LiveCodeBench
1.0.0
Repositorio oficial del documento "LivecodeBench: evaluación holística y gratuita de contaminación de modelos de lenguaje grandes para el código"
? Página de inicio • ¿Datos •? Tabla de clasificación
LivecodeBench proporciona una evaluación holística y sin contaminación de las capacidades de codificación de LLM. Particularmente, LivecodeBench recopila continuamente nuevos problemas a lo largo del tiempo de los concursos en tres plataformas de competencia: Leetcode, AtCoder y Codeforces. A continuación, LivecodeBench también se centra en una gama más amplia de capacidades relacionadas con el código, como la auto reparación, la ejecución del código y la predicción de salida de la prueba, más allá de la generación de código solo. Actualmente, LivecodeBench alberga cuatrocientos problemas de codificación de alta calidad que se publicaron entre mayo de 2023 y marzo de 2024.
Puede clonar el repositorio usando el siguiente comando:
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBenchRecomendamos usar poesía para administrar dependencias. Puede instalar poesía y las dependencias utilizando los siguientes comandos:
pip install poetry
poetry install La configuración predeterminada no instala vllm . Para instalar vllm también puede usar:
poetry install --with with-gpuProporcionamos un punto de referencia para diferentes escenarios de capacidad de código
Dado que LivecodeBench es un punto de referencia continuamente actualizado, proporcionamos diferentes versiones del conjunto de datos. Particularmente, proporcionamos las siguientes versiones del conjunto de datos:
release_v1 : la versión inicial del conjunto de datos con problemas lanzados entre mayo de 2023 y marzo de 2024 que contiene 400 problemas.release_v2 : la versión actualizada del conjunto de datos con problemas lanzados entre mayo de 2023 y mayo de 2024 que contiene 511 problemas.release_v3 : la versión actualizada del conjunto de datos con problemas lanzados entre mayo de 2023 y julio de 2024 que contiene 612 problemas.release_v4 : la versión actualizada del conjunto de datos con problemas lanzados entre mayo de 2023 y septiembre de 2024 que contiene 713 problemas. Puede usar el indicador --release_version para especificar la versión del conjunto de datos que desea usar. Particularmente, puede usar el siguiente comando para ejecutar la evaluación en el conjunto de datos release_v2 . Versión de lanzamiento predeterminada a release_latest .
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2 Usamos vllm para inferencia utilizando modelos abiertos. Por defecto, usamos tensor_parallel_size=${num_gpus} para paralelizar la inferencia en todas las GPU disponibles. Se puede configurar utilizando el indicador --tensor_parallel_size según sea necesario.
Para ejecutar la inferencia, proporcione el model_name basado en el archivo ./lcb_runner/lm_styles.py. El escenario (aquí codegeneration ) se puede utilizar para especificar el escenario para el modelo.
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration Además, el indicador --use_cache se puede usar para almacenar en caché las salidas generadas y --continue_existing Flag se puede usar para usar los resultados volcados existentes. En caso de que desee usar el modelo desde una ruta local, también puede proporcionar el indicador --local_model_path con la ruta al modelo. Usamos n=10 y temperature=0.2 para la generación. Consulte el archivo ./lcb_runner/runner/parser.py para obtener más detalles sobre las banderas.
Para los modelos API cerrados, el indicador --multiprocess se puede usar para paralelizar las consultas a los servidores API (ajustables según los límites de velocidad).
Calculamos pass@1 y pass@5 métricas para evaluaciones de modelos. Utilizamos una versión modificada del comprobador lanzado con el punto de referencia apps para calcular las métricas. Particularmente, identificamos algunos casos de borde no controlados en el verificador original y los fijamos y también simplificamos el verificador en función de nuestro conjunto de datos recopilado. Para ejecutar la evaluación, puede agregar el indicador --evaluate :
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate Tenga en cuenta que los límites de tiempo pueden causar pequeños ( < 0.5 ) puntos de variación en el cálculo del pass@1 y las métricas pass@5 . Si observa una variación significativa en el rendimiento, ajuste el indicador --num_process_evaluate a un valor más bajo o aumente el indicador --timeout . Por favor, informe sobre problemas particulares causados por tiempos de espera incorrectos aquí.
Finalmente, para obtener puntajes en diferentes ventanas de tiempo, puede usar el archivo ./lcb_runner/evaluation/compute_scores.py. Particularmente, puede proporcionar las banderas --start_date y --end_date (usando el formato YYYY-MM-DD ) para obtener puntajes en la ventana de tiempo especificada. En nuestro artículo, para contrarrestar la contaminación en los modelos Deepseek, solo informamos los resultados sobre los problemas publicados después de agosto de 2023. Puede replicar esas evaluaciones utilizando:
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01 NOTA: Hemos podado una gran cantidad de casos de prueba desde el punto de referencia original y creado code_generation_lite que se establece como el punto de referencia predeterminado que ofrece una estimación de rendimiento similar mucho más rápido. Si desea utilizar el punto de referencia original, use la bandera --not_fast . Estamos en el proceso de actualizar los puntajes de la tabla de clasificación con esta configuración actualizada.
Nota: Actualización de V2: para ejecutar la actualización livecodeBench, use --release_version release_v2 . Además, si tiene los resultados existentes de release_v1 , puede agregar --continue_existing o mejor --continue_existing_with_eval flags para reutilizar las terminaciones o evaluaciones antiguas respectivamente.
Para ejecutar autocuración, debe proporcionar un indicador adicional --codegen_n que se asigna a la cantidad de códigos que se generaron durante la generación de código. Además, el indicador --temperature se utiliza para resolver el archivo evaluación de generación de código anterior que debe estar presente en el directorio output .
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supported En caso de que tenga resultados en un subconjunto o versión más pequeños del punto de referencia, puede usar --continue_existing y --continue_existing_with_eval Flags para reutilizar los cálculos antiguos. Particularmente, puede ejecutar el siguiente comando para continuar desde las soluciones generadas existentes.
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existing Tenga en cuenta que esto solo reutilizará las muestras generadas y las evaluaciones de volver a ejecutar. Para reutilizar las evaluaciones antiguas, puede agregar el indicador --continue_existing_with_eval .
Para ejecutar el escenario de predicción de salida de prueba, simplemente puede ejecutar
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluatePara ejecutar el escenario de predicción de salida de prueba, simplemente puede ejecutar
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluateAdemás, apoyamos la configuración de cuna con
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluate Alternativamente, puede usar lcb_runner/runner/custom_evaluator.py para evaluar directamente las generaciones de modelos en un archivo personalizado. El archivo debe contener una lista de salidas de modelos, formateadas para la evaluación en el orden de los problemas de referencia.
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}Particularmente, organice las salidas en el siguiente formato
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]Para agregar soporte para nuevos modelos, hemos implementado un marco extensible para agregar nuevos modelos y personalizar las indicaciones sobre la aprobación.
Paso 1: Agregue un nuevo modelo al archivo ./lcb_runner/lm_styles.py. Particularmente, extienda la clase LMStyle para agregar una nueva familia de modelos y extender el modelo a la matriz LanguageModelList .
Paso 2: Dado que usamos modelos sintonizados de instrucciones, permitimos configurar la instrucción para cada modelo. Modifique el archivo ./lcb_runner/prompts/generation.py para agregar un nuevo indicador para el modelo en la función format_prompt_generation . Por ejemplo, el aviso para la familia de modelos de DeepSeekCodeInstruct se ve de la siguiente manera
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt Para enviar modelos a la tabla de clasificación, puede completar este formulario. Deberá completar los detalles del modelo y proporcionar el archivo de evaluación generado con las generaciones de modelos y aprobar puntajes. Revisaremos la presentación y agregaremos el modelo a la tabla de clasificación en consecuencia.
Mantenemos una lista de problemas y actualizaciones conocidas en el archivo Errata.md. Particularmente, documentamos problemas con respecto a las pruebas y problemas erróneos no susceptibles de autogradación. Estamos utilizando constantemente esta retroalimentación para mejorar nuestra selección de problemas Heuristics a medida que actualizamos LivecodeBench.
LivecodeBench se puede usar para evaluar el rendimiento de los LLM en diferentes camisetas de tiempo (utilizando la fecha de liberación del problema para filtrar los modelos). Por lo tanto, podemos detectar y prevenir la contaminación potencial en el proceso de evaluación y evaluar LLM en nuevos problemas.
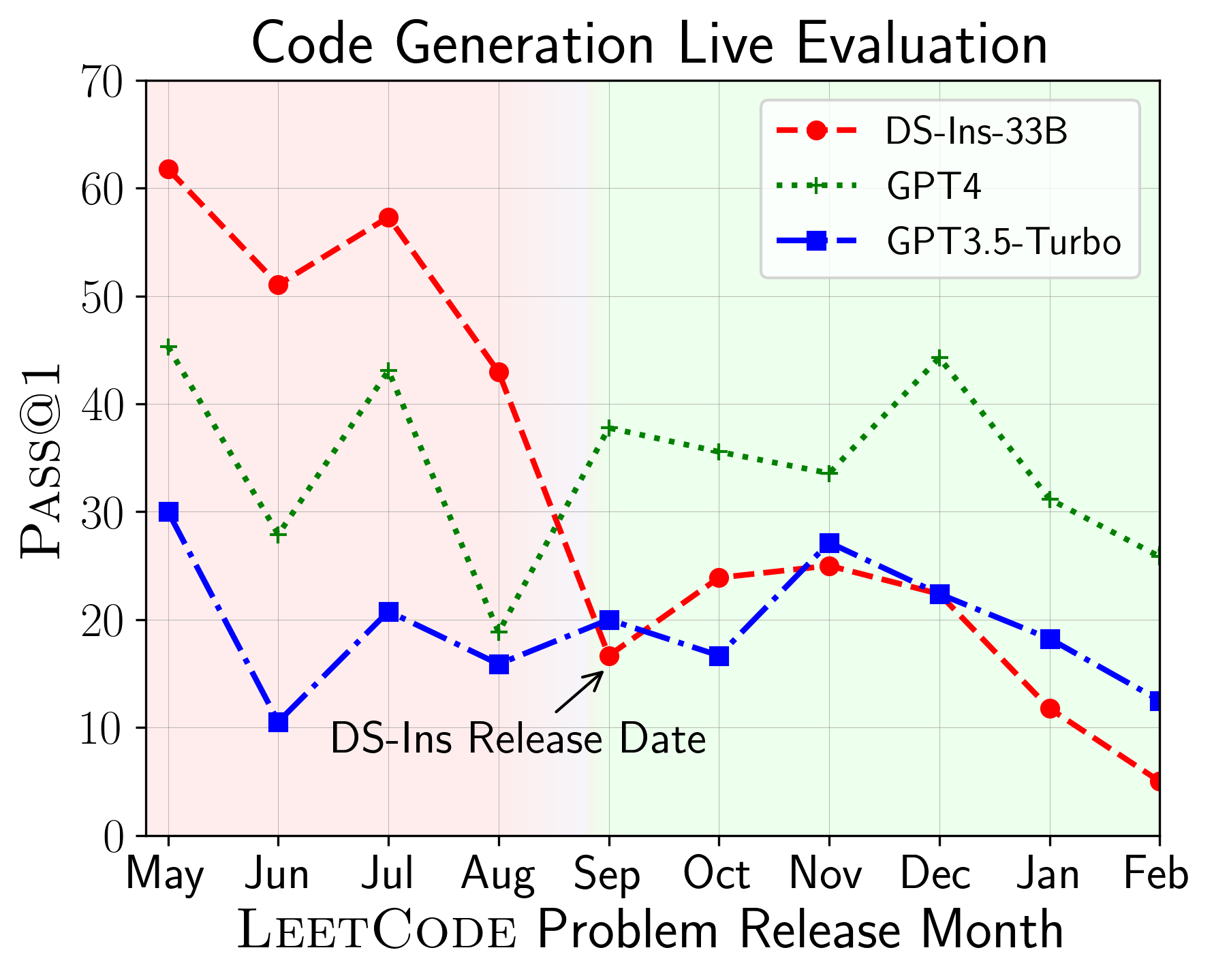
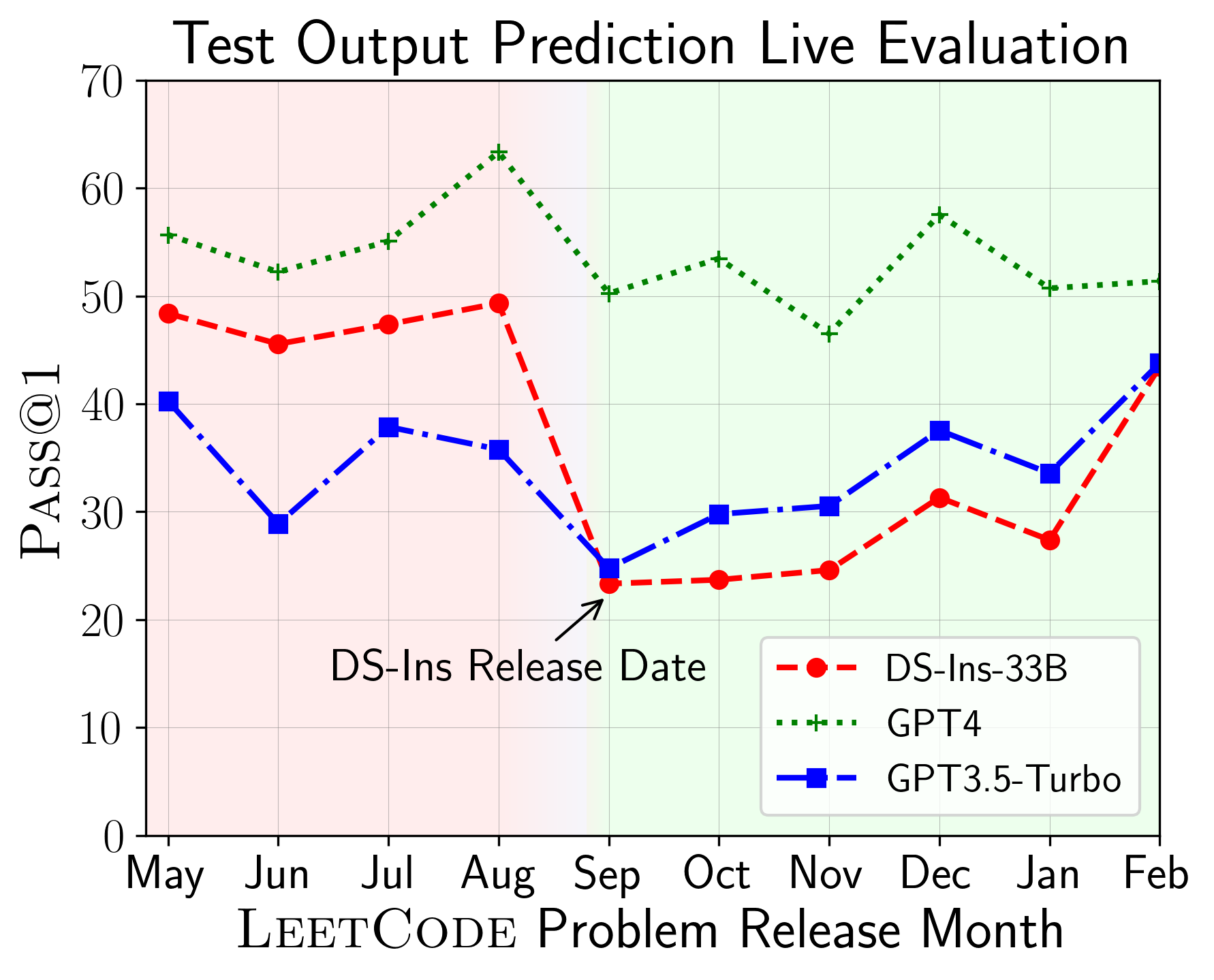
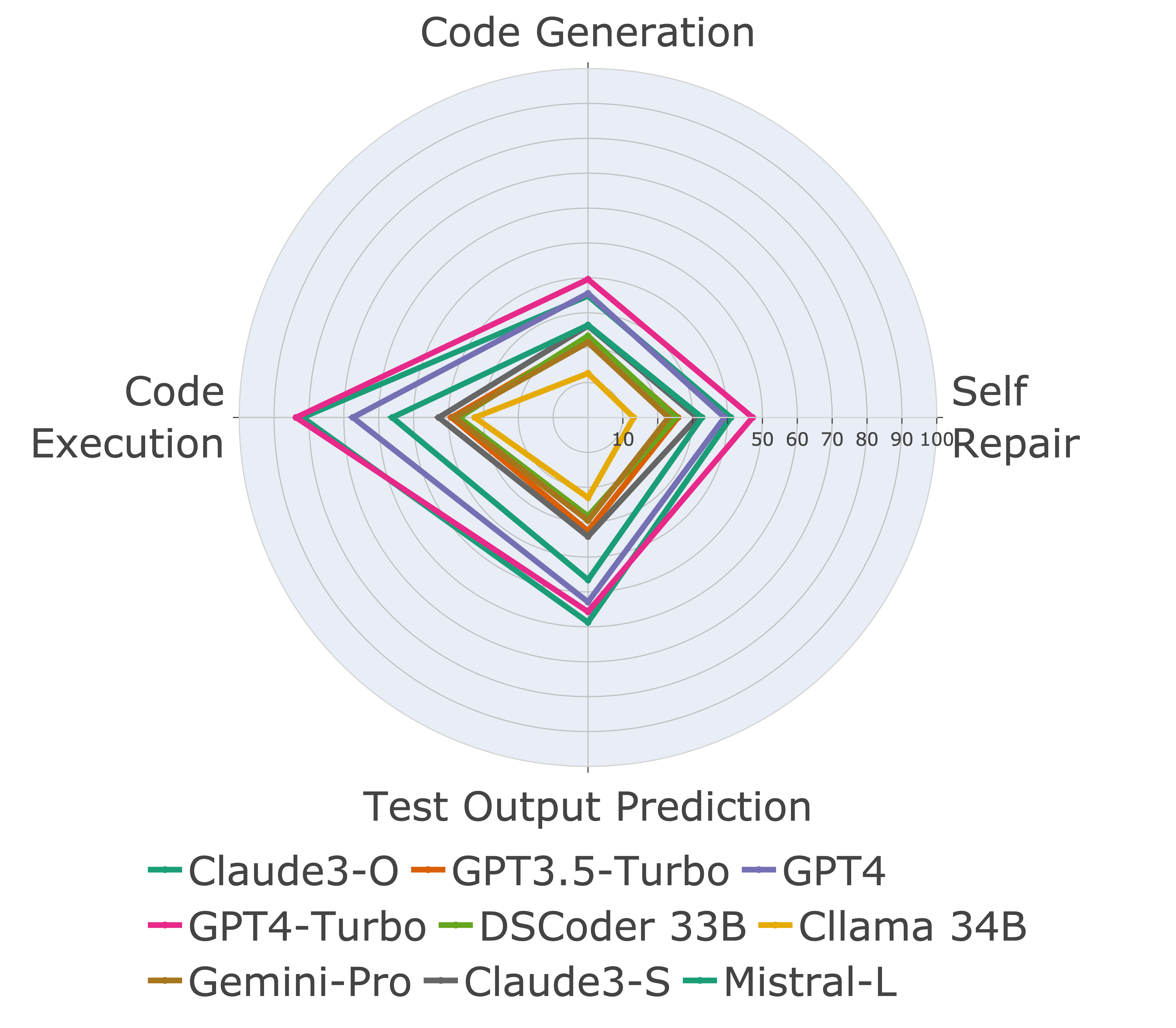
A continuación, evaluamos modelos en diferentes capacidades de código y encontramos que las actuaciones relativas de los modelos cambian sobre las tareas (izquierda). Por lo tanto, destaca la necesidad de una evaluación holística de LLM para el código.
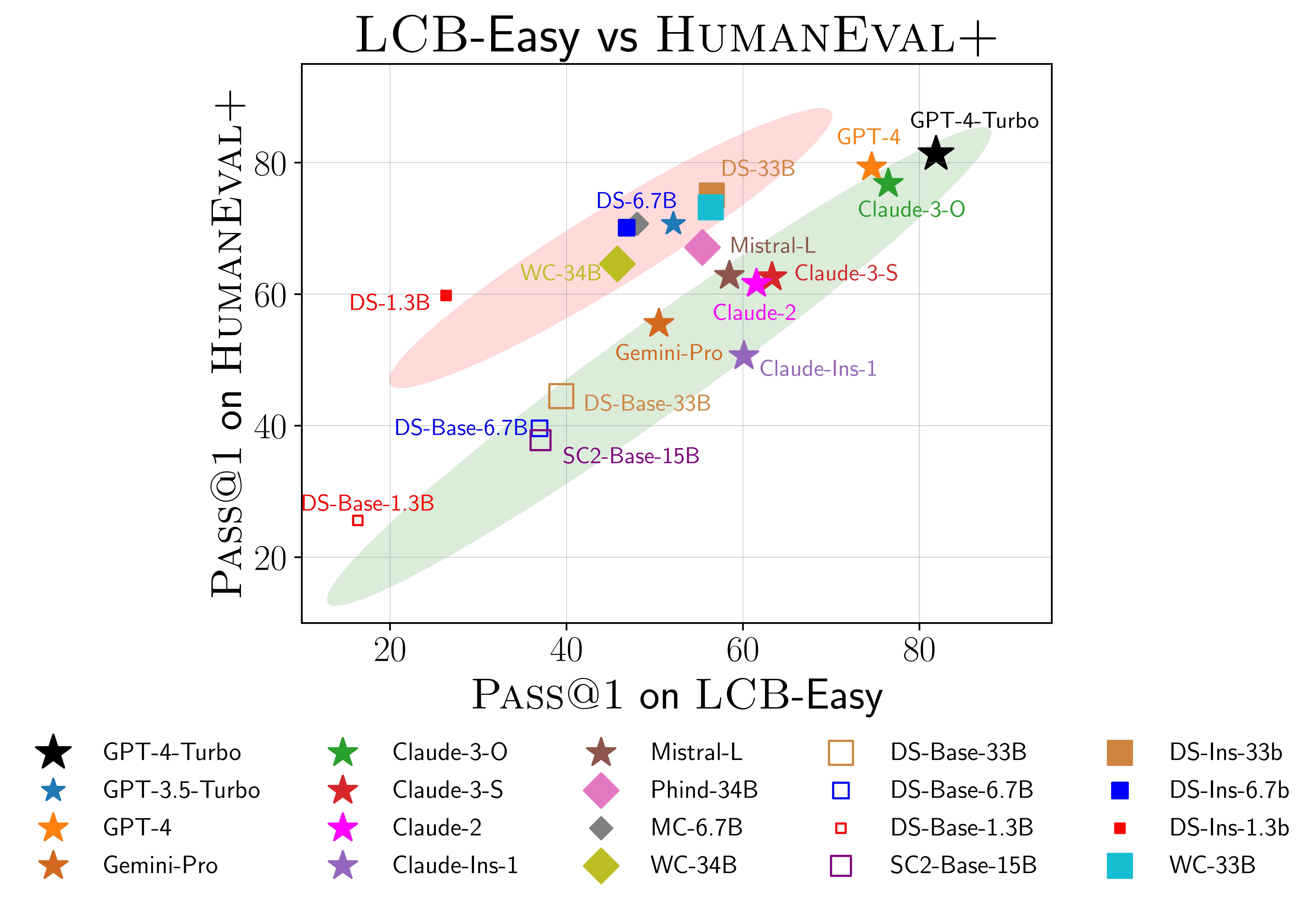
También encontramos evidencia de posible sobreajuste en humaneval (derecha). Particularmente, los modelos que funcionan bien en Humaneval no necesariamente funcionan bien en LivecodeBench. En el diagrama de dispersión anterior, encontramos que los modelos se agrupan en dos grupos, sombreados en rojo y verde. El grupo rojo contiene modelos que funcionan bien en Humaneval pero mal en LivecodeBench, mientras que el grupo verde contiene modelos que funcionan bien en ambos.
Para obtener más detalles, consulte nuestro sitio web en LivecodeBench.github.io.
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

