langchain learning
1.0.0
Catatan Studi Langchain. mengandalkan:
openai == 0.27 . 8
langchian == 0.0 . 225Beberapa alat yang mirip dengan Langchain:
Catatan: Karena pembaruan Langchain atau Langchain-Catglm, beberapa kode sumber dan penjelasan mungkin berbeda.
Beberapa artikel secara langsung menempatkan tautan dan dikumpulkan dari internet.
Saat ini, ada dua proyek Cina berdasarkan Langchain:
Kita bisa belajar banyak darinya.
Propt yang dioptimalkan sangat penting untuk hasilnya.
YZFLY/LANGGPT: LANGGPT: Memberdayakan semua orang untuk menjadi ahli yang cepat! (github.com): Bangun propt berkualitas tinggi terstruktur
Meskipun Langchain memberi kita kenyamanan, ada juga beberapa masalah:
Masalah teknologi dasar model besar tidak dapat diselesaikan, terutama masalah penggunaan kembali propt : Pertama -tama, banyak masalah dalam model besar adalah cacat teknologi dasar model besar, dan bukan sesuatu yang dapat dipecahkan oleh Langchain. Masalah intinya adalah bahwa pekerjaan utama pengembangan model skala besar adalah rekayasa propt. Dan ini sangat dapat digunakan kembali. Namun, semua fitur ini membutuhkan propt tulisan tangan yang sangat disesuaikan . Setiap langkah dalam rantai membutuhkan propt tulisan tangan. Data input harus diformat dengan cara yang sangat spesifik untuk menghasilkan output yang baik untuk langkah fungsi/rantai. Menyiapkan orkestrasi DAG untuk menjalankan rantai ini hanya menyumbang 5% dari pekerjaan, dan 95% dari pekerjaan sebenarnya hanya pada penyesuaian yang diminta dan format serialisasi data. Hal -hal ini tidak dapat digunakan kembali .
Abstraksi Langchain yang buruk dan propt sampah tersembunyi menyebabkan kesulitan pengembangan : Sederhananya, pekerjaan abstraksi Langchain tidak cukup baik, begitu banyak langkah yang perlu dibangun sendiri. Selain itu, banyak alat peraga bawaan dari Langchain adalah buruk, jadi mereka tidak sebagus membangunnya sendiri, tetapi mereka menyembunyikan alat peraga default ini.
Kerangka kerja Langchain sulit untuk debug : Meskipun banyak metode Langchain memberikan parameter untuk mencetak informasi terperinci, mereka sebenarnya tidak memiliki banyak informasi yang berharga . Misalnya, sangat sulit jika Anda ingin melihat pertanyaan propt atau LLM yang sebenarnya. Alasannya sama seperti sebelumnya. Jadi, jika Anda menggunakan Langchain untuk berkembang dengan buruk dan Anda ingin men -debug kode untuk melihat petunjuk mana yang memiliki masalah, itu akan sulit.
Langchain mendorong penguncian alat : Langchain mendorong pengguna untuk mengembangkan dan beroperasi di platform mereka, tetapi jika pengguna perlu melakukan beberapa alur kerja yang tidak tercakup dalam dokumentasi Langchain, sulit untuk memodifikasi bahkan dengan proxy khusus. Ini berarti bahwa begitu pengguna mulai menggunakan Langchain, mereka mungkin menemukan diri mereka terbatas pada alat dan fitur spesifik langchain dan tidak dapat dengan mudah beralih ke alat atau platform lain yang mungkin lebih cocok untuk kebutuhan mereka.
Konten di atas berasal dari:
Kadang -kadang kita dapat menerapkan proses yang relevan untuk beberapa tugas sederhana sendiri, sehingga setiap bagian dikendalikan oleh diri kita sendiri dan lebih mudah dimodifikasi.
Penyetelan fine LLM menggunakan data domain dibatasi oleh ukuran sumber daya komputasi dan parameter model, dan model akan dikabarkan. Ini melibatkan serangkaian masalah:
Ide Dasar:
1. Pertanyaan Pengguna: Harap bandingkan produk Estee Laudert Soft Perbaikan Essence Perawatan Kulit dan Esensi Perawatan Kulit SK-II?
2. Perutean masalah routerchain, yaitu, bagaimana menjawab pertanyaan: (hubungi llm sekali)
3. Gunakan perencana untuk menghasilkan langkah: (hubungi llm sekali)
4. Eksekutor Executer menjalankan langkah -langkah di atas: (Langkah Panggilan LLM, N adalah hiperparameter yang menunjukkan jumlah maksimum panggilan)
5. Ringkasan semua hasil. (Hubungi LLM sekali)
Dibandingkan dengan Skema 1, tanpa menggunakan alat, database dicari secara langsung berdasarkan pertanyaan, dan kemudian hasil yang diambil dijawab.
Metode pencarian dapat didasarkan pada kata kunci dari pertanyaan yang diberikan, dan menggunakan alat ES untuk mengambil paragraf Topk dengan kemungkinan jawaban dari database besar. Kirim paragraf Topk ini bersama dengan pertanyaan ke LLM untuk dijawab.
Metode pencarian diubah ke bentuk vektor.
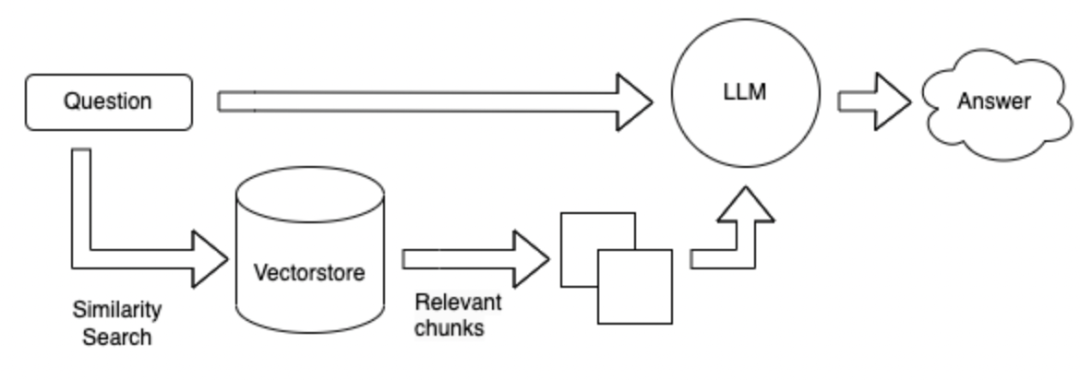
Keuntungan dan Kekurangan dari metode di atas:
Field Fine-Tuning LLM : Dibutuhkan banyak tenaga kerja untuk mengumpulkan data dan tanya jawab di lapangan, dan membutuhkan banyak daya komputasi untuk menyempurnakan.
Langchain + LLM + Tools : Ini adalah layanan yang mengambil LLM sebagai sub-layanan. Generasi LLM tidak dapat diandalkan saat memanggil alat berdasarkan masalah dan alat. Tidak dapat memanfaatkan alat dengan baik. Mungkin tidak mungkin untuk memanggil alat yang sesuai sesuai dengan instruksi, dan rencananya mungkin buruk dan sulit dikendalikan. Keuntungan adalah: digunakan untuk memecahkan masalah yang kompleks.
Langchain + LLM + Pencarian : Keuntungannya adalah struktur tanya jawab utama di bidang saat ini, dan kerugiannya adalah bahwa pencarian paragraf yang mungkin berisi jawaban mungkin tidak akurat ketika mencari jawaban berdasarkan pertanyaan. Tidak cocok untuk pertanyaan dan jawaban yang rumit
Ringkasan: Masalah terbesar adalah LLM sendiri:
LLM adalah dasar dari seluruh sistem, dan masih ada banyak pilihan yang tersedia.
Referensi di atas: https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
Tinggalkan beberapa pertanyaan untuk dipikirkan: mungkin terkait dengan langchain atau model besar
** Bagaimana memilih model besar Cina berdasarkan data di bidang vertikal? ** 1. 2. Menurut versi peringkat dari setiap ulasan. 3. Evaluasi data lapangan Anda sendiri. 4. Gambar dari model lapangan vertikal yang ada, seperti model keuangan, model hukum, model medis, dll.
** Jawaban untuk data terdiri dari serangkaian kalimat yang terhubung. **Misalnya:
怎么能够解决失眠?
1 、保持良好的心情;
2 、进行适当的训练。
3 、可适当使用药物。1. Cobalah untuk mengatur panjang teks yang terbagi menjadi lebih besar. 2. Untuk menghindari jawaban yang sedang dibagi, Anda dapat mengatur teks tertentu untuk diulang di antara paragraf yang berbeda. 3. Dokumen top_k pertama dapat dikembalikan selama pencarian. 4. Fusion Beberapa teks ditemukan dan rangkum mereka menggunakan LLM.
Bagaimana cara membangun embedding di bidang vertikal?
Bagaimana cara menyimpan embedding yang diperoleh?
Bagaimana cara membimbing LLM untuk berpikir lebih baik? Anda dapat menggunakan: rantai pikiran, tanya sendiri, bereaksi .
PENDAHULUAN |?
Referensi API - ??
https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
https://python.langchain.com.cn/docs/modules/agents/how_to/custom_llm_chat_agent


