deep seek
1.0.0
Это новая экспериментальная архитектура для двигателя поиска интернет -шкалы LLM. Эта архитектура сильно отличается от текущих исследований, которые разработаны в качестве двигателей ответов .
Вы можете увидеть некоторые примеры результатов здесь: https://deep-seek.vercel.app/ (обратите внимание, что это не позволит вам выполнить реальные вопросы, так как я не смогу себе это позволить?)
Основное различие между двумя понятиями распадается до:
Конечным результатом для ответного двигателя является исследовательский отчет, конечным результатом для двигателя поиска является таблица со всеми извлеченными объектами и обогащенными столбцами.
Вот как выглядит конечный результат (масштабирован для масштаба): 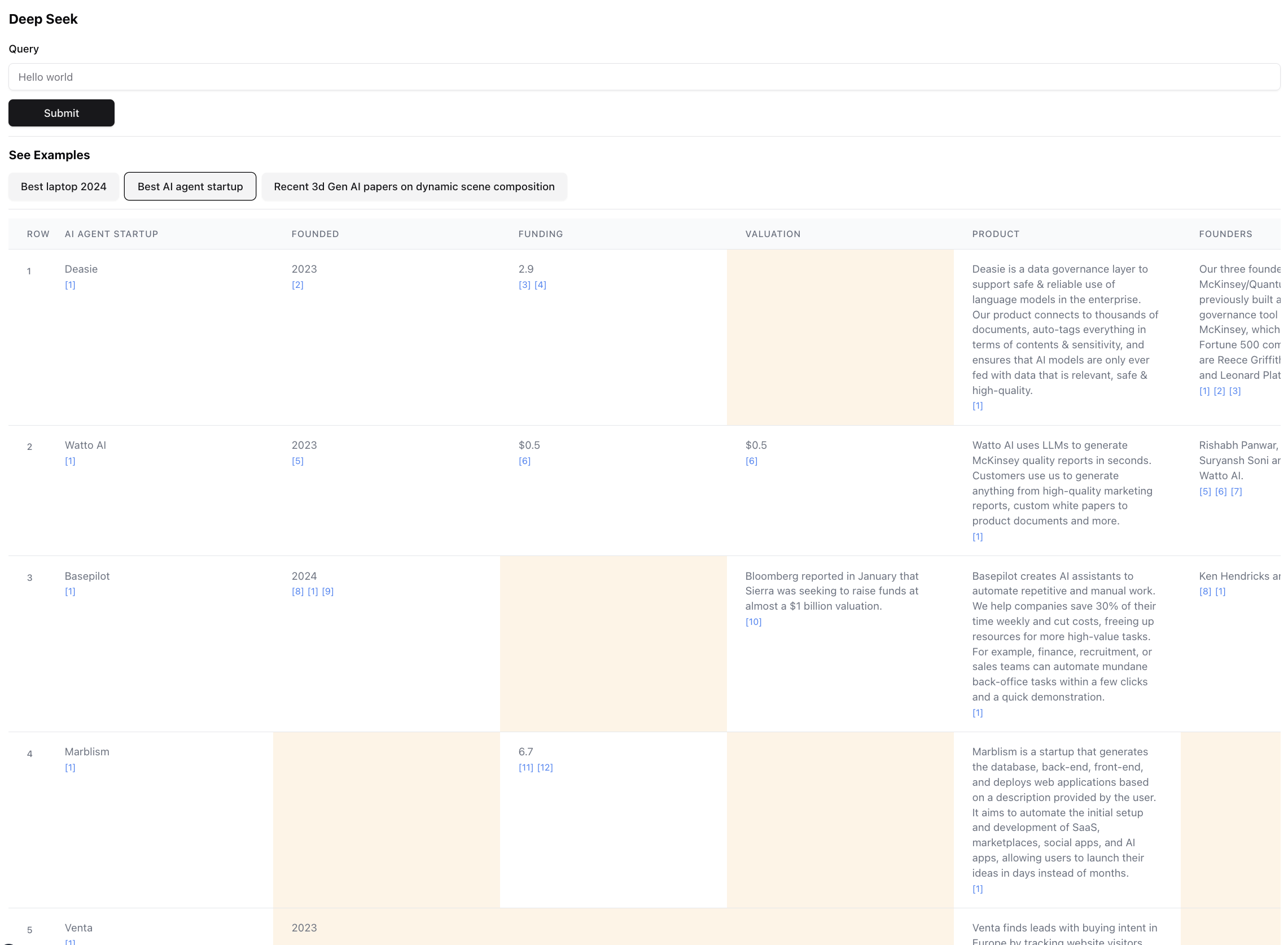
Это фактически небольшая часть результата для этого запроса. Фактический результат настолько велик, что экранинг невозможно. В конечном результате есть 94 записи, которые агент собрал и обогатил после просмотра 356 источников.
Агент также генерирует достоверную оценку для данных в ячейках таблицы по мере его обогащения. Обратите внимание, что определенные клетки выделены в желтом цвете - это клетки с низкой уверенностью. Это случаи, когда источники могут конфликтовать, или нет никаких источников, поэтому агент сделал лучшее предположение. На самом деле это число от 0 до 1, поэтому, безусловно, может быть лучше и более креативный пользовательский интерфейс, чтобы продемонстрировать счет в более высокой верности.
Установите любой из следующих менеджеров пакетов
Следуйте инструкциям в установке, чтобы установить диспетчер пакетов и зависимости проекта
Чтобы запустить Dev Server, используйте одну из следующих команд в соответствии с диспетчера пакетов
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun devОткройте http: // localhost: 3000 с вашим браузером, чтобы начать поиск или изучить предварительно созданные примеры. Обратите внимание, что примеры фактически не будут запускать агента (он стоит много $), это больше, чтобы показать силу и недостатки архитектуры, позволяя вам проверить результаты.
Если у вас установлены переменные среды, вы можете запустить ее для себя. Обратите внимание, что это занимает ~ 5 минут и может стоить от 0,1 до 3 долл. США кредитов, в зависимости от количества извлеченных организаций и объема данных, которые необходимо обогащены.
При запуске агента проверьте терминал, чтобы увидеть журналы того, что происходит за кулисами.
Убедитесь, что у вас есть ключи API для антропного и EXA.
Создайте файл .ENV и поместите следующие переменные среды:
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
Система работает как многоэтапный исследовательский агент. Первоначальный пользовательский запрос разбивается на план, и ответ построен итерательно, когда он течет через систему. Другим названием для этого типа архитектуры является инженерия потока.
Исследовательский трубопровод разделен на 4 основных этапа:
План - на основе пользовательского запроса, планировщик строит, как будет выглядеть форма конечного результата. Это происходит путем определения типа сущности для извлечения, а также различных столбцов в полученной таблице. Столбцы представляют дополнительные данные, которые актуальны для запроса пользователя, относящегося к объектам.
Поиск - мы используем как стандартный поиск ключевых слов, так и нейронный поиск для поиска соответствующего контента для обработки (оба типа поиска предоставляются ESA). Поиск ключевых слов отлично подходит для поиска контента, сгенерированного пользователем, рассказывающих о объектах, которые можно найти (например, обзоры, списки ... и т. Д.). Нейронный поиск отлично подходит для поиска самих отдельных организаций (например, компании, документы и т. Д.).
Извлечение - весь контент, найденной в поиске, обрабатывается через LLM для извлечения конкретных объектов и связанного с ним содержимого. Это делается с помощью новой методики, которую я проверяю, где между предложениями вставлены специальные токены (разделенные через небольшую языковую модель Winknlp), и LLM поручено определять диапазон контента для извлечения, указав токены начала и конечного. Это очень быстро и эффективно.
Enrich - у нас на самом деле есть меньший агент ответов в этом большем поиске, задача которой состоит в том, чтобы обогатить все столбцы, определенные планировщиком для каждого сущности. Это самая трудоемкая часть всего процесса, но это также причина, по которой этот агент чрезвычайно тщательный.
Вот более подробный поток того, как это работает: 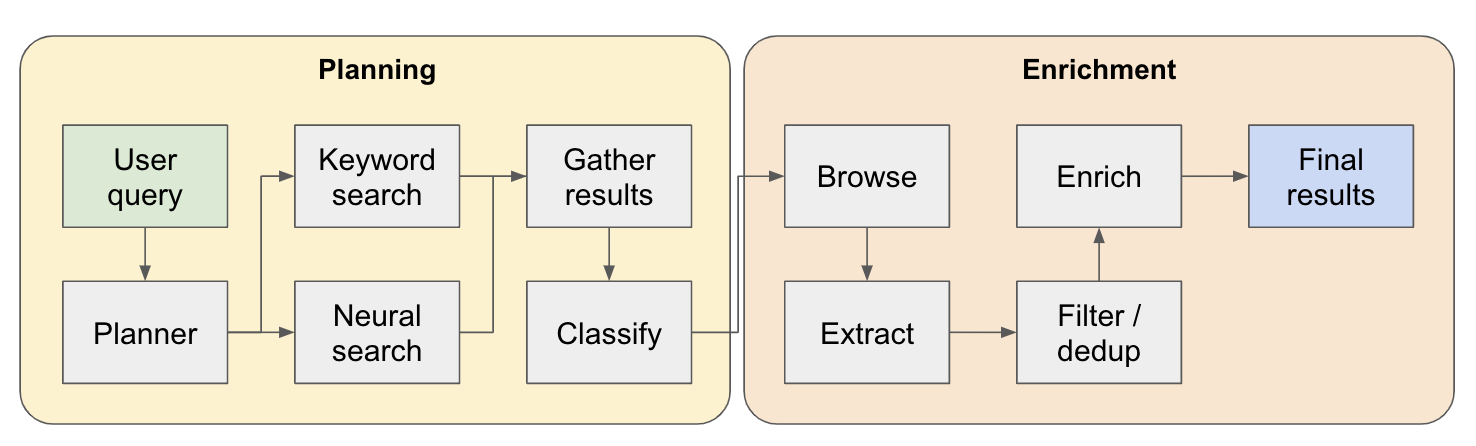
Для тех, кто изучает эту архитектуру - если вы найдете хороший или интересный вариант использования, добавьте ее в список примеров, чтобы другие люди могли это проверить! В app есть файл examples.ts . Вы можете получить необработанные данные через консоли браузера после завершения запроса (просто скопируйте их в файл примеров).
Сортировка / ранжирование полученных объектов по релевантности - это особенно важно для запросов с такими квалификаторами, как «лучшие» или «новейшие» ... и т. Д. Это должно быть добавлено в качестве дополнительного шага в конце трубопровода.
Лучшее разрешение сущности. Для обнаружения дублированных сущностей - агент по -прежнему попадает в тупик, такие как M2 против M3 Macbook, есть методы для лучшего формата объектов, которые могут привести к лучшей производительности здесь.
Связанный с предыдущим пунктом, лучшая проверка источников при обогащении, чтобы убедиться, что она подключена к организации.
Поддержка глубокого просмотра источников. Иногда агент должен щелкнуть по веб -странице, чтобы действительно бурить в контенте, например, это будет необходимо выполнить хорошую работу по поиску исследовательских работ по ARXIV.
Поддержка потоковой передачи в данных - было бы удивительно видеть, как список населения и ячейки обогащены в реальном времени в пользовательском интерфейсе. Прямо сейчас вы можете получить чувство прогресса, только просмотрев журналы на терминале.
Если вы хотите сотрудничать по этому вопросу или просто хотите обсудить идеи, не стесняйтесь написать мне по электронной почте по адресу [email protected] или пинг меня в Twitter.


