deep seek
1.0.0
这是针对LLM动力互联网量表检索引擎的新实验体系结构。该体系结构与当前设计的研究代理有很大不同,后者被设计为答案引擎。
您可以在此处看到一些示例结果:https://deep-seek.vercel.app/(请注意,这不会让您进行真正的查询,因为我负担不起吗?)
两个概念之间的主要区别分解为:
答案引擎的最终结果是研究报告,检索引擎的最终结果是一张具有所有检索的实体和富含列的表。
这是最终结果的样子(缩放缩放): 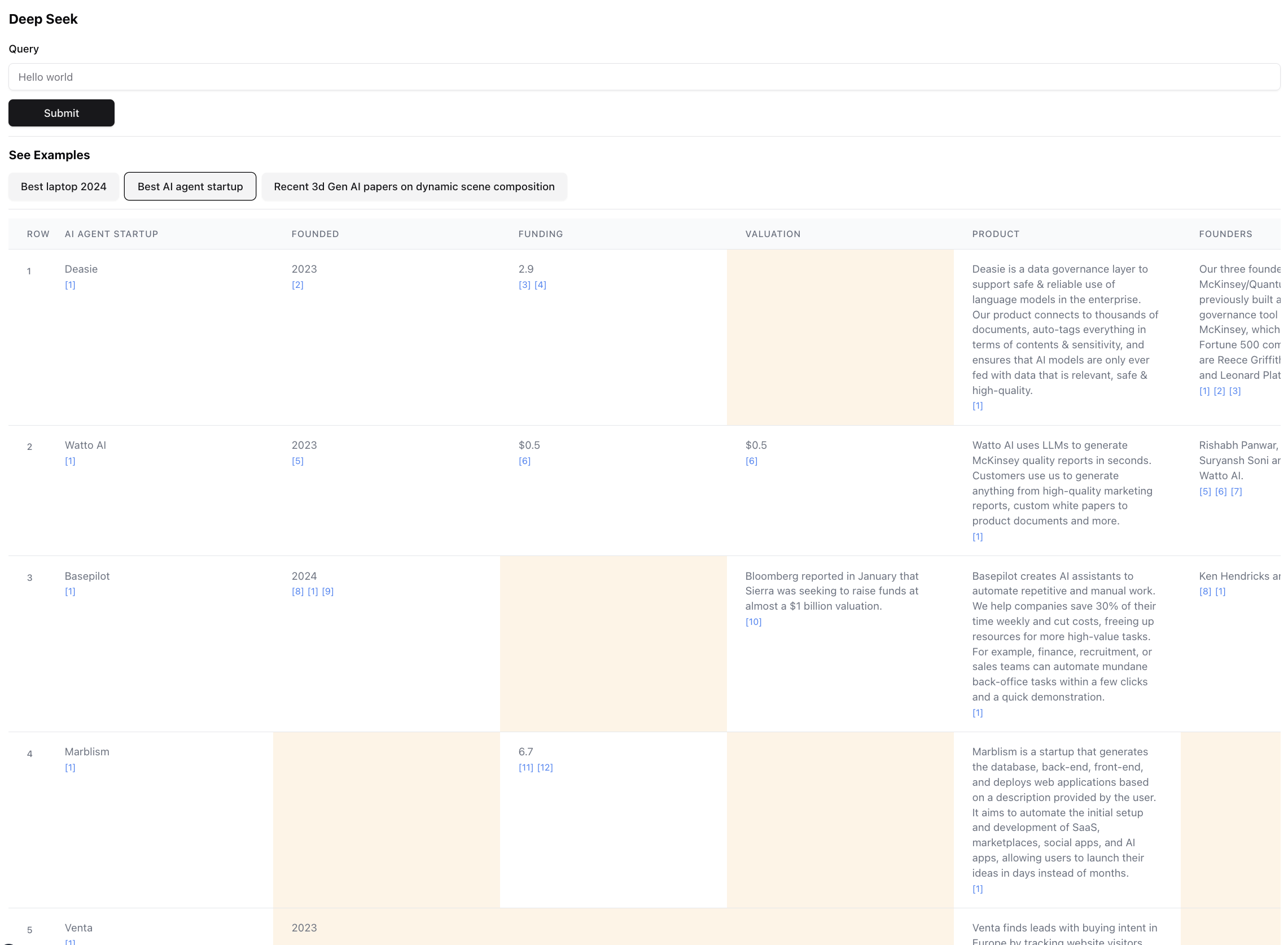
这是此查询结果的一小部分。实际结果是如此之大,以至于不可能屏幕截图。最终结果中有94个记录,代理商通过356个来源浏览后收集并丰富了这些记录。
该代理还会在表单元中生成数据富集时数据的置信得分。请注意,黄色突出显示了某些细胞 - 这些细胞是置信度较低的细胞。在这些情况下,来源可能会发生冲突,或者根本没有来源,因此代理商做出了最好的猜测。这实际上是0-1之间的数字,因此肯定可以有更好,更具创意的UI来展示更高的忠诚度的分数。
安装以下任何包装管理人员
按照安装中的说明安装软件包管理器和项目依赖项
要运行DEV服务器,请根据您的软件包管理器使用以下命令之一
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun dev打开http:// localhost:3000使用浏览器开始搜索或探索预构建的示例。请注意,这些示例实际上不会运行代理(花费很多$),通过让您检查结果来显示架构的功率和缺陷,更多的地方。
如果您设置了环境变量,则可以自己运行。请注意,这需要约5分钟,可能会在$ 0.1- $ 3的信用额之间花费,具体取决于检索到的实体数量和需要丰富的数据数量。
运行代理时,请检查终端以查看幕后发生的事情的日志。
确保您有拟人化和EXA的API键。
创建一个.ENV文件,然后放入以下环境变量:
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
该系统是多步研究代理。初始的用户查询被分解为一个计划,答案在整个系统流动时迭代构建。这种类型的体系结构的另一个名称是流程工程。
研究管道分为4个主要步骤:
计划 - 根据用户查询,计划者构建了最终结果的形状。它通过定义提取的实体的类型以及结果表中的不同列来做到这一点。这些列表示与用户与实体有关的查询相关的其他数据。
搜索 - 我们同时使用标准关键字搜索和神经搜索来查找相关的内容(两种类型的搜索均由EXA提供)。关键字搜索非常擅长查找用户生成的内容,讨论要找到的实体(例如评论,列表等)。神经搜索非常擅长寻找特定实体本身(例如公司,文件等)。
提取 - 通过LLM处理搜索中的所有内容,以提取特定实体及其相关内容。这是通过我正在测试的新技术完成的,其中在内容中插入句子(通过WinkNLP的小语言模型拆分)的特殊令牌,而LLM的任务是定义用于提取的内容范围,以指示启动和结束代币。这是超快速且有效的。
ENRICH-我们实际上确实在这个较大的检索代理中有一个较小的答案代理,其工作是丰富了每个实体为计划者定义的所有列。这是整个过程中最耗时的部分,但这也是该代理非常彻底的原因。
这是其工作原理的更详细的流程: 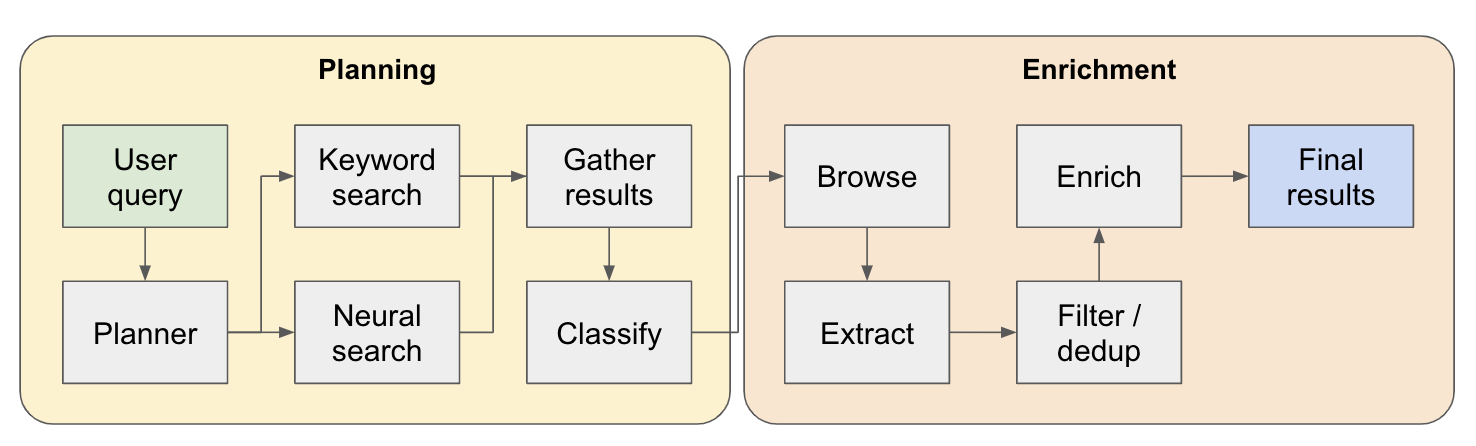
对于任何探索此架构的人 - 如果您发现一个好的或有趣的用例,请将其添加到示例列表中,以便其他人可以检查一下!在app下有一个examples.ts文件,其中包含示例的所有原始数据。查询完成运行后,您可以通过浏览器控制台获取原始数据(只需将其复制到示例文件中)即可。
通过相关性对检索到的实体进行排序 /排名 - 这对于具有“最佳”或“最新”等预选赛的查询尤为重要。
更好的实体解决方案来检测重复的实体 - 有时候,代理商仍然被M2 VS M3 MacBook之类的东西所困扰,有一些技术可以使更好的格式实体标题可以在这里导致更好的性能。
与上几点有关,在富集时更好地验证源以确保其连接到原始实体。
支持来源的深度浏览 - 有时代理应该单击网页以真正介绍内容,例如,这是在搜索有关ARXIV的研究论文时做得很好的。
支持数据中流媒体的支持 - 令人惊讶的是,在UI中实时丰富了列表的列表和单元格。现在,您只能通过观看终端上的日志来获得进度感。
如果您想对此进行合作或只是想讨论想法,请随时通过[email protected]给我发送电子邮件或在Twitter上ping我。


