deep seek
1.0.0
這是針對LLM動力互聯網量表檢索引擎的新實驗體系結構。該體系結構與當前設計的研究代理有很大不同,後者被設計為答案引擎。
您可以在此處看到一些示例結果:https://deep-seek.vercel.app/(請注意,這不會讓您進行真正的查詢,因為我負擔不起嗎?)
兩個概念之間的主要區別分解為:
答案引擎的最終結果是研究報告,檢索引擎的最終結果是一張具有所有檢索的實體和富含列的表。
這是最終結果的樣子(縮放縮放): 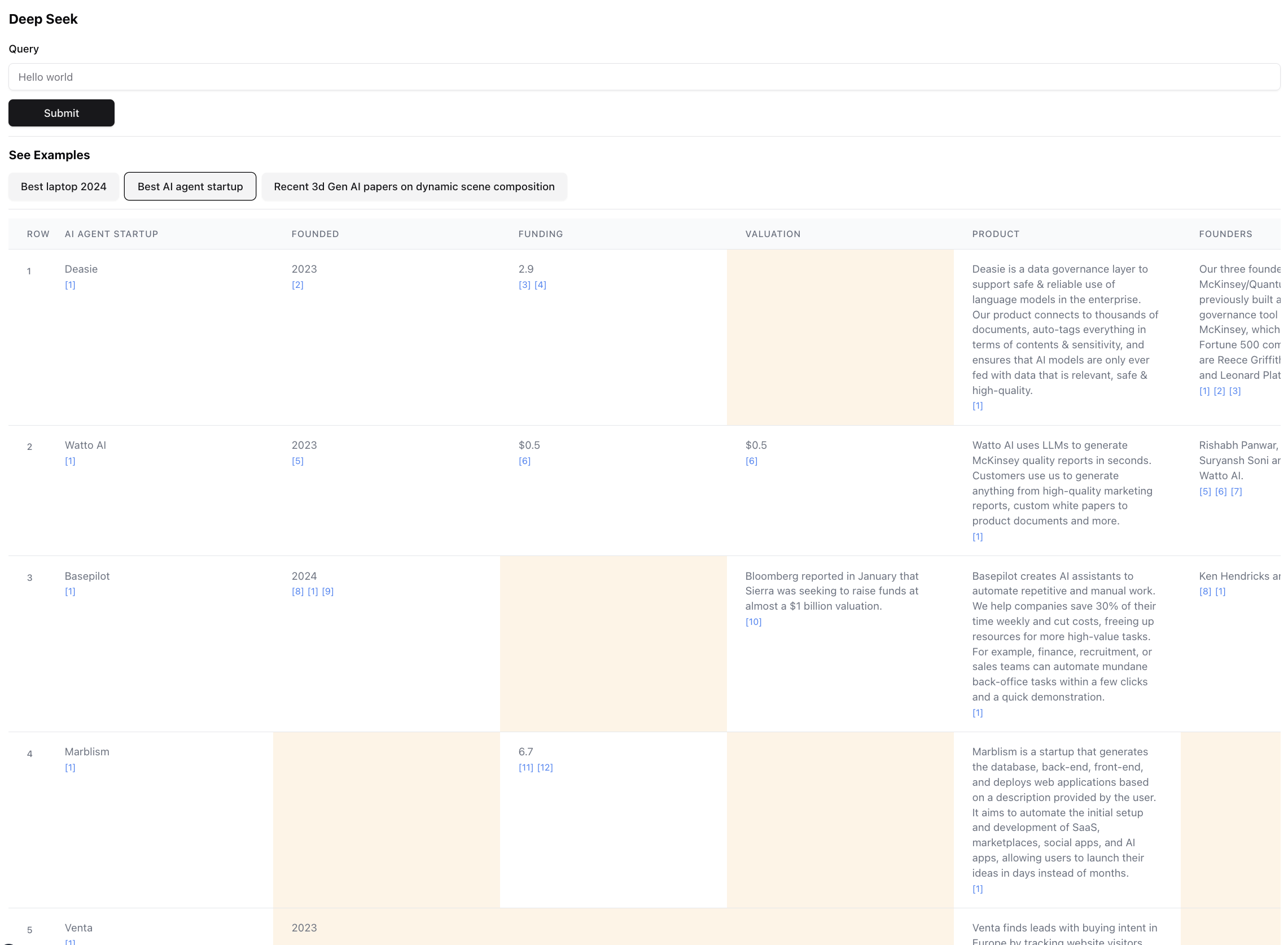
這是此查詢結果的一小部分。實際結果是如此之大,以至於不可能屏幕截圖。最終結果中有94個記錄,代理商通過356個來源瀏覽後收集並豐富了這些記錄。
該代理還會在表單元中生成數據富集時數據的置信得分。請注意,黃色突出顯示了某些細胞 - 這些細胞是置信度較低的細胞。在這些情況下,來源可能會發生衝突,或者根本沒有來源,因此代理商做出了最好的猜測。這實際上是0-1之間的數字,因此肯定可以有更好,更具創意的UI來展示更高的忠誠度的分數。
安裝以下任何包裝管理人員
按照安裝中的說明安裝軟件包管理器和項目依賴項
要運行DEV服務器,請根據您的軟件包管理器使用以下命令之一
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun dev打開http:// localhost:3000使用瀏覽器開始搜索或探索預構建的示例。請注意,這些示例實際上不會運行代理(花費很多$),通過讓您檢查結果來顯示架構的功率和缺陷,更多的地方。
如果您設置了環境變量,則可以自己運行。請注意,這需要約5分鐘,可能會在$ 0.1- $ 3的信用額之間花費,具體取決於檢索到的實體數量和需要豐富的數據數量。
運行代理時,請檢查終端以查看幕後發生的事情的日誌。
確保您有擬人化和EXA的API鍵。
創建一個.ENV文件,然後放入以下環境變量:
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
該系統是多步研究代理。初始的用戶查詢被分解為一個計劃,答案在整個系統流動時迭代構建。這種類型的體系結構的另一個名稱是流程工程。
研究管道分為4個主要步驟:
計劃 - 根據用戶查詢,計劃者構建了最終結果的形狀。它通過定義提取的實體的類型以及結果表中的不同列來做到這一點。這些列表示與用戶與實體有關的查詢相關的其他數據。
搜索 - 我們同時使用標準關鍵字搜索和神經搜索來查找相關的內容(兩種類型的搜索均由EXA提供)。關鍵字搜索非常擅長查找用戶生成的內容,討論要找到的實體(例如評論,列表等)。神經搜索非常擅長尋找特定實體本身(例如公司,文件等)。
提取 - 通過LLM處理搜索中的所有內容,以提取特定實體及其相關內容。這是通過我正在測試的新技術完成的,其中在內容中插入句子(通過WinkNLP的小語言模型拆分)的特殊令牌,而LLM的任務是定義用於提取的內容範圍,以指示啟動和結束代幣。這是超快速且有效的。
ENRICH-我們實際上確實在這個較大的檢索代理中有一個較小的答案代理,其工作是豐富了每個實體為計劃者定義的所有列。這是整個過程中最耗時的部分,但這也是該代理非常徹底的原因。
這是其工作原理的更詳細的流程: 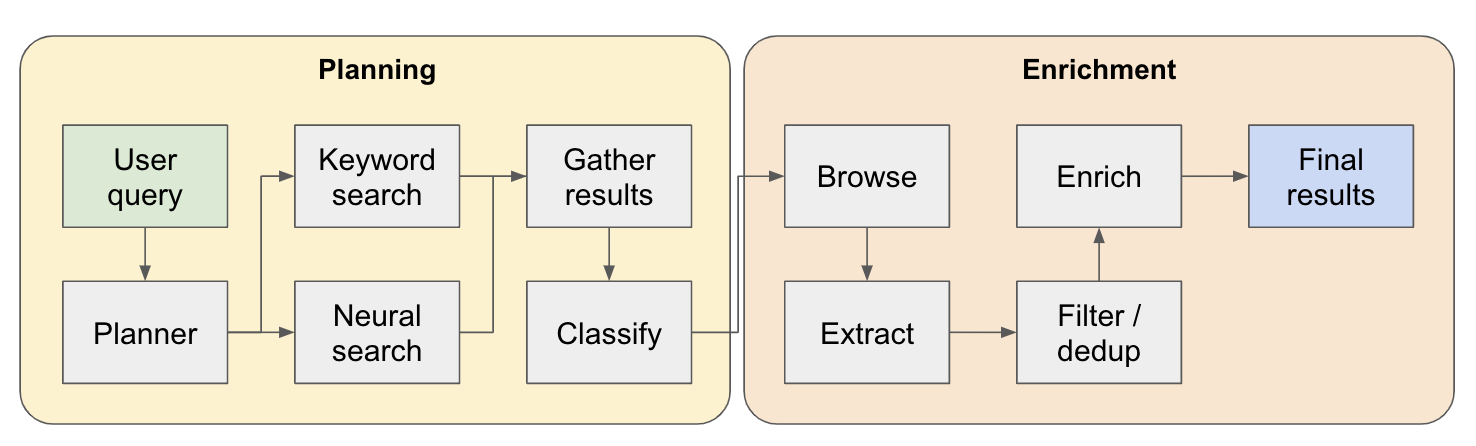
對於任何探索此架構的人 - 如果您發現一個好的或有趣的用例,請將其添加到示例列表中,以便其他人可以檢查一下!在app下有一個examples.ts文件,其中包含示例的所有原始數據。查詢完成運行後,您可以通過瀏覽器控制台獲取原始數據(只需將其複製到示例文件中)即可。
通過相關性對檢索到的實體進行排序 /排名 - 這對於具有“最佳”或“最新”等預選賽的查詢尤為重要。
更好的實體解決方案來檢測重複的實體 - 有時候,代理商仍然被M2 VS M3 MacBook之類的東西所困擾,有一些技術可以使更好的格式實體標題可以在這裡導致更好的性能。
與上幾點有關,在富集時更好地驗證源以確保其連接到原始實體。
支持來源的深度瀏覽 - 有時代理應該單擊網頁以真正介紹內容,例如,這是在搜索有關ARXIV的研究論文時做得很好的。
支持數據中流媒體的支持 - 令人驚訝的是,在UI中實時豐富了列表的列表和單元格。現在,您只能通過觀看終端上的日誌來獲得進度感。
如果您想對此進行合作或只是想討論想法,請隨時通過[email protected]給我發送電子郵件或在Twitter上ping我。


