deep seek
1.0.0
これは、LLMを搭載したインターネットスケール検索エンジンの新しい実験アーキテクチャです。このアーキテクチャは、回答エンジンとして設計された現在の研究エージェントとは大きく異なります。
ここでいくつかの例を見ることができます:https://deep-seek.vercel.app/(これにより、実際のクエリができないことに注意してください。
2つの概念の主な違いは、次のように分類されます。
回答エンジンの最終結果は調査レポートであり、検索エンジンの最終結果は、すべての取得エンティティと濃縮列を備えたテーブルです。
最終結果がどのように見えるか(スケールのためにズームアウトされています): 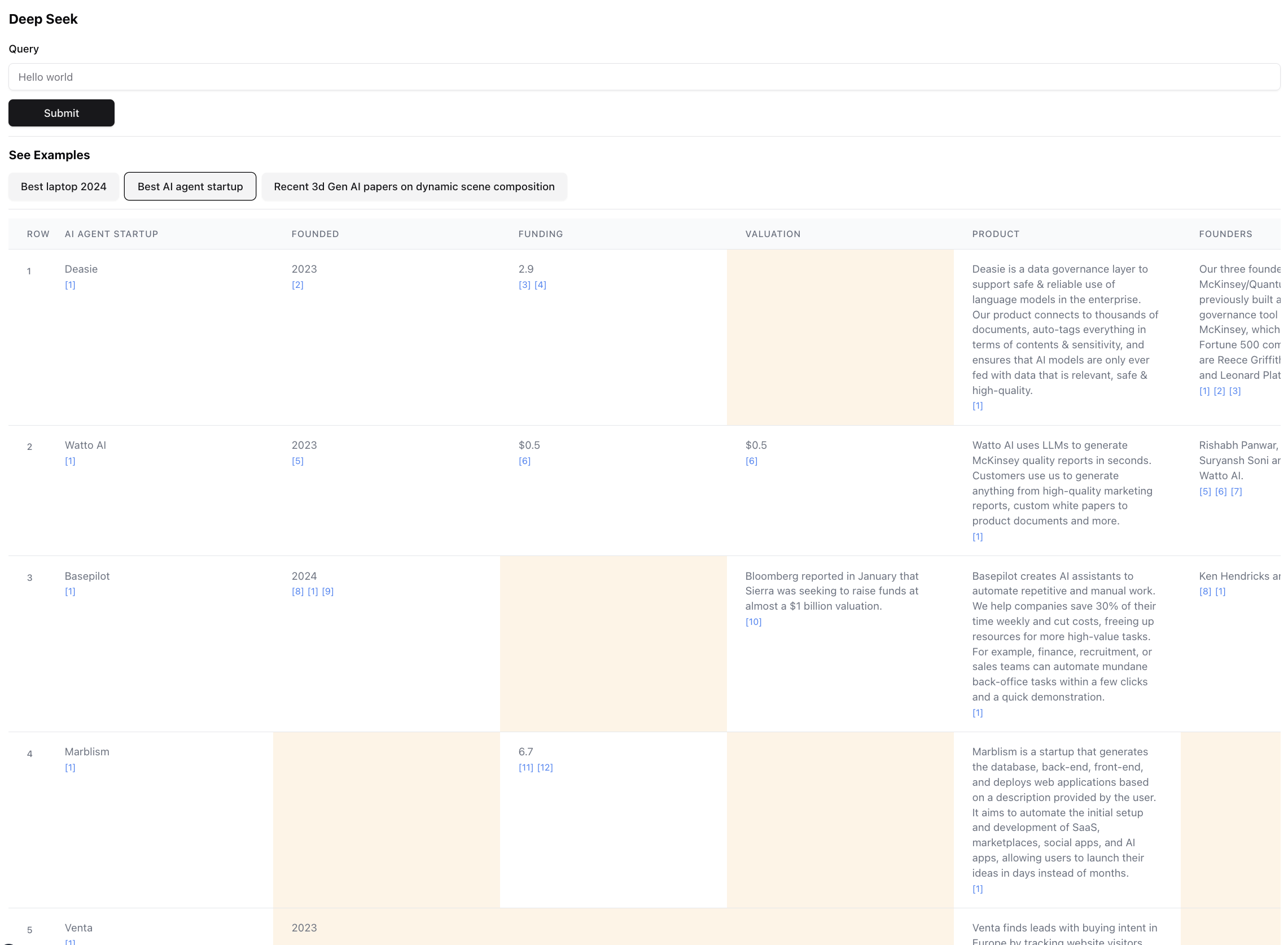
これは、このクエリの結果のごく一部です。実際の結果は非常に大きいため、スクリーンショットは不可能です。最終結果には94のレコードがあり、356のソースを閲覧した後、エージェントが収集して濃縮しました。
エージェントは、濃縮されているため、テーブルセルのデータの信頼性スコアも生成します。黄色で強調表示されている特定の細胞があることに注意してください - それらは信頼性の低いセルです。これらは、ソースが競合する可能性がある場合、またはソースがまったくない場合であるため、エージェントが最良の推測を行いました。これは実際には0〜1の間であるため、より高い忠実度のスコアを紹介するために、より良い&より創造的なUIが確実にある可能性があります。
次のパッケージマネージャーのいずれかをインストールします
インストールの指示に従って、パッケージマネージャーとプロジェクトの依存関係をインストールする
開発サーバーを実行するには、パッケージマネージャーに従って次のコマンドのいずれかを使用します
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun devhttp:// localhost:3000を開き、ブラウザの検索を開始したり、事前に構築された例を検討したりします。例は実際にエージェントを実行しないことに注意してください(費用はかかります)。結果を検査できることにより、アーキテクチャの力と欠陥を示すことができます。
環境変数が設定されている場合は、自分で実行できます。 〜5分かかり、取得されたエンティティの数と充実したデータの量に応じて、$ 0.1〜3ドル相当のクレジットのどこかにかかる可能性があることに注意してください。
エージェントを実行するときは、端末をチェックして、舞台裏で何が起こっているのかのログを確認します。
人為的およびEXA用のAPIキーがあることを確認してください。
.ENVファイルを作成し、次の環境変数に入れます。
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
このシステムは、マルチステップの研究エージェントとして機能します。最初のユーザークエリは計画に分割され、回答はシステムを流れると反復的に構築されます。このタイプのアーキテクチャの別の名前はフローエンジニアリングです。
研究パイプラインは、4つの主要なステップに分割されています。
プラン - ユーザークエリに基づいて、プランナーは最終結果の形状がどのように見えるかを構築します。これは、抽出するエンティティのタイプを定義し、結果のテーブル内の異なる列を定義することにより行います。列は、エンティティに関連するユーザーのクエリに関連する追加データを表します。
検索 - 標準のキーワード検索とニューラル検索の両方を使用して、関連するコンテンツをプロセスします(両方のタイプの検索がEXAによって提供されます)。キーワード検索は、発見されるエンティティ(レビュー、リストなど)について話しているユーザー生成コンテンツを見つけるのに最適です。ニューラル検索は、特定のエンティティ自体(企業、論文など)を見つけるのに最適です。
抽出 - 検索で見つかったすべてのコンテンツは、特定のエンティティとその関連コンテンツを抽出するためにLLMを介して処理されます。これは、コンテンツ内の文の間に特別なトークン(WinkNLPの小さな言語モデルを介して分割)の間に挿入されている場所をテストしている新しい手法を介して行われ、LLMには、開始トークンを示すことで抽出するコンテンツの範囲を定義することが課せられています。これは非常に高速でトークン効率が良くなります。
Encrich-実際には、このより大きな検索エージェント内に小さな回答エージェントがあります。これはプロセス全体の中で最も時間のかかる部分ですが、このエージェントが非常に徹底的である理由でもあります。
これがそれがどのように機能するかのより詳細な流れです: 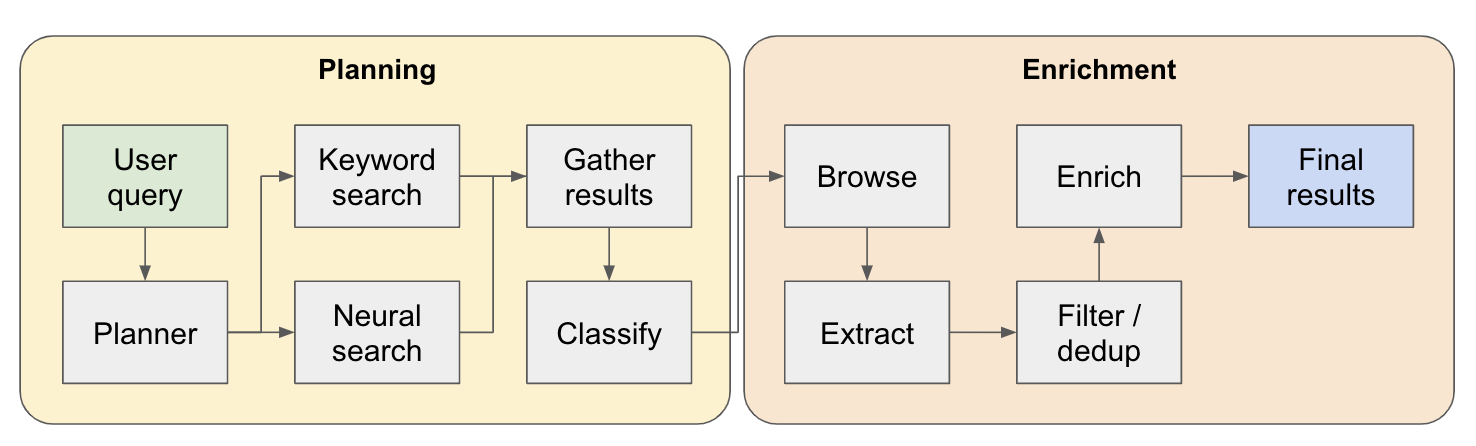
このアーキテクチャを探索している人のために - 良いまたは興味深いユースケースを見つけた場合は、他の人がチェックできるように例リストに追加してください!例のすべての生データを含むexamples.tsファイルがappの下にあります。クエリの実行が終了した後、ブラウザコンソールを介して生データを取得できます(例ファイルにコピーするだけです)。
検索されたエンティティを関連性によって並べ替え /ランキング - これは、「ベスト」や「最新」などの修飾子を持つクエリにとって特に重要です。これは、パイプラインの終わりに追加のステップとして追加する必要があります。
重複したエンティティを検出するためのより良いエンティティ解像度 - エージェントは、M2対M3 MacBooksのようなものにまだ困惑していますが、ここでより良いパフォーマンスにつながる可能性のあるエンティティタイトルを改善するためのテクニックがあります。
前のポイントに関連して、濃縮する際のソースのより良い検証のために、それが元のエンティティに接続されていることを確認します。
ソースの深いブラウジングのサポート - エージェントがWebページをクリックして実際にコンテンツにドリルする必要がある場合があります。これは、たとえばARXIVの研究論文を検索する際に良い仕事をする必要があります。
データのストリーミングのサポート - リストが人口計算され、セルがUIでリアルタイムで濃縮されているのを見るのは驚くべきことです。現在、端末のログを見ることで、進歩の感覚を得ることができます。
これについてコラボレーションしたい場合、またはアイデアについて話し合いたい場合は、[email protected]にメールしたり、Twitterで私にメールしてください。


