langchain learning
1.0.0
Langchainの研究ノート。頼る:
openai == 0.27 . 8
langchian == 0.0 . 225Langchainに似たいくつかのツール:
注:LangchainまたはLangchain-Chatglmの更新により、いくつかのソースコードと説明が異なる場合があります。
いくつかの記事は、リンクを直接掲載し、インターネットから収集しました。
現在、Langchainに基づいた2つの中国のプロジェクトがあります。
私たちはそれから多くを学ぶことができます。
最適化されたプロップは、それをチェックすることができます。
yzfly/langgpt:langgpt:プロンプトのプロンプト、構造化されたプロンプトワードになるようになります。 (github.com):構造化された高品質のプロップを構築します
Langchainは私たちにいくらかの利便性を提供しますが、いくつかの問題もあります。
大規模なモデルの基本技術の問題は解決することはできません。主にProptの再利用の問題です。まず第一に、大規模なモデルの多くの問題は大規模なモデルの基本技術の欠陥であり、Langchainが解決できるものではありません。中心的な問題は、大規模なモデル開発の主な作業がProptエンジニアリングであることです。そして、これは非常に再利用可能です。ただし、これらの機能にはすべて、非常にカスタマイズされた手書きのプロップが必要です。チェーン内のすべてのステップには、手書きのプロップが必要です。入力データは、その関数/チェーンステップの適切な出力を生成するために、非常に具体的な方法でフォーマットする必要があります。これらのチェーンを実行するためにDAGオーケストレーションをセットアップすると、作業の5%のみが占められており、作業の95%は実際に調整とデータのシリアル化形式を促すだけです。これらのことは再利用できません。
Langchainの不十分な抽象化と隠れたごみproptは開発の困難を引き起こします。簡単に言えば、Langchainの抽象化作業は十分ではないため、多くの手順を自分で構築する必要があります。さらに、Langchainの組み込みの小道具の多くは悪いので、自分で構築するほど良くありませんが、これらのデフォルトの小道具を隠しています。
Langchainフレームワークはデバッグが困難です。Langchainの多くの方法は、詳細情報を印刷するためのパラメーターを提供しますが、実際にはあまり価値のある情報がありません。たとえば、実際のPROPTまたはLLMクエリを見たい場合は非常に困難です。理由は以前と同じです。したがって、Langchainを使用して開発が悪化し、コードをデバッグしてどのプロンプトに問題があるかを確認したい場合は、難しいでしょう。
Langchainはツールのロックを奨励しています。Langchainは、ユーザーがプラットフォームで開発および操作することを奨励していますが、ユーザーがLangchainドキュメントでカバーされていないワークフローを実行する必要がある場合は、カスタムプロキシを使用しても変更することは困難です。これは、ユーザーがLangchainの使用を開始すると、Langchainの特定のツールや機能に限定され、ニーズにより適した他のツールやプラットフォームに簡単に切り替えることができないことを意味します。
上記のコンテンツは次のとおりです。
一部の単純なタスクに関連するプロセスを自分で実装できる場合があり、各部分が自分で制御され、変更が容易になる場合があります。
ドメインデータを使用したLLMの微調整は、コンピューティングリソースとモデルパラメーターのサイズによって制限され、モデルは噂されます。これには、一連の問題が含まれます。
基本的なアイデア:
1。ユーザーの質問:製品ESTEE LAUDERTソフト修理スキンケアのエッセンスとSK-IIスキンケアのエッセンスを比較してください。
2。ルーターチェーンの問題ルーティング、つまり、質問への回答方法:( LLMを1回電話)
3.プランナーを使用してステップを生成します:( LLMを1回呼び出します)
4。執行者エグゼキューターは上記の手順を実行します:(コールステップLLM、nは、コールの最大数を示すハイパーパラメーターです)
5。すべての結果の概要。 (LLMに一度電話)
スキーム1と比較して、ツールを使用せずに、データベースは質問に基づいて直接検索され、取得された結果に回答します。
検索方法は、特定の質問のキーワードに基づいており、ESツールを使用して、大規模なデータベースからの可能な回答でTOPK段落を取得します。これらのTOPK段落を質問とともにLLMに送信して回答します。
検索方法は、最初にベクトル形式に変更されます。すべての既知の情報は、300語に応じて小さな段落に分割されます。これらの段落は、ユーザーの質問をベクトルにエンコードし、これらのパラグラフを検索して、これらの段落を獲得します。
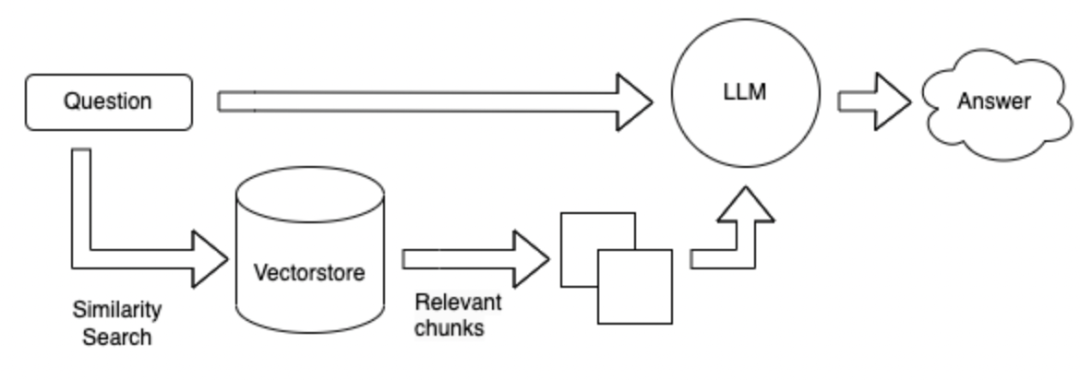
上記の方法の利点と短所:
フィールド微調整LLM :フィールドでデータとQ&Aを収集するには多くの人材が必要であり、微調整するには多くのコンピューティング能力が必要です。
LANGCHAIN + LLM + TOULS :LANGCHAINは、プランナーとエグゼキューターの脳です。問題やツールに基づいてツールを呼び出す場合、LLMの生成は信頼できません。ツールをうまく利用できません。指示に従って適切なツールを呼び出すことはできない場合があり、計画は貧弱で制御が困難な場合があります。利点は次のとおりです。複雑な問題を解決するために使用されます。
Langchain + LLM +検索:利点は現在のフィールドの主流の問題と回答の構造であり、不利な点は、質問に基づいて回答を検索するときに答えを含む可能性のある段落の検索が不正確である可能性があることです。複雑な質問や回答には適していません
要約:最大の問題はLLM自体です:
LLMはシステム全体のベースであり、多くの大規模な中国語モデルがオンラインで開かれていますが、それらのほとんどはスマートな脳を持ちたい場合、モデルのパラメーターの数を保証する必要があります。
上記のリファレンス:https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
考えるためにいくつかの質問を残してください:それはLangchainまたは大きなモデルに関連している可能性があります
**垂直フィールドのデータに基づいて中国の大きなモデルを選択する方法は? ** 1。 2。各レビューのランキングバージョンによると。 3。独自のフィールドデータを評価します。 4.財務モデル、法的モデル、医療モデルなど、既存の垂直フィールドモデルから抽選
**データへの回答は、一連の接続された文で構成されています。 **例えば:
怎么能够解决失眠?
1 、保持良好的心情;
2 、进行适当的训练。
3 、可适当使用药物。1.分割されたテキストの長さを大きくするようにしてください。 2。答えが分割されないようにするために、異なる段落間で特定のテキストを繰り返すように設定できます。 3.最初のTOP_Kドキュメントは、検索中に返すことができます。 4. Fusion LLMを使用して、それらを見つけて要約した複数のテキスト。
垂直フィールドに埋め込みを構築する方法は?
取得した埋め込みを保存する方法は?
LLMをよりよく考えるように導く方法は?使用できます。
はじめに|
APIリファレンス - ?? LANGCHAIN 0.0.229
https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
https://python.langchain.com.cn/docs/modules/agents/how_to/custom_llm_chat_agent


