Super mario bros A3C pytorch
1.0.0
Hier ist mein Python -Quellcode für das Training eines Agenten, um Super Mario Bros zu spielen. Durch die Verwendung eines asynchronen Vorteils der Actor-kritischen (A3C) -Algorithmus, die in den Papier asynchronen Methoden für das Lernen von Tiefstärken eingeführt wurden.
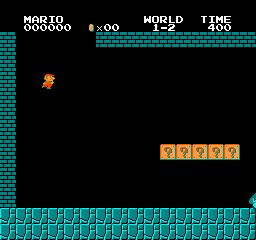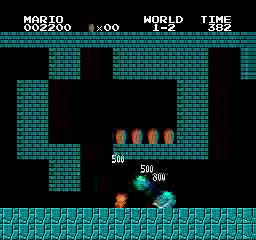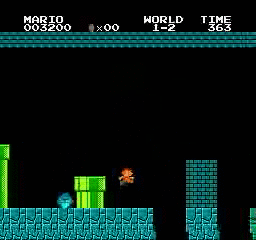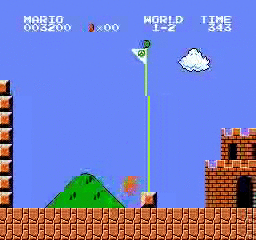

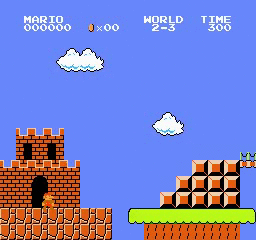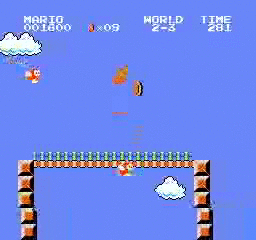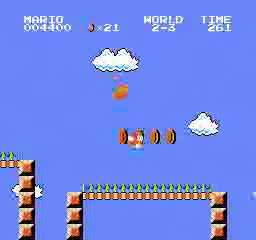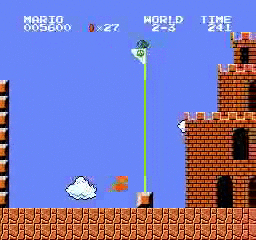
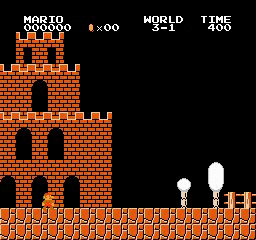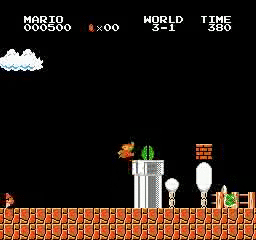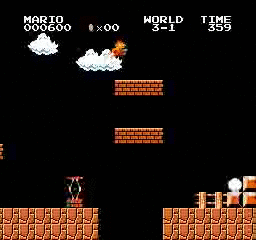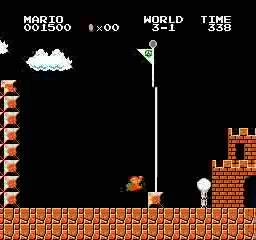
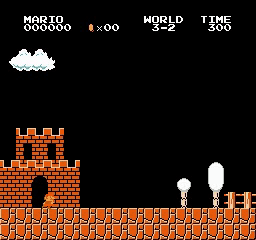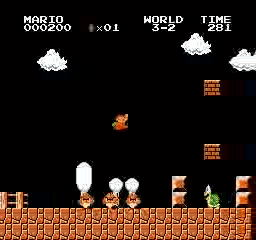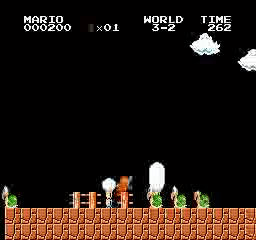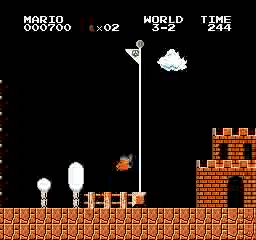
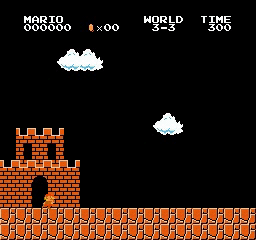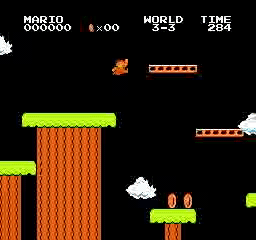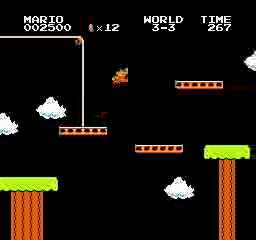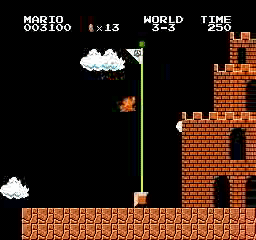
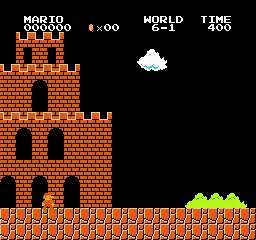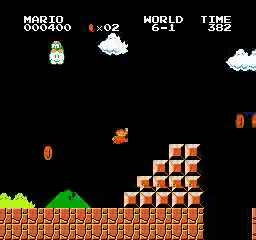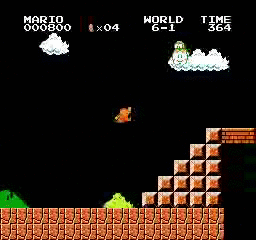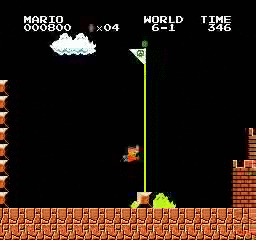
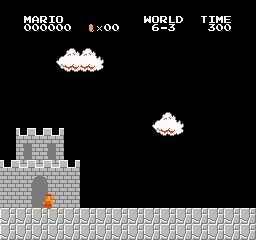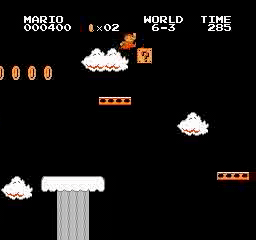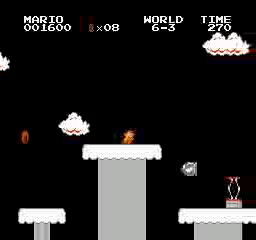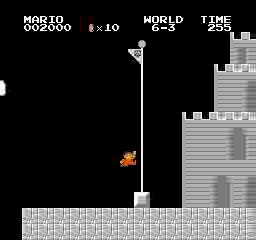
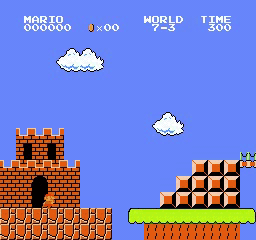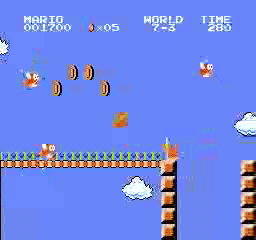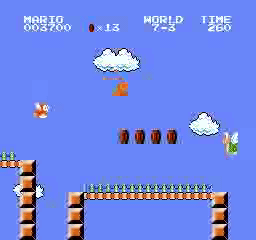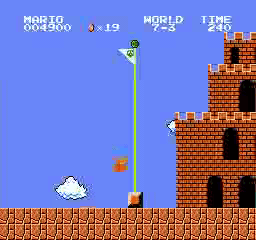
Beispielergebnisse
Bevor ich dieses Projekt implementiert habe, gibt es mehrere Repositories, die das Ergebnis des Papiers in verschiedenen gemeinsamen tiefen Lernrahmen wie Tensorflow, Keras und Pytorch recht gut reproduzieren. Meiner Meinung nach sind die meisten von ihnen großartig. Sie scheinen jedoch in vielen Teilen übermäßig kompliziert zu sein, einschließlich der Vorverarbeitung, der Umgebung und der Gewichtsinitialisierung, die die Aufmerksamkeit des Benutzers von wichtigeren Angelegenheiten ablenkt. Daher entscheide ich mich, einen saubereren Code zu schreiben, der unwichtige Teile vereinfacht, während sie dem Papier immer noch ausschließlich folgt. Wie Sie sehen konnten, lehrt ein Agent mit minimalem Setup und der Initialisierung eines einfachen Netzwerks, solange Sie den Algorithmus korrekt implementieren, wie man mit der Umgebung interagiert und schrittweise herausfindet, wie man das endgültige Ziel erreichen kann.
Wenn Sie dem Verstärkungslernen im Allgemeinen und A3C im Besonderen bereits vertraut sind, können Sie diesen Teil überspringen. Ich schreibe diesen Teil, um zu erklären, was A3C -Algorithmus ist, wie und warum es funktioniert, Menschen, die sich für A3C oder meine Implementierung interessieren oder neugierig sind, aber den Mechanismus dahinter nicht verstehen. Daher benötigen Sie kein Vorauskenntnis zum Lesen dieses Teils
Wenn Sie im Internet suchen, gibt es zahlreiche Artikel, die A3C einführen oder erklären. Einige bieten sogar Beispielcode an. Ich möchte jedoch einen anderen Ansatz verfolgen: den Namen Asynchroner Schauspieler-Kritiker in kleinere Teile aufzuteilen und auf aggregierte Weise zu erklären.
Ihr Agent hat 2 Teile, die als Schauspieler und Kritiker bezeichnet werden, und sein Ziel ist es, beide Teile im Laufe der Zeit besser durchzuführen, indem sie die Umwelt erkundet und ausnutzt. Stellen Sie sich vor, ein kleines schelmisches Kind ( Schauspieler ) entdeckt die erstaunliche Welt um ihn herum, während sein Vater ( Kritiker ) ihn überwacht, um sicherzustellen, dass er nichts Gefährliches tut. Immer wenn das Kind etwas Gutes tut, wird sein Vater ihn loben und ermutigen, diese Handlung in Zukunft zu wiederholen. Und wenn das Kind etwas Schädliches tut, wird es natürlich vor seinem Vater warnen. Je mehr das Kind mit der Welt interagiert und unterschiedliche Handlungen wirkt, desto mehr Feedback, sowohl positiv als auch negativ, erhält er von seinem Vater. Das Ziel des Kindes ist es, von seinem Vater so viele positive Feedback wie möglich zu sammeln, während das Ziel des Vaters es ist, die Handlung seines Sohnes besser zu bewerten. Mit anderem haben wir eine Win-Win-Beziehung zwischen dem Kind und seinem Vater oder gleichmäßig zwischen Schauspieler und Kritiker .
Damit das Kind schneller und stabiler lernen kann, wird der Vater, anstatt seinem Sohn zu sagen, wie gut seine Handlung ist, ihm sagen, wie besser oder schlimmer seine Aktion im Vergleich zu anderen Aktionen (oder einer "virtuellen" durchschnittlichen Aktion ). Ein Beispiel ist mehr als tausend Worte. Vergleichen wir 2 Paar Vater und Sohn. Der erste Vater gibt seinem Sohn 10 Süßigkeiten für die 10. Klasse und 1 Süßigkeiten für die 1 -Klasse in der Schule. Der zweite Vater hingegen gibt seinem Sohn 5 Süßigkeiten für die 10. Klasse und "bestraft" seinen Sohn, indem er ihm nicht erlaubt, seine Lieblingsfernsehserie für einen Tag zu sehen, an dem er die Klasse 1. Klasse bekommt. Wie denkst du? Der zweite Vater scheint ein bisschen schlauer zu sein, oder? In der Tat könnten Sie selten schlechte Handlungen verhindern, wenn Sie sie immer noch mit geringer Belohnung "ermutigen".
Wenn ein Agent die Umgebung allein entdeckt, wäre der Lernprozess langsam. Im Ernst, der Agent könnte möglicherweise eine bestimmte suboptimale Lösung sein, die unerwünscht ist. Was passiert, wenn Sie eine Reihe von Agenten haben, die gleichzeitig einen unterschiedlichen Teil der Umwelt entdecken und ihr neues erworbenes Wissen regelmäßig miteinander aktualisieren? Es ist genau die Idee des asynchronen Vorteils-Schauspielers . Jetzt haben das Kind und seine Kumpels im Kindergarten einen Ausflug zu einem schönen Strand (natürlich mit ihrem Lehrer). Ihre Aufgabe ist es, eine tolle Sandburg zu bauen. Anderes Kind baut verschiedene Teile des Schlosses, die vom Lehrer beaufsichtigt wurden. Jeder von ihnen hat eine andere Aufgabe, mit dem gleichen endgültigen Ziel ist eine starke und auffällige Burg. Die Rolle des Lehrers ist sicherlich die gleiche wie der Vater im vorherigen Beispiel. Der einzige Unterschied ist, dass der erstere geschäftiger ist?
Mit meinem Code können Sie:
Sie konnten einige ausgebildete Models finden, die ich in Super Mario Bros A3C ausgebildeten Models trainiert habe
Am Anfang konnte ich meinen Agenten nur auf 9 Etappen ausbilden. Dann wies @Davincibj darauf hin, dass 19 Stufen fertiggestellt werden könnten, und schickte mir die geschulten Gewichte. Vielen Dank für die Erkenntnis!


