langchain learning
1.0.0
Notes d'étude de Langchain. compter sur:
openai == 0.27 . 8
langchian == 0.0 . 225Quelques outils similaires à Langchain:
Remarque: En raison de la mise à jour de Langchain ou Langchain-chatGlm, certains codes source et explications peuvent être différents.
Certains articles mettent directement des liens et collectés sur Internet.
Actuellement, il y a deux projets chinois basés sur Langchain:
Nous pouvons en apprendre beaucoup.
Un propt optimisé est crucial pour les résultats.
YZFLY / LANGGPT: Langgpt: Germer tout le monde à devenir un expert rapide! (github.com): construire une propt structuré de haute qualité
Bien que Langchain nous fournit une certaine commodité, il y a aussi quelques problèmes:
Le problème de la technologie de base des grands modèles ne peut pas être résolu, principalement le problème de la réutilisation de Propt : tout d'abord, de nombreux problèmes dans les grands modèles sont des défauts de la technologie de base de grands modèles, et ne sont pas quelque chose que Langchain peut résoudre. Le problème central est que le travail principal du développement de modèles à grande échelle est l'ingénierie ProT. Et c'est très réutilisable. Cependant, ces fonctionnalités nécessitent toutes une propt manuscrite très personnalisée . Chaque étape de la chaîne nécessite une propt manuscrite. Les données d'entrée doivent être formatées de manière très spécifique pour générer une bonne sortie pour cette étape de fonction / chaîne. La configuration de l'orchestration DAG pour exécuter ces chaînes ne représente que 5% des travaux, et 95% des travaux sont en fait uniquement d'inciter les ajustements et les formats de sérialisation des données. Ces choses ne sont pas réutilisables .
La pauvre abstraction de Langchain et la propt de déchets cachés provoquent des difficultés de développement : tout simplement, le travail d'abstraction de Langchain n'est pas assez bon, donc de nombreuses étapes doivent être construites par elles-mêmes. De plus, bon nombre des accessoires intégrés de Langchain sont mauvais, ils ne sont donc pas aussi bons que de les construire vous-même, mais ils cachent ces accessoires par défaut.
Les cadres de Langchain sont difficiles à déboguer : bien que de nombreuses méthodes de Langchain fournissent des paramètres pour l'impression d'informations détaillées, ils n'ont en fait pas beaucoup d'informations précieuses . Par exemple, il est très difficile si vous souhaitez voir des requêtes Propt ou LLM réelles. La raison est la même qu'auparavant. Donc, si vous utilisez Langchain pour mal développer et que vous souhaitez déboguer le code pour voir quelles invites ont des problèmes, ce sera difficile.
Langchain encourage le verrouillage des outils : Langchain encourage les utilisateurs à développer et à opérer sur leur plate-forme, mais si les utilisateurs doivent faire des flux de travail non couverts dans la documentation de Langchain, il est difficile de modifier même avec un proxy personnalisé. Cela signifie qu'une fois que les utilisateurs commencent à utiliser Langchain, ils peuvent se retrouver confinés à des outils et des fonctionnalités spécifiques de Langchain et ne peuvent pas facilement passer à d'autres outils ou plateformes qui peuvent être plus adaptés à leurs besoins.
Le contenu ci-dessus vient de:
Parfois, nous pouvons implémenter des processus pertinents pour certaines tâches simples par nous-mêmes, afin que chaque partie soit contrôlée par nous-mêmes et est plus facile à modifier.
Le réglage fin de LLM à l'aide des données du domaine est limité par la taille des ressources informatiques et des paramètres du modèle, et le modèle sera supposé. Cela implique une série de problèmes:
Idées de base:
1. Question de l'utilisateur: Veuillez comparer les produits Estee Laudert Réparation de la peau Solaire Essence et SK-II Skin Care Essence?
2. Routerchain Problème Route, c'est-à-dire comment répondre à la question: (Appelez LLM une fois)
3. Utilisez le planificateur pour générer l'étape: (Appelez LLM une fois)
4. Executer Executer exécute les étapes ci-dessus: (étapes d'appel llm, n est l'hyperparamètre indiquant le nombre maximum d'appels)
5. Résumé de tous les résultats. (Appelez LLM une fois)
Par rapport au schéma 1, sans utiliser d'outils, la base de données est recherchée directement en fonction de la question, puis les résultats récupérés sont répondus.
La méthode de recherche peut être basée sur les mots clés d'une question donnée et utiliser l'outil ES pour récupérer les paragraphes Topk avec des réponses possibles à partir d'une base de données massive. Envoyez ces paragraphes Topk avec la question à LLM pour répondre.
La méthode de recherche est changée en un formulaire vectoriel.
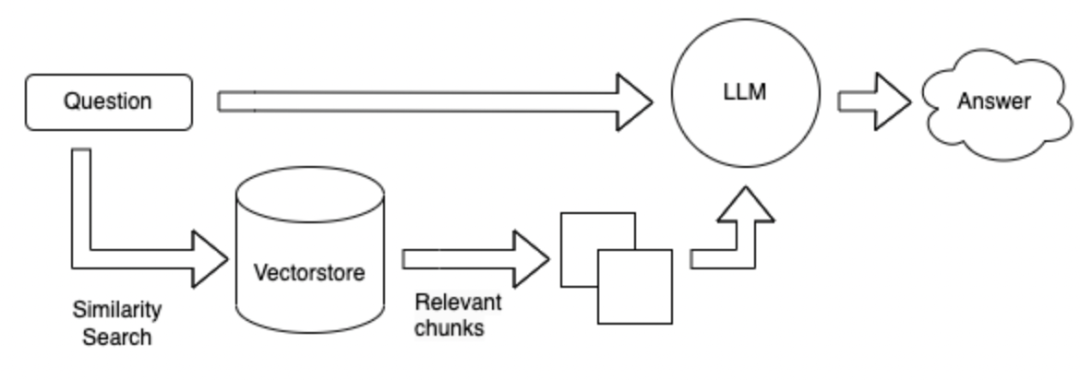
Avantages et inconvénients de la méthode ci-dessus:
Field Fine-Tuning LLM : il nécessite beaucoup de main-d'œuvre pour collecter des données et des questions et réponses sur le terrain, et nécessite beaucoup de puissance de calcul pour affiner.
Langchain + LLM + Tools : Il s'agit d'un service qui prend LLM en tant que sous-service. La génération LLM n'est pas fiable lors de l'appel d'outils en fonction des problèmes et des outils. Impossible de faire bon usage des outils. Il peut ne pas être possible d'appeler les outils appropriés en fonction des instructions, et le plan peut être médiocre et difficile à contrôler. Les avantages sont: utilisés pour résoudre des problèmes complexes.
Langchain + LLM + Recherche : L'avantage est la structure de questions et réponses grand public dans le champ actuel, et l'inconvénient est que la recherche de paragraphes qui peuvent contenir des réponses peuvent être inexactes lors de la recherche de réponses en fonction de la question. Pas adapté aux questions et réponses complexes
Résumé: Le plus gros problème est LLM lui-même:
LLM est la base de l'ensemble du système, et il y a encore de nombreuses options.
La référence ci-dessus: https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
Laissez quelques questions à réfléchir: elle peut être liée à Langchain ou aux grands modèles
** Comment choisir un gros modèle chinois basé sur des données dans les champs verticaux? ** 1. 2. Selon la version de classement de chaque critique. 3. Évaluez vos propres données sur le terrain. 4. Dessinez des modèles de champ vertical existants, tels que des modèles financiers, des modèles juridiques, des modèles médicaux, etc.
** Une réponse aux données est composée d'une série de phrases connectées. **Par exemple:
怎么能够解决失眠?
1 、保持良好的心情;
2 、进行适当的训练。
3 、可适当使用药物。1. Essayez de régler la longueur du texte divisé pour être plus grand. 2. Afin d'éviter que la réponse soit divisée, vous pouvez définir un certain texte pour être répété entre différents paragraphes. 3. Les premiers documents TOP_K peuvent être retournés lors de la recherche. 4. Fusion multiples textes trouvés et les résumer à l'aide de LLM.
Comment construire l'incorporation dans des champs verticaux?
Comment stocker l'intégration obtenue?
Comment guider LLM pour mieux réfléchir? Vous pouvez utiliser: chaîne de pensées, auto-demande, réagir .
Introduction |?
Référence API -?? Langchain 0.0.229
https://mp.weixin.qq.com/s/fvrchit0c0xhysco_d-sda
https://python.langchain.com.cn/docs/modules/agents/how_to/custom_llm_chat_agent


