langchain learning
1.0.0
langchain的學習筆記。依賴:
openai == 0.27 . 8
langchian == 0.0 . 225和langchain相類似的一些工具:
注意:由於langchain或langchain-ChatGLM的更新,可能導致部分源碼和講解的有所差異。
有的一些文章直接放的是一些鏈接,從網上收集整理而來。
目前基於langchain的中文項目有兩個:
我們從中可以學到不少。
一個優化的prompt對結果至關重要,感興趣的可以去看看這個。
yzfly/LangGPT: LangGPT: Empowering everyone to become a prompt expert! Structured Prompt,結構化提示詞。 (github.com):構建結構化的高質量prompt
雖然langchain給我們提供了一些便利,但是也存在一些問題:
無法解決大模型基礎技術問題,主要是prompt重用問題:首先很多大模型應用的問題都是大模型基礎技術的缺陷,並不是LangChain能夠解決的。其中核心的問題是大模型的開發主要工作是prompt工程。而這一點的重用性很低。但是,這些功能都需要非常定制的手寫prompt 。鏈中的每一步都需要手寫prompt。輸入數據必須以非常特定的方式格式化,以生成該功能/鏈步驟的良好輸出。設置DAG編排來運行這些鏈的部分只佔工作的5%,95%的工作實際上只是在提示調整和數據序列化格式上。這些東西都是不可重用的。
LangChain糟糕的抽象與隱藏的垃圾prompt造成開發的困難:簡單說,就是LangChain的抽象工作不夠好,所以很多步驟需要自己構建。而且LangChain內置的很多prompt都很差,不如自己構造,但是它們又隱藏了這些默認prompt。
LangChain框架很難debug :儘管LangChain很多方法提供打印詳細信息的參數,但是實際上它們並沒有很多有價值的信息。例如,如果你想看到實際的prompt或者LLM查詢等,都是十分困難的。原因和剛才一樣,LangChain大多數時候都是隱藏了自己內部的prompt。所以如果你使用LangChain開發效果不好,你想去調試代碼看看哪些prompt有問題,那就很難。
LangChain鼓勵工具鎖定:LangChain鼓勵用戶在其平台上進行開發和操作,但是如果用戶需要進行一些LangChain文檔中沒有涵蓋的工作流程,即使有自定義代理,也很難進行修改。這就意味著,一旦用戶開始使用LangChain,他們可能會發現自己被限制在LangChain的特定工具和功能中,而無法輕易地切換到其他可能更適合他們需求的工具或平台。
以上內容來自:
有時候一些簡單的任務,我們完全可以自己去實現相關的流程,這樣每一部分都由我們自己把控,更易於修改。
使用領域數據對LLM進行微調,受限於計算資源和模型參數的大小,而且模型會存在胡言亂語的情況。這裡面涉及到一系列的問題:
基本思路:
1、用戶提問:請對比下商品雅詩蘭黛特潤修護肌活精華露和SK-II護膚精華?
2、RouterChain問題路由,即使用哪種方式回答問題:(調用一次LLM)
3、使用Planner生成step:(調用一次LLM)
4、執行者Executer執行上述步驟:(調用steps次LLM,n是超參數表明調用的最大次數)
5、對所有的結果進行匯總。 (調用一次LLM)
相比於方案1,不使用工具,直接根據問題進行對數據庫進行檢索,然後對檢索到的結果進行回答。
檢索的方式可以是基於給定問題的關鍵字,使用ES工具從海量數據庫中檢索到可能存在答案的topk段落。把這topk個段落連同問題一起發送給LLM,進行回答。
檢索的方式改成向量的形式,先對所有已知資料按照300個字切分成小的段落,然後對這些段落進行編碼成向量,當用戶提問時,把用戶問題同樣編碼成向量,然後對這些段落進行檢索,得到topk最相關的段落,把這topk個段落連同問題一起發送給LLM,進行回答。
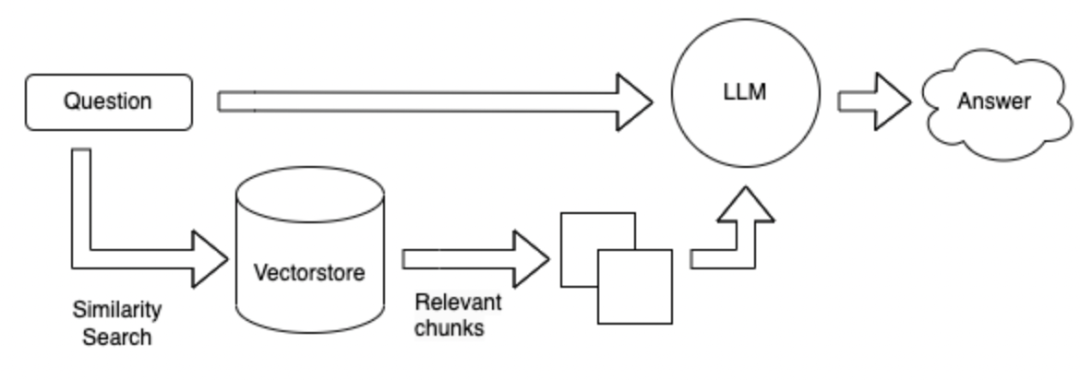
上述方法的優缺點:
領域微調LLM :需要耗費很多的人力收集領域內數據和問答對,需要耗費很多算力進行微調。
langchain + LLM + tools :是把LLM作為一個子的服務,LangChain作為計劃者和執行者的大腦,合適的時機調用LLM,優點是解決複雜問題,缺點是不可靠。 LLM生成根據問題和工具調用工具獲取數據時不可靠。可以不能很好的利用工具。可能不能按照指令調用合適的工具,還可能設定計劃差,難以控制。優點是:用於解決複雜的問題。
langchain + LLM + 檢索:優點是現在的領域內主流問答結構,缺點:是根據問題對可能包含答案的段落檢索時可能檢索不准。不適用於復雜問答
總結:最大的問題還是LLM本身:
LLM是整個系統的基座,目前還是有不少選擇的餘地的,網上開源了不少中文大語言模型,但大多都是6B/7B/13B的,要想有一個聰明的大腦,模型的參數量還是需要有保證的。
以上參考:https://mp.weixin.qq.com/s/FvRchiT0c0xHYscO_D-sdA
留出一些問題以待思考:可能和langchain相關,也可能和大模型相關
**怎麼根據垂直領域的數據選擇中文大模型? **1、是否可以商用。 2、根據各評測的排行版。 3、在自己領域數據上進行評測。 4、借鑒現有的垂直領域模型的選擇,比如金融大模型、法律大模型、醫療大模型等。
**數據的一個答案由一系列相連的句子構成,怎麼對文本進行切分以獲得完整的答案? **比如:
怎么能够解决失眠?
1 、保持良好的心情;
2 、进行适当的训练。
3 、可适当使用药物。1、盡量將劃分的文本的長度設置大一些。 2、為了避免答案被分割,可以設置不同段之間可以重複一定的文本。 3、檢索時可返回前top_k個文檔。 4、融合查詢出的多個文本,利用LLM進行總結。
怎麼構建垂直領域的embedding?
怎麼存儲獲得的embedding?
如何引導LLM更好的思考?可使用: chain of thoughts、self ask、ReAct ,具體介紹可以看這一篇文章:https://zhuanlan.zhihu.com/p/622617292 實際上,langchain中就使用了ReAct這一策略。
Introduction | ?️? Langchain
API Reference — ?? LangChain 0.0.229
https://mp.weixin.qq.com/s/FvRchiT0c0xHYscO_D-sdA
https://python.langchain.com.cn/docs/modules/agents/how_to/custom_llm_chat_agent


