deep seek
1.0.0
Dies ist eine neue experimentelle Architektur für eine LLM -Abruf -Engine im Internet Scale. Diese Architektur unterscheidet sich stark von aktuellen Forschungsagenten, die als Antwortmotoren konzipiert sind.
Sie können hier einige Beispielergebnisse sehen: https://deep-seek.vercel.app/ (Beachten Sie, dass Sie diese keine echten Fragen durchführen lassen, da ich es mir nicht leisten kann?)
Der Hauptunterschied zwischen den 2 Konzepten bricht auf:
Das Endergebnis für eine Antwortmotor ist ein Forschungsbericht. Das Endergebnis für eine Abrufmotor ist eine Tabelle mit allen abgerufenen Einheiten und angereicherten Spalten.
So sieht das Endergebnis aus (nach Maßstab vergrößert): 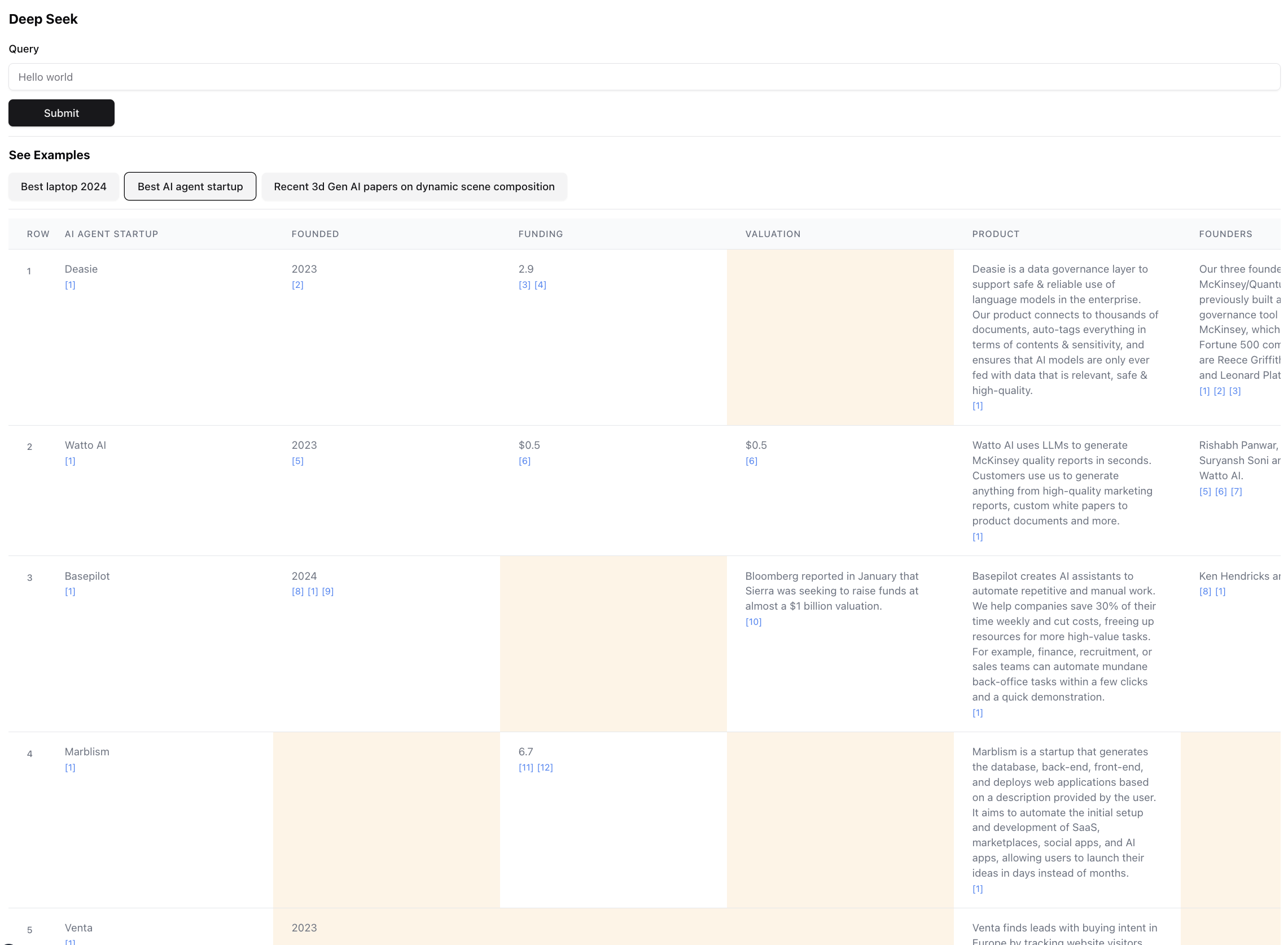
Dies ist eine kleine Teil des Ergebniss für diese Abfrage. Das tatsächliche Ergebnis ist so groß, dass es unmöglich ist, Screenshot zu erstellen. Es gibt 94 Aufzeichnungen im Endergebnis, die der Agent nach dem Durchsuchen von 356 Quellen gesammelt und angereichert hat.
Das Agent erzeugt auch eine Vertrauensbewertung für die Daten in den Tabellenzellen, da diese angereichert sind. Beachten Sie, dass bestimmte Zellen gelb hervorgehoben sind - das sind Zellen mit geringem Vertrauen. Dies sind Fälle, in denen die Quellen konfliktfrei sind, oder es gibt überhaupt keine Quellen, daher machte der Agent die beste Vermutung. Dies ist tatsächlich eine Zahl zwischen 0 und 1, sodass es definitiv eine bessere und kreativere Benutzeroberfläche geben kann, um die Punktzahl in höherer Treue zu präsentieren.
Installieren Sie einen der folgenden Paketmanager
Befolgen Sie die Anweisungen in der Installation, um den Paketmanager und die Projektabhängigkeiten zu installieren
Verwenden Sie, um den Dev -Server auszuführen, einen der folgenden Befehle gemäß Ihrem Paketmanager
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun devÖffnen Sie http: // localhost: 3000 mit Ihrem Browser, um die vorgefertigten Beispiele zu suchen oder zu erkunden. Beachten Sie, dass die Beispiele den Agenten nicht tatsächlich ausführen (es kostet viel $), es ist mehr da, die Kraft und die Mängel der Architektur zu zeigen, indem Sie die Ergebnisse überprüfen können.
Wenn Sie die Umgebungsvariablen festlegen, können Sie sie selbst ausführen. Beachten Sie, dass es ~ 5 min dauert und zwischen 0,1 und 3 US -Dollar kosten, abhängig von der Anzahl der abgerufenen Unternehmen und der Datenmenge, die angereichert werden müssen.
Überprüfen Sie beim Ausführen des Agenten das Terminal, um Protokolle dessen zu sehen, was hinter den Kulissen passiert.
Stellen Sie sicher, dass Sie API -Schlüssel für Anthropic und Exa haben.
Erstellen Sie eine .env -Datei und geben Sie die folgenden Umgebungsvariablen ein:
ANTHROPIC_KEY="anthropic_api_key"
EXA_KEY="exa_api_key"
Das System arbeitet als mehrstufiger Forschungsagent. Die anfängliche Benutzerabfrage wird in einen Plan unterteilt und die Antwort wird iterat erstellt, wenn sie durch das System fließt. Ein anderer Name für diese Art von Architektur ist Flow Engineering.
Die Forschungspipeline ist in 4 Hauptschritte aufgeteilt:
Plan - Basierend auf der Benutzerabfrage konstruiert der Planer, wie die Form des Endergebnisses aussehen würde. Dies geschieht, indem die Art der Entität sowie die verschiedenen Spalten in der resultierenden Tabelle definiert werden. Die Spalten stellen zusätzliche Daten dar, die für die Abfrage des Benutzers in Bezug auf die Entitäten relevant sind.
Suche - Wir verwenden sowohl Standard -Keywords -Suche als auch neuronale Suche, um relevante Inhalte zu finden, um zu verarbeiten (beide Sucharten werden von EXA bereitgestellt). Die Keyword -Suche ist hervorragend darin, benutzergenerierte Inhalte zu finden, die über die zu findenen Entitäten sprechen (z. B. Bewertungen, Listen .. usw.). Die neuronale Suche ist hervorragend darin, selbst bestimmte Unternehmen selbst zu finden (z. B. Unternehmen, Papiere .. usw.).
Extrakt - Alle in der Suche gefundenen Inhalte werden über LLM verarbeitet, um bestimmte Entitäten und die zugehörigen Inhalte zu extrahieren. Dies geschieht über eine neue Technik, die ich teste, wo spezielle Token zwischen Sätzen (über das kleine Sprachmodell von Winknlp) in den Inhalt eingefügt werden, und das LLM wird beauftragt, den Inhaltsbereich zu definieren, indem es die Start- und End -Token angibt. Dies ist super schnell und tokeneffizient.
Enrich - Wir haben tatsächlich einen kleineren Antwortagenten in diesem größeren Abrufagent, dessen Aufgabe es ist, alle vom Planer definierten Spalten für jedes Unternehmen zu bereichern. Dies ist der zeitaufwändigste Teil des gesamten Prozesses, aber auch der Grund, warum dieser Agent extrem gründlich ist.
Hier ist ein detaillierterer Fluss, wie es funktioniert: 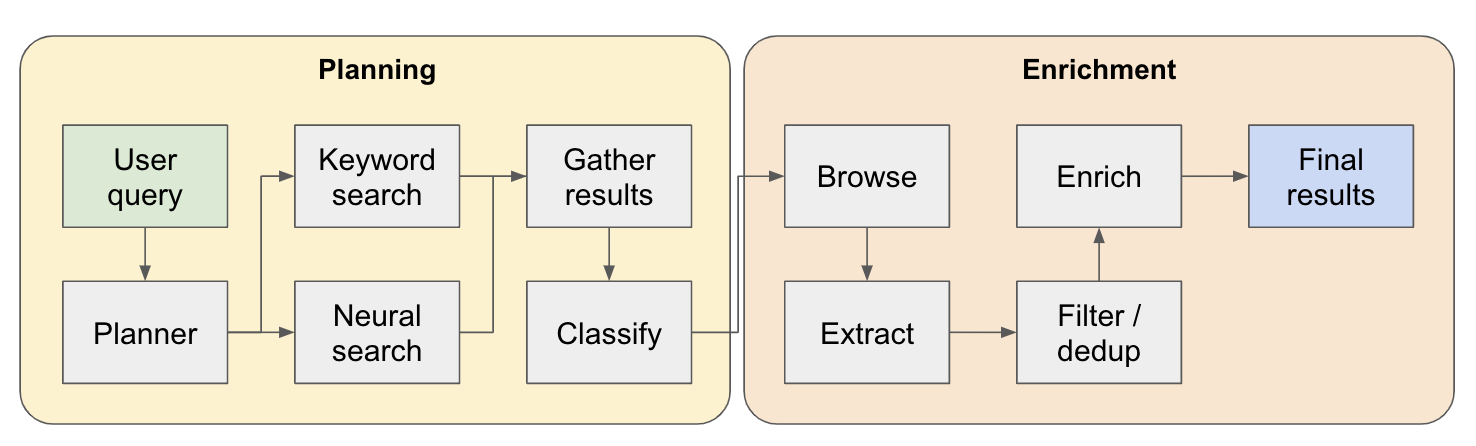
Für alle, die diese Architektur erkundet - wenn Sie einen guten oder interessanten Anwendungsfall finden, fügen Sie ihn bitte der Beispielliste hinzu, damit andere Personen ihn überprüfen können! Es gibt eine examples.ts -Datei unter app mit allen Rohdaten der Beispiele. Sie können die Rohdaten über die Browserkonsole abrufen, nachdem eine Abfrage ausgeführt wurde (kopieren Sie sie einfach in die Beispieldatei).
Sortieren / Ranking der abgerufenen Einheiten nach Relevanz - Dies ist besonders wichtig für Abfragen mit Qualifikationsgebern wie "Best" oder "neuest" ... usw. Dies sollte als zusätzlicher Schritt am Ende der Pipeline hinzugefügt werden.
Bessere Entitätslösung zum Erkennen von doppelten Einheiten - Der Agent wird immer noch von Dingen wie M2 gegen M3 -MacBooks verblüfft. Manchmal gibt es Techniken, um bessere Entitätstitel zu formatieren, die hier zu einer besseren Leistung führen könnten.
Bezogen auf den vorherigen Punkt, eine bessere Überprüfung der Quellen bei der Anreicherung, um sicherzustellen, dass sie mit der orginalen Entität verbunden sind.
Unterstützung für das tiefgreifende Surfen von Quellen - Manchmal sollte der Agent auf der Webseite klicken, um den Inhalt wirklich zu bohren. Dies muss beispielsweise gute Arbeit bei der Suche durch Forschungsarbeiten auf Arxiv erledigen.
Unterstützung für das Streaming in den Daten - Es wäre erstaunlich zu sehen, dass die Liste der Liste in Echtzeit in der Benutzeroberfläche angereichert wird. Im Moment können Sie nur ein Gefühl des Fortschritts erzielen, indem Sie die Protokolle am Terminal ansehen.
Wenn Sie daran zusammenarbeiten möchten oder nur Ideen diskutieren möchten, können Sie mir gerne eine E -Mail an [email protected] senden oder mich auf Twitter pingen.


