langchain learning
1.0.0
Langchain의 연구 노트. 의존하다:
openai == 0.27 . 8
langchian == 0.0 . 225Langchain과 유사한 일부 도구 :
참고 : Langchain 또는 Langchain-Chatglm의 업데이트로 인해 일부 소스 코드 및 설명이 다를 수 있습니다.
일부 기사는 직접 링크를 넣고 인터넷에서 수집했습니다.
현재 Langchain을 기반으로 한 두 개의 중국 프로젝트가 있습니다.
우리는 그것으로부터 많은 것을 배울 수 있습니다.
최적화 된 소품은 결과에 중요합니다.
yzfly/langgpt : langgpt : 모든 사람이 프롬프트 전문가가되도록 권한을 부여합니다! (github.com) : 구조화 된 고품질 소품을 빌드하십시오
Langchain은 우리에게 편의성을 제공하지만 몇 가지 문제도 있습니다.
대형 모델의 기본 기술 문제는 해결할 수 없습니다. 주로 Propt 재사용 문제는 해결할 수 없습니다 . 우선, 대형 모델의 많은 문제는 대형 모델의 기본 기술의 결함이며 Langchain이 해결할 수있는 것이 아닙니다. 핵심 문제는 대규모 모델 개발의 주요 작업이 Propt 엔지니어링이라는 것입니다. 그리고 이것은 매우 재사용 가능합니다. 그러나 이러한 기능은 모두 매우 맞춤형 필기 프로포트가 필요합니다 . 체인의 모든 단계에는 손으로 쓴 프로트가 필요합니다. 입력 데이터는 해당 함수/체인 단계에 대한 좋은 출력을 생성하기 위해 매우 구체적인 방식으로 형식화되어야합니다. 이 체인을 실행하기 위해 Dag Orchestration을 설정하면 작업의 5%만을 차지하며 작업의 95%는 실제로 조정 및 데이터 직렬화 형식을 제기하는 것입니다. 이러한 것들은 재사용 할 수 없습니다 .
Langchain의 추상화가 열악하고 숨겨진 쓰레기 소품은 개발 어려움을 야기합니다 . 간단히 말해서 Langchain의 추상화 작업은 충분하지 않으므로 많은 단계를 스스로 구축해야합니다. 더욱이, Langchain의 많은 내장 소품은 나쁘기 때문에 직접 구성하는 것만 큼 좋지는 않지만 기본 소품을 숨 깁니다.
Langchain 프레임 워크는 디버그하기가 어렵습니다 . 많은 Langchain 방법이 자세한 정보를 인쇄하기위한 매개 변수를 제공하지만 실제로는 많은 귀중한 정보가 없습니다 . 예를 들어 실제 Propt 또는 LLM 쿼리를보고 싶다면 매우 어렵습니다. 그 이유는 이전과 동일합니다. 대부분의 시간은 내부 소품을 숨 깁니다. 따라서 Langchain을 사용하여 제대로 발전하지 않고 코드를 디버깅하여 어떤 프롬프트가 문제가 있는지 확인하려면 어려울 것입니다.
Langchain은 도구 잠금을 권장합니다 . Langchain은 사용자가 플랫폼에서 개발 및 운영을 권장하지만 사용자가 Langchain 문서에서 다루지 않은 일부 워크 플로를 수행 해야하는 경우 사용자 정의 프록시로도 수정하기가 어렵습니다. 즉, 사용자가 Langchain을 사용하기 시작하면 Langchain의 특정 도구 및 기능에 국한되어 있으며 자신의 요구에 더 적합한 다른 도구 나 플랫폼으로 쉽게 전환 할 수 없습니다.
위의 내용은 다음과 같습니다.
때로는 간단한 작업에 대한 관련 프로세스를 스스로 구현할 수 있으므로 각 부분은 스스로 제어 하고 수정하기가 더 쉽습니다.
도메인 데이터를 사용한 LLM의 미세 조정은 컴퓨팅 리소스 및 모델 매개 변수의 크기로 제한되며 모델에 소문이납니다. 여기에는 일련의 문제가 포함됩니다.
기본 아이디어 :
1. 사용자 질문 : 제품을 비교하십시오 Estee Laudert 소프트 수리 피부 관리 에센스 및 SK-II 스킨 케어 본질을 비교해 보시겠습니까?
2. Routerchain 문제 라우팅, 즉 질문에 답하는 방법 : (LLM에 한 번 전화)
3. 플래너를 사용하여 단계를 생성하십시오 : (LLM을 한 번 호출)
4. Executor Executer는 위의 단계를 실행합니다.
5. 모든 결과의 요약. (한 번 LLM에 전화)
체계 1과 비교하여 도구를 사용하지 않고 데이터베이스는 질문에 따라 직접 검색 한 다음 검색된 결과에 응답합니다.
검색 방법은 주어진 질문의 키워드를 기반으로 할 수 있으며 ES 도구를 사용하여 대규모 데이터베이스의 가능한 답변으로 Topk 단락을 검색합니다. 이 Topk 단락을 질문과 함께 LLM에 보내기 위해 답변하십시오.
검색 방법은 벡터 형식으로 변경됩니다. 먼저 알려진 모든 정보는 300 단어에 따라 작은 단락으로 나뉘어져 있으며,이 단락은 벡터로 인코딩됩니다.
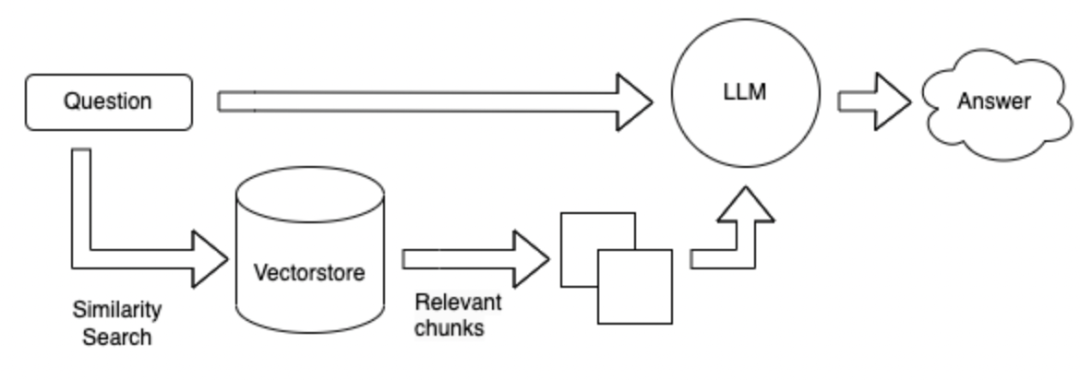
위의 방법의 장점과 단점 :
Field Fine Tuning LLM : 현장에서 데이터와 Q & A를 수집하기 위해 많은 인력이 필요하며 미세 조정하려면 많은 컴퓨팅 전력이 필요합니다.
Langchain + LLM + 도구 : LLM을 하위 서비스로 사용하는 서비스는 Planner와 Execution의 뇌입니다. LLM 생성은 문제와 도구를 기반으로 도구를 호출 할 때 신뢰할 수 없습니다. 도구를 잘 활용할 수 없습니다. 지침에 따라 적절한 도구를 호출 할 수 없으며 계획은 열악하고 통제하기 어려울 수 있습니다. 장점은 다음과 같습니다. 복잡한 문제를 해결하는 데 사용됩니다.
Langchain + LLM + 검색 : 이점은 현재 필드의 주류 질문 및 답변 구조이며, 단점은 질문을 기반으로 답변을 검색 할 때 답변을 포함 할 수있는 단락 검색이 부정확 할 수 있다는 것입니다. 복잡한 질문과 답변에는 적합하지 않습니다
요약 : 가장 큰 문제는 LLM 자체입니다.
LLM은 전체 시스템의 기본이며 여전히 많은 중국어 모델이 온라인으로 열려 있었지만 대부분의 옵션은 6B/7B/13B입니다.
위의 참조 : https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
몇 가지 질문을 남겨 두십시오.
** 수직 필드의 데이터를 기반으로 중국 대형 모델을 선택하는 방법은 무엇입니까? ** 1. 상업적으로 이용 가능합니까? 2. 각 검토의 순위 버전에 따라. 3. 자신의 현장 데이터를 평가하십시오. 4. 재무 모델, 법률 모델, 의료 모델 등과 같은 기존의 수직 필드 모델에서 그리기.
** 데이터에 대한 답은 일련의 연결된 문장으로 구성되어 있습니다. **예를 들어:
怎么能够解决失眠?
1 、保持良好的心情;
2 、进行适当的训练。
3 、可适当使用药物。1. 분할 된 텍스트의 길이를 더 크게 설정하십시오. 2. 답을 분할하지 않기 위해 다른 단락 사이에서 반복 할 특정 텍스트를 설정할 수 있습니다. 3. 첫 번째 TOP_K 문서는 검색 중에 반환 할 수 있습니다. 4. Fusion 다중 텍스트가 LLM을 사용하여 그것들을 찾아 요약합니다.
수직 필드에 포함 된 방법은 무엇입니까?
얻은 임베딩을 저장하는 방법?
LLM을 더 잘 생각하도록 안내하는 방법? 당신은 사용할 수 있습니다 : 사고, self ask, reft . 세부 사항은 https://zhuanlan.zhihu.com/p/62617292를 볼 수 있습니다.
소개 |..? 닐?
API 참조 - ?? Langchain 0.0.229
https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
https://python.langchain.com.cn/docs/modules/agents/how_to/custom_llm_chat_agent


