deep seek
1.0.0
Esta é uma nova arquitetura experimental para um mecanismo de recuperação em escala da Internet LLM. Essa arquitetura é muito diferente dos agentes de pesquisa atuais, projetados como mecanismos de resposta .
Você pode ver alguns resultados de exemplo aqui: https://deep-seek.vercel.app/ (observe que isso não permite fazer consultas reais, já que não poderei pagar?)
A principal diferença entre os 2 conceitos se decompõe para:
O resultado final para um mecanismo de resposta é um relatório de pesquisa, o resultado final para um mecanismo de recuperação é uma tabela com todas as entidades recuperadas e colunas enriquecidas.
Aqui está como é o resultado final (ampliado para escala):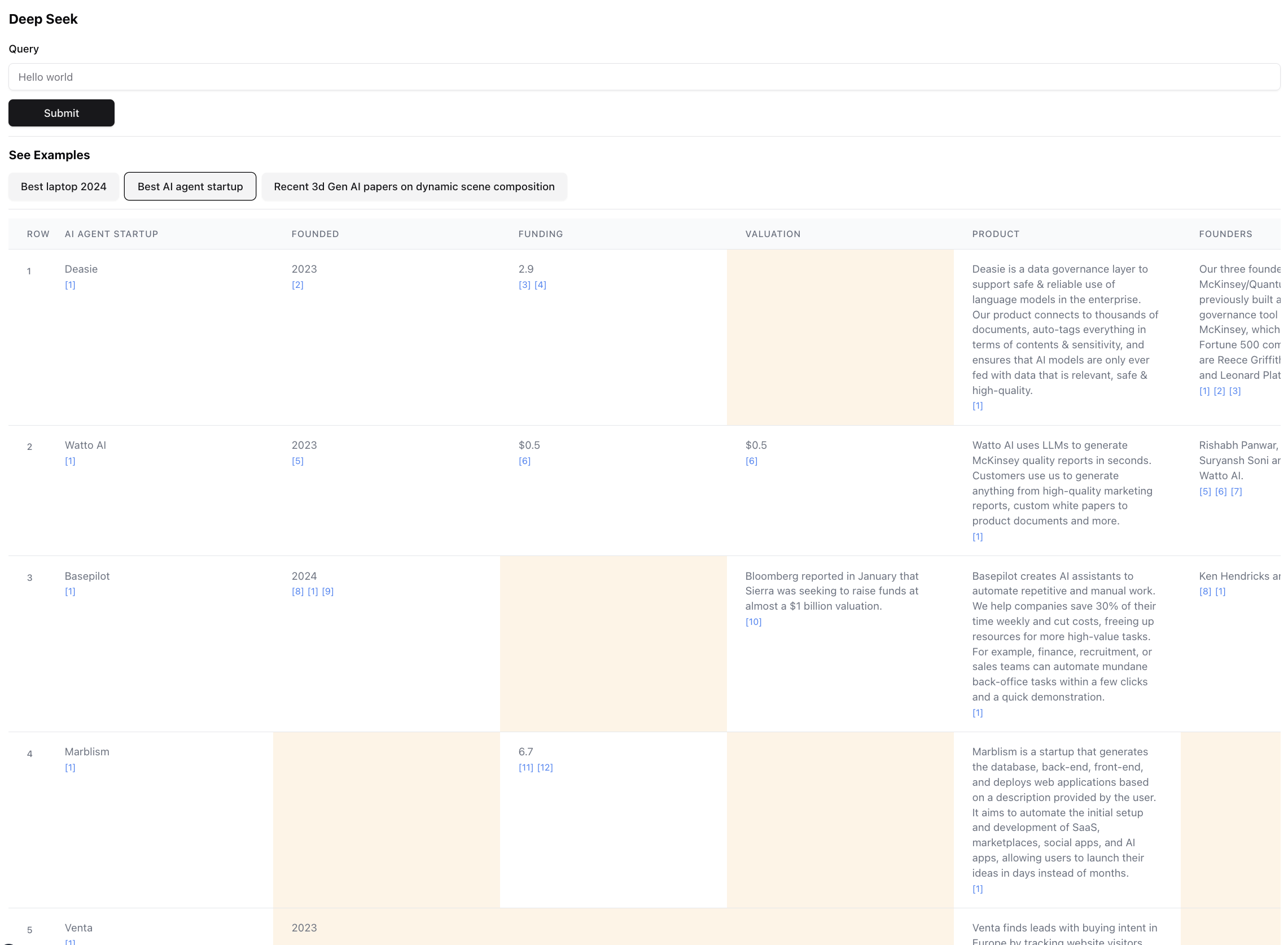
Esta é uma pequena parte do resultado desta consulta. O resultado real é tão grande que é impossível capturar capturas de tela. Existem 94 registros no resultado final, que o agente reuniu e enriqueceu após navegar por 356 fontes.
O agente também gera uma pontuação de confiança para os dados nas células da tabela, pois são enriquecedores. Observe que existem certas células destacadas em amarelo - essas são células com baixa confiança. Esses são os casos em que as fontes podem entrar em conflito, ou não há fontes, então o agente fez o melhor palpite. Na verdade, este é um número entre 0 e 1, então pode definitivamente haver uma interface do usuário melhor e mais criativa para mostrar a pontuação em fidelidade mais alta.
Instale qualquer um dos seguintes gerentes de pacotes
Siga as instruções no Install para instalar o gerenciador de pacotes e as dependências do projeto
Para executar o servidor dev, use um dos seguintes comandos de acordo com o seu gerenciador de pacotes
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun devAbrir http: // localhost: 3000 com o navegador para começar a pesquisar ou explorar os exemplos pré-criados. Observe que os exemplos não executam o agente (custa muito US $), é mais lá para mostrar o poder e as falhas da arquitetura, permitindo que você inspecione os resultados.
Se você tiver as variáveis de ambiente definidas, poderá executá -lo por si mesmo. Observe que leva ~ 5 min e pode custar entre US $ 0,1 e US $ 3 em créditos, dependendo do número de entidades recuperadas e da quantidade de dados que precisam ser enriquecidos.
Ao executar o agente, verifique o terminal para ver os registros do que está acontecendo nos bastidores.
Certifique -se de ter teclas de API para antropia e exa.
Crie um arquivo .env e coloque as seguintes variáveis de ambiente:
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
O sistema funciona como um agente de pesquisa em várias etapas. A consulta inicial do usuário é dividida em um plano e a resposta é construída iteradamente à medida que flui pelo sistema. Outro nome para esse tipo de arquitetura é a engenharia de fluxo.
O pipeline de pesquisa é dividido em 4 etapas principais:
Plano - Com base na consulta do usuário, o planejador constrói como seria a forma do resultado final. Faz isso definindo o tipo de entidade a extrair, bem como as diferentes colunas na tabela resultante. As colunas representam dados adicionais relevantes para a consulta do usuário relacionada às entidades.
Pesquisa - Usamos a pesquisa de palavras -chave padrão e a pesquisa neural para encontrar conteúdo relevante para processo (ambos os tipos de pesquisa são fornecidos pelo EXA). A pesquisa de palavras -chave é ótima para encontrar o conteúdo gerado pelo usuário falando sobre as entidades a serem encontradas (por exemplo, análises, listículas .. etc.). A busca neural é ótima em encontrar entidades específicas (por exemplo, empresas, artigos .. etc).
Extrato - Todo o conteúdo encontrado na pesquisa é processado via LLM para extrair entidades específicas e seu conteúdo associado. Isso é feito por meio de uma nova técnica que estou testando onde os tokens especiais são inseridos entre as frases (divididas por meio do modelo de linguagem pequeno do WinkNLP) no conteúdo, e o LLM é encarregado de definir a gama de conteúdo para extrair, indicando os tokens Start & End. Isso é super rápido e eficiente em termos de token.
Enriqueça - Na verdade, temos um agente de resposta menor nesse agente de recuperação maior, cujo trabalho é enriquecer todas as colunas definidas pelo planejador para todas as entidades. Esta é a parte mais demorada de todo o processo, mas também é a razão pela qual esse agente é extremamente completo.
Aqui está um fluxo mais detalhado de como funciona: 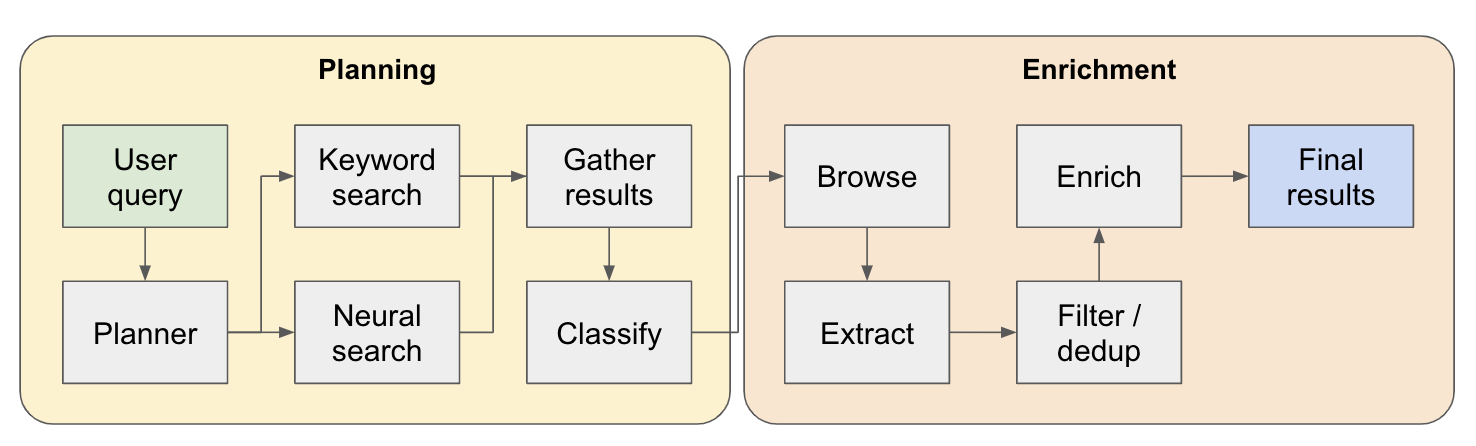
Para quem explora essa arquitetura - se você encontrar um caso de uso bom ou interessante, adicione -o à lista de exemplos para que outras pessoas possam conferir! Há um arquivo examples.ts no app com todos os dados brutos dos exemplos. Você pode obter os dados brutos via console do navegador depois que uma consulta terminar de executar (basta copiar -os no arquivo de exemplos).
Classificação / classificação das entidades recuperadas por relevância - isso é especialmente importante para consultas com qualificadores como "Melhor" ou "mais recente" ... etc. Isso deve ser adicionado como uma etapa adicional no final do pipeline.
Melhor resolução da entidade para detectar entidades duplicadas - o agente ainda é perplexo por coisas como M2 vs M3 MacBooks às vezes, existem técnicas para melhor formatar títulos de entidades que podem levar a um melhor desempenho aqui.
Relacionado ao ponto anterior, melhor verificação de fontes ao enriquecer para garantir que ele esteja conectado à entidade orginal.
Suporte para a navegação profunda de fontes - Às vezes, o agente deve clicar na página da web para realmente perfurar o conteúdo, isso será obrigado a fazer um bom trabalho na pesquisa de trabalhos de pesquisa sobre o ARXIV, por exemplo.
Suporte ao streaming nos dados - seria incrível ver a lista preenchida e as células sendo enriquecidas em tempo real na interface do usuário. No momento, você só pode ter uma sensação de progresso assistindo aos logs no terminal.
Se você deseja colaborar sobre isso ou apenas quiser discutir idéias, sinta -se à vontade para me enviar um e -mail para [email protected] ou me ping no Twitter.


