deep seek
1.0.0
Il s'agit d'une nouvelle architecture expérimentale pour un moteur de récupération à l'échelle Internet LLM. Cette architecture est très différente des agents de recherche actuels, qui sont conçus comme des moteurs de réponse .
Vous pouvez voir quelques exemples de résultats ici: https://deep-seek.vercel.app/ (notez que cela ne vous permettra pas de faire de vraies requêtes, car je ne pourrai pas vous le permettre?)
La principale différence entre les 2 concepts se décompose à:
Le résultat final d'un moteur de réponse est un rapport de recherche, le résultat final d'un moteur de récupération est un tableau avec toutes les entités récupérées et les colonnes enrichies.
Voici à quoi ressemble le résultat final (zoom arrière pour l'échelle): 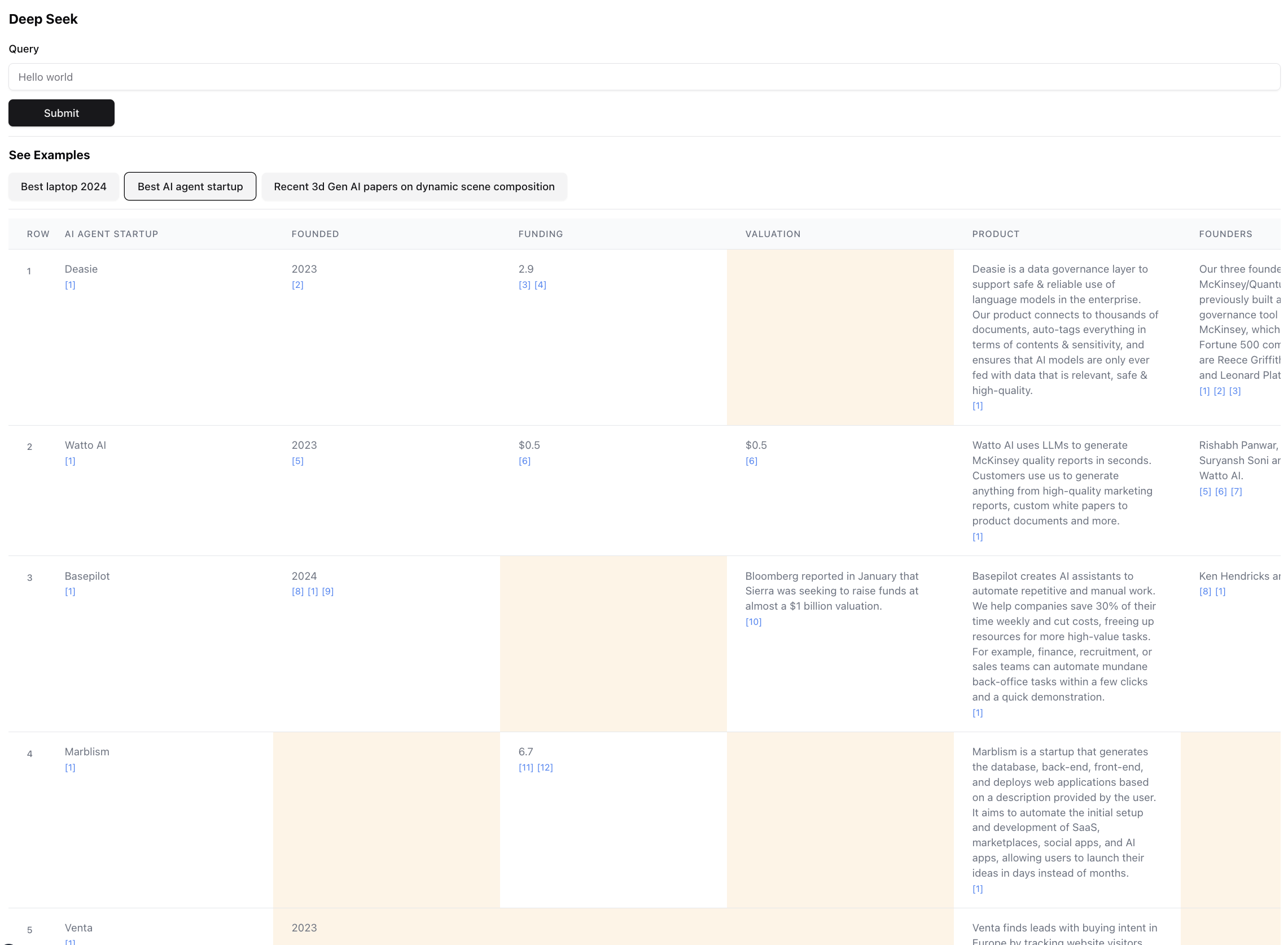
Ceci est en fait une petite partie du résultat pour cette requête. Le résultat réel est si grand qu'il est impossible de la capture d'écran. Il y a 94 records dans le résultat final, que l'agent a rassemblé et enrichi après avoir parcouru 356 sources.
L'agent génère également un score de confiance pour les données dans les cellules de la table tel qu'elle est enrichissante. Notez qu'il existe certaines cellules mises en évidence en jaune - ce sont des cellules à faible confiance. Ce sont des cas où les sources peuvent entrer en conflit, ou il n'y a pas de sources du tout, donc l'agent a fait une meilleure supposition. Il s'agit en fait d'un nombre entre 0 et 1, donc il peut certainement y avoir une interface utilisateur meilleure et plus créative pour présenter le score dans une fidélité plus élevée.
Installez l'un des gestionnaires de packages suivants
Suivez les instructions dans l'installation pour installer le gestionnaire de packages et les dépendances du projet
Pour exécuter le serveur de développement, utilisez l'une des commandes suivantes en fonction de votre gestionnaire de packages
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun devOuvrez http: // localhost: 3000 avec votre navigateur pour commencer à rechercher ou explorer les exemples pré-construits. Notez que les exemples ne gèrent pas réellement l'agent (il en coûte beaucoup de $), il est plus là pour montrer la puissance et les défauts de l'architecture en vous permettant d'inspecter les résultats.
Si vous avez les variables environnementales définies, vous pouvez l'exécuter par vous-même. Notez qu'il faut environ 5 min et pourrait coûter entre 0,1 $ et 3 $ de crédits, selon le nombre d'entités récupérées et le montant des données qui doivent être enrichies.
Lorsque vous exécutez l'agent, vérifiez le terminal pour voir des journaux de ce qui se passe dans les coulisses.
Assurez-vous d'avoir des clés d'API pour anthropic et exa.
Créez un fichier .env et placez les variables d'environnement suivantes:
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
Le système fonctionne comme un agent de recherche en plusieurs étapes. La requête utilisateur initiale est décomposée en un plan et la réponse est construite de manière itéralement lorsqu'elle traverse le système. Un autre nom pour ce type d'architecture est l'ingénierie de flux.
Le pipeline de recherche est divisé en 4 étapes principales:
Plan - En fonction de la requête utilisateur, le planificateur construit à quoi ressemblerait la forme du résultat final. Il le fait en définissant le type d'entité à extraire, ainsi que les différentes colonnes de la table résultante. Les colonnes représentent des données supplémentaires pertinentes pour la requête de l'utilisateur concernant les entités.
Recherche - Nous utilisons à la fois la recherche de mots clés standard et la recherche neuronale pour trouver du contenu pertinent pour traiter (les deux types de recherche sont fournis par EXA). La recherche de mots clés est excellente pour trouver du contenu généré par l'utilisateur en parlant des entités à trouver (par exemple, avis, listicles .. etc.). La recherche neuronale est excellente pour trouver elles-mêmes des entités spécifiques (par exemple, les entreprises, les articles .. etc.).
Extrait - Tout le contenu trouvé dans la recherche est traité via LLM pour extraire des entités spécifiques et son contenu associé. Cela se fait via une nouvelle technique que je teste où les jetons spéciaux sont insérés entre les phrases (divisé via le modèle de langage de WinkNLP) dans le contenu, et le LLM est chargé de définir la gamme de contenu à extraire en indiquant les jetons de démarrage et fin. C'est très rapide et efficace.
Enrich - nous avons en fait un agent de réponse plus petit au sein de cet agent de récupération plus grand, dont le travail consiste à enrichir toutes les colonnes définies par le planificateur de chaque entité. C'est la partie la plus longue de l'ensemble du processus, mais c'est aussi la raison pour laquelle cet agent est extrêmement complet.
Voici un flux plus détaillé de son fonctionnement: 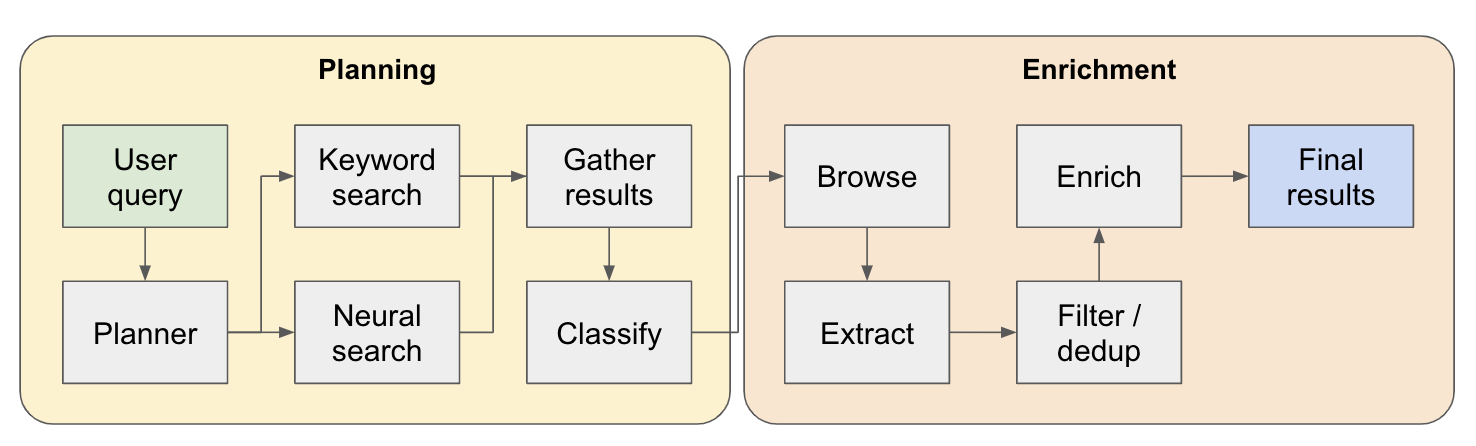
Pour quiconque explore cette architecture - si vous trouvez un bon cas d'utilisation ou intéressant, veuillez l'ajouter à la liste des exemples afin que d'autres personnes puissent le vérifier! Il existe un fichier examples.ts sous app avec toutes les données brutes des exemples. Vous pouvez obtenir les données brutes via la console du navigateur une fois la requête terminée en cours d'exécution (il suffit de le copier dans le fichier d'exemples).
Triage / classement les entités récupérées par pertinence - Ceci est particulièrement important pour les requêtes avec des qualifications comme "Best" ou "le plus récent" ... etc. Cela devrait être ajouté comme étape supplémentaire à la fin du pipeline.
Une meilleure résolution d'entités pour détecter les entités dupliquées - l'agent est toujours perplexe par des choses comme M2 vs M3 MacBooks Parfois, il existe des techniques pour mieux formater les titres d'entités qui pourraient conduire à de meilleures performances ici.
En rapport avec le point précédent, une meilleure vérification des sources lors de l'enrichissement pour s'assurer qu'elle est connectée à l'entité originale.
Prise en charge de la navigation profonde des sources - Parfois, l'agent doit cliquer sur la page Web pour vraiment percer le contenu, cela devra faire du bon travail pour rechercher des articles de recherche sur ArXIV, par exemple.
Prise en charge du streaming dans les données - il serait incroyable de voir la liste remplie et les cellules enrichies en temps réel dans l'interface utilisateur. En ce moment, vous ne pouvez avoir un sentiment de progrès en regardant les journaux sur le terminal.
Si vous souhaitez collaborer à ce sujet ou si vous souhaitez simplement discuter des idées, n'hésitez pas à m'envoyer un e-mail à [email protected] ou à me faire un cinglé sur Twitter.


