Super mario bros A3C pytorch
1.0.0
إليكم رمز مصدر بيثون لتدريب وكيل للعب سوبر ماريو بروس. باستخدام خوارزمية غير متزامنة Advance-Actor-Critic (A3C) التي تم تقديمها في الأساليب غير المتزامنة الورقية لورقة التعلم التعزيز العميق .
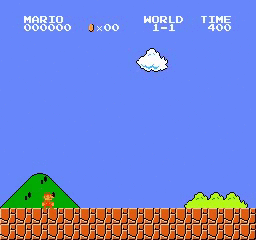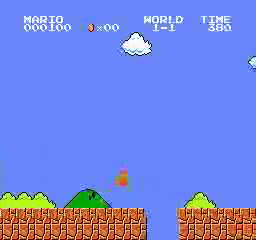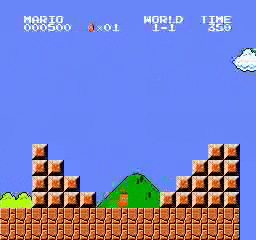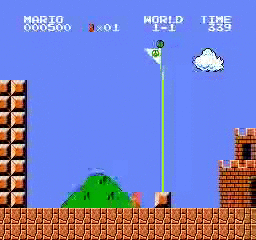
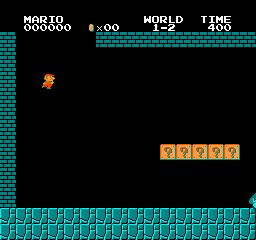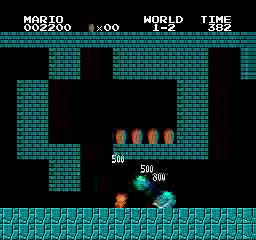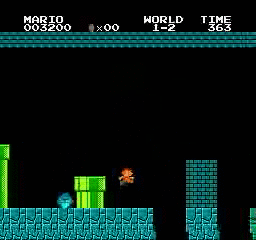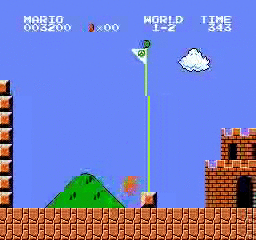

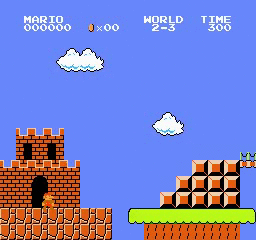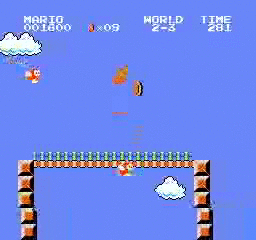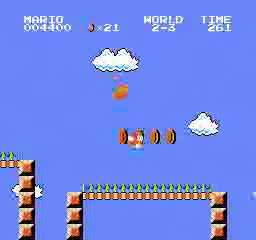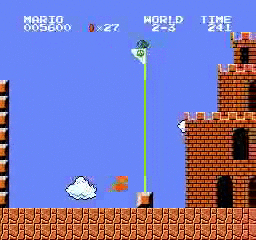
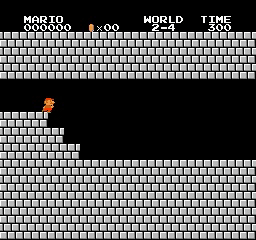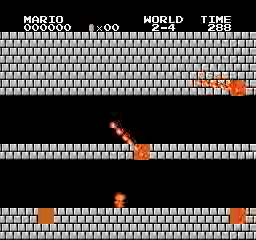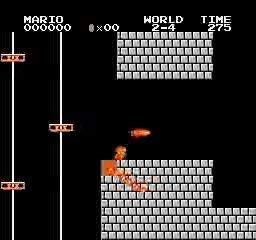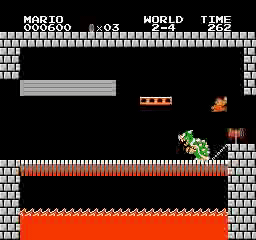
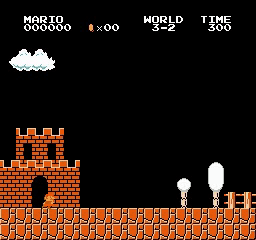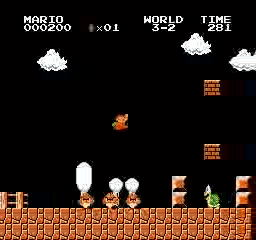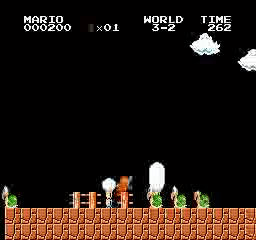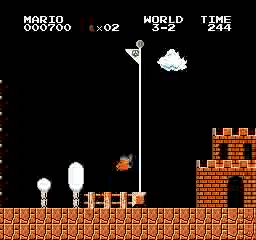
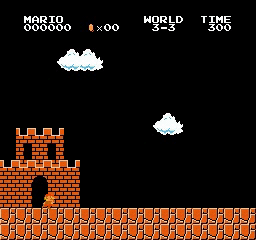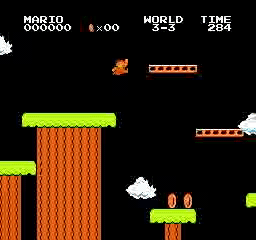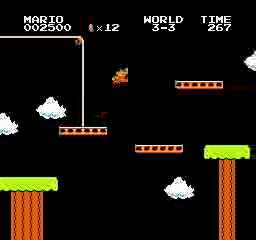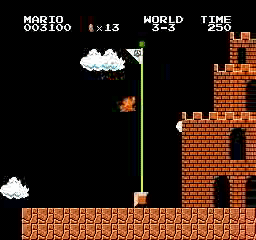
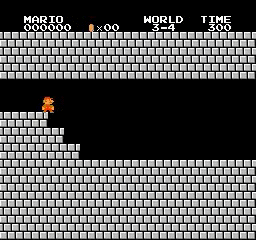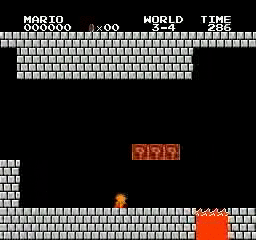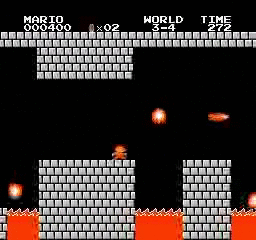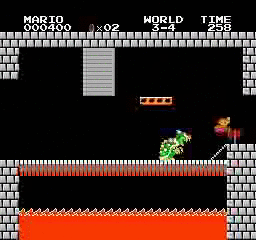
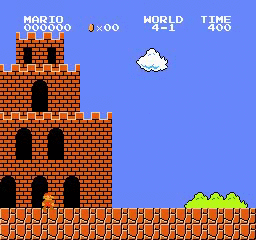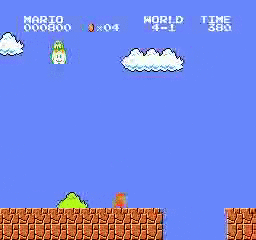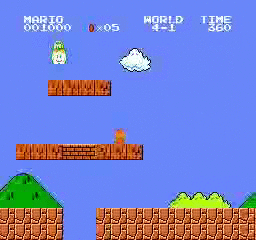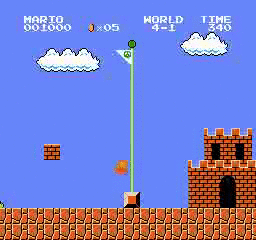
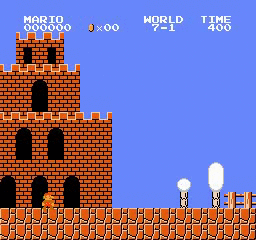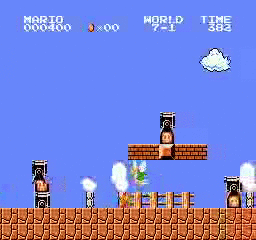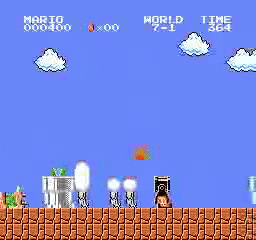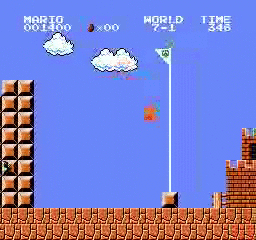
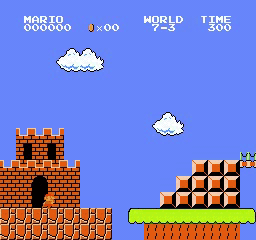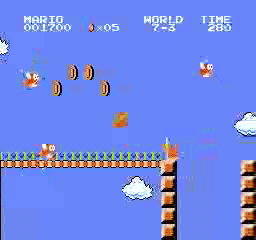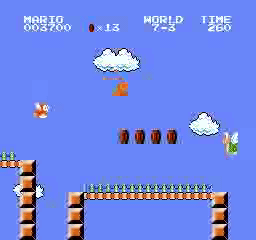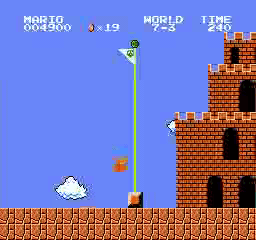
نتائج العينة
قبل تنفيذ هذا المشروع ، هناك العديد من المستودعات التي تستنسخ نتيجة الورقة بشكل جيد للغاية ، في أطر العمل العميقة المشتركة المختلفة مثل TensorFlow و Keras و Pytorch. في رأيي ، معظمهم رائعون. ومع ذلك ، يبدو أنها معقدة بشكل مفرط في أجزاء كثيرة بما في ذلك المعالجة المسبقة للصور ، وإعداد Envierontment وتهيئة الوزن ، والتي تصرف انتباه المستخدم عن الأمور الأكثر أهمية. لذلك ، قررت كتابة رمز أنظف ، والذي يبسط أجزاء غير مهمة ، بينما لا يزال يتبع الورقة بدقة. كما ترون ، مع الحد الأدنى من الإعداد وتهيئة الشبكة البسيطة ، طالما قمت بتنفيذ الخوارزمية بشكل صحيح ، فإن الوكيل سوف يعلم نفسه كيفية التفاعل مع البيئة ومعرفة طريقة الوصول إلى الهدف النهائي تدريجياً.
إذا كنت مألوفًا بالفعل للتعلم التعزيز بشكل عام و A3C على وجه الخصوص ، فيمكنك تخطي هذا الجزء. أكتب هذا الجزء لشرح ما هي خوارزمية A3C ، وكيف ولماذا تعمل ، للأشخاص المهتمين أو فضوليون حول A3C أو تنفيذي ، ولكن لا يفهمون الآلية وراءهم. لذلك ، لا تحتاج إلى أي معرفة مسبقة لقراءة هذا الجزء
إذا قمت بالبحث على الإنترنت ، فهناك العديد من المقالات التي تقدم أو شرح A3C ، حتى أن بعضها يوفر رمز العينة. ومع ذلك ، أود أن أتبع نهجًا آخر: تحطيم اسم العوامل الناقدة للممثل غير المتزامن إلى أجزاء أصغر وشرح بطريقة مجمعة.
لدى وكيلك جزأين يسمى الممثل والناقد ، وهدفه هو جعل كلا الجزأين أفضل مع مرور الوقت من خلال استكشاف البيئة واستغلالها. دع تخيل طفل صغير مؤذ ( ممثل ) يكتشف العالم المذهل من حوله ، بينما يشرف عليه والده ( الناقد ) ، للتأكد من أنه لا يفعل أي شيء خطير. كلما فعل الطفل أي شيء جيد ، فإن والده سيثني ويشجعه على تكرار هذا الإجراء في المستقبل. وبالطبع ، عندما يفعل الطفل أي شيء ضار ، سوف يحذر من والده. كلما زاد تفاعل الطفل مع العالم ، ويتخذ إجراءات مختلفة ، كلما زادت ردود الفعل ، الإيجابية والسلبية ، يحصل من والده. الهدف من الطفل هو جمع أكبر عدد ممكن من ردود الفعل الإيجابية من والده ، في حين أن هدف الأب هو تقييم عمل ابنه بشكل أفضل. وبعبارة أخرى ، لدينا علاقة مربحة بين الطفل ووالده ، أو ما يعادلها بين الممثل والناقد .
لجعل الطفل يتعلم بشكل أسرع ، وأكثر استقرارًا ، فإن الأب ، بدلاً من إخبار ابنه بمدى جودة عمله ، سيخبره بمدى عمله أفضل أو أسوأ في الإجراءات الأخرى (أو العمل "الافتراضي" المتوسط ). مثال يستحق ألف كلمة. دعنا نقارن زوجين من الأب والابن. أبي الأول يعطي ابنه 10 حلوى للصف 10 و 1 حلوى للصف الأول في المدرسة. الأب الثاني ، من ناحية أخرى ، يعطي ابنه 5 حلوى للصف 10 ، و "يعاقب" ابنه من خلال عدم السماح له بمشاهدة مسلسله التلفزيوني المفضل ليوم عندما يحصل على الصف الأول. كيف تعتقد؟ يبدو أن الأب الثاني أكثر ذكاءً ، أليس كذلك؟ في الواقع ، نادراً ما تمنع الإجراءات السيئة ، إذا كنت لا تزال "تشجعها" بمكافأة صغيرة.
إذا اكتشف الوكيل البيئة وحدها ، فستكون عملية التعلم بطيئة. والأهم من ذلك ، يمكن أن يكون الوكيل تحيزًا لحلًا دون المستوى الأمثل ، وهو أمر غير مرغوب فيه. ماذا يحدث إذا كان لديك مجموعة من الوكلاء الذين يكتشفون في وقت واحد جزءًا مختلفًا من البيئة وتحديث معرفتهم الجديدة التي تم الحصول عليها لبعضها البعض بشكل دوري؟ إنها بالضبط فكرة الممثل غير المتزامن . الآن لدى الطفل وزملائه في رياض الأطفال رحلة إلى شاطئ جميل (مع معلمهم ، بالطبع). مهمتهم هي بناء قلعة رمل رائعة. سوف يبني طفل مختلف أجزاء مختلفة من القلعة ، تحت إشراف المعلم. سيكون لكل منهم مهمة مختلفة ، مع نفس الهدف النهائي هو قلعة قوية وجذابة. بالتأكيد ، فإن دور المعلم الآن هو نفس أبي في المثال السابق. الفرق الوحيد هو أن الأول أكثر انشغالًا؟
مع الكود الخاص بي ، يمكنك:
يمكنك العثور على بعض النماذج المدربة التي دربتها في نماذج مدربة Super Mario Bros A3C
في البداية ، كان بإمكاني تدريب وكيلي فقط على إكمال 9 مراحل. ثم أشار Davincibj إلى أنه يمكن إكمال 19 مرحلة وأرسلت لي الأوزان المدربة. شكرا جزيلا لك على النتيجة!


