deep seek
1.0.0
Esta es una nueva arquitectura experimental para un motor de recuperación de escala de Internet alimentado por LLM. Esta arquitectura es muy diferente de los agentes de investigación actuales, que están diseñados como motores de respuesta .
Puede ver algunos resultados de ejemplo aquí: https://deep-seek.vercel.app/ (tenga en cuenta que esto no le permitirá hacer consultas reales, ya que no podré pagarlo.
La principal diferencia entre los 2 conceptos se rompe a:
El resultado final para un motor de respuestas es un informe de investigación, el resultado final para un motor de recuperación es una tabla con todas las entidades recuperadas y columnas enriquecidas.
Así es como se ve el resultado final (zoom a la escala): 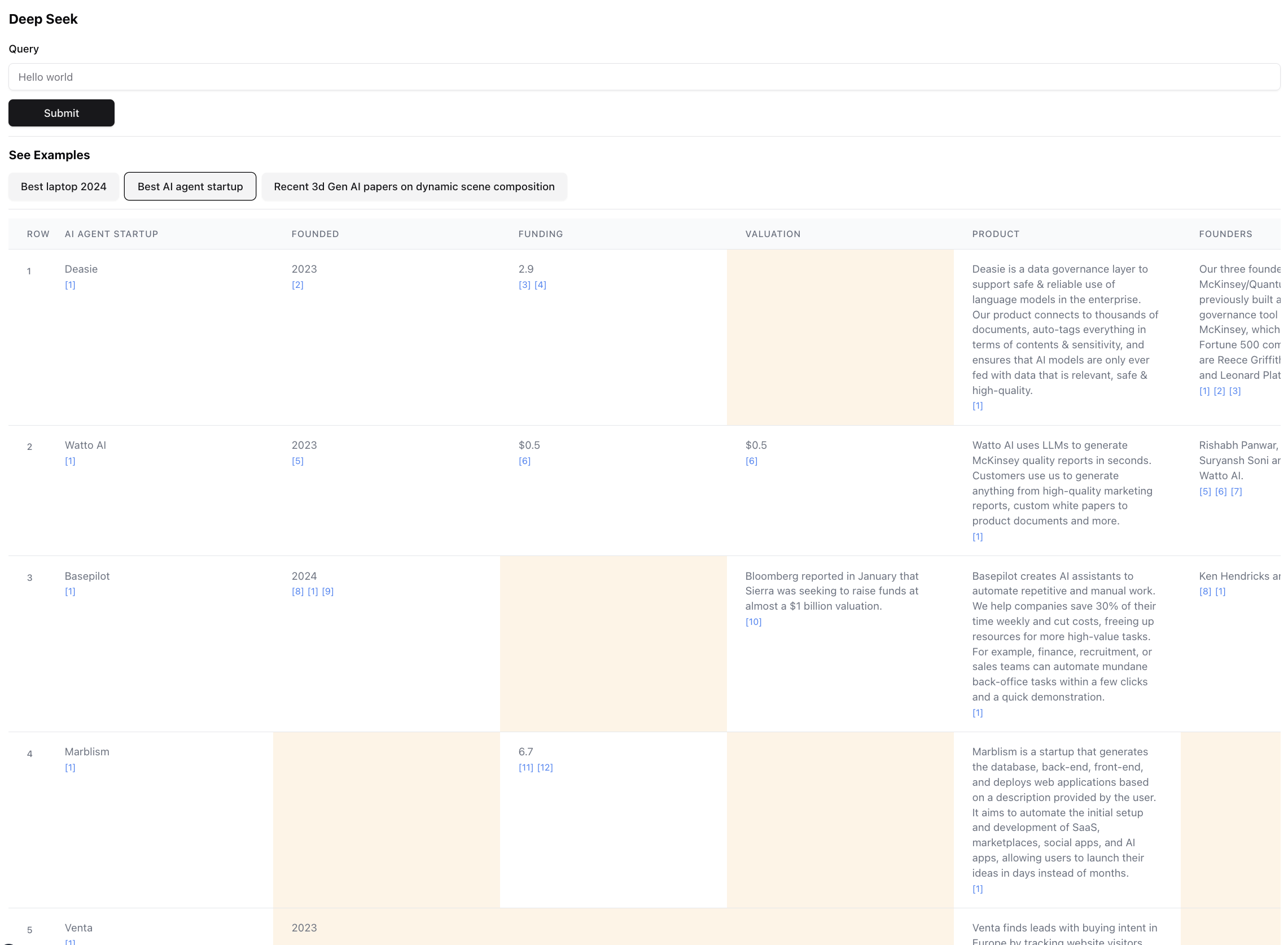
Esto es de hecho una pequeña porción del resultado para esta consulta. El resultado real es tan grande que es imposible capturar la captura de pantalla. Hay 94 registros en el resultado final, que el agente reunió y enriqueció después de navegar a través de 356 fuentes.
El agente también genera una puntuación de confianza para los datos en las celdas de la tabla, ya que está enriqueciendo. Tenga en cuenta que hay ciertas células destacadas en amarillo: esas son células con poca confianza. Esos son casos en los que las fuentes pueden entrar en conflicto, o no hay fuentes en absoluto, por lo que el agente hizo una mejor suposición. En realidad, este es un número entre 0 a 1, por lo que definitivamente puede haber una interfaz de usuario mejor y más creativa para mostrar el puntaje en una mayor fidelidad.
Instale cualquiera de los siguientes administradores de paquetes
Siga las instrucciones en la instalación para instalar el Administrador de paquetes y las dependencias del proyecto
Para ejecutar el servidor Dev, use uno de los siguientes comandos de acuerdo con su administrador de paquetes
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun devAbra http: // localhost: 3000 con su navegador para comenzar a buscar o explorar los ejemplos preconstruidos. Tenga en cuenta que los ejemplos en realidad no ejecutarán el agente (cuesta muchos $), está más allí para mostrar el poder y los defectos de la arquitectura al permitirle inspeccionar los resultados.
Si tiene el conjunto de variables de entorno, puede ejecutarlo por usted mismo. Tenga en cuenta que lleva ~ 5 minutos y podría costar entre $ 0.1 y $ 3 en créditos, dependiendo del número de entidades recuperadas y la cantidad de datos que deben enriquecerse.
Al ejecutar el agente, verifique la terminal para ver registros de lo que sucede detrás de escena.
Asegúrese de tener teclas API para antrópico y EXA.
Cree un archivo .env y coloque las siguientes variables de entorno:
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
El sistema funciona como un agente de investigación de varios pasos. La consulta de usuario inicial se divide en un plan y la respuesta se construye iteradamente a medida que fluye a través del sistema. Otro nombre para este tipo de arquitectura es la ingeniería de flujo.
La tubería de investigación se divide en 4 pasos principales:
Plan: basado en la consulta del usuario, el planificador construye cómo sería la forma del resultado final. Lo hace definiendo el tipo de entidad para extraer, así como las diferentes columnas en la tabla resultante. Las columnas representan datos adicionales que son relevantes para la consulta del usuario relacionada con las entidades.
Búsqueda: utilizamos tanto la búsqueda de palabras clave estándar como la búsqueda neuronal para encontrar contenido relevante para procesar (EXA proporciona ambos tipos de búsqueda). La búsqueda de palabras clave es excelente para encontrar contenido generado por el usuario que habla sobre las entidades que se encuentran (por ejemplo, revisiones, listas ... etc.). La búsqueda neuronal es excelente para encontrar entidades específicas (por ejemplo, compañías, documentos ... etc.).
Extracto: todo el contenido que se encuentra en la búsqueda se procesa a través de LLM para extraer entidades específicas y su contenido asociado. Esto se realiza a través de una nueva técnica que estoy probando dónde se insertan tokens especiales entre las oraciones (divididas a través del modelo de lenguaje pequeño de WinkNLP) en el contenido, y el LLM tiene la tarea de definir el rango de contenido para extraer indicando los tokens de inicio y finalización. Esto es súper rápido y token eficiente.
Enriquecer: en realidad tenemos un agente de respuesta más pequeño dentro de este agente de recuperación más grande, cuyo trabajo es enriquecer todas las columnas definidas por el planificador para cada entidad. Esta es la parte más lenta de todo el proceso, pero también es la razón por la cual este agente es extremadamente exhaustivo.
Aquí hay un flujo más detallado de cómo funciona: 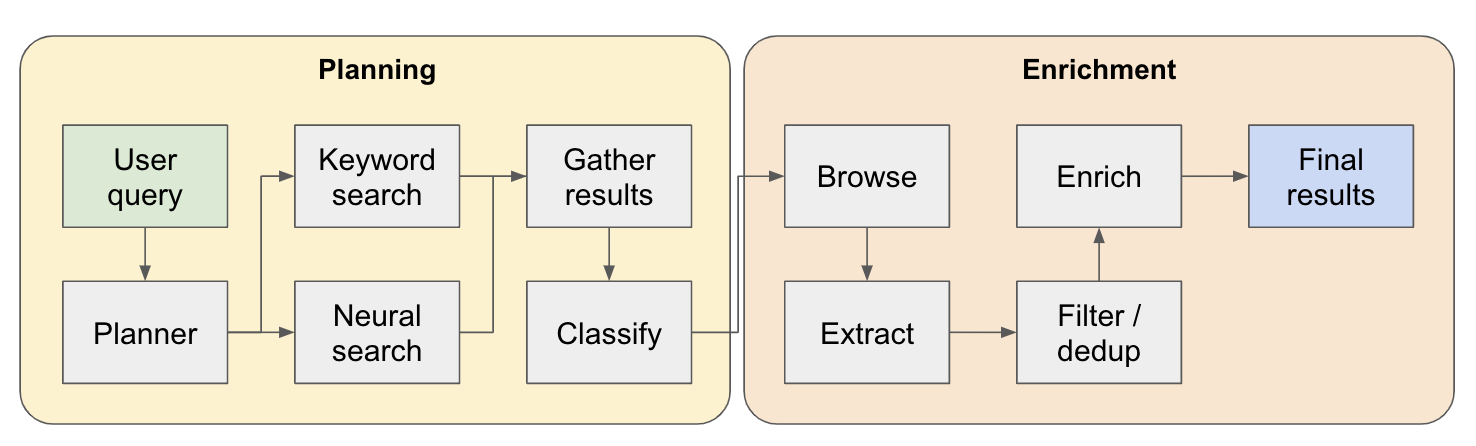
Para cualquiera que explique esta arquitectura: si encuentra un caso de uso bueno o interesante, agregue a la lista de ejemplos para que otras personas puedan verlo. Hay un archivo examples.ts en app con todos los datos sin procesar de los ejemplos. Puede obtener los datos sin procesar a través de la consola del navegador después de que una consulta haya terminado de ejecutarse (simplemente copie en el archivo de ejemplos).
Clasificación / clasificación de las entidades recuperadas por relevancia: esto es especialmente importante para consultas con calificadores como "mejor" o "más nuevo" ... etc. Esto debe agregarse como un paso adicional al final de la tubería.
Mejor resolución de la entidad para detectar entidades duplicadas: el agente aún se queda perplejo por cosas como M2 vs M3 MacBooks a veces, hay técnicas para formatear mejor títulos de entidades que podrían conducir a un mejor rendimiento aquí.
Relacionado con el punto anterior, una mejor verificación de fuentes al enriquecer para asegurarse de que esté conectado a la entidad orginal.
Soporte para la navegación profunda de las fuentes: a veces, el agente debe hacer clic en la página web para perforar realmente el contenido, esto será necesario para hacer un buen trabajo al buscar trabajos de investigación en ARXIV, por ejemplo.
Soporte para la transmisión en los datos: sería sorprendente ver que la lista se poblara y las celdas se enriquecen en tiempo real en la UI. En este momento solo puede tener una sensación de progreso observando los registros en la terminal.
Si desea colaborar en esto o simplemente desea discutir ideas, no dude en enviarme un correo electrónico a [email protected] o ping en Twitter.


