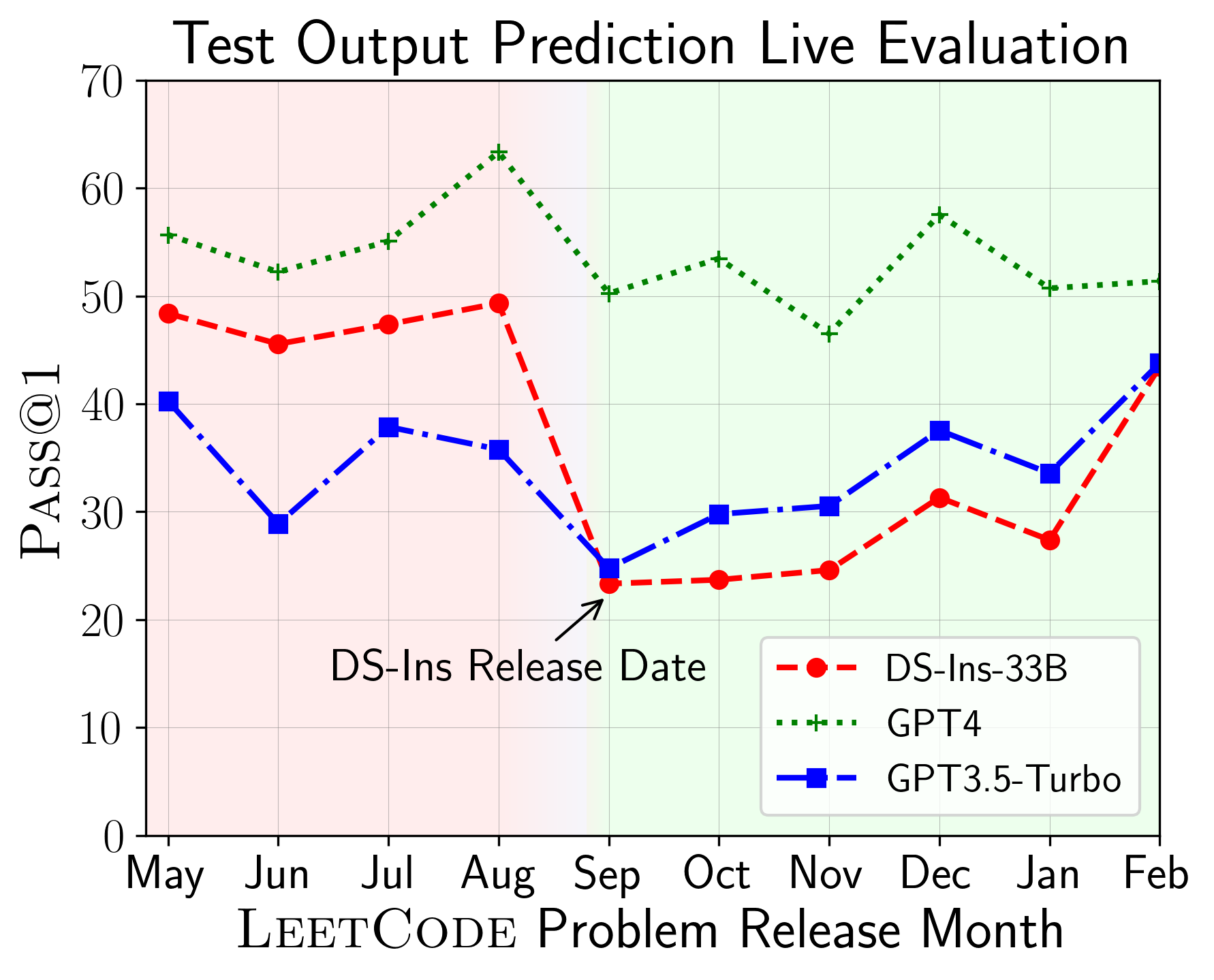
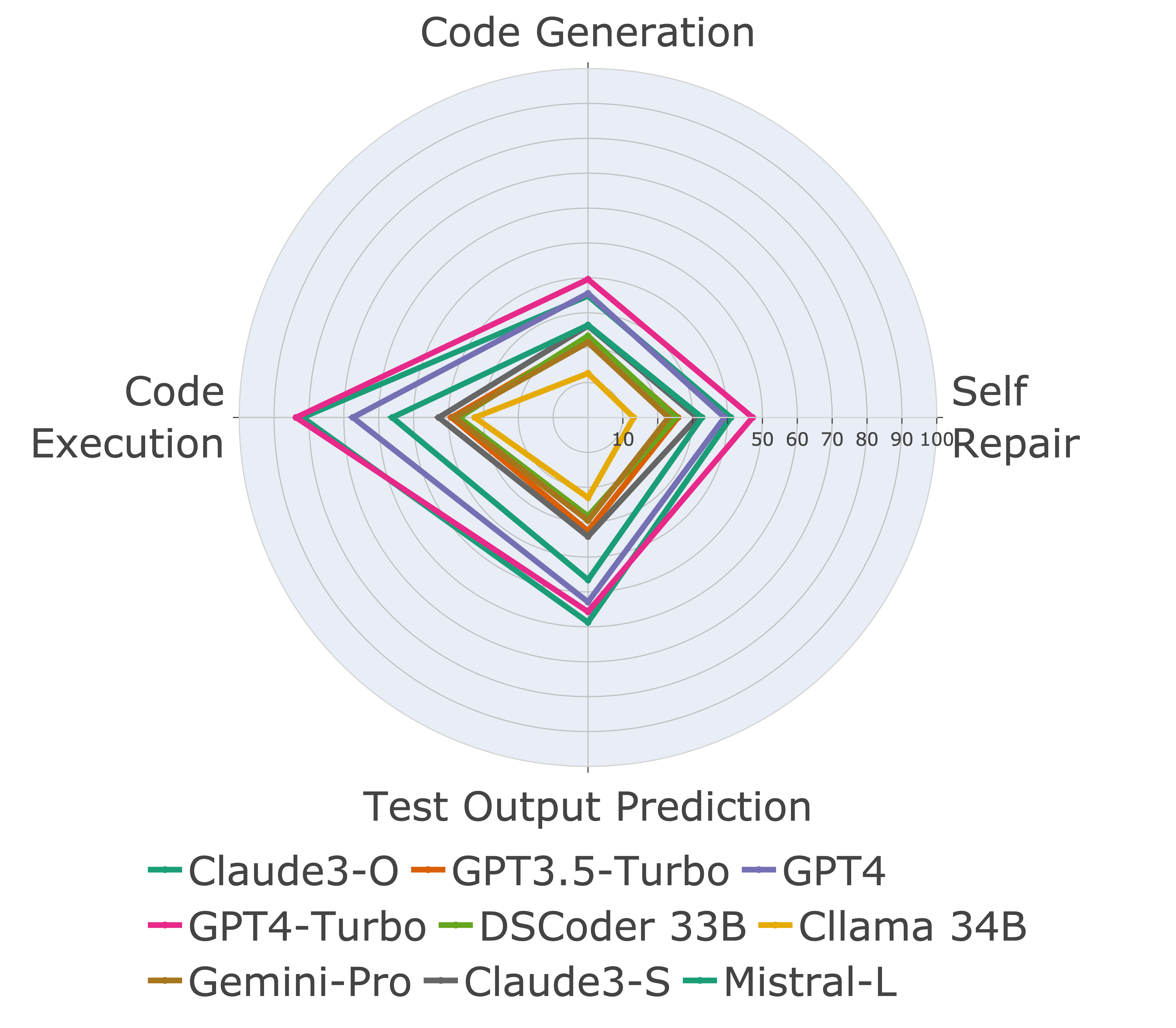
Selanjutnya, kami mengevaluasi model pada kemampuan kode yang berbeda dan menemukan bahwa kinerja relatif model memang berubah dari tugas (kiri). Dengan demikian, ini menyoroti perlunya evaluasi holistik LLMS untuk kode.
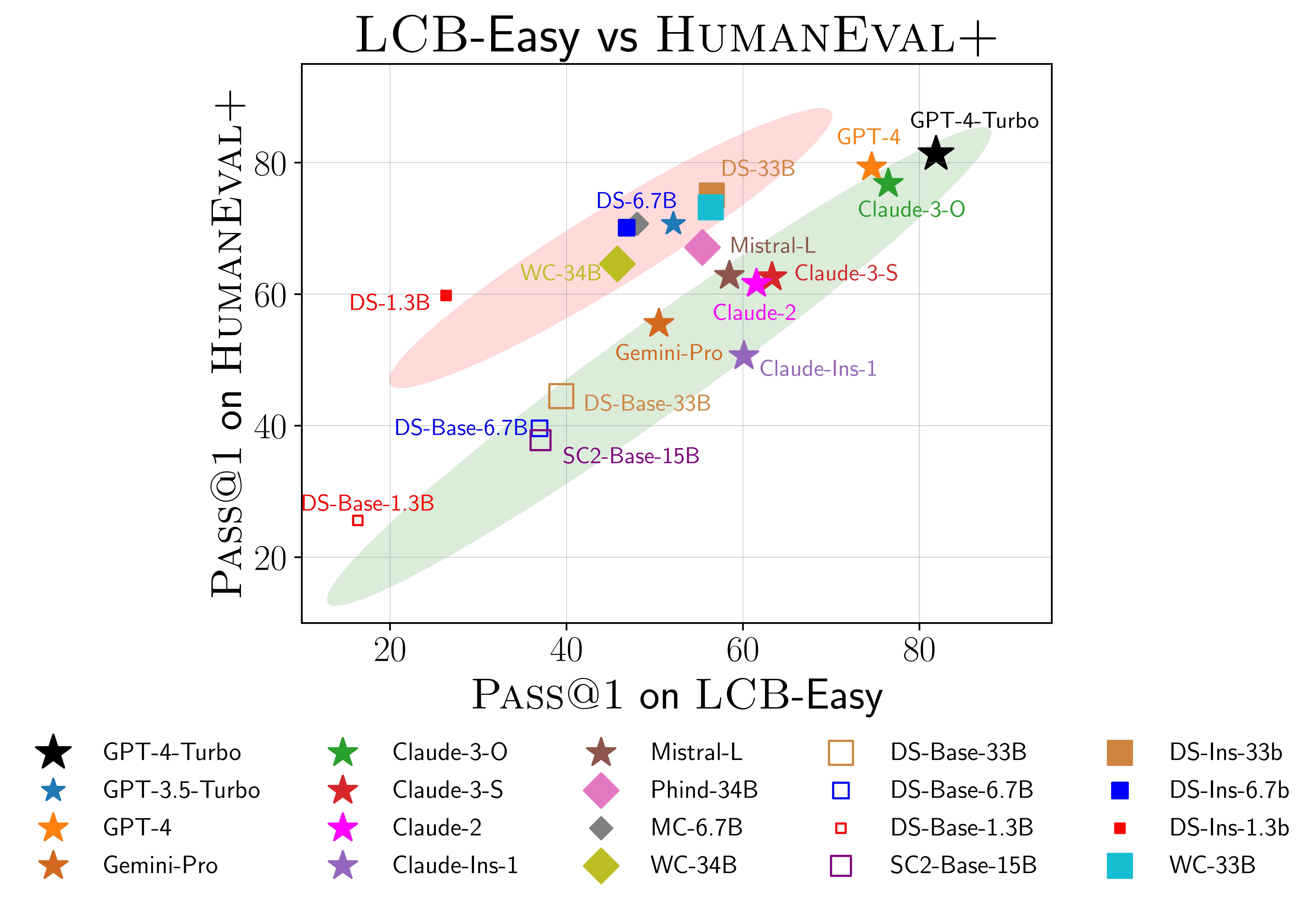
Kami juga menemukan bukti kemungkinan overfitting pada manusia (kanan). Khususnya, model yang berkinerja baik pada humaneval tidak selalu berkinerja baik di LiveCodebench. Di scatterplot di atas, kami menemukan model dikelompokkan menjadi dua kelompok, diarsir dengan warna merah dan hijau. Kelompok merah berisi model yang berkinerja baik pada manusia selama tetapi buruk pada LiveCodebench, sedangkan kelompok hijau berisi model yang berkinerja baik pada keduanya.
Untuk detail lebih lanjut, silakan merujuk ke situs web kami di livecodebench.github.io.
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

