deep seek
1.0.0
Ini adalah arsitektur eksperimental baru untuk mesin pengambilan skala internet bertenaga LLM. Arsitektur ini sangat berbeda dari agen penelitian saat ini, yang dirancang sebagai mesin jawaban .
Anda dapat melihat beberapa contoh hasil di sini: https://deep-seek.vercel.app/ (perhatikan bahwa ini tidak akan memungkinkan Anda melakukan pertanyaan nyata, karena saya tidak akan mampu membelinya?)
Perbedaan utama antara 2 konsep rusak menjadi:
Hasil akhir untuk mesin jawaban adalah laporan penelitian, hasil akhir untuk mesin pengambilan adalah tabel dengan semua entitas yang diambil dan kolom yang diperkaya.
Inilah hasil akhirnya (diperbesar untuk skala):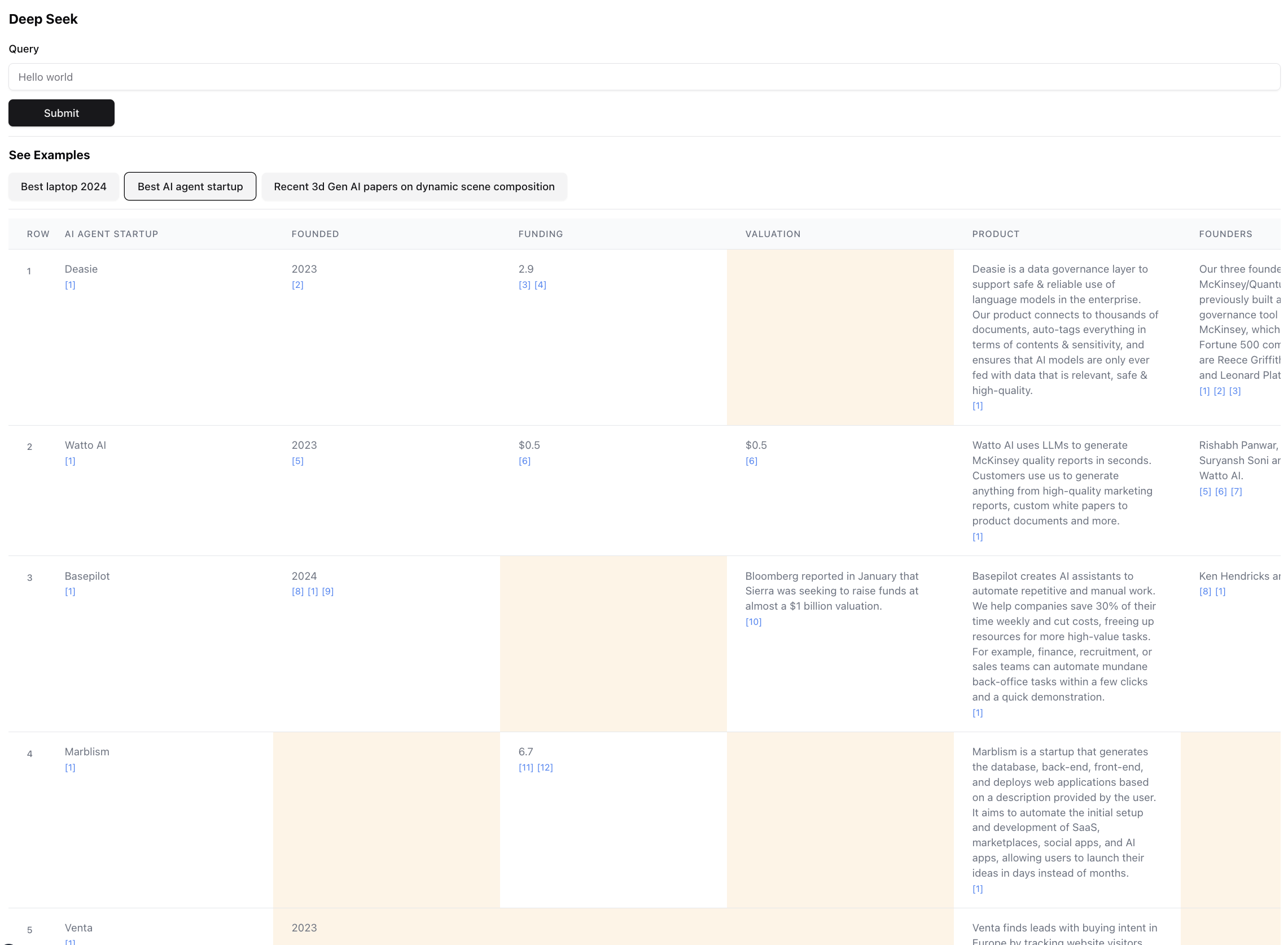
Ini adalah bagian kecil dari hasil untuk kueri ini. Hasil sebenarnya sangat besar sehingga tidak mungkin untuk tangkapan layar. Ada 94 catatan dalam hasil akhir, yang dikumpulkan oleh agen & diperkaya setelah menjelajah melalui 356 sumber.
Agen juga menghasilkan skor kepercayaan diri untuk data dalam sel tabel karena memperkaya. Perhatikan bahwa ada sel -sel tertentu yang disorot dengan warna kuning - itu adalah sel dengan kepercayaan diri rendah. Itulah kasus di mana sumber dapat bertentangan, atau tidak ada sumber sama sekali sehingga agen membuat tebakan terbaik. Ini sebenarnya angka antara 0 - 1, sehingga pasti ada UI yang lebih baik & lebih kreatif untuk menampilkan skor dalam kesetiaan yang lebih tinggi.
Instal salah satu dari manajer paket berikut
Ikuti instruksi di Install untuk menginstal Paket Manajer dan dependensi proyek
Untuk menjalankan server dev, gunakan salah satu perintah berikut sesuai dengan manajer paket Anda
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun devBuka http: // localhost: 3000 dengan browser Anda untuk mulai mencari atau menjelajahi contoh pra-dibangun. Perhatikan bahwa contoh -contoh tersebut tidak akan benar -benar menjalankan agen (harganya banyak $), lebih banyak di sana untuk menunjukkan kekuatan dan kekurangan arsitektur dengan membiarkan Anda memeriksa hasilnya.
Jika Anda memiliki variabel lingkungan yang ditetapkan, Anda dapat menjalankannya sendiri. Perhatikan bahwa dibutuhkan ~ 5 menit dan bisa menelan biaya antara kredit senilai $ 0,1 - $ 3, tergantung pada jumlah entitas yang diambil dan jumlah data yang perlu diperkaya.
Saat menjalankan agen, periksa terminal untuk melihat log tentang apa yang terjadi di balik layar.
Pastikan Anda memiliki kunci API untuk antropik dan exa.
Buat file .env, dan masukkan variabel lingkungan berikut:
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
Sistem ini berfungsi sebagai agen penelitian multi-langkah. Kueri pengguna awal dipecah menjadi rencana dan jawabannya dibangun dengan itu saat mengalir melalui sistem. Nama lain untuk jenis arsitektur ini adalah rekayasa aliran.
Pipa penelitian dibagi menjadi 4 langkah utama:
Plan - Berdasarkan kueri pengguna, perencana membangun seperti apa bentuk hasil akhir. Ini melakukan ini dengan mendefinisikan jenis entitas untuk mengekstrak, serta kolom yang berbeda dalam tabel yang dihasilkan. Kolom mewakili data tambahan yang relevan untuk kueri pengguna yang berkaitan dengan entitas.
Pencarian - Kami menggunakan pencarian kata kunci standar dan pencarian saraf untuk menemukan konten yang relevan untuk diproses (kedua jenis pencarian disediakan oleh EXA). Pencarian kata kunci sangat bagus untuk menemukan konten yang dibuat pengguna berbicara tentang entitas yang akan ditemukan (misalnya ulasan, listicles .. dll). Pencarian saraf sangat bagus dalam menemukan entitas spesifik itu sendiri (misalnya perusahaan, makalah .. dll).
Ekstrak - Semua konten yang ditemukan dalam pencarian diproses melalui LLM untuk mengekstraksi entitas tertentu dan konten yang terkait. Ini dilakukan melalui teknik baru yang saya uji di mana token khusus dimasukkan di antara kalimat (dibagi melalui model bahasa kecil Winknlp) dalam konten, dan LLM ditugaskan untuk mendefinisikan kisaran konten untuk mengekstrak dengan menunjukkan token start & end. Ini sangat cepat & token efisien.
Engrich - Kami benar -benar memiliki agen jawaban yang lebih kecil dalam agen pengambilan yang lebih besar ini, yang tugasnya adalah memperkaya semua kolom yang ditentukan oleh perencana untuk setiap entitas. Ini adalah bagian yang paling memakan waktu dari seluruh proses, tetapi juga alasan mengapa agen ini sangat teliti.
Berikut aliran yang lebih rinci tentang cara kerjanya: 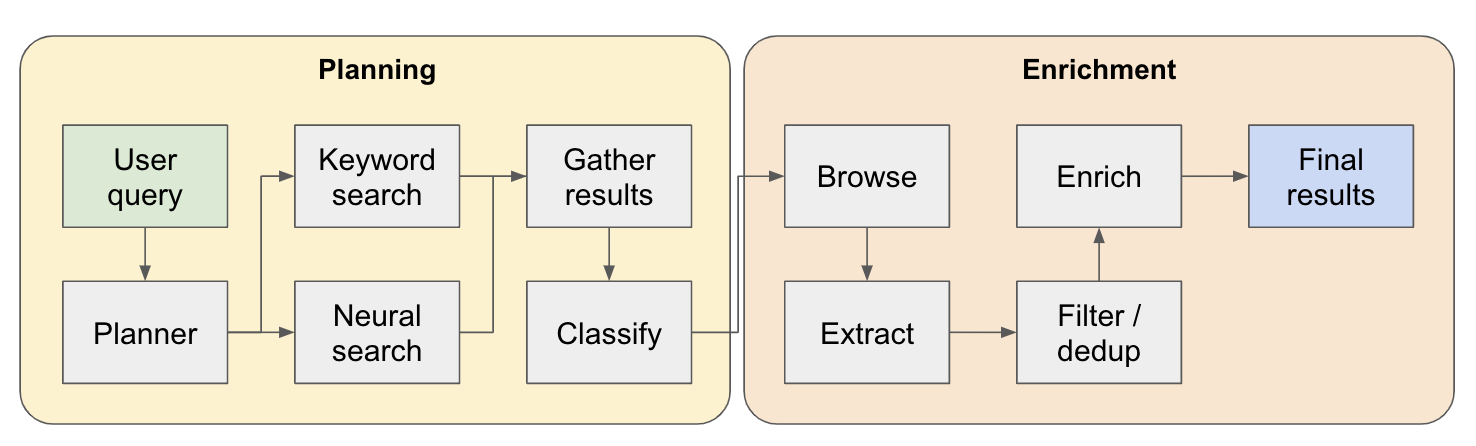
Untuk siapa pun yang menjelajahi arsitektur ini - jika Anda menemukan kasus penggunaan yang baik atau menarik, silakan tambahkan ke daftar contoh sehingga orang lain dapat memeriksanya! Ada file examples.ts di bawah app dengan semua data mentah dari contoh. Anda bisa mendapatkan data mentah melalui konsol browser setelah kueri selesai berjalan (cukup salin ke file contoh).
Menyortir / Peringkat entitas yang diambil berdasarkan relevansi - Ini sangat penting untuk pertanyaan dengan kualifikasi seperti "terbaik" atau "terbaru" ... dll. Ini harus ditambahkan sebagai langkah tambahan di akhir pipa.
Resolusi entitas yang lebih baik untuk mendeteksi entitas yang digandakan - agen masih bingung oleh hal -hal seperti M2 vs M3 MacBooks kadang -kadang, ada teknik untuk judul entitas format yang lebih baik yang dapat mengarah pada kinerja yang lebih baik di sini.
Terkait dengan poin sebelumnya, verifikasi sumber yang lebih baik ketika memperkaya untuk memastikan bahwa itu terhubung ke entitas orginal.
Dukungan untuk penelusuran sumber yang dalam - Terkadang agen harus mengklik di sekitar halaman web untuk benar -benar mengebor konten, ini akan diminta untuk melakukan pekerjaan yang baik dalam mencari melalui makalah penelitian tentang ARXIV, misalnya.
Dukungan untuk streaming dalam data - akan luar biasa untuk melihat daftar yang diisi & sel -sel yang diperkaya secara real -time di UI. Saat ini Anda hanya bisa merasakan kemajuan dengan menonton log di terminal.
Jika Anda ingin berkolaborasi dalam hal ini atau hanya ingin membahas ide, jangan ragu untuk mengirim email kepada saya di [email protected] atau Ping saya di Twitter.


