Super mario bros A3C pytorch
1.0.0
Aquí está mi código fuente de Python para entrenar a un agente para jugar Super Mario Bros. Mediante el uso del algoritmo de actor-actor-crítico (A3C) de ventaja asincrónica introducido en el documento de métodos asíncronos para el papel de aprendizaje de refuerzo profundo .
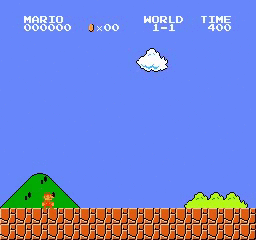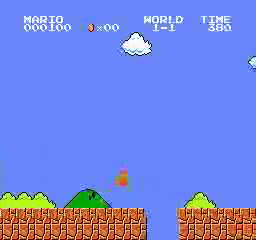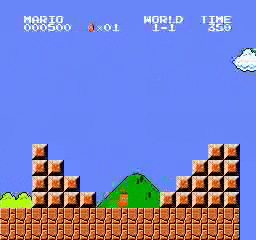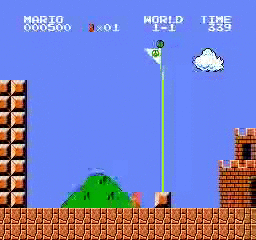
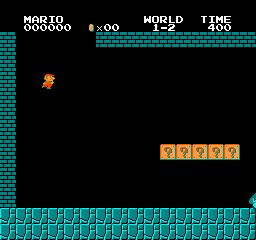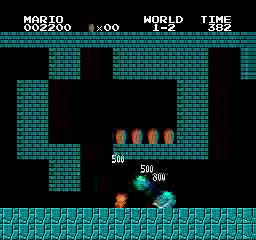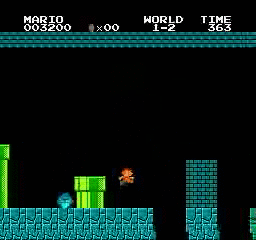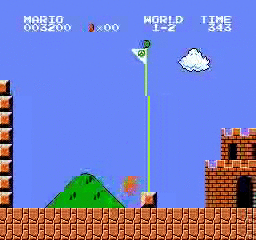
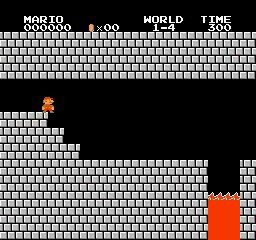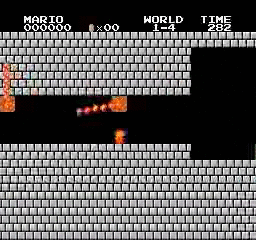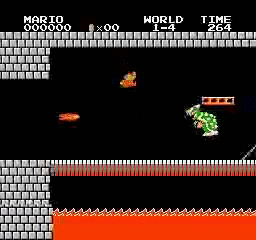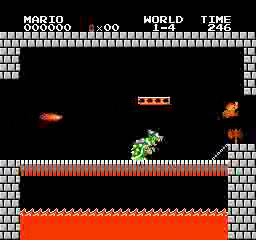

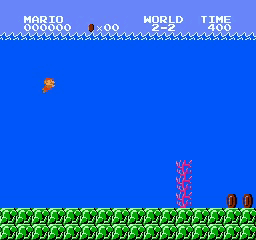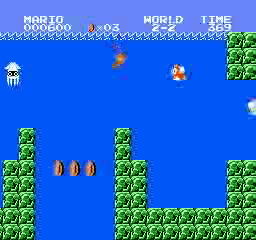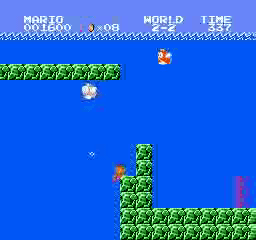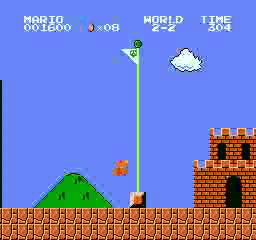
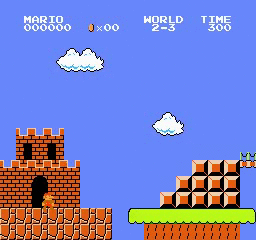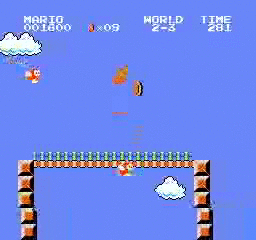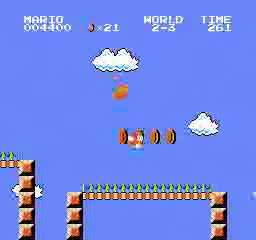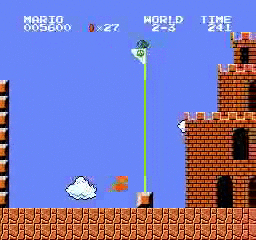
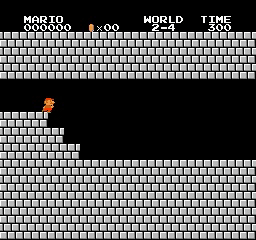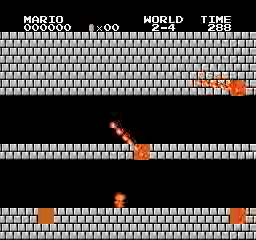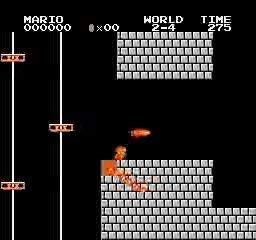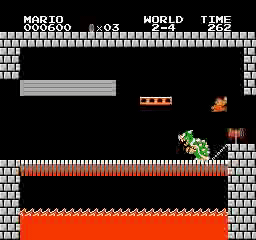
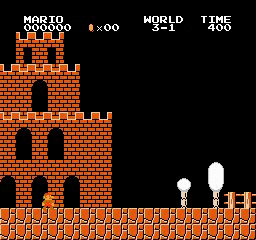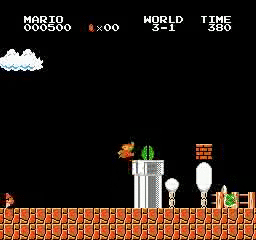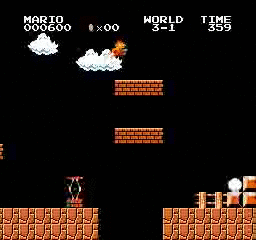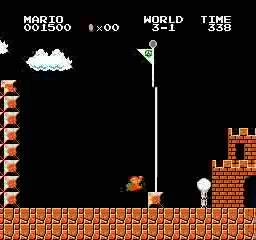
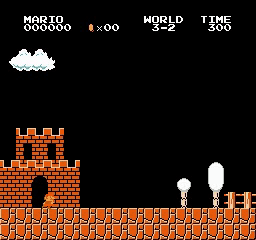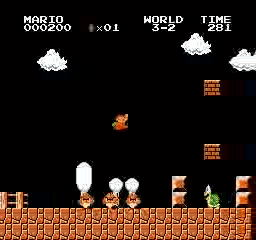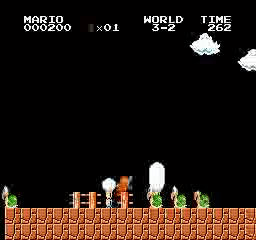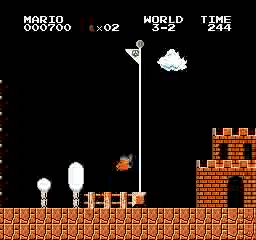
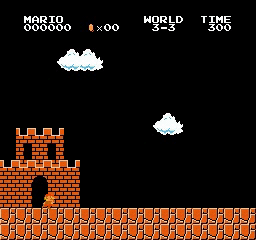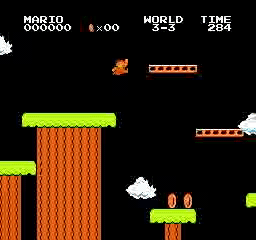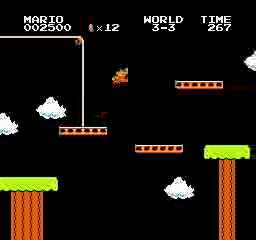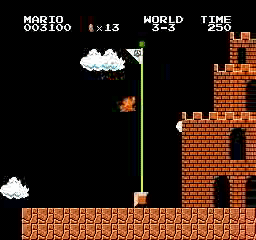
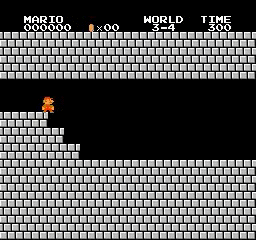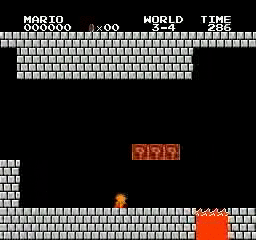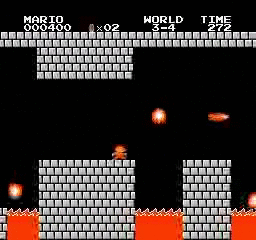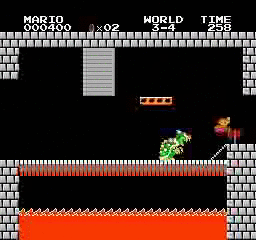
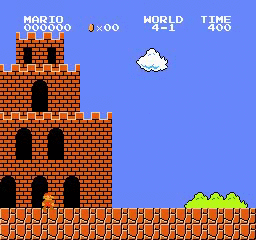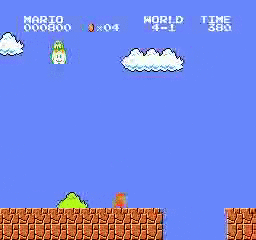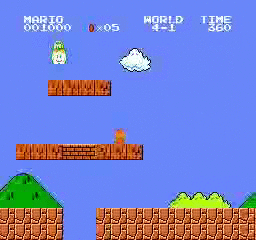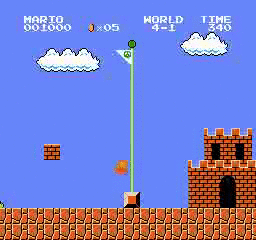
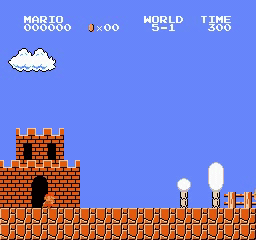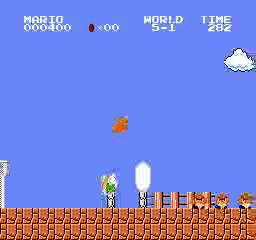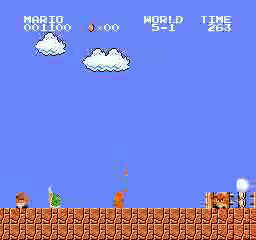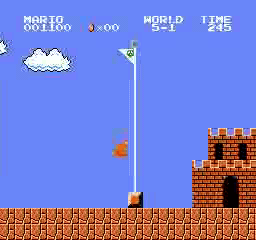
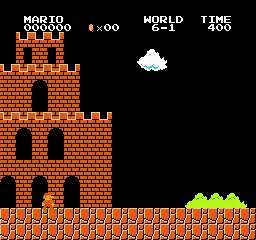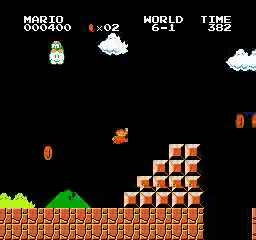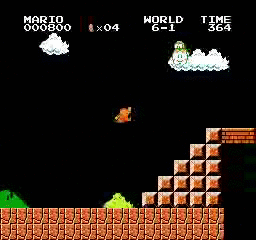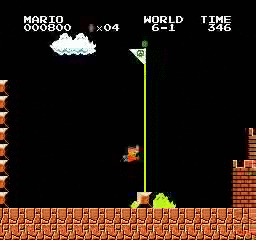
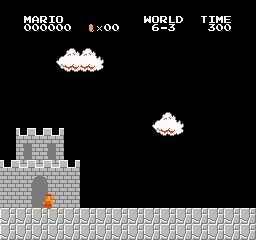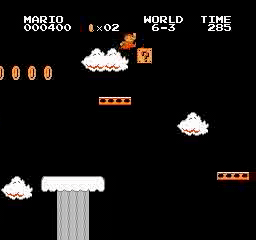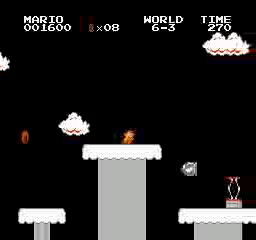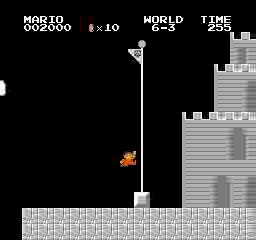
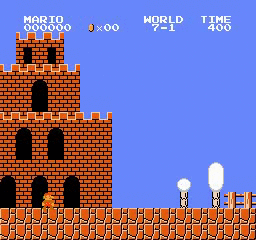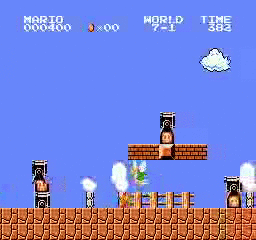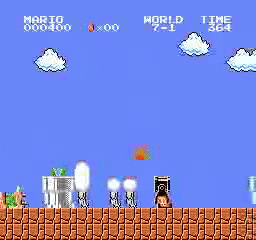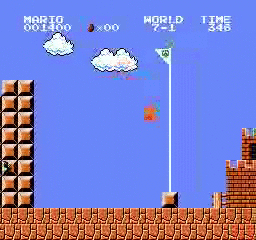
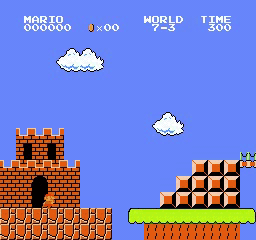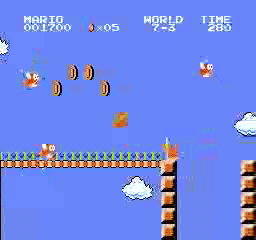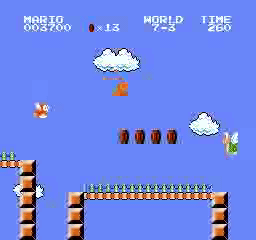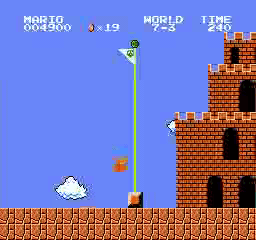
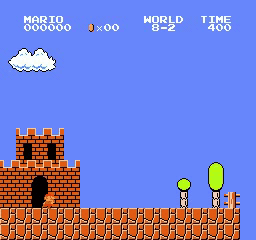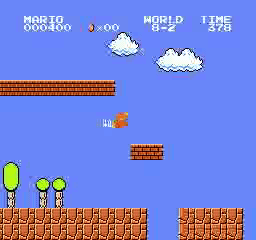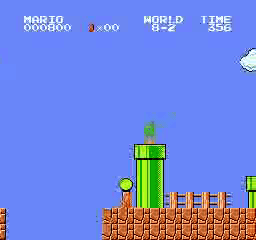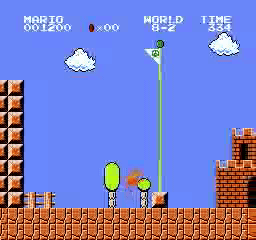
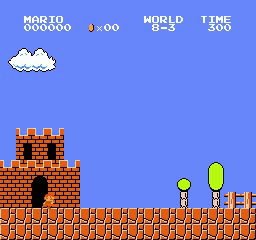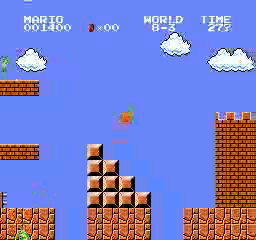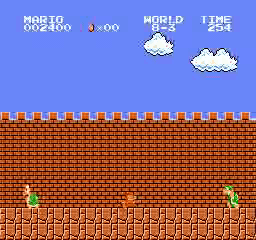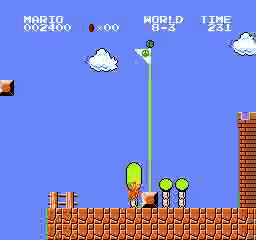
Resultados de la muestra
Antes de implementar este proyecto, hay varios repositorios que reproducen el resultado del documento bastante bien, en diferentes marcos comunes de aprendizaje profundo como TensorFlow, Keras y Pytorch. En mi opinión, la mayoría de ellos son geniales. Sin embargo, parecen ser demasiado complicados en muchas partes, incluido el preprocesamiento de Image, la configuración del compromiso y la inicialización de peso, lo que distrae la atención del usuario de asuntos más importantes. Por lo tanto, decido escribir un código más limpio, que simplifica piezas sin importancia, mientras que sigue estrictamente el documento. Como puede ver, con una configuración mínima y la inicialización de la red simple, siempre que implemente el algoritmo correctamente, un agente se enseñará cómo interactuar con el entorno y gradualmente descubrirá la manera de alcanzar el objetivo final.
Si ya está familiarizado con el aprendizaje de refuerzo en general y A3C en particular, podría omitir esta parte. Escribo esta parte para explicar qué es el algoritmo A3C, cómo y por qué funciona, a las personas interesadas o curiosas por A3C o mi implementación, pero no entienden el mecanismo detrás. Por lo tanto, no necesita ningún conocimiento previo para leer esta parte
Si busca en Internet, hay numerosos artículos que presentan o explican A3C, algunos incluso proporcionan código de muestra. Sin embargo, me gustaría adoptar otro enfoque: desglose el nombre de los agentes de actor asíncrono-crítico en partes más pequeñas y explique de manera agregada.
Su agente tiene 2 partes llamadas actor y crítico , y su objetivo es mejorar las dos partes con el tiempo explorando y explotando el medio ambiente. Imagine que un pequeño niño travieso ( actor ) está descubriendo el increíble mundo que lo rodea, mientras su padre ( crítico ) lo supervisa, para asegurarse de que no haga nada peligroso. Cada vez que el niño hace algo bueno, su padre lo alabará y lo alentará a repetir esa acción en el futuro. Y, por supuesto, cuando el niño hace algo dañino, recibirá advertencia de su padre. Cuanto más interactúa el niño con el mundo y toma acciones diferentes, más retroalimentación, tanto positiva como negativa, se obtiene de su padre. El objetivo del niño es recopilar tantos comentarios positivos como sea posible de su padre, mientras que el objetivo del padre es evaluar mejor la acción de su hijo. En otra palabra, tenemos una relación beneficiosa entre el niño y su padre, o de manera equivalente entre el actor y el crítico .
Hacer que el niño aprenda más rápido y más estable, el padre, en lugar de decirle a su hijo cuán buena es su acción, le dirá cuán mejor o peor es su acción en comparación con otras acciones (o una acción promedio "virtual" ). Un ejemplo vale más que mil palabras. Comparemos 2 pares de papá e hijo. El primer padre le da a su hijo 10 dulces para el grado 10 y 1 de dulces para el grado 1 en la escuela. El segundo padre, por otro lado, le da a su hijo 5 dulces para el grado 10, y "castiga" a su hijo al no permitirle ver su serie de televisión favorita por un día en que obtiene el grado 1. ¿Cómo piensas? El segundo papá parece ser un poco más inteligente, ¿verdad? De hecho, rara vez podría prevenir malas acciones, si aún las "alienta" con una pequeña recompensa.
Si un agente descubre solo el entorno, el proceso de aprendizaje sería lento. Más en serio, el agente podría ser posiblemente un sesgo a una solución subóptima particular, que no es deseable. ¿Qué pasa si tiene un montón de agentes que simultáneamente descubren una parte diferente del entorno y actualizan su nuevo conocimiento obtenido entre sí periódicamente? Es exactamente la idea de la ventaja asincrónica actor-crítico . Ahora el niño y sus compañeros en el jardín de infantes tienen un viaje a una hermosa playa (con su maestro, por supuesto). Su tarea es construir un gran castillo de arena. Diferentes niños construirán diferentes partes del castillo, supervisadas por el maestro. Cada uno de ellos tendrá una tarea diferente, con el mismo objetivo final es un castillo fuerte y llamativo. Ciertamente, el papel del maestro ahora es el mismo que el papá en el ejemplo anterior. La única diferencia es que el primero está más ocupado?
Con mi código, puedes:
Podrías encontrar algunos modelos entrenados que he entrenado en modelos entrenados de Super Mario Bros A3C
Al principio, solo pude entrenar a mi agente para completar 9 etapas. Luego, @Davincibj señaló que 19 etapas podrían completarse y enviarme los pesos entrenados. ¡Muchas gracias por el hallazgo!


