Super mario bros A3C pytorch
1.0.0
這是我的Python源代碼,用於培訓代理商扮演超級馬里奧兄弟。通過使用異步參與者 - 批評(A3C)算法,在論文異步方法中引入了深鋼筋學習論文中。
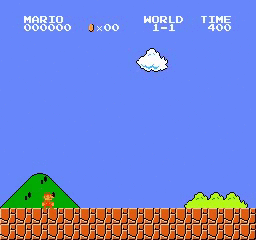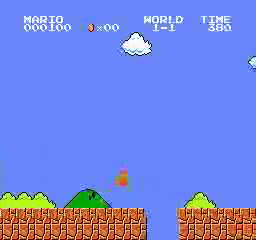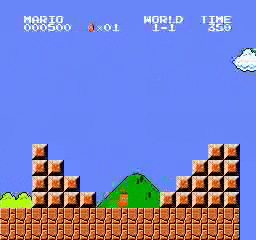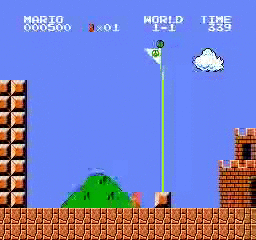
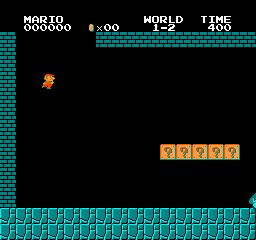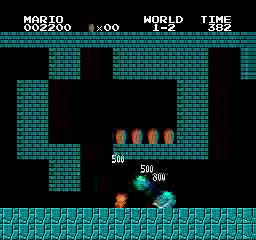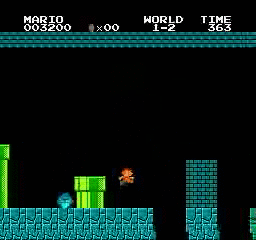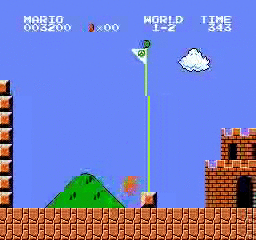
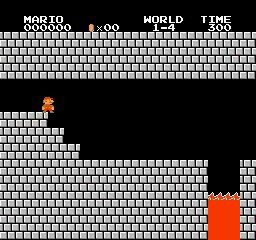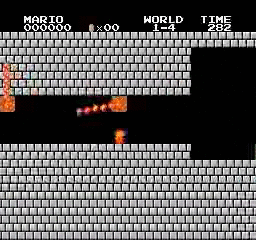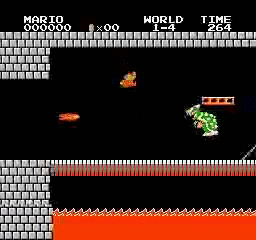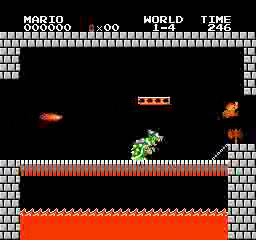

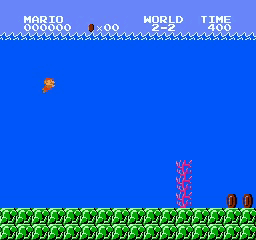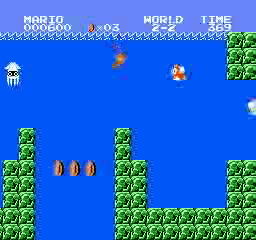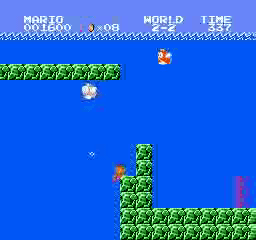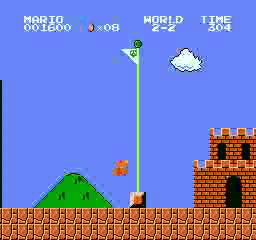
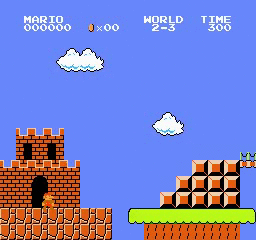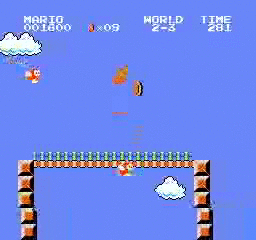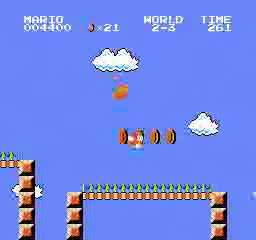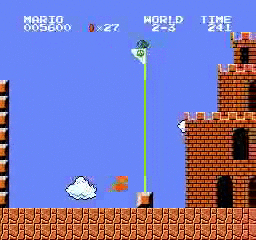
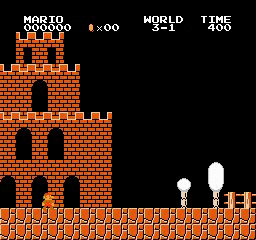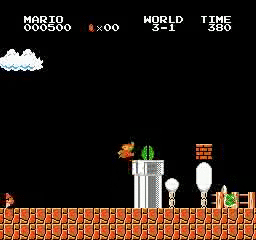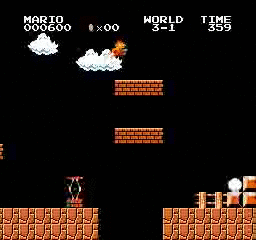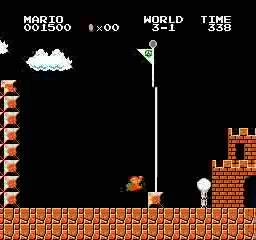
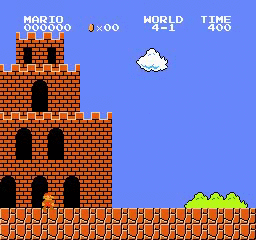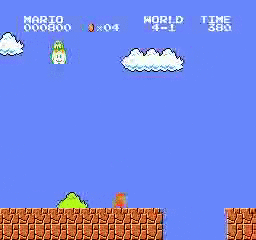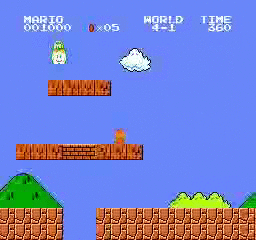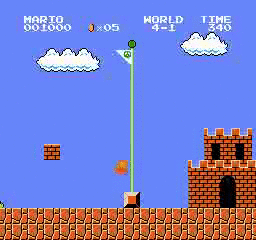
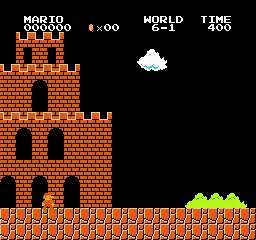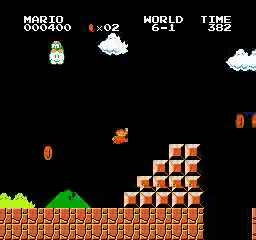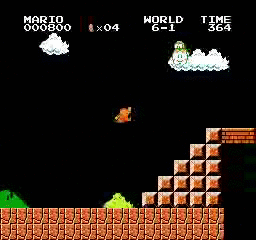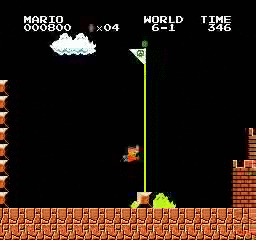
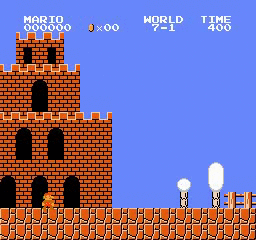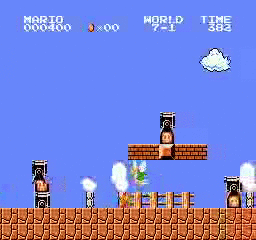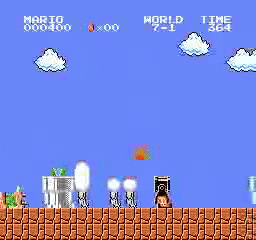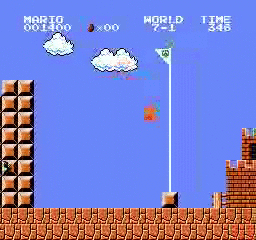
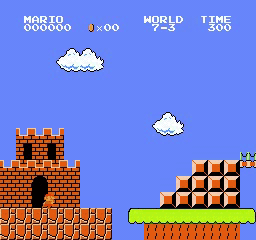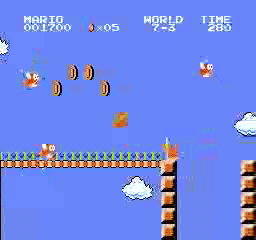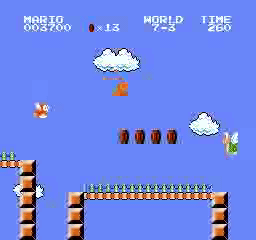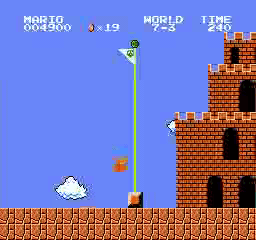
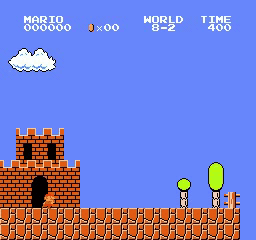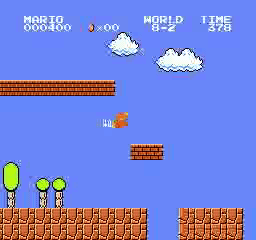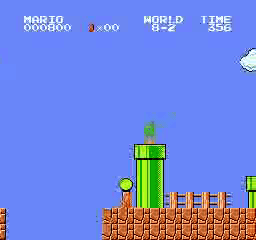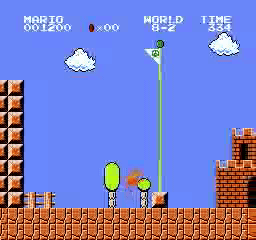
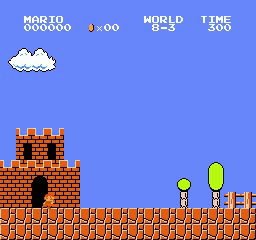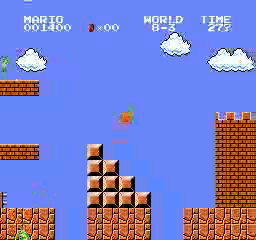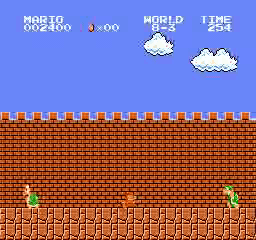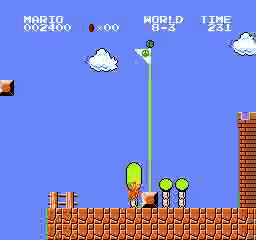
樣本結果
在實施該項目之前,有幾個存儲庫很好地複制了本文的結果,在不同的常見深度學習框架中,例如Tensorflow,Keras和Pytorch。我認為,其中大多數都很棒。但是,它們在許多部分中似乎過於復雜,包括圖像的預處理,環境設置和權重初始化,這使用戶的注意力分散了更重要的問題。因此,我決定編寫一個清潔代碼,這簡化了不重要的部分,而仍然嚴格遵循論文。如您所見,只要您正確實現算法,代理就會教會自己如何與環境交互,並逐漸找到達到最終目標的方法,只要您正確實現算法,就可以看到最小的設置和簡單網絡的初始化。
如果您已經熟悉加強學習,尤其是A3C,則可以跳過此部分。我寫了這部分,以解釋什麼是A3C算法,如何以及為什麼起作用,對對A3C或我的實施感興趣或好奇的人,但不了解背後的機制。因此,您不需要任何前知識知識來閱讀此部分
如果您在Internet上搜索,則有許多文章介紹或解釋A3C,有些甚至提供示例代碼。但是,我想採取另一種方法:將異步演員的名稱分解為較小的部分,並以匯總方式解釋。
您的經紀人有2個名為Actor and Critic的部分,其目標是通過探索和利用環境,隨著時間的流逝,這兩個部分都會變得更好。想像一個小小的頑皮的孩子(演員)正在發現他周圍的驚人世界,而他的父親(評論家)則監督他,以確保他沒有做任何危險的事情。每當孩子做任何好事時,他的父親都會讚揚並鼓勵他將來重複這一行動。當然,當孩子做任何有害的事情時,他會從父親那裡得到警告。孩子與世界互動越多,採取不同的行動,他從父親那裡得到的反饋就越積極和消極。孩子的目標是,從父親那裡收集盡可能多的積極反饋,而父親的目標是更好地評估兒子的行動。換句話說,我們在孩子和他的父親之間或演員和評論家之間有雙贏的關係。
為了使孩子的學習速度更快,更穩定,父親沒有告訴兒子的行為有多好,而是要告訴他與其他行動相比(或“虛擬”平均動作)的行為更好或更糟。一個例子是一千個字。讓我們比較2對爸爸和兒子。第一位爸爸給兒子10年級的10糖和1年級的糖果送給了1年級的一年級。另一方面,第二個父親給了他的兒子5次10年級的糖果,並通過不允許他觀看他最喜歡的電視連續劇的一天來“懲罰”他的兒子。您怎麼看?第二個爸爸似乎有點聰明,對吧?確實,如果您仍然以少量獎勵“鼓勵”他們,則很少會防止不良行動。
如果代理人僅發現環境,學習過程就會很慢。更嚴重的是,代理可能對特定的次優溶液有偏見,這是不可取的。如果您有一堆代理商同時發現環境的不同部分並定期將其新的知識更新到彼此之間,該怎麼辦?這正是異步優勢參與者評論的想法。現在,孩子和他的伴侶在幼兒園裡去了一個美麗的海灘(當然,和他們的老師一起)。他們的任務是建造一座偉大的沙堡。不同的孩子將建造由老師監督的城堡的不同部分。他們每個人都會有不同的任務,最終目標是一個強大而醒目的城堡。當然,在上一個示例中,老師的角色與父親相同。唯一的區別是前者更忙?
使用我的代碼,您可以:
您可以找到我在超級Mario Bros A3C訓練的模型中訓練的訓練有素的型號
一開始,我只能訓練我的經紀人完成9個階段。然後@DavinCibj指出,可以完成19個階段,並將訓練有素的權重寄給我。非常感謝您的發現!


