LiveCodeBench
1.0.0
Référentiel officiel pour l'article "LivecodeBench: Holistique et Contamination Évaluation gratuite des modèles de gros langues pour le code"
? Page d'accueil • Données •? Classement
LivecodeBench fournit une évaluation holistique et sans contamination des capacités de codage des LLM. En particulier, LivecodeBench recueille en permanence de nouveaux problèmes au fil du temps à partir de concours sur trois plates-formes de compétition - Leetcode, Atcoder et Codeforces. Ensuite, LiveCodeBench se concentre également sur une gamme plus large de capacités liées au code, telles que l'auto-réparation, l'exécution de code et la prédiction de sortie du test, au-delà de la génération de code. Actuellement, LivecodeBench héberge quatre cents problèmes de codage de haute qualité qui ont été publiés entre mai 2023 et mars 2024.
Vous pouvez cloner le référentiel à l'aide de la commande suivante:
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBenchNous vous recommandons d'utiliser la poésie pour gérer les dépendances. Vous pouvez installer la poésie et les dépendances en utilisant les commandes suivantes:
pip install poetry
poetry install La configuration par défaut n'installe pas vllm . Pour installer vllm également que vous pouvez utiliser:
poetry install --with with-gpuNous fournissons une référence pour différents scénarios de capacité de code
Étant donné que LiveCodeBench est une référence à mise à jour continue, nous fournissons différentes versions de l'ensemble de données. En particulier, nous fournissons les versions suivantes de l'ensemble de données:
release_v1 : la version initiale de l'ensemble de données avec des problèmes publiés entre mai 2023 et mars 2024 contenant 400 problèmes.release_v2 : la version mise à jour de l'ensemble de données avec des problèmes publiés entre mai 2023 et mai 2024 contenant 511 problèmes.release_v3 : La version mise à jour de l'ensemble de données avec des problèmes publiés entre mai 2023 et juil 2024 contenant 612 problèmes.release_v4 : la version mise à jour de l'ensemble de données avec des problèmes publiés entre mai 2023 et septembre 2024 contenant 713 problèmes. Vous pouvez utiliser l'indicateur --release_version pour spécifier la version de l'ensemble de données que vous souhaitez utiliser. En particulier, vous pouvez utiliser la commande suivante pour exécuter l'évaluation de l'ensemble de données release_v2 . La version version par défaut est par défaut de release_latest .
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2 Nous utilisons vllm pour l'inférence en utilisant des modèles ouverts. Par défaut, nous utilisons tensor_parallel_size=${num_gpus} pour paralléliser l'inférence sur tous les GPU disponibles. Il peut être configuré à l'aide de l'indicateur --tensor_parallel_size selon les besoins.
Pour exécuter l'inférence, veuillez fournir le model_name basé sur le fichier ./lcb_runner/LM_STYLES.py. Le scénario (ici codegeneration ) peut être utilisé pour spécifier le scénario du modèle.
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration De plus, le drapeau --use_cache peut être utilisé pour mettre en cache les sorties générées et le drapeau --continue_existing peut être utilisé pour utiliser les résultats déversés existants. Dans le cas où vous souhaitez utiliser le modèle à partir d'un chemin local, vous pouvez en outre fournir un drapeau --local_model_path avec le chemin du modèle. Nous utilisons n=10 et temperature=0.2 pour la génération. Veuillez vérifier le fichier ./lcb_runner/runner/parser.py pour plus de détails sur les drapeaux.
Pour les modèles d'API fermés, le drapeau --multiprocess peut être utilisé pour paralléliser les requêtes aux serveurs d'API (réglable en fonction des limites de taux).
Nous calculons pass@1 et pass@5 mesures pour les évaluations de modèles. Nous utilisons une version modifiée du vérificateur publié avec la référence apps pour calculer les mesures. En particulier, nous avons identifié des cas de bord non perdus dans le vérificateur d'origine et les avons fixés et simplifié en outre le vérificateur en fonction de notre ensemble de données collecté. Pour exécuter l'évaluation, vous pouvez ajouter le drapeau --evaluate :
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate Notez que les limites de temps peuvent provoquer de légères variations ( < 0.5 ) de variation du calcul du pass@1 et pass@5 mesures. Si vous observez une variation significative des performances, ajustez le drapeau --num_process_evaluate à une valeur inférieure ou augmentez le drapeau --timeout . Veuillez signaler des problèmes particuliers causés par des délais d'attente inappropriés ici.
Enfin, pour obtenir des scores sur différentes fenêtres de temps, vous pouvez utiliser ./LCB_RUNNER/Evaluation/Compute_Scores.py File. En particulier, vous pouvez fournir des drapeaux --start_date et --end_date (en utilisant le format YYYY-MM-DD ) pour obtenir des scores sur la fenêtre de temps spécifiée. Dans notre article, pour contrer la contamination dans les modèles Deepseek, nous rapportons les résultats uniquement sur les problèmes publiés après août 2023. Vous pouvez reproduire ces évaluations en utilisant:
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01 Remarque: Nous avons taillé un grand nombre de cas de test à partir de la référence d'origine et créé code_generation_lite qui est défini comme le benchmark par défaut offrant une estimation des performances similaire beaucoup plus rapidement. Si vous souhaitez utiliser l'indice de référence d'origine, veuillez utiliser l'indicateur --not_fast . Nous sommes en train de mettre à jour les scores de classement avec ce paramètre mis à jour.
Remarque: V2 Mise à jour: Pour exécuter la mise à jour livecodebench, veuillez utiliser --release_version release_v2 . De plus, si vous avez des résultats existants de release_v1 , vous pouvez ajouter --continue_existing ou mieux --continue_existing_with_eval pour réutiliser les anciens compléments ou évaluations respectivement.
Pour l'exécution de l'auto-réparation, vous devez fournir un indicateur --codegen_n supplémentaire qui correspond au nombre de codes générés pendant la génération de code. De plus, l'indicateur --temperature est utilisé pour résoudre l'ancien fichier de génération de code EVAL qui doit être présent dans le répertoire output .
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supported Dans le cas où vous avez des résultats sur un sous-ensemble ou une version plus petit de la référence, vous pouvez utiliser --continue_existing et --continue_existing_with_eval pour réutiliser les anciens calculs. En particulier, vous pouvez exécuter la commande suivante pour continuer à partir de solutions générées existantes.
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existing Notez que cela ne réutilisera que les échantillons générés et les évaluations de relance. Pour réutiliser les anciennes évaluations, vous pouvez ajouter le drapeau --continue_existing_with_eval .
Pour exécuter le scénario de prédiction de sortie de test, vous pouvez simplement exécuter
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluatePour exécuter le scénario de prédiction de sortie de test, vous pouvez simplement exécuter
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluateDe plus, nous soutenons le réglage du COT avec
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluate Alternativement, vous pouvez utiliser lcb_runner/runner/custom_evaluator.py pour évaluer directement les générations de modèle dans un fichier personnalisé. Le fichier doit contenir une liste des sorties du modèle, formatée de manière appropriée pour évaluation dans l'ordre des problèmes de référence.
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}En particulier, organisez les sorties dans le format suivant
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]Pour ajouter la prise en charge de nouveaux modèles, nous avons implémenté un cadre extensible pour ajouter de nouveaux modèles et personnaliser les invites de manière appropriée.
Étape 1: Ajoutez un nouveau modèle au fichier ./lcb_runner/LM_STYLES.py. En particulier, étendez la classe LMStyle pour ajouter une nouvelle famille de modèles et étendre le modèle à la matrice LanguageModelList .
Étape 2: Étant donné que nous utilisons des modèles réglés par instructions, nous permettons de configurer l'instruction pour chaque modèle. Modifiez le fichier ./lcb_runner/prompts/generation.py pour ajouter une nouvelle invite pour le modèle dans la fonction format_prompt_generation . Par exemple, l'invite pour DeepSeekCodeInstruct Family of Models semble être comme suit
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt Pour soumettre des modèles au classement, vous pouvez remplir ce formulaire. Vous devrez remplir les détails du modèle et fournir le fichier d'évaluation généré avec des générations de modèle et passer les scores @ 1. Nous examinerons la soumission et ajouterons le modèle au classement en conséquence.
Nous maintenons une liste de problèmes et de mises à jour connus dans le fichier errata.md. En particulier, nous documentons des problèmes concernant les tests erronés et les problèmes qui ne sont pas susceptibles de se procurer. Nous utilisons constamment ces commentaires pour améliorer notre heuristique de sélection de problèmes pendant que nous mettons à jour LivecodeBench.
LiveCodeBench peut être utilisé pour évaluer les performances de LLMS sur différents temps de temps (en utilisant la date de libération du problème pour filtrer les modèles). Ainsi, nous pouvons détecter et prévenir une contamination potentielle dans le processus d'évaluation et évaluer les LLM sur de nouveaux problèmes.
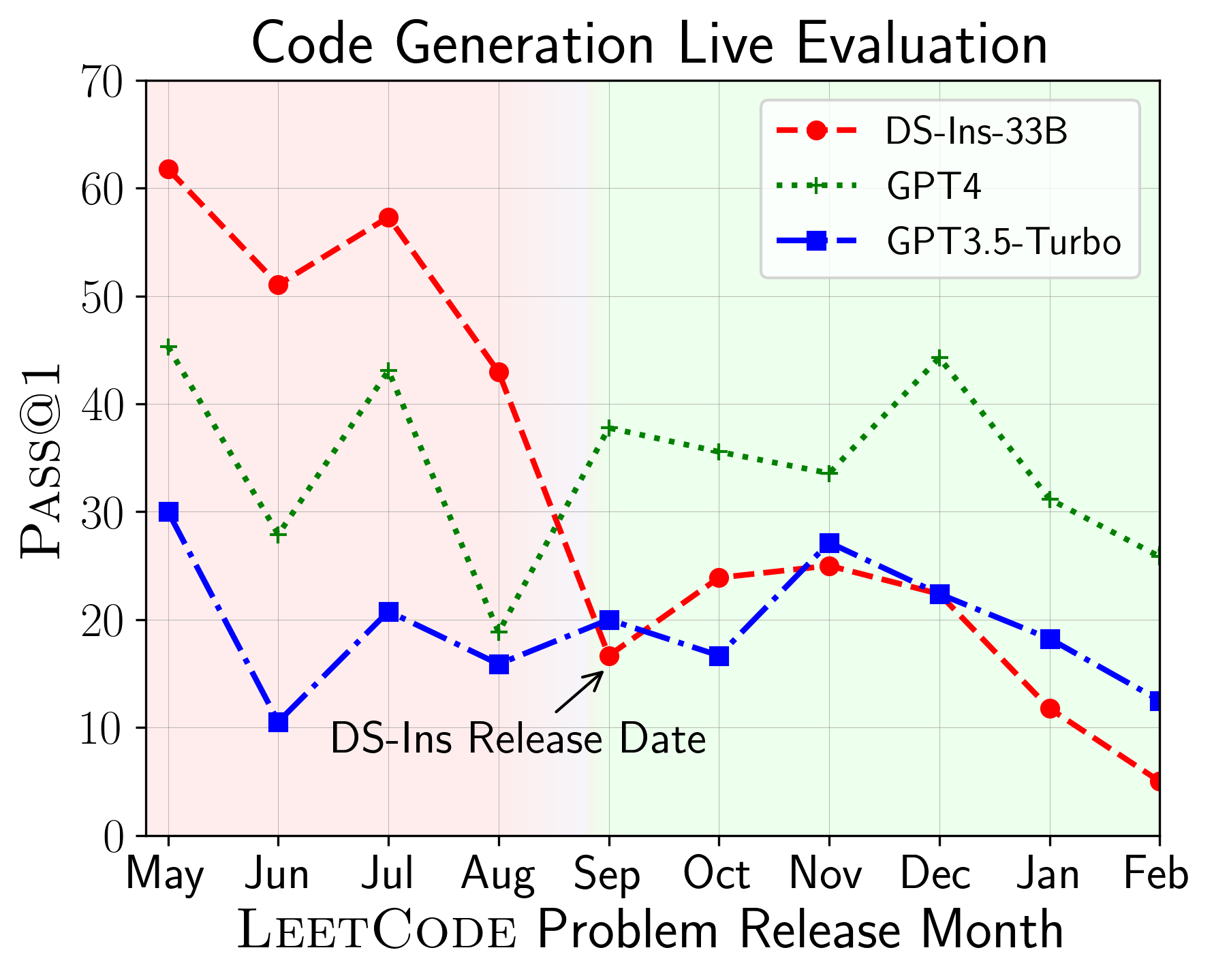
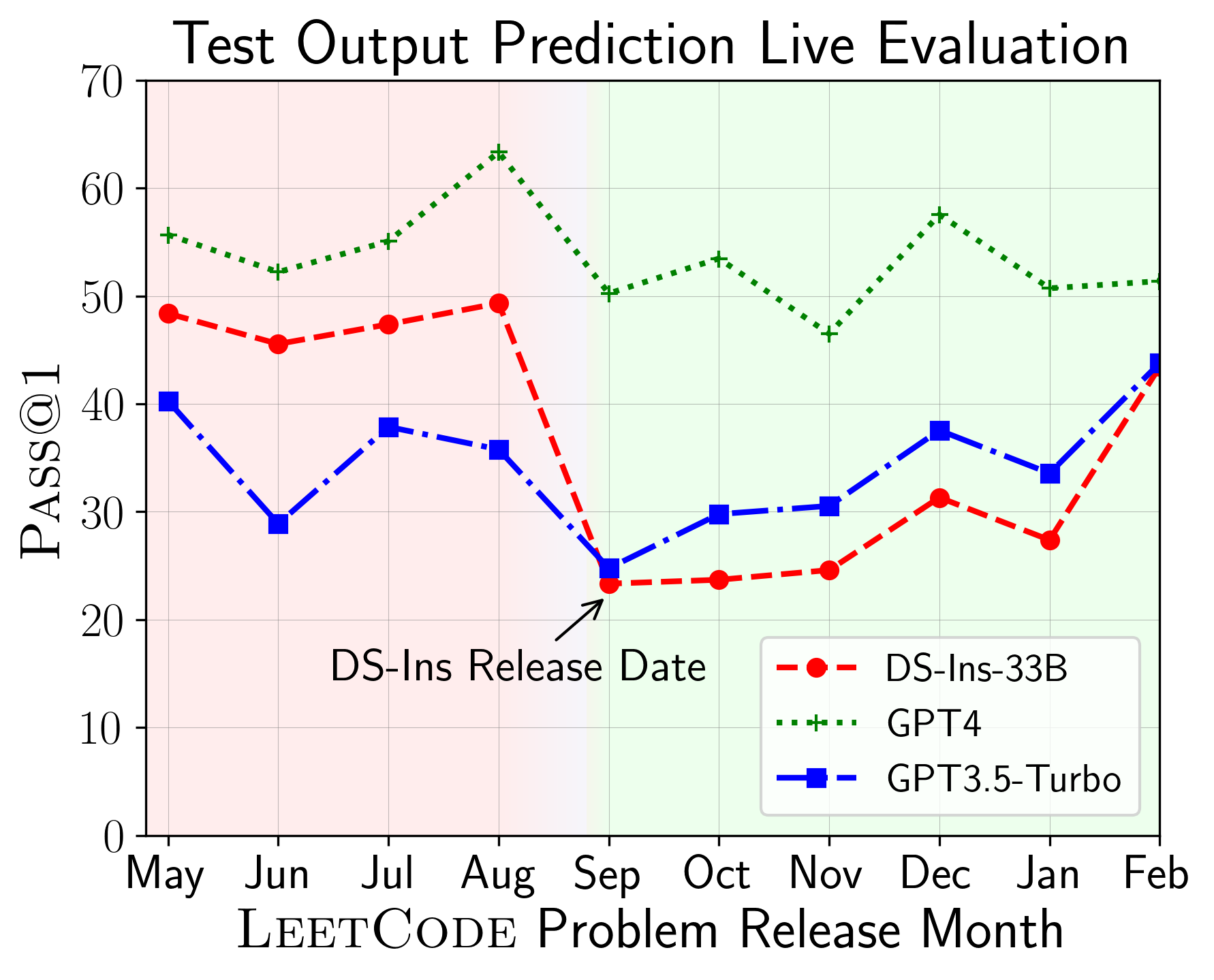
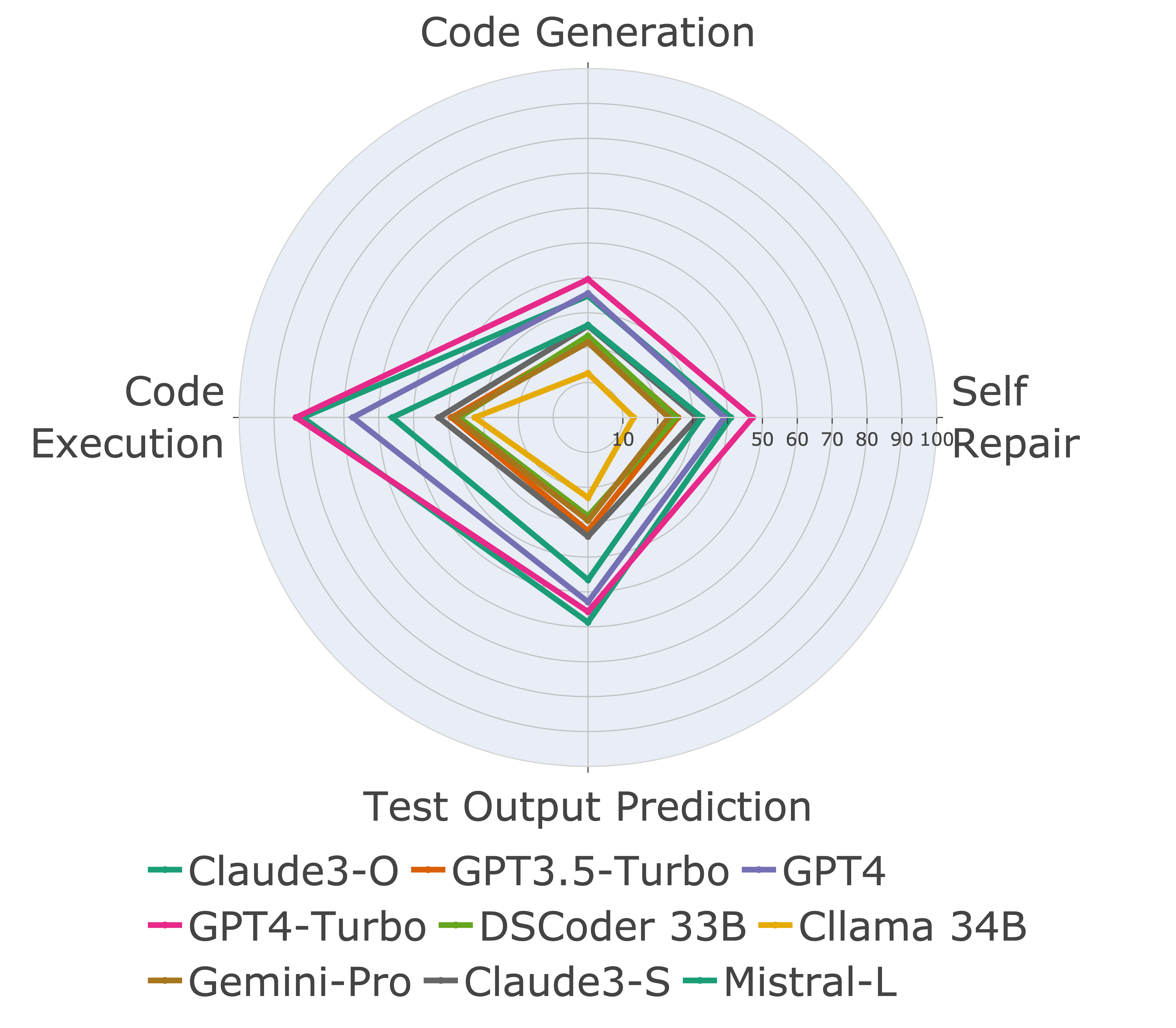
Ensuite, nous évaluons les modèles sur différentes capacités de code et constatons que les performances relatives des modèles changent par rapport aux tâches (à gauche). Ainsi, il met en évidence la nécessité d'une évaluation holistique des LLM pour le code.
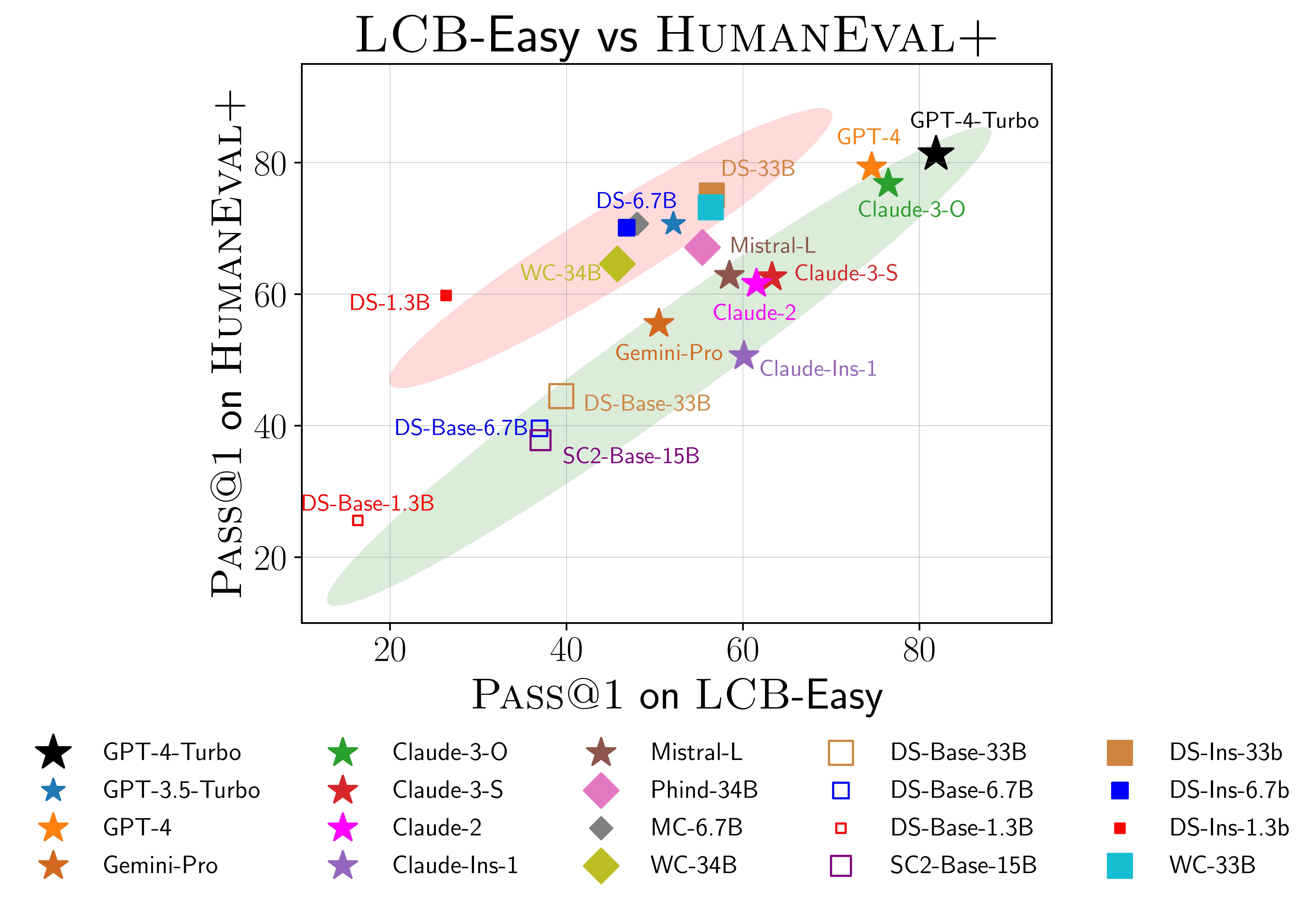
Nous trouvons également des preuves de sur-ajustement possible sur Humaneval (à droite). En particulier, les modèles qui fonctionnent bien sur Humaneval ne fonctionnent pas nécessairement bien sur livecodebench. Dans le diagramme de dispersion ci-dessus, nous constatons que les modèles sont regroupés en deux groupes, ombrés en rouge et en vert. Le groupe rouge contient des modèles qui fonctionnent bien sur Humaneval mais mal sur LivecodeBench, tandis que le groupe vert contient des modèles qui fonctionnent bien sur les deux.
Pour plus de détails, veuillez consulter notre site Web sur livecodebench.github.io.
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

