langchain learning
1.0.0
Notas de estudo de Langchain. confiar:
openai == 0.27 . 8
langchian == 0.0 . 225Algumas ferramentas semelhantes a Langchain:
Nota: Devido à atualização de Langchain ou Langchain-Chatglm, alguns códigos e explicações de origem podem ser diferentes.
Alguns artigos colocam diretamente os links e coletados na Internet.
Atualmente, existem dois projetos chineses baseados em Langchain:
Podemos aprender muito com isso.
Um Propt otimizado é crucial para os resultados.
YZFLY/LANGGPT: LANGGPT: capacitando todos a se tornar um especialista rápido! (github.com): construir propt estruturado de alta qualidade
Embora Langchain nos forneça alguma conveniência, também existem alguns problemas:
O problema da tecnologia básica de modelos grandes não pode ser resolvida, principalmente o problema da reutilização do Propt : antes de tudo, muitos problemas em grandes modelos são defeitos da tecnologia básica de modelos grandes e não são algo que Langchain pode resolver. O problema principal é que o principal trabalho do desenvolvimento de modelos em larga escala é a engenharia da Propt. E isso é muito reutilizável. No entanto, esses recursos requerem um Propt manuscrito muito personalizado . Cada etapa da cadeia requer Propt manuscrito. Os dados de entrada devem ser formatados de uma maneira muito específica para gerar uma boa saída para essa etapa de função/cadeia. A configuração da Orquestração de DAG para executar essas cadeias é responsável apenas por 5% do trabalho, e 95% do trabalho está realmente apenas ao solicitar ajustes e formatos de serialização de dados. Essas coisas não são reutilizáveis .
A baixa abstração e o lixo oculto de Langchain causam dificuldades de desenvolvimento : Simplificando, o trabalho de abstração de Langchain não é bom o suficiente, tantas etapas precisam ser construídas por si mesmas. Além disso, muitos dos adereços embutidos de Langchain são ruins, por isso não são tão bons quanto construí-los você mesmo, mas escondem esses adereços padrão.
As estruturas de Langchain são difíceis de depurar : embora muitos métodos de Langchain forneçam parâmetros para imprimir informações detalhadas, elas realmente não têm informações valiosas . Por exemplo, é muito difícil se você deseja ver consultas reais do Propt ou LLM. O motivo é o mesmo de antes. Portanto, se você usar o Langchain para se desenvolver mal e deseja depurar o código para ver quais instruções têm problemas, será difícil.
Langchain incentiva o bloqueio de ferramentas : o Langchain incentiva os usuários a desenvolver e operar em sua plataforma, mas se os usuários precisam fazer alguns fluxos de trabalho não abordados na documentação de Langchain, é difícil modificar mesmo com um proxy personalizado. Isso significa que, uma vez que os usuários começam a usar o Langchain, eles podem se encontrar confinados a ferramentas e recursos específicos do Langchain e não podem mudar facilmente para outras ferramentas ou plataformas que podem ser mais adequadas para suas necessidades.
O conteúdo acima vem de:
Às vezes, podemos implementar processos relevantes para algumas tarefas simples por nós mesmos, para que cada parte seja controlada por nós mesmos e seja mais fácil de modificar.
O ajuste fino do LLM usando dados de domínio é limitado pelo tamanho dos recursos de computação e dos parâmetros do modelo, e o modelo será rumores. Isso envolve uma série de questões:
Ideias básicas:
1. Pergunta do usuário: Compare os produtos Estee Laudert Reparando a essência da pele e a essência de cuidados com a pele SK-II?
2. Routerchain Problem Routing, isto é, como responder à pergunta: (ligue para LLM uma vez)
3. Use o Planner para gerar etapa: (ligue para LLM uma vez)
4. Executor executador executa as etapas acima: (etapas de chamada llm, n é o hiperparâmetro indicando o número máximo de chamadas)
5. Resumo de todos os resultados. (Ligue para LLM uma vez)
Comparado com o Esquema 1, sem o uso de ferramentas, o banco de dados é pesquisado diretamente com base na pergunta e, em seguida, os resultados recuperados são respondidos.
O método de pesquisa pode ser baseado nas palavras -chave de uma determinada pergunta e usar a ferramenta ES para recuperar parágrafos Topk com possíveis respostas de um banco de dados enorme. Envie esses parágrafos Topk juntamente com a pergunta ao LLM para responder.
O método de pesquisa é alterado para um formulário de vetor.
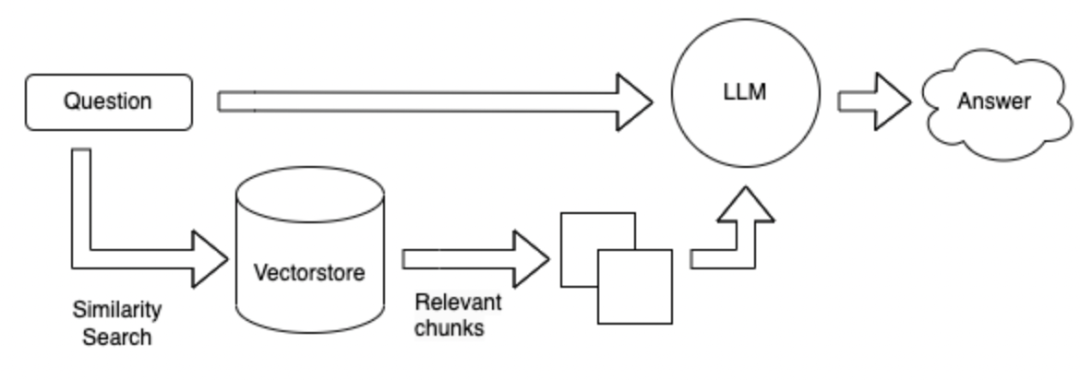
Vantagens e desvantagens do método acima:
Campo Fine Tuning LLM : Requer muita mão de obra para coletar dados e perguntas e respostas no campo e requer muito poder de computação para ajustar.
Langchain + LLM + Ferramentas : É um serviço que leva o LLM como um sub-serviço. A geração LLM não é confiável ao chamar ferramentas com base em problemas e ferramentas. Não posso fazer bom uso de ferramentas. Pode não ser possível chamar as ferramentas apropriadas de acordo com as instruções, e o plano pode ser ruim e difícil de controlar. As vantagens são: usadas para resolver problemas complexos.
Langchain + LLM + Pesquisa : A vantagem é a estrutura de perguntas e respostas, e a desvantagem é que a busca de parágrafos que possa conter respostas pode ser imprecisa ao procurar respostas com base na pergunta. Não é adequado para perguntas e respostas complexas
Resumo: O maior problema é o próprio LLM:
O LLM é a base de todo o sistema e ainda existem muitas opções disponíveis.
A referência acima: https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
Deixe algumas perguntas para pensar: pode estar relacionado a Langchain ou a grandes modelos
** Como escolher um grande modelo chinês com base em dados em campos verticais? ** 1. 2. De acordo com a versão de classificação de cada revisão. 3. Avalie seus próprios dados de campo. 4. Retire -se dos modelos de campo vertical existentes, como modelos financeiros, modelos legais, modelos médicos, etc.
** Uma resposta para os dados é composta por uma série de frases conectadas. **por exemplo:
怎么能够解决失眠?
1 、保持良好的心情;
2 、进行适当的训练。
3 、可适当使用药物。1. Tente definir o comprimento do texto dividido como maior. 2. Para evitar que a resposta seja dividida, você pode definir um determinado texto a ser repetido entre diferentes parágrafos. 3. Os primeiros documentos top_k podem ser retornados durante a pesquisa. 4. Vários textos de fusão encontrados e resumem -os usando LLM.
Como construir incorporação em campos verticais?
Como armazenar a incorporação obtida?
Como orientar o LLM a pensar melhor? Você pode usar: Cadeia de pensamentos, auto -pergunte, reação .
Introdução |
Referência da API - ?? Langchain 0.0.229
https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
https://python.langchain.com.cn/docs/modules/agents/how_to/custom_llm_chat_agent


