langchain learning
1.0.0
langchain's study notes. rely:
openai == 0.27 . 8
langchian == 0.0 . 225Some tools similar to langchain:
Note: Due to the update of langchain or langchain-ChatGLM, some source codes and explanations may be different.
Some articles directly put links and collected from the Internet.
Currently, there are two Chinese projects based on langchain:
We can learn a lot from it.
An optimized propt is crucial to the results. Those who are interested can check it out.
yzfly/LangGPT: LangGPT: Empowering everyone to become a prompt expert! Structured Prompt, structured prompt word. (github.com): Build structured high-quality propt
Although langchain provides us with some convenience, there are also some problems:
The problem of basic technology of large models cannot be solved, mainly the problem of reuse of propt : First of all, many problems in large models are defects of basic technology of large models, and are not something that LangChain can solve. The core problem is that the main work of large-scale model development is the propt engineering. And this is very reusable. However, these features all require a very customized handwritten propt . Every step in the chain requires handwritten propt. The input data must be formatted in a very specific way to generate a good output for that function/chain step. Setting up DAG orchestration to run these chains only accounts for 5% of the work, and 95% of the work is actually just on prompting adjustments and data serialization formats. These things are not reusable .
LangChain's poor abstraction and hidden garbage propt cause development difficulties : simply put, LangChain's abstraction work is not good enough, so many steps need to be built by themselves. Moreover, many of the built-in props of LangChain are bad, so they are not as good as constructing them yourself, but they hide these default props.
LangChain frameworks are difficult to debug : Although many methods of LangChain provide parameters for printing detailed information, they actually do not have much valuable information . For example, it is very difficult if you want to see actual propt or LLM queries. The reason is the same as before. LangChain most of the time hides the internal prop. So if you use LangChain to develop poorly and you want to debug the code to see which prompts have problems, it will be difficult.
LangChain encourages tool locking : LangChain encourages users to develop and operate on their platform, but if users need to do some workflows not covered in the LangChain documentation, it is difficult to modify even with a custom proxy. This means that once users start using LangChain, they may find themselves confined to specific tools and features of LangChain and cannot easily switch to other tools or platforms that may be more suitable for their needs.
The above content comes from:
Sometimes we can implement relevant processes for some simple tasks by ourselves, so that each part is controlled by ourselves and is easier to modify.
Fine-tuning of LLM using domain data is limited by the size of computing resources and model parameters, and the model will be rumored. This involves a series of issues:
Basic ideas:
1. User question: Please compare the products Estee Laudert Soft Repairing Skin Care Essence and SK-II Skin Care Essence?
2. RouterChain problem routing, that is, how to answer the question: (Call LLM once)
3. Use Planner to generate step: (Call LLM once)
4. Executor Executer executes the above steps: (Call steps LLM, n is the hyperparameter indicating the maximum number of calls)
5. Summary of all results. (Call LLM once)
Compared with Scheme 1, without using tools, the database is searched directly based on the question, and then the retrieved results are answered.
The search method can be based on the keywords of a given question, and use the ES tool to retrieve topk paragraphs with possible answers from a massive database. Send these topk paragraphs together with the question to LLM to answer.
The search method is changed to a vector form. First, all known information is divided into small paragraphs according to 300 words, and then these paragraphs are encoded into vectors. When the user asks a question, the user's questions are also encoded into vectors, and then these paragraphs are searched to obtain the most relevant paragraphs of topk, and send these topk paragraphs together with the question to LLM to answer.
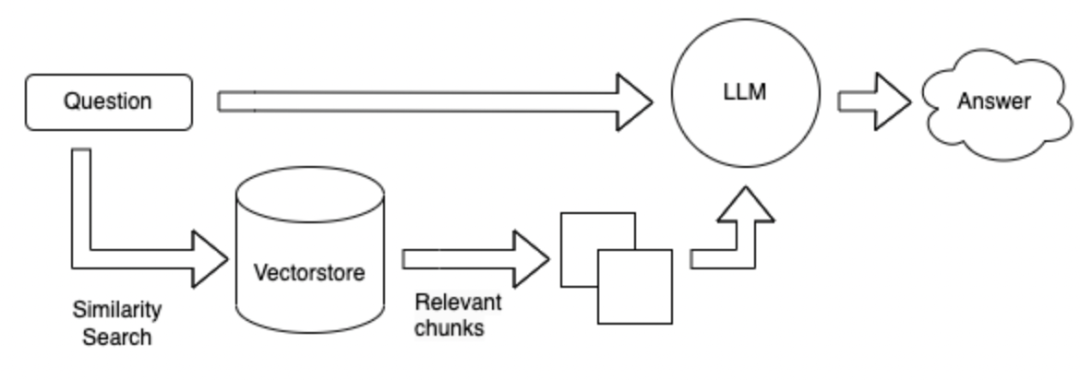
Advantages and disadvantages of the above method:
Field fine-tuning LLM : It requires a lot of manpower to collect data and Q&A in the field, and requires a lot of computing power to fine-tune.
langchain + LLM + tools : It is a service that takes LLM as a sub-service. LangChain is the brain of the planner and executor. It calls LLM at the right time. The advantage is to solve complex problems, but the disadvantage is to be unreliable. LLM generation is unreliable when calling tools based on problems and tools. Can't make good use of tools. It may not be possible to call appropriate tools according to the instructions, and the plan may be poor and difficult to control. Advantages are: used to solve complex problems.
langchain + LLM + Search : The advantage is the mainstream question-and-answer structure in the current field, and the disadvantage is that the search for paragraphs that may contain answers may be inaccurate when searching for answers based on the question. Not suitable for complex questions and answers
Summary: The biggest problem is LLM itself:
LLM is the base of the entire system, and there are still many options available. Many large Chinese language models have been opened sourced online, but most of them are 6B/7B/13B. If you want to have a smart brain, the number of parameters of the model needs to be guaranteed.
The above reference: https://mp.weixin.qq.com/s/FvRchiT0c0xHYscO_D-sdA
Leave some questions to think about: it may be related to langchain or to big models
**How to choose a Chinese big model based on data in vertical fields? **1. Is it commercially available? 2. According to the ranking version of each review. 3. Evaluate on your own field data. 4. Draw from existing vertical field models, such as financial models, legal models, medical models, etc.
**An answer to the data is composed of a series of connected sentences. How to segment the text to obtain a complete answer? **for example:
怎么能够解决失眠?
1 、保持良好的心情;
2 、进行适当的训练。
3 、可适当使用药物。1. Try to set the length of the divided text to be larger. 2. In order to avoid the answer being divided, you can set a certain text to be repeated between different paragraphs. 3. The first top_k documents can be returned during search. 4. Fusion multiple texts found and summarize them using LLM.
How to build embedding in vertical fields?
How to store the obtained embedding?
How to guide LLM to think better? You can use: chain of thoughts, self ask, ReAct . For details, you can see this article: https://zhuanlan.zhihu.com/p/622617292 In fact, the ReAct strategy is used in langchain.
Introduction | ?️? Langchain
API Reference — ?? LangChain 0.0.229
https://mp.weixin.qq.com/s/FvRchiT0c0xHYscO_D-sdA
https://python.langchain.com.cn/docs/modules/agents/how_to/custom_llm_chat_agent


