langchain learning
1.0.0
บันทึกการศึกษาของ Langchain พึ่งพา:
openai == 0.27 . 8
langchian == 0.0 . 225เครื่องมือบางอย่างที่คล้ายกับ Langchain:
หมายเหตุ: เนื่องจากการอัปเดตของ Langchain หรือ Langchain-Chatglm ซอร์สโค้ดและคำอธิบายบางอย่างอาจแตกต่างกัน
บางบทความใส่ลิงก์โดยตรงและรวบรวมจากอินเทอร์เน็ต
ปัจจุบันมีโครงการจีนสองโครงการตาม Langchain:
เราสามารถเรียนรู้มากมายจากมัน
propt ที่ได้รับการปรับปรุงเป็นสิ่งสำคัญสำหรับผลลัพธ์
YZFLY/Langgpt: Langgpt: ช่วยให้ทุกคนเป็นผู้เชี่ยวชาญที่รวดเร็ว! (github.com): สร้าง propt คุณภาพสูงที่มีโครงสร้าง
แม้ว่า Langchain จะให้ความสะดวกแก่เรา แต่ก็มีปัญหาบางอย่าง:
ปัญหาของเทคโนโลยีพื้นฐานของโมเดลขนาดใหญ่ไม่สามารถแก้ไขได้ส่วนใหญ่เป็นปัญหาของการใช้ซ้ำของ PROPT : ประการแรกปัญหามากมายในรูปแบบขนาดใหญ่เป็นข้อบกพร่องของเทคโนโลยีพื้นฐานของโมเดลขนาดใหญ่และไม่ใช่สิ่งที่ Langchain สามารถแก้ไขได้ ปัญหาหลักคืองานหลักของการพัฒนาแบบจำลองขนาดใหญ่คือวิศวกรรม Propt และนี่เป็นสิ่งที่นำกลับมาใช้ใหม่ได้มาก อย่างไรก็ตามคุณสมบัติเหล่านี้ทั้งหมด ต้องการ propp ที่เขียนด้วยลายมือที่กำหนดเองมาก ทุกขั้นตอนในห่วงโซ่ต้องใช้ proppt ที่เขียนด้วยลายมือ ข้อมูลอินพุตจะต้องจัดรูปแบบในวิธีที่เฉพาะเจาะจงมากในการสร้างเอาต์พุตที่ดีสำหรับขั้นตอนฟังก์ชัน/ห่วงโซ่ การตั้งค่า DAG orchestration เพื่อเรียกใช้โซ่เหล่านี้คิดเป็นเพียง 5% ของงานและ 95% ของงานเป็นเพียงการปรับเปลี่ยนและรูปแบบการทำให้เป็นอนุกรมข้อมูล สิ่งเหล่านี้ ไม่สามารถนำกลับมาใช้ซ้ำได้
สิ่งที่เป็นนามธรรมและขยะที่ซ่อนอยู่ของ Langchain ทำให้เกิดปัญหาการพัฒนา : เพียงแค่ใส่สิ่งที่เป็นนามธรรมของ Langchain ไม่ดีพอดังนั้นจึงต้องสร้างขั้นตอนต่าง ๆ มากมายด้วยตัวเอง ยิ่งไปกว่านั้นอุปกรณ์ประกอบฉากในตัวของ Langchain ในตัวนั้นไม่ดีดังนั้นพวกเขาจึงไม่ดีเท่าการสร้างตัวเอง แต่พวกเขาซ่อนอุปกรณ์ประกอบฉากเริ่มต้นเหล่านี้
เฟรมเวิร์ก Langchain นั้นยากที่จะแก้ไขข้อบกพร่อง : แม้ว่าวิธีการหลายวิธีของ Langchain จะให้พารามิเตอร์สำหรับการพิมพ์ข้อมูลโดยละเอียด แต่จริง ๆ แล้วพวกเขาไม่มีข้อมูลที่มีค่ามากนัก ตัวอย่างเช่นมันเป็นเรื่องยากมากหากคุณต้องการดูการสืบค้น PROPT หรือ LLM จริง เหตุผลเหมือนกันก่อนหน้านี้ ดังนั้นหากคุณใช้ Langchain เพื่อพัฒนาไม่ดีและคุณต้องการดีบักรหัสเพื่อดูว่ามีปัญหาใดที่มีปัญหามันจะยาก
Langchain สนับสนุนการล็อคเครื่องมือ : Langchain สนับสนุนให้ผู้ใช้พัฒนาและทำงานบนแพลตฟอร์มของพวกเขา แต่หากผู้ใช้จำเป็นต้องทำเวิร์กโฟลว์บางอย่างที่ไม่ได้กล่าวถึงในเอกสาร Langchain มันยากที่จะแก้ไขแม้จะมีพร็อกซีที่กำหนดเอง ซึ่งหมายความว่าเมื่อผู้ใช้เริ่มใช้ Langchain พวกเขาอาจพบว่าตัวเองถูกกักขังอยู่ในเครื่องมือและคุณสมบัติเฉพาะของ Langchain และไม่สามารถเปลี่ยนไปใช้เครื่องมือหรือแพลตฟอร์มอื่น ๆ ที่อาจเหมาะสมกับความต้องการของพวกเขาได้อย่างง่ายดาย
เนื้อหาข้างต้นมาจาก:
บางครั้งเราสามารถใช้กระบวนการที่เกี่ยวข้องสำหรับงานง่าย ๆ ด้วยตัวเองเพื่อให้ แต่ละส่วนถูกควบคุมด้วยตัวเอง และง่ายต่อการปรับเปลี่ยน
การปรับแต่ง LLM โดยใช้ข้อมูลโดเมนนั้นถูก จำกัด ด้วยขนาดของทรัพยากรการคำนวณและพารามิเตอร์แบบจำลองและรูปแบบจะมีข่าวลือ สิ่งนี้เกี่ยวข้องกับชุดของปัญหา:
แนวคิดพื้นฐาน:
1. คำถามผู้ใช้: โปรดเปรียบเทียบผลิตภัณฑ์ Estee Laudert การซ่อมแซม Soft การดูแลผิวและ SK-II Skin Care Essence?
2. การกำหนดเส้นทางปัญหา Routerchain นั่นคือวิธีตอบคำถาม: (โทร LLM หนึ่งครั้ง)
3. ใช้ Planner เพื่อสร้างขั้นตอน: (โทร LLM หนึ่งครั้ง)
4. Executor Executer ดำเนินการตามขั้นตอนข้างต้น: (ขั้นตอนการโทร LLM, N คือ HyperParameter ที่ระบุจำนวนการโทรสูงสุด)
5. สรุปผลลัพธ์ทั้งหมด (โทร LLM หนึ่งครั้ง)
เมื่อเปรียบเทียบกับ Scheme 1 โดยไม่ต้องใช้เครื่องมือฐานข้อมูลจะถูกค้นหาโดยตรงตามคำถามและจากนั้นผลลัพธ์ที่ดึงมาจะได้รับคำตอบ
วิธีการค้นหาสามารถขึ้นอยู่กับคำหลักของคำถามที่กำหนดและใช้เครื่องมือ ES เพื่อดึงย่อหน้า TOPK พร้อมคำตอบที่เป็นไปได้จากฐานข้อมูลขนาดใหญ่ ส่งย่อหน้า topk เหล่านี้พร้อมกับคำถามที่ LLM เพื่อตอบ
วิธีการค้นหาถูกเปลี่ยนเป็นรูปแบบเวกเตอร์
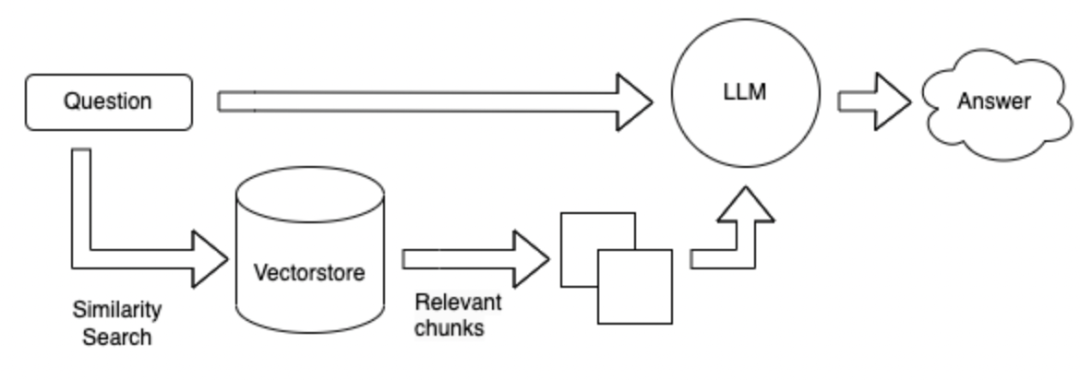
ข้อดีและข้อเสียของวิธีการข้างต้น:
Field Fine-Tuning LLM : ต้องใช้กำลังคนจำนวนมากในการรวบรวมข้อมูลและคำถามและคำตอบในสนามและต้องใช้พลังในการคำนวณจำนวนมากเพื่อปรับแต่ง
Langchain + LLM + เครื่องมือ : เป็นบริการที่ใช้ LLM เป็นบริการย่อย การสร้าง LLM นั้นไม่น่าเชื่อถือเมื่อเรียกเครื่องมือตามปัญหาและเครื่องมือ ไม่สามารถใช้เครื่องมือที่ดีได้ อาจเป็นไปไม่ได้ที่จะเรียกเครื่องมือที่เหมาะสมตามคำแนะนำและแผนอาจไม่ดีและยากต่อการควบคุม ข้อดีคือ: ใช้ในการแก้ปัญหาที่ซับซ้อน
Langchain + LLM + Search : ข้อได้เปรียบคือโครงสร้างคำถามและคำตอบที่สำคัญในฟิลด์ปัจจุบันและข้อเสียคือการค้นหาย่อหน้าที่อาจมีคำตอบอาจไม่ถูกต้องเมื่อค้นหาคำตอบตามคำถาม ไม่เหมาะสำหรับคำถามและคำตอบที่ซับซ้อน
สรุป: ปัญหาที่ใหญ่ที่สุดคือ LLM เอง:
LLM เป็นฐานของระบบทั้งหมดและยังมีตัวเลือกมากมาย
ข้อมูลอ้างอิงข้างต้น: https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
ทิ้งคำถามไว้ให้คิด: มันอาจเกี่ยวข้องกับ Langchain หรือกับรุ่นใหญ่
** วิธีเลือกโมเดลขนาดใหญ่ภาษาจีนตามข้อมูลในเขตข้อมูลแนวตั้ง? ** 1. มีวางจำหน่ายทั่วไปหรือไม่? 2. ตามเวอร์ชันการจัดอันดับของการตรวจสอบแต่ละครั้ง 3. ประเมินข้อมูลภาคสนามของคุณเอง 4. ดึงจากแบบจำลองสนามแนวตั้งที่มีอยู่เช่นรูปแบบทางการเงินแบบจำลองทางกฎหมายแบบจำลองทางการแพทย์ ฯลฯ
** คำตอบของข้อมูลประกอบด้วยชุดของประโยคที่เชื่อมต่อ **ตัวอย่างเช่น:
怎么能够解决失眠?
1 、保持良好的心情;
2 、进行适当的训练。
3 、可适当使用药物。1. พยายามตั้งค่าความยาวของข้อความที่แบ่งออกเป็นขนาดใหญ่ 2. เพื่อหลีกเลี่ยงคำตอบที่ถูกแบ่งออกคุณสามารถตั้งค่าข้อความบางอย่างที่จะทำซ้ำระหว่างย่อหน้าที่แตกต่างกัน 3. เอกสาร TOP_K แรกสามารถส่งคืนระหว่างการค้นหา 4. ฟิวชั่นหลายข้อความพบและสรุปโดยใช้ LLM
วิธีการสร้างการฝังในทุ่งแนวตั้ง?
จะเก็บการฝังที่ได้รับได้อย่างไร?
จะแนะนำ LLM ให้คิดได้ดีขึ้นได้อย่างไร? คุณสามารถใช้: ห่วงโซ่แห่งความคิด, ถามตัวเอง, ตอบสนอง
บทนำ |?
API อ้างอิง - ?? langchain 0.0.229
https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
https://python.langchain.com.cn/docs/modules/agents/how_to/custom_llm_chat_agent


