langchain learning
1.0.0
Учебные примечания Лэнгчейна. полагаться:
openai == 0.27 . 8
langchian == 0.0 . 225Некоторые инструменты, похожие на Langchain:
Примечание. Из-за обновления Langchain или Langchain-Chatglm некоторые исходные коды и объяснения могут быть разными.
Некоторые статьи напрямую размещают ссылки и собираются из Интернета.
В настоящее время есть два китайских проекта, основанных на Langchain:
Мы можем многому научиться из этого.
Оптимизированное Propt имеет решающее значение для результатов.
YZFLY/LANGGPT: LANGGPT: Расширение возможностей всех станет быстрым экспертом! (github.com): построить структурированное высококачественное Propt
Хотя Langchain предоставляет нам некоторое удобство, есть и некоторые проблемы:
Проблема основных технологий крупных моделей не может быть решена, в основном проблема повторного использования ProPT : во -первых, многие проблемы в крупных моделях являются дефектами основных технологий крупных моделей, и это не то, что Langchain может решить. Основная проблема заключается в том, что основной работой крупномасштабной разработки модели является инженерия ProPT. И это очень используется. Тем не менее, все эти функции требуют очень настроенного рукописного пропта . Каждый шаг в цепочке требует рукописного пропта. Входные данные должны быть отформатированы очень специфическим способом для создания хорошего вывода для этой функции/цепочки. Настройка DAG Orchestration для запуска этих цепей составляет только 5% работы, и 95% работы на самом деле связаны с тем, чтобы вызвать корректировки и форматы сериализации данных. Эти вещи не используются многоразовым .
Плохая абстракция Лэнгкейна и скрытое пропта для мусора вызывают трудности с развитием : проще говоря, работа по абстракции Лэнгкейна недостаточно хороша, поэтому многие шаги должны быть созданы сами по себе. Более того, многие из встроенных реквизитов Langchain плохи, поэтому они не так хороши, как построить их самостоятельно, но они скрывают эти реквизиты по умолчанию.
Отлаживать фреймворки Langchain трудно отладить : хотя многие методы Langchain предоставляют параметры для печати подробной информации, они фактически не имеют много ценной информации . Например, очень сложно, если вы хотите увидеть фактические запросы ProPT или LLM. Причина такая же, как и раньше. Поэтому, если вы используете Langchain для плохого развития и хотите отладить код, чтобы увидеть, какие подсказки имеют проблемы, это будет сложно.
Langchain поощряет блокировку инструментов : Langchain поощряет пользователей разработать и работать на своей платформе, но если пользователи должны выполнять некоторые рабочие процессы, не охватывающие документацию Langchain, его трудно изменить даже с помощью пользовательского прокси. Это означает, что как только пользователи начнут использовать Langchain, они могут оказаться ограниченными конкретными инструментами и функциями Langchain и не могут легко переключиться на другие инструменты или платформы, которые могут быть более подходящими для их потребностей.
Приведенный выше контент поступает:
Иногда мы можем реализовать соответствующие процессы для некоторых простых задач сами, так что каждая часть контролируется нами, и ее легче изменить.
Тонкая настройка LLM с использованием данных домена ограничена размером вычислительных ресурсов и параметров модели, и модель будет ходить. Это включает в себя ряд вопросов:
Основные идеи:
1. Пользовательский вопрос: Сравните продукты Estee Laudert Soft Remocting Essence Essence и Essence Sk-II по уходу за кожей?
2. Маршрутизация проблем с маршрутизацией, то есть как ответить на вопрос: (позвоните LLM один раз)
3. Используйте планировщик, чтобы генерировать шаг: (вызовите LLM один раз)
4. Исполнитель исполнителя выполняет вышеуказанные шаги: (Шаги вызовов LLM, n - гиперпараметр, указывающий максимальное количество вызовов)
5. Резюме всех результатов. (Позвоните LLM один раз)
По сравнению со схемой 1 без использования инструментов база данных поиск непосредственно на основе вопроса, а затем на полученные результаты отвечают.
Метод поиска может быть основан на ключевых словах данного вопроса и использовать инструмент ES для извлечения параграфов Topk с возможными ответами из массивной базы данных. Отправьте эти параграфы Topk вместе с вопросом, чтобы ответить.
Метод поиска изменяется на векторную форму.
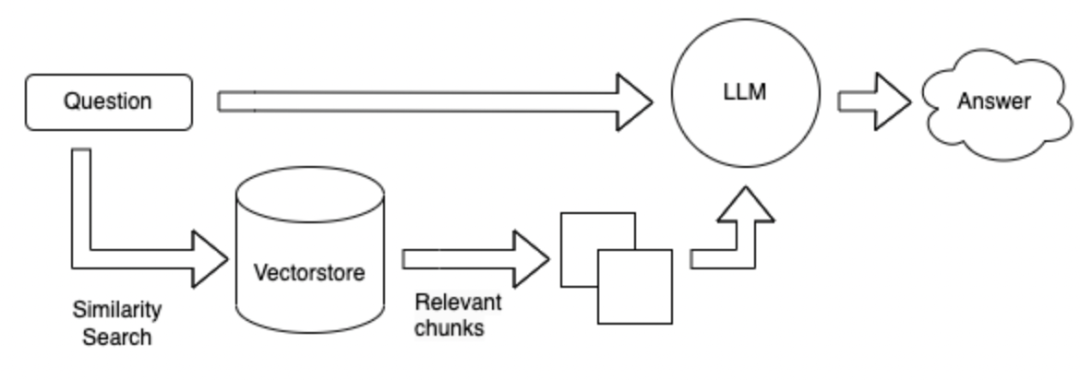
Преимущества и недостатки приведенного выше метода:
Field Fine-Tuning LLM : Для сбора данных и вопросов и ответов требуется много рабочей силы, и требуется много вычислительной мощности для тонкой настройки.
Langchain + LLM + Инструменты : это услуга, которая принимает LLM в качестве подселения. Генерация LLM ненадежна при вызове инструментов на основе проблем и инструментов. Не могу хорошо использовать инструменты. Возможно, невозможно назвать соответствующие инструменты в соответствии с инструкциями, и план может быть плохим и трудным для контроля. Преимущества: используются для решения сложных задач.
Langchain + LLM + Search : Преимущество-основная структура вопросов и ответов в текущем поле, и недостаток заключается в том, что поиск абзацев, которые могут содержать ответы, может быть неточным при поиске ответов на основе вопроса. Не подходит для сложных вопросов и ответов
Резюме: Самая большая проблема - сама LLM:
LLM является основой всей системы, и есть еще много вариантов.
Приведенная выше ссылка: https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
Оставьте некоторые вопросы, чтобы подумать: это может быть связано с Langchain или с большими моделями
** Как выбрать китайскую большую модель на основе данных в вертикальных полях? ** 1. 2. Согласно рейтингу версии каждого обзора. 3. Оцените свои собственные полевые данные. 4. Нарисуйте из существующих вертикальных полевых моделей, таких как финансовые модели, юридические модели, медицинские модели и т. Д.
** Ответ на данные состоит из ряда подключенных предложений. **например:
怎么能够解决失眠?
1 、保持良好的心情;
2 、进行适当的训练。
3 、可适当使用药物。1. Попробуйте установить длину разделенного текста, чтобы быть больше. 2. Чтобы избежать разделения ответа, вы можете установить определенный текст, который будет повторяться между различными абзацами. 3. Первые документы top_k могут быть возвращены во время поиска. 4. Обнаружено несколько текстов и суммируйте их с помощью LLM.
Как построить встраивание в вертикальные поля?
Как сохранить полученное встрадание?
Как направить LLM, чтобы думать лучше? Вы можете использовать: цепочка мыслей, самопросите, реагируйте .
Введение |
Ссылка на API -?
https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
https://python.langchain.com.cn/docs/modules/agents/how_to/custom_llm_chat_agent


