deep seek
1.0.0
นี่คือสถาปัตยกรรมการทดลองใหม่สำหรับ เอ็นจิ้นการดึง สเกลอินเทอร์เน็ต LLM สถาปัตยกรรมนี้แตกต่างจากตัวแทนวิจัยในปัจจุบันซึ่งได้รับการออกแบบให้เป็น เครื่องยนต์คำตอบ
คุณสามารถดูผลลัพธ์ตัวอย่างได้ที่นี่: https://deep-seek.vercel.app/ (โปรดทราบว่าสิ่งนี้จะไม่ให้คุณทำแบบสอบถามจริงเนื่องจากฉันไม่สามารถจ่ายได้?)
ความแตกต่างที่สำคัญระหว่างแนวคิดทั้งสองแบ่งออกเป็น:
ผลลัพธ์สุดท้ายสำหรับเอ็นจิ้นคำตอบคือรายงานการวิจัยผลลัพธ์สุดท้ายสำหรับเอ็นจิ้นการดึงข้อมูลคือตารางที่มีเอนทิตีที่ดึงมาทั้งหมดและคอลัมน์ที่ได้รับการตกแต่ง
นี่คือผลลัพธ์สุดท้ายที่ดูเหมือน (ซูมออกมาสเกล): 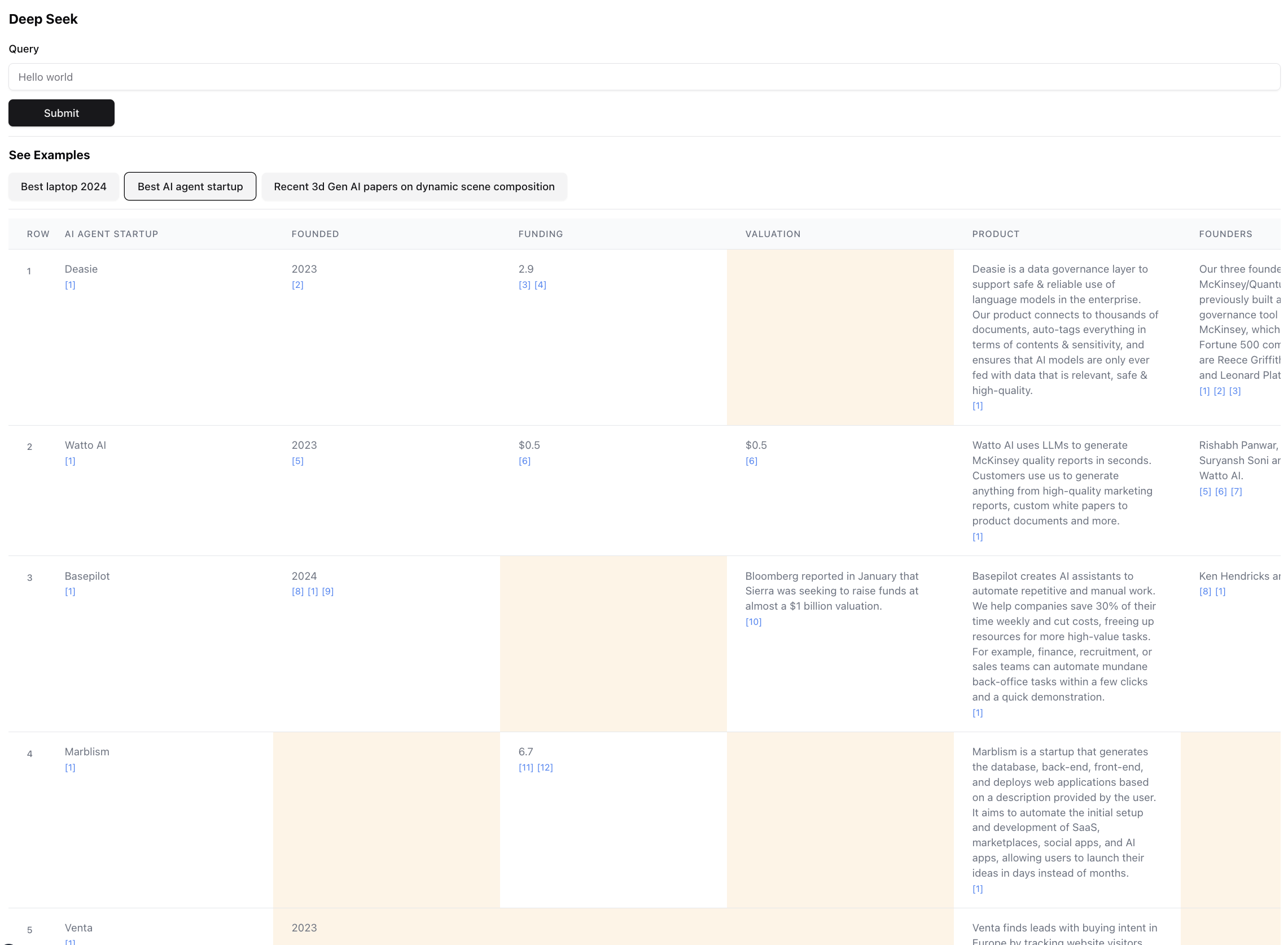
นี่เป็นส่วนเล็ก ๆ ของผลลัพธ์สำหรับแบบสอบถามนี้ ผลลัพธ์ที่เกิดขึ้นจริงมีขนาดใหญ่มากเป็นไปไม่ได้ที่จะถ่ายภาพหน้าจอ มี 94 ระเบียนในผลลัพธ์สุดท้ายซึ่งตัวแทนรวบรวมและเพิ่มขึ้นหลังจากเรียกดูผ่านแหล่งข้อมูล 356 แหล่ง
ตัวแทนยังสร้างคะแนนความมั่นใจสำหรับข้อมูลในเซลล์ตารางเนื่องจากมีการเพิ่มคุณค่า โปรดทราบว่ามีเซลล์บางเซลล์ที่เน้นเป็นสีเหลือง - เซลล์เหล่านั้นเป็นเซลล์ที่มีความมั่นใจต่ำ นี่เป็นกรณีที่แหล่งที่มาอาจขัดแย้งหรือไม่มีแหล่งที่มาเลยดังนั้นตัวแทนจึงคาดเดาได้ดีที่สุด นี่คือตัวเลขระหว่าง 0 - 1 ดังนั้นจึงมี UI ที่ดีกว่าและสร้างสรรค์มากขึ้นในการแสดงคะแนนในความซื่อสัตย์ที่สูงขึ้น
ติดตั้งหนึ่งในผู้จัดการแพ็คเกจต่อไปนี้
ทำตามคำแนะนำในการติดตั้งเพื่อติดตั้งตัวจัดการแพ็คเกจและการพึ่งพาโครงการ
ในการเรียกใช้เซิร์ฟเวอร์ dev ให้ใช้หนึ่งในคำสั่งต่อไปนี้ตามตัวจัดการแพ็คเกจของคุณ
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun devเปิด http: // localhost: 3000 กับเบราว์เซอร์ของคุณเพื่อเริ่มค้นหาหรือสำรวจตัวอย่างที่สร้างไว้ล่วงหน้า โปรดทราบว่าตัวอย่างจะไม่เรียกใช้เอเจนต์จริง ๆ (มีค่าใช้จ่ายมาก $) มันมีมากกว่าที่จะแสดงพลังและข้อบกพร่องของสถาปัตยกรรมโดยให้คุณตรวจสอบผลลัพธ์
หากคุณมีชุดตัวแปรสภาพแวดล้อมคุณสามารถเรียกใช้ด้วยตัวคุณเอง โปรดทราบว่าใช้เวลาประมาณ 5 นาทีและอาจมีค่าใช้จ่ายระหว่างเครดิต $ 0.1 - $ 3 ขึ้นอยู่กับจำนวนหน่วยงานที่ดึงมาและจำนวนข้อมูลที่ต้องเพิ่มขึ้น
เมื่อเรียกใช้เอเจนต์ให้ตรวจสอบเทอร์มินัลเพื่อดูบันทึกของสิ่งที่เกิดขึ้นเบื้องหลัง
ตรวจสอบให้แน่ใจว่าคุณมีคีย์ API สำหรับมานุษยวิทยาและ EXA
สร้างไฟล์. env และใส่ในตัวแปรสภาพแวดล้อมต่อไปนี้:
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
ระบบทำงานเป็นตัวแทนวิจัยหลายขั้นตอน แบบสอบถามผู้ใช้เริ่มต้นแบ่งออกเป็นแผนและคำตอบนั้นถูกสร้างขึ้นซ้ำ ๆ เมื่อไหลผ่านระบบ อีกชื่อหนึ่งสำหรับสถาปัตยกรรมประเภทนี้คือวิศวกรรมการไหล
ไปป์ไลน์การวิจัยแบ่งออกเป็น 4 ขั้นตอนหลัก:
แผน - ขึ้นอยู่กับการสืบค้นผู้ใช้ผู้วางแผนจะสร้างรูปร่างของผลลัพธ์ที่ได้จะเป็นอย่างไร มันทำได้โดยการกำหนดประเภทของเอนทิตีเพื่อแยกรวมถึงคอลัมน์ที่แตกต่างกันในตารางผลลัพธ์ คอลัมน์แสดงข้อมูลเพิ่มเติมที่เกี่ยวข้องกับการสืบค้นของผู้ใช้ที่เกี่ยวข้องกับเอนทิตี
การค้นหา - เราใช้ทั้งการค้นหาคำหลักมาตรฐานและการค้นหาประสาทเพื่อค้นหาเนื้อหาที่เกี่ยวข้องในการประมวลผล (การค้นหาทั้งสองประเภทนั้นจัดทำโดย EXA) การค้นหาคำหลักนั้นยอดเยี่ยมในการค้นหาเนื้อหาที่ผู้ใช้สร้างขึ้นพูดถึงเอนทิตีที่จะพบ (เช่นบทวิจารณ์, listicles .. ฯลฯ ) การค้นหาทางประสาทนั้นยอดเยี่ยมในการค้นหาหน่วยงานเฉพาะเอง (เช่น บริษัท เอกสาร .. ฯลฯ )
Extract - เนื้อหาทั้งหมดที่พบในการค้นหาจะถูกประมวลผลผ่าน LLM เพื่อแยกเอนทิตีเฉพาะและเนื้อหาที่เกี่ยวข้อง สิ่งนี้ทำผ่านเทคนิคใหม่ฉันกำลังทดสอบว่ามีการแทรกโทเค็นพิเศษระหว่างประโยค (แยกผ่านโมเดลภาษาขนาดเล็กของ Winknlp) ในเนื้อหาและ LLM ได้รับมอบหมายให้กำหนดช่วงของเนื้อหาเพื่อแยกโดยระบุโทเค็นเริ่มต้นและสิ้นสุด นี่คือ Super Fast & Token มีประสิทธิภาพ
Enrich - เรามีตัวแทนคำตอบที่เล็กกว่าภายในตัวแทนการดึงข้อมูลที่ใหญ่กว่านี้ซึ่งมีงานจะเพิ่มคอลัมน์ทั้งหมดที่กำหนดโดยผู้วางแผนสำหรับทุกเอนทิตี นี่เป็นส่วนที่เสียเวลามากที่สุดของกระบวนการทั้งหมด แต่ก็เป็นเหตุผลว่าทำไมตัวแทนนี้จึงละเอียดถี่ถ้วน
นี่คือรายละเอียดเพิ่มเติมเกี่ยวกับวิธีการทำงาน: 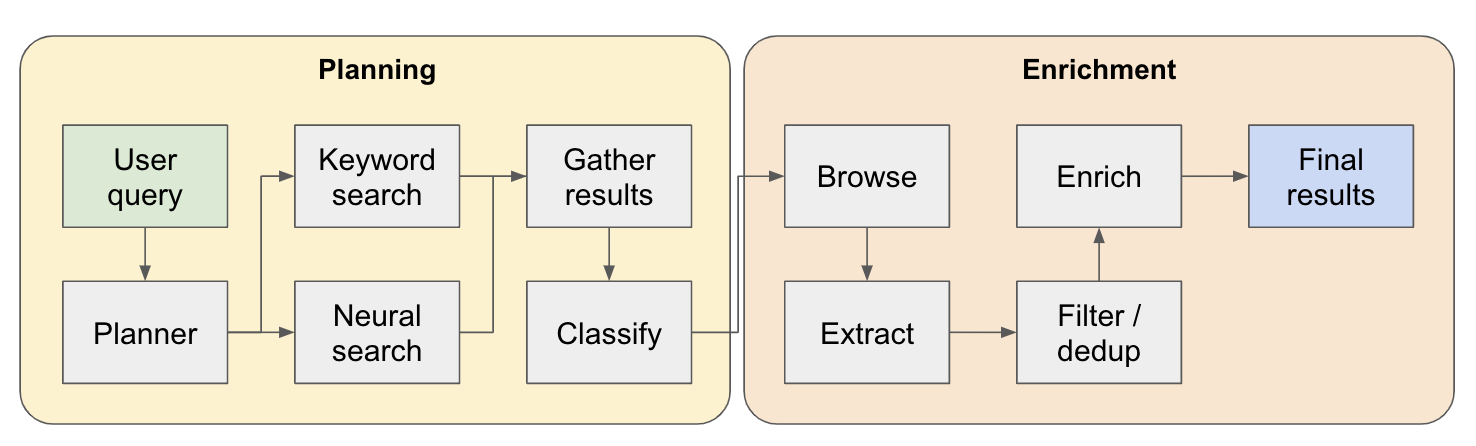
สำหรับทุกคนที่สำรวจสถาปัตยกรรมนี้ - หากคุณพบกรณีการใช้งานที่ดีหรือน่าสนใจโปรดเพิ่มลงในรายการตัวอย่างเพื่อให้คนอื่นสามารถตรวจสอบได้! มี examples.ts ไฟล์ใต้ app พร้อมข้อมูลดิบทั้งหมดของตัวอย่าง คุณสามารถรับข้อมูลดิบผ่านคอนโซลเบราว์เซอร์หลังจากที่มีการค้นหาเสร็จแล้ว (เพียงแค่คัดลอกลงในไฟล์ตัวอย่าง)
การเรียงลำดับ / จัดอันดับเอนทิตีที่ดึงมาโดยความเกี่ยวข้อง - นี่เป็นสิ่งสำคัญอย่างยิ่งสำหรับการสอบถามที่มีผู้คัดเลือกเช่น "ดีที่สุด" หรือ "ใหม่ล่าสุด" ... ฯลฯ สิ่งนี้ควรเพิ่มเป็นขั้นตอนเพิ่มเติมในตอนท้ายของท่อ
ความละเอียดของเอนทิตีที่ดีขึ้นในการตรวจจับเอนทิตีที่ซ้ำกัน - ตัวแทนยังคงนิ่งงันโดยสิ่งต่าง ๆ เช่น M2 vs M3 MacBooks บางครั้งมีเทคนิคในการจัดรูปแบบของชื่อเอนทิตีที่ดีกว่าซึ่งอาจนำไปสู่ประสิทธิภาพที่ดีขึ้นที่นี่
เกี่ยวข้องกับจุดก่อนหน้าการตรวจสอบแหล่งที่ดีขึ้นเมื่อเพิ่มคุณค่าเพื่อให้แน่ใจว่ามันเชื่อมต่อกับเอนทิตีออร์จินัล
สนับสนุนการท่องเว็บอย่างลึกล้ำ - บางครั้งตัวแทนควรคลิกรอบ ๆ หน้าเว็บเพื่อเจาะลึกลงไปในเนื้อหาจริง ๆ นี้จะต้องทำงานได้ดีในการค้นหาผ่านงานวิจัยเกี่ยวกับ Arxiv เป็นต้น
การสนับสนุนการสตรีมในข้อมูล - มันน่าอัศจรรย์ที่ได้เห็นรายการที่มีประชากรและเซลล์ที่ได้รับการเสริมสมรรถนะแบบเรียลไทม์ใน UI ตอนนี้คุณสามารถรับความคืบหน้าได้โดยการดูบันทึกบนเทอร์มินัล
หากคุณต้องการทำงานร่วมกันในเรื่องนี้หรือเพียงแค่ต้องการพูดคุยเกี่ยวกับแนวคิดอย่าลังเลที่จะส่งอีเมลถึงฉันที่ [email protected] หรือ ping me บน Twitter


