deep seek
1.0.0
이것은 LLM 전동 인터넷 스케일 검색 엔진을 위한 새로운 실험 아키텍처입니다. 이 아키텍처는 현재 연구 에이전트와 매우 다르며, 이는 응답 엔진 으로 설계되었습니다.
여기에는 몇 가지 예를 볼 수 있습니다 : https://deep-seek.vercel.app/ (이렇게하면서 감당할 수 없기 때문에 실제 쿼리를 할 수 없습니까?)
두 개념의 주요 차이점은 다음과 같습니다.
답변 엔진의 최종 결과는 연구 보고서이며, 검색 엔진의 최종 결과는 검색 된 모든 엔티티와 풍부한 열이있는 테이블입니다.
최종 결과가 어떻게 보이는지 (스케일을 위해 확대) : 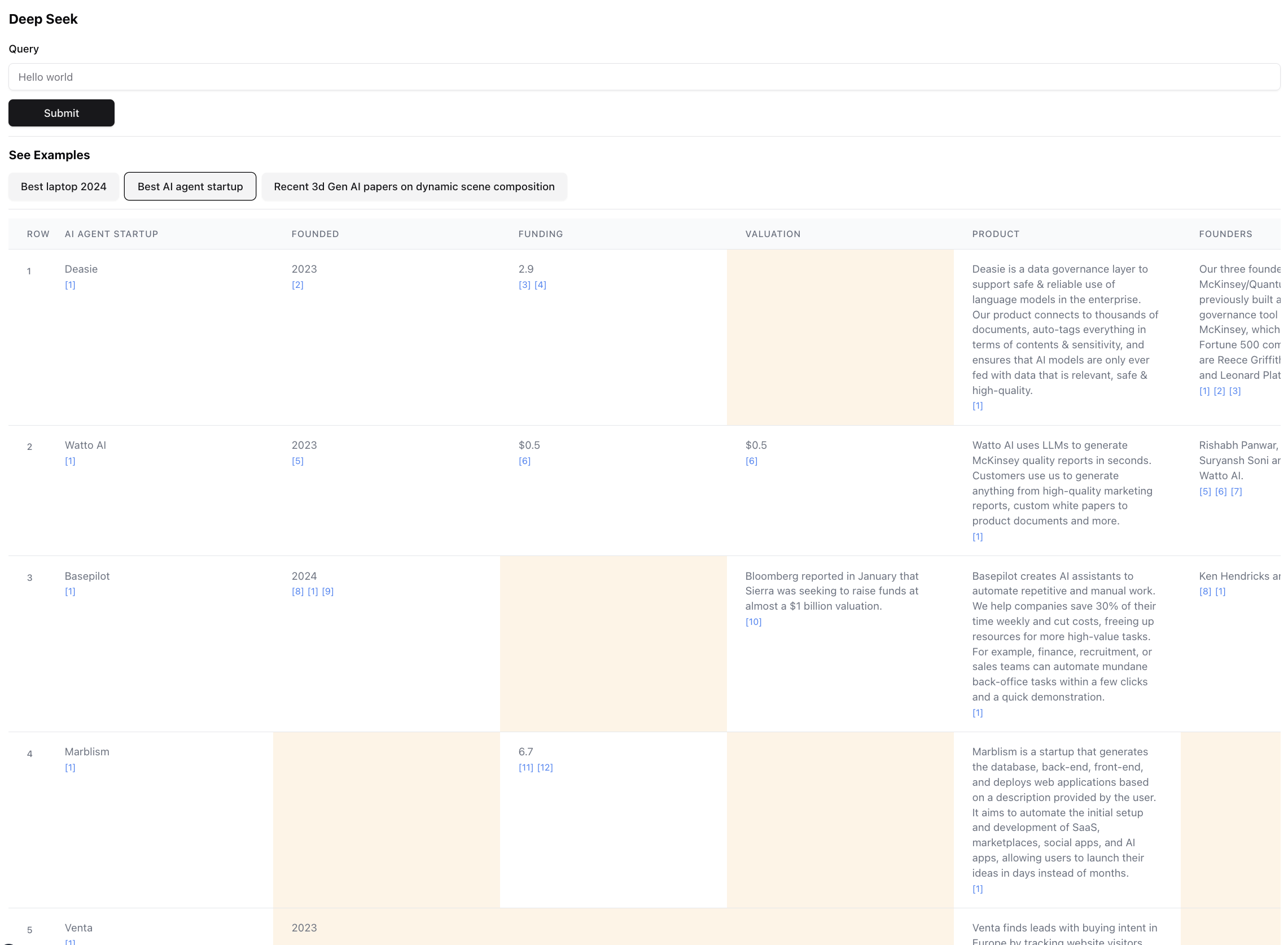
이것은이 쿼리의 결과의 작은 부분입니다. 실제 결과는 너무 커서 스크린 샷이 불가능합니다. 최종 결과에는 94 개의 레코드가 있으며, 356 개의 출처를 탐색 한 후 에이전트가 수집하고 풍부했습니다.
에이전트는 또한 테이블 셀의 데이터에 대한 신뢰 점수를 풍부하게 생성합니다. 노란색으로 강조 표시된 특정 세포가 있습니다.이 세포는 신뢰가 낮은 세포입니다. 이들은 출처가 충돌 할 수있는 경우이거나 소스가 전혀 없으므로 에이전트가 최선의 추측을했습니다. 이것은 실제로 0-1 사이의 숫자이므로, 더 높은 충실도로 점수를 보여줄 수있는 더 나은 창의적인 UI가있을 수 있습니다.
다음 패키지 관리자 중 하나를 설치하십시오
설치 지침에 따라 패키지 관리자 및 프로젝트 종속성을 설치하십시오.
개발자 서버를 실행하려면 패키지 관리자에 따라 다음 명령 중 하나를 사용하십시오.
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun dev브라우저를 사용하여 http : // localhost : 3000을 엽니 다. 이 예제는 실제로 에이전트를 실행하지 않으며 (많은 비용이 많이 든다), 결과를 검사 할 수 있도록 아키텍처의 힘과 결함을 보여줄 것이 더 많다.
환경 변수가 설정되어 있으면 직접 실행할 수 있습니다. 검색 된 엔티티 수와 풍부하게 필요한 데이터 금액에 따라 ~ 5 분이 소요되며 $ 0.1- $ 3 상당의 크레딧 사이의 비용이 소요될 수 있습니다.
에이전트를 실행할 때는 터미널을 확인하여 무대 뒤에서 일어나는 일의 로그를 확인하십시오.
인류 및 EXA 용 API 키가 있는지 확인하십시오.
.env 파일을 만들고 다음 환경 변수를 넣으십시오.
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
이 시스템은 다단계 연구 에이전트로 작동합니다. 초기 사용자 쿼리는 계획으로 나뉘며 답은 시스템을 통해 흐르면서 반복적으로 구성됩니다. 이 유형의 아키텍처의 또 다른 이름은 흐름 엔지니어링입니다.
연구 파이프 라인은 4 가지 주요 단계로 나뉩니다.
계획 - 사용자 쿼리를 기반으로 플래너는 최종 결과의 모양이 어떻게 보일지 구성합니다. 추출 할 엔티티의 유형과 결과 테이블의 다른 열을 정의함으로써이를 수행합니다. 열은 엔티티와 관련된 사용자의 쿼리와 관련된 추가 데이터를 나타냅니다.
검색 - 표준 키워드 검색 및 신경 검색을 모두 사용하여 처리 할 관련 컨텐츠를 찾습니다 (두 유형의 검색은 EXA에서 제공합니다). 키워드 검색은 찾을 수있는 엔티티 (예 : 리뷰, 목록 등)에 대해 이야기하는 사용자 생성 컨텐츠를 찾는 데 좋습니다. 신경 검색은 특정 실체 자체 (예 : 회사, 논문 등)를 찾는 데 능숙합니다.
추출 - 검색에서 발견 된 모든 컨텐츠는 LLM을 통해 처리되어 특정 엔티티 및 관련 내용을 추출합니다. 이것은 컨텐츠의 문장 (WinkNLP의 작은 언어 모델을 통해 분할) 사이에 특별 토큰이 삽입되는 곳을 테스트하는 새로운 기술을 통해 수행되며 LLM은 시작 및 엔드 토큰을 표시하여 추출 할 컨텐츠 범위를 정의해야합니다. 이것은 매우 빠르고 토큰 효율적입니다.
Enrich- 우리는 실제로이 더 큰 검색 에이전트 내에 더 작은 답변을 가지고 있으며, 그의 임무는 모든 엔티티의 플래너에 의해 정의 된 모든 열을 풍부하게하는 것입니다. 이것은 전체 프로세스에서 가장 시간이 많이 걸리는 부분이지만이 에이전트가 매우 철저한 이유이기도합니다.
다음은 작동 방식에 대한 자세한 흐름입니다. 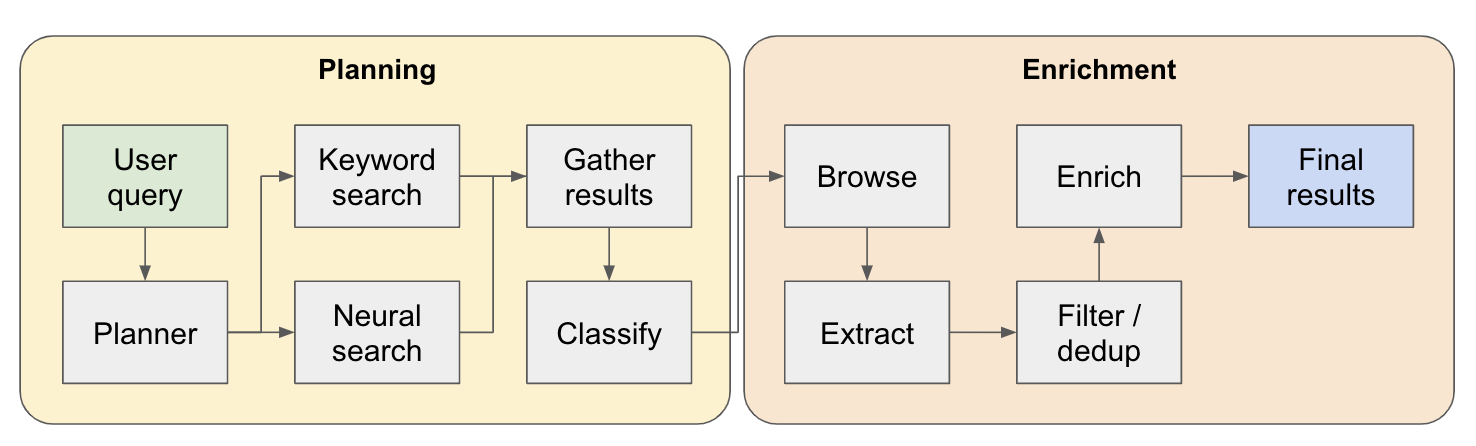
이 아키텍처를 탐색하는 사람이라면 누구의 경우 - 좋은 사용 사례를 찾으면 다른 사람들이 확인할 수 있도록 예제 목록에 추가하십시오! 예제의 모든 원시 데이터와 함께 app 아래에 examples.ts 파일이 있습니다. 쿼리가 실행을 마친 후 브라우저 콘솔을 통해 원시 데이터를 얻을 수 있습니다 (예제 파일에 복사).
관련성에 따라 검색된 엔티티를 정렬 / 순위 - 이는 "Best"또는 "최신"과 같은 예선이있는 쿼리에 특히 중요합니다. 이는 파이프 라인 끝에 추가 단계로 추가되어야합니다.
중복 된 엔티티를 감지하기위한 더 나은 엔티티 해상도 - 에이전트는 여전히 M2 대 M3 MacBook과 같은 것들에 의해 혼란스러워지기 때문에 때로는 더 나은 성능을 제공 할 수있는 더 나은 엔티티 타이틀을 형식화하는 기술이 있습니다.
이전 지점과 관련하여, 기관이 기관에 연결되도록 강화 될 때 소스의 더 나은 검증.
소스의 심층 탐색 지원 - 때로는 에이전트가 웹 페이지를 클릭하여 콘텐츠를 실제로 드릴링해야합니다. 예를 들어 ARXIV의 연구 논문을 검색하는 데 좋은 작업을 수행해야합니다.
데이터의 스트리밍 지원 - UI에서 실시간이 풍부한 목록 및 셀이 풍부한 목록을 보는 것은 놀라운 일입니다. 지금 당신은 터미널의 로그를 보면서만 진보를 얻을 수 있습니다.
이것에 대해 협력하거나 아이디어에 대해 토론하고 싶다면 [email protected]으로 이메일을 보내거나 Twitter에서 저를 핑하십시오.


