LiveCodeBench
1.0.0
論文の公式リポジトリ「livecodebench:ホリスティックおよび汚染コードの大規模な言語モデルの無料評価」
?ホームページ•データ•?リーダーボード
LiveCodebenchは、LLMのコーディング機能の全体的および汚染のない評価を提供します。特に、LiveCodebenchは、LeetCode、Atcoder、Codeforcesの3つの競争プラットフォームにわたるコンテストから、時間の経過とともに新しい問題を継続的に収集します。次に、LiveCodebenchは、単なるコード生成を超えて、自己修復、コード実行、テスト出力予測など、より広範なコード関連の機能にも焦点を当てています。現在、LiveCodebenchは、2023年5月から2024年3月に発行された400の高品質のコーディング問題をホストしています。
次のコマンドを使用して、リポジトリをクローンできます。
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBench依存関係を管理するために詩を使用することをお勧めします。次のコマンドを使用して、詩と依存関係をインストールできます。
pip install poetry
poetry installデフォルトのセットアップはvllmをインストールしません。 vllmもインストールするには、使用できます。
poetry install --with with-gpuさまざまなコード機能シナリオのベンチマークを提供します
LiveCodebenchは継続的に更新されたベンチマークであるため、データセットのさまざまなバージョンを提供します。特に、データセットの次のバージョンを提供します。
release_v1 :2023年5月から2024年3月の間にリリースされた問題を伴うデータセットの最初のリリースには、400の問題が含まれています。release_v2 :2023年5月から2024年5月の間にリリースされた問題を伴うデータセットの更新されたリリースは、511の問題を含みます。release_v3 :2023年5月から2024年7月までにリリースされた問題を伴うデータセットの更新されたリリースは、612の問題を含みます。release_v4 :2023年5月から2024年9月までにリリースされた問題を伴うデータセットの更新されたリリースは、713の問題を含みます。 --release_versionフラグを使用して、使用するデータセットバージョンを指定できます。特に、次のコマンドを使用して、 release_v2データセットで評価を実行できます。リリースバージョンはデフォルトでrelease_latestになります。
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2オープンモデルを使用した推論にはvllmを使用します。デフォルトでは、 tensor_parallel_size=${num_gpus}を使用して、利用可能なすべてのGPUにわたって推論を並列化します。必要に応じて、 --tensor_parallel_sizeフラグを使用して構成できます。
推論を実行するには、./lcb_runner/lm_styles.pyファイルに基づいてmodel_nameを提供してください。シナリオ(こちらのcodegeneration )を使用して、モデルのシナリオを指定できます。
python -m lcb_runner.runner.main --model {model_name} --scenario codegenerationさらに、 --use_cacheフラグを使用して生成された出力をキャッシュでき、 --continue_existingフラグを使用して既存のダンプ結果を使用できます。ローカルパスからモデルを使用したい場合は、さらに--local_model_pathフラグをモデルへのパスに提供できます。生成にはn=10 、 temperature=0.2を使用します。フラグの詳細については、./lcb_runner/runner/parser.pyファイルを確認してください。
閉じたAPIモデルの場合、 --multiprocessフラグを使用して、クエリをAPIサーバーに並列化できます(レート制限に応じて調整可能)。
モデル評価のためにpass@1とpass@5メトリックを計算します。 appsベンチマークでリリースされたチェッカーの変更されたバージョンを使用して、メトリックを計算します。特に、元のチェッカーで未処理のエッジケースを特定し、それらを修正し、収集したデータセットに基づいてチェッカーをさらに簡素化しました。評価を実行するには、 --evaluateフラグを追加できます。
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate時間制限は、 pass@1およびpass@5メトリックの計算にわずかな( < 0.5 )ポイントの変動を引き起こす可能性があることに注意してください。パフォーマンスに大きな変動がある場合は、 --num_process_evaluateフラグをより低い値に調整するか、 --timeoutフラグを増やします。ここで不適切なタイムアウトによって引き起こされた特定の問題を報告してください。
最後に、さまざまな時間Windowsでスコアを取得するには、./lcb_runner/evaluation/compute_scores.pyファイルを使用できます。特に、 --start_dateおよび--end_dateフラグ( YYYY-MM-DD形式を使用)を提供して、指定されたタイムウィンドウでスコアを取得できます。私たちの論文では、DeepSeekモデルの汚染に対抗するために、2023年8月以降に発表された問題の結果のみを報告します。これらの評価を次のように再現できます。
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01注:元のベンチマークから多数のテストケースをプルーニングし、 code_generation_liteを作成しました。これは、同様のパフォーマンスの推定をより速く提供するデフォルトのベンチマークとして設定されています。元のベンチマークを使用する場合は、 --not_fastフラグを使用してください。この更新された設定でリーダーボードスコアを更新する過程にあります。
注:V2アップデート:更新を実行するには、LiveCodeBenchを使用してください--release_version release_v2使用してください。さらに、 release_v1の既存の結果がある場合は、 --continue_existingまたはより良い--continue_existing_with_evalフラグを追加して、それぞれ古い完成または評価を再利用できます。
自己修理を実行するには、コード生成中に生成されたコードの数にマップする追加の--codegen_nフラグを提供する必要があります。さらに、 --temperatureフラグは、 outputディレクトリに存在する必要がある古いコード生成評価ファイルを解決するために使用されます。
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supportedより小さなサブセットまたはベンチマークのバージョンで結果が得られた場合、古い計算を再利用するには、 --continue_existing and --continue_existing_with_evalフラグを使用できます。特に、次のコマンドを実行して、既存の生成されたソリューションから続行できます。
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existingこれは、生成されたサンプルと再実行評価のみを再利用することに注意してください。古い評価を再利用するには、 --continue_existing_with_evalフラグを追加できます。
テスト出力予測シナリオを実行するには、単純に実行できます
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluateテスト出力予測シナリオを実行するには、単純に実行できます
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluateさらに、コット設定をサポートします
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluateまたは、 lcb_runner/runner/custom_evaluator.pyを使用して、カスタムファイルでモデル世代を直接評価することができます。ファイルには、ベンチマークの問題の順序で評価のために適用されるモデル出力のリストを含める必要があります。
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}特に、出力を次の形式で配置します
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]新しいモデルのサポートを追加するために、新しいモデルを追加し、プロンプトを適切にカスタマイズするための拡張可能なフレームワークを実装しました。
ステップ1:./lcb_runner/lm_styles.pyファイルに新しいモデルを追加します。特に、 LMStyleクラスを拡張して新しいモデルファミリを追加し、モデルをLanguageModelListアレイに拡張します。
ステップ2:命令調整モデルを使用するため、各モデルの命令を構成することができます。 ./lcb_runner/prompts/generation.pyファイルを変更して、 format_prompt_generation関数のモデルの新しいプロンプトを追加します。たとえば、モデルのDeepSeekCodeInstructファミリのプロンプトは次のように見えます
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt モデルをリーダーボードに送信するには、このフォームに記入できます。モデルの詳細に記入し、生成された評価ファイルをモデル世代を提供し、@1スコアを渡す必要があります。提出物を確認し、それに応じてモデルをリーダーボードに追加します。
errata.mdファイルに既知の問題と更新のリストを維持します。特に、誤ったテストと自動化に適していない問題に関する問題を文書化します。 LiveCodebenchを更新する際に、このフィードバックを常に使用して問題の選択ヒューリスティックを改善しています。
LiveCodebenchを使用して、異なる時間巻きでLLMのパフォーマンスを評価できます(問題のリリース日を使用してモデルをフィルタリングします)。したがって、評価プロセスで潜在的な汚染を検出および防止し、新しい問題についてLLMを評価できます。
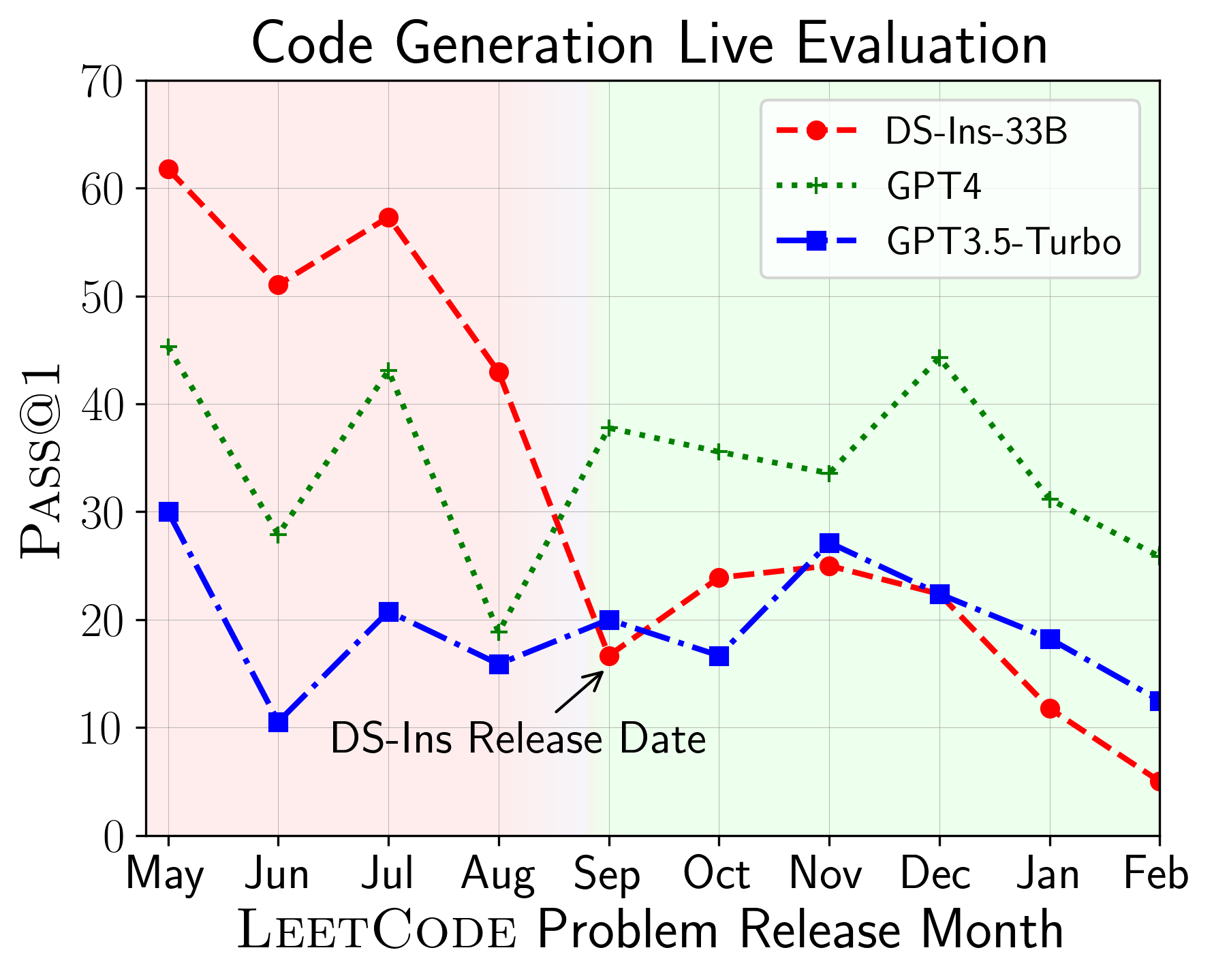
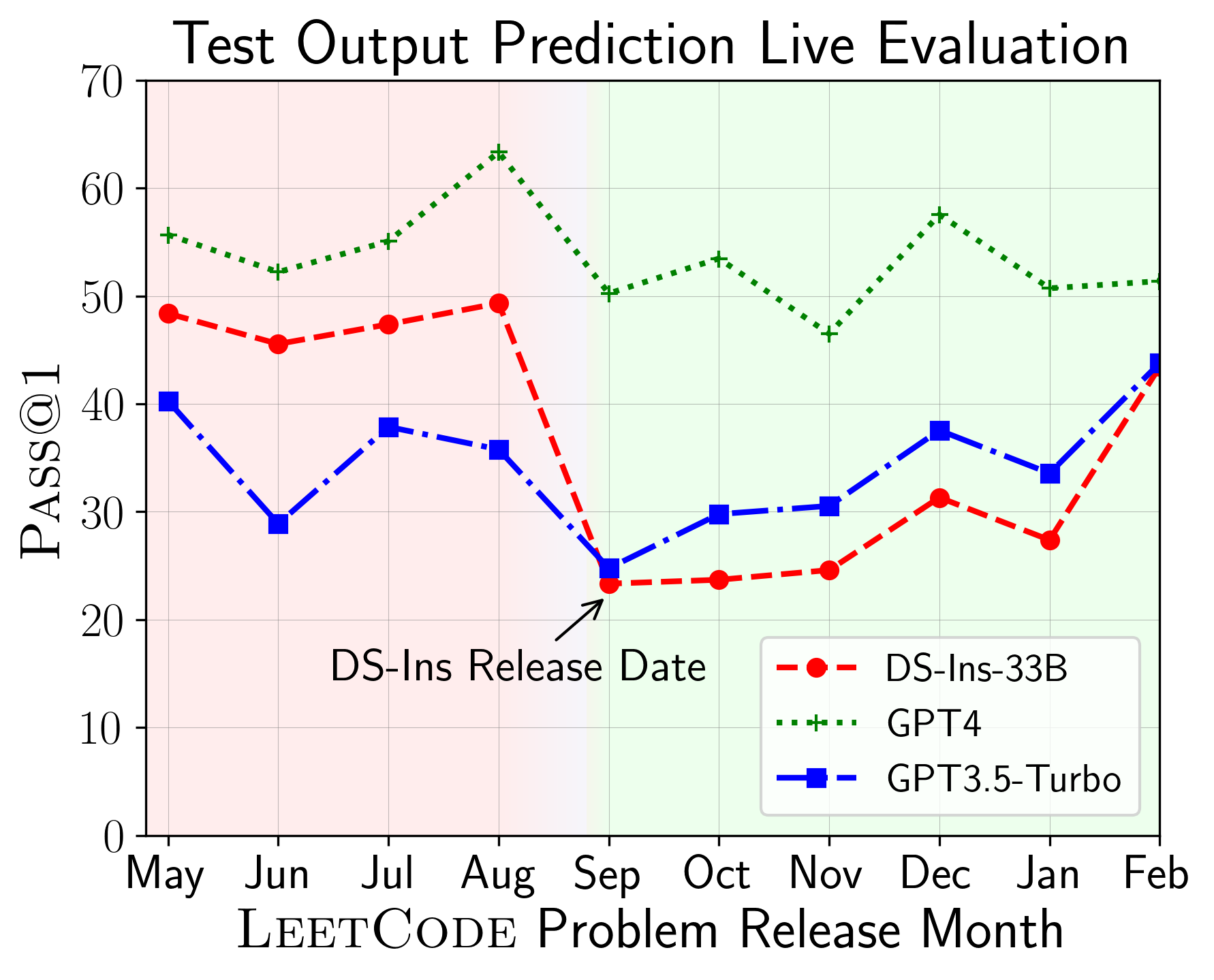
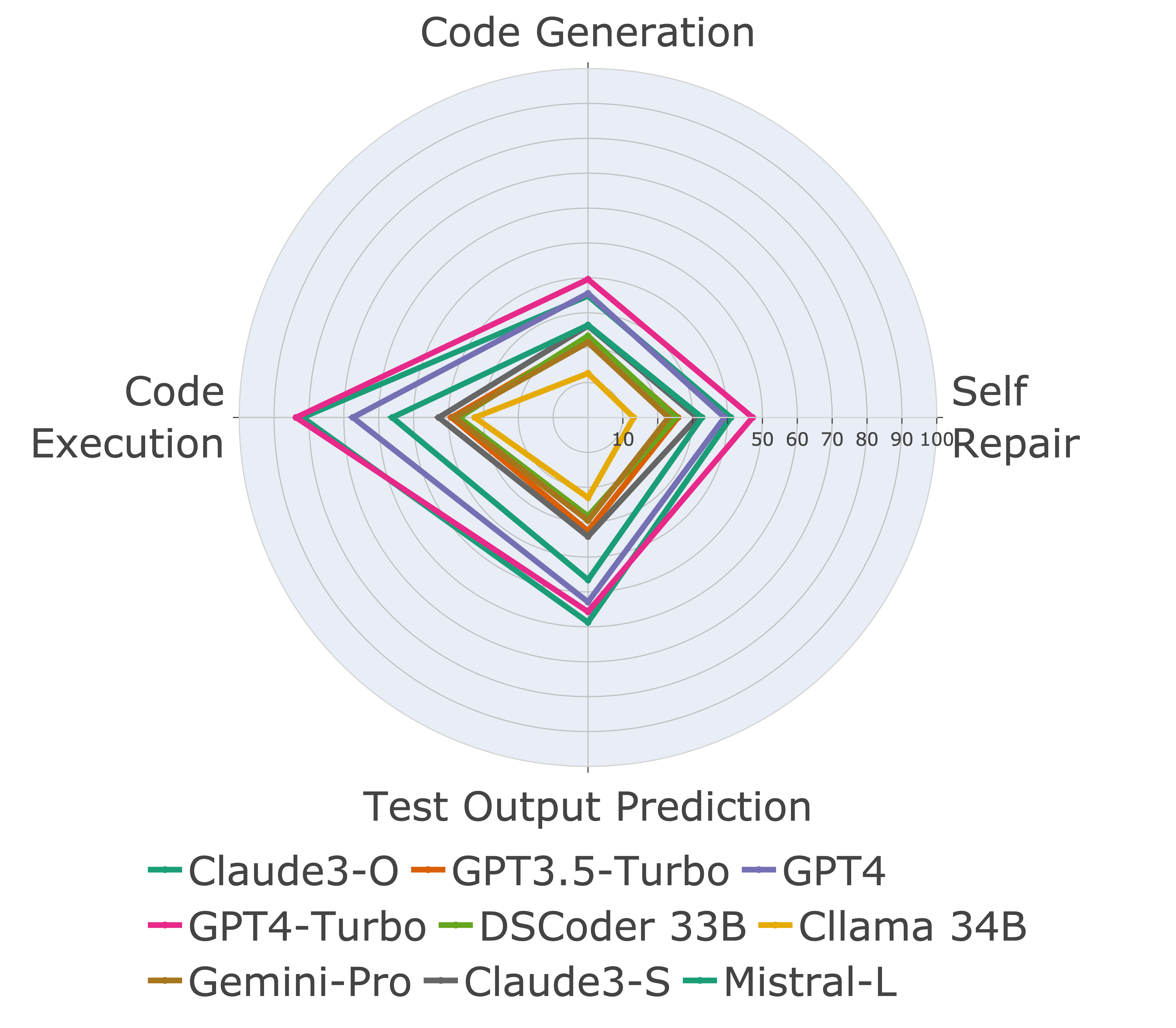
次に、さまざまなコード機能のモデルを評価し、モデルの相対的なパフォーマンスがタスクで変化することがわかります(左)。したがって、コードに対するLLMの全体的な評価の必要性を強調します。
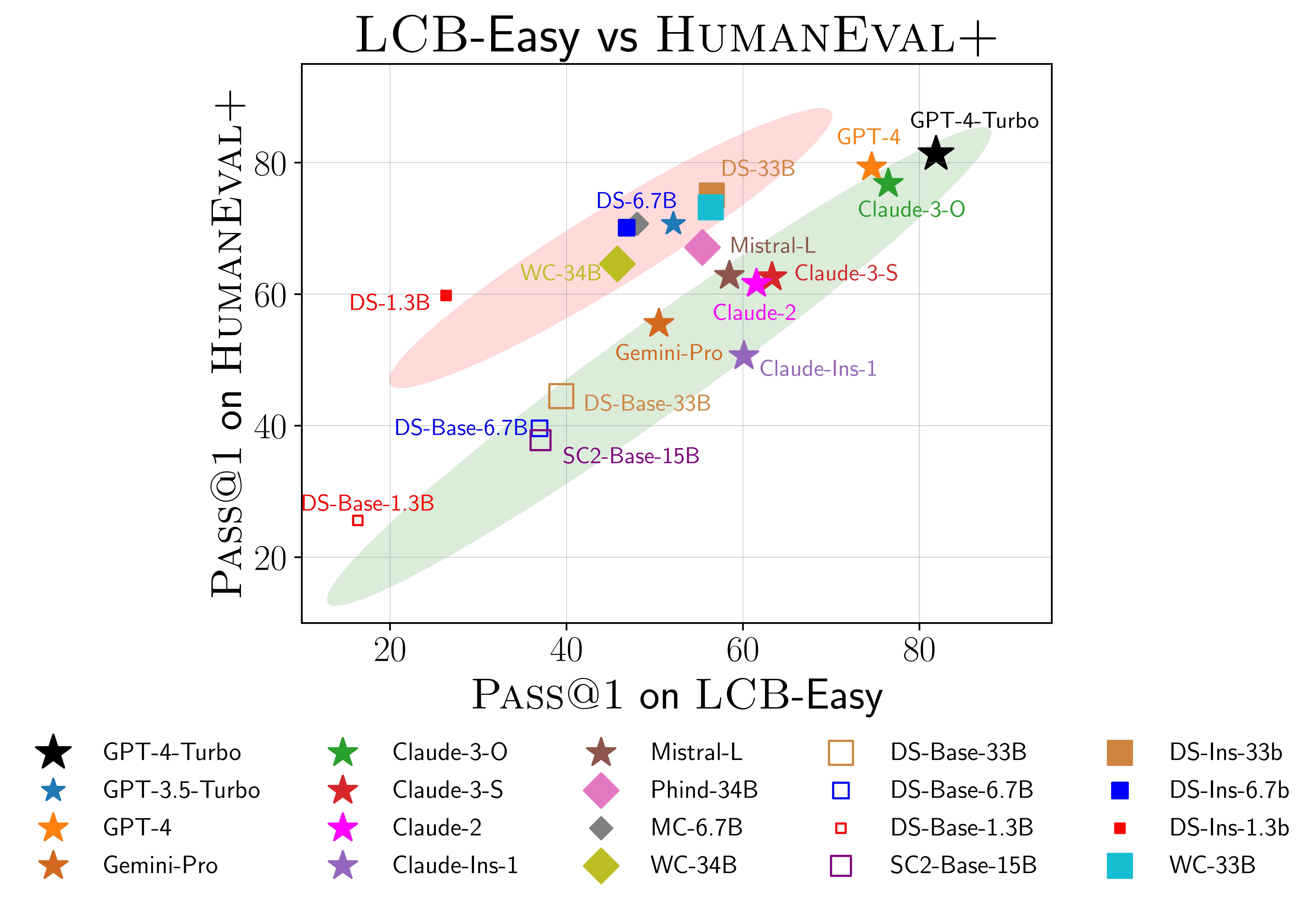
また、Humaneval(右)に過剰適合の可能性の証拠も見つかります。特に、Humanevalでうまく機能するモデルは、必ずしもLiveCodebenchでうまく機能するわけではありません。上記の散布図では、モデルが赤と緑で覆われた2つのグループにクラスター化されることがわかります。赤いグループには、ヒューマンルートでうまく機能するが、livecodebenchでは不十分なモデルが含まれていますが、緑色のグループには両方でうまく機能するモデルが含まれています。
詳細については、当社のWebサイトlivecodebench.github.ioを参照してください。
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

