langchain learning
1.0.0
Notas de estudio de Langchain. confiar:
openai == 0.27 . 8
langchian == 0.0 . 225Algunas herramientas similares a Langchain:
Nota: Debido a la actualización de langchain o langchain-chatglm, algunos códigos de origen y explicaciones pueden ser diferentes.
Algunos artículos ponen enlaces directamente y se recopilan de Internet.
Actualmente, hay dos proyectos chinos basados en Langchain:
Podemos aprender mucho de eso.
Un PropT optimizado es crucial para los resultados.
YZFLY/LANGGPT: LANGGPT: ¡Empoderar a todos para que se conviertan en un experto rápido! (Github.com): construir propuesta estructurada de alta calidad
Aunque Langchain nos proporciona cierta conveniencia, también hay algunos problemas:
No se puede resolver el problema de la tecnología básica de modelos grandes, principalmente el problema de la reutilización de PropT : en primer lugar, muchos problemas en modelos grandes son defectos de tecnología básica de modelos grandes, y no son algo que Langchain puede resolver. El problema central es que el trabajo principal del desarrollo del modelo a gran escala es la ingeniería de propt. Y esto es muy reutilizable. Sin embargo, todas estas características requieren un PropT escrito a mano muy personalizado . Cada paso de la cadena requiere propt escrito a mano. Los datos de entrada deben formatearse de una manera muy específica para generar una buena salida para esa función/paso de cadena. La configuración de la orquestación DAG para ejecutar estas cadenas solo representa el 5% del trabajo, y el 95% del trabajo es solo solo en los ajustes y formatos de serialización de datos. Estas cosas no son reutilizables .
La pobre abstracción de Langchain y el apoyo de basura oculta causan dificultades de desarrollo : en pocas palabras, el trabajo de abstracción de Langchain no es lo suficientemente bueno, por lo que se deben construir muchos pasos por sí mismos. Además, muchos de los accesorios incorporados de Langchain son malos, por lo que no son tan buenos como construirlos usted mismo, pero ocultan estos accesorios predeterminados.
Los marcos de Langchain son difíciles de depurar : aunque muchos métodos de Langchain proporcionan parámetros para imprimir información detallada, en realidad no tienen mucha información valiosa . Por ejemplo, es muy difícil si desea ver consultas reales de propt o LLM. La razón es la misma que antes. Entonces, si usa Langchain para desarrollarse mal y desea depurar el código para ver qué indicaciones tienen problemas, será difícil.
Langchain fomenta el bloqueo de las herramientas : Langchain alienta a los usuarios a desarrollar y operar en su plataforma, pero si los usuarios necesitan hacer algunos flujos de trabajo no cubiertos en la documentación de Langchain, es difícil modificar incluso con un proxy personalizado. Esto significa que una vez que los usuarios comienzan a usar Langchain, pueden encontrarse confinados a herramientas y características específicas de Langchain y no pueden cambiar fácilmente a otras herramientas o plataformas que puedan ser más adecuadas para sus necesidades.
El contenido anterior proviene de:
A veces podemos implementar procesos relevantes para algunas tareas simples por nosotros mismos, de modo que cada parte esté controlada por nosotros mismos y sea más fácil de modificar.
El ajuste fino de LLM utilizando datos de dominio está limitado por el tamaño de los recursos informáticos y los parámetros del modelo, y se rumorea el modelo. Esto implica una serie de problemas:
Ideas básicas:
1. Pregunta del usuario: Compare los productos estee laudert reparación suave de la esencia de cuidado de la piel y esencia de cuidado de la piel SK-II?
2. Enrutamiento de problemas de enrutadora, es decir, cómo responder la pregunta: (llame a LLM una vez)
3. Use el planificador para generar el paso: (llame a LLM una vez)
4. Ejecutor Ejecutor ejecuta los pasos anteriores: (Pasos de llamada LLM, N es el hiperparameter que indica el número máximo de llamadas)
5. Resumen de todos los resultados. (Llame a LLM una vez)
En comparación con el esquema 1, sin usar herramientas, la base de datos se busca directamente en función de la pregunta, y luego se responden los resultados recuperados.
El método de búsqueda puede basarse en las palabras clave de una pregunta dada y usar la herramienta ES para recuperar los párrafos de TOPK con posibles respuestas de una base de datos masiva. Envíe estos párrafos de TOPK junto con la pregunta a LLM para responder.
El método de búsqueda se cambia a una forma vectorial.
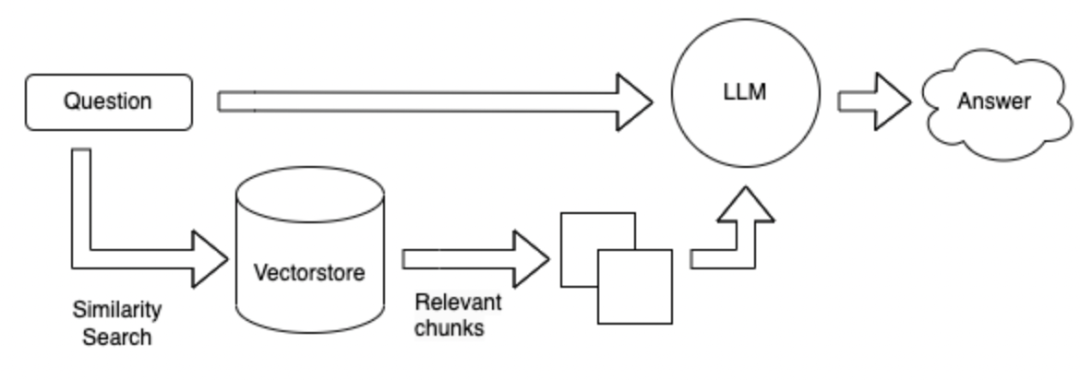
Ventajas y desventajas del método anterior:
Field Finuning LLM : requiere mucha mano de obra para recopilar datos y preguntas y respuestas en el campo, y requiere una gran cantidad de potencia informática para ajustar.
Langchain + LLM + Herramientas : es un servicio que toma LLM como un subservicio. La generación de LLM no es confiable cuando llaman herramientas basadas en problemas y herramientas. No puedo hacer un buen uso de las herramientas. Puede que no sea posible llamar a las herramientas apropiadas de acuerdo con las instrucciones, y el plan puede ser pobre y difícil de controlar. Las ventajas son: se usan para resolver problemas complejos.
Langchain + LLM + Búsqueda : la ventaja es la estructura principal de preguntas y respuestas en el campo actual, y la desventaja es que la búsqueda de párrafos que pueden contener respuestas pueden ser inexactos cuando se busca respuestas basadas en la pregunta. No es adecuado para preguntas y respuestas complejas
Resumen: El mayor problema es LLM:
LLM es la base de todo el sistema, y todavía hay muchas opciones disponibles.
La referencia anterior: https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
Deje algunas preguntas en las que pensar: puede estar relacionado con Langchain o con modelos grandes
** ¿Cómo elegir un gran modelo chino basado en datos en campos verticales? ** 1. 2. Según la versión de clasificación de cada revisión. 3. Evalúe en sus propios datos de campo. 4. Dibuje de modelos de campo vertical existentes, como modelos financieros, modelos legales, modelos médicos, etc.
** Una respuesta a los datos se compone de una serie de oraciones conectadas. **Por ejemplo:
怎么能够解决失眠?
1 、保持良好的心情;
2 、进行适当的训练。
3 、可适当使用药物。1. Intente establecer la longitud del texto dividido para que sea más grande. 2. Para evitar la respuesta que se divide, puede establecer un cierto texto para repetirse entre diferentes párrafos. 3. Los primeros documentos TOP_K se pueden devolver durante la búsqueda. 4. Fusion múltiples textos encontrados y resumidos los utilizando LLM.
¿Cómo construir la incrustación en campos verticales?
¿Cómo almacenar la incrustación obtenida?
¿Cómo guiar a LLM a pensar mejor? Puede usar: Cadena de pensamientos, Solicitar, Reaccionar .
Introducción |
Referencia de API - ?? Langchain 0.0.229
https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
https://python.langchain.com.cn/docs/modules/agents/how_to/custom_llm_chat_agent


