Super mario bros A3C pytorch
1.0.0
Ini kode sumber Python saya untuk melatih agen untuk bermain Super Mario Bros. Dengan menggunakan algoritma Actor-Critic (A3C) Asynchronous Advantage yang diperkenalkan dalam Metode Asinkron Kertas untuk Kertas Pembelajaran Penguatan yang mendalam .
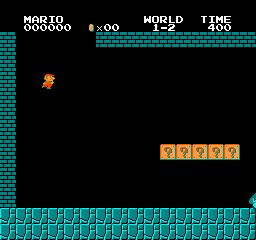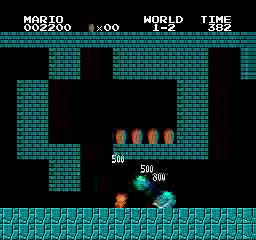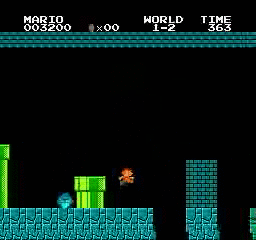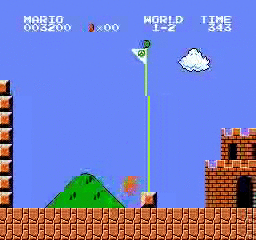

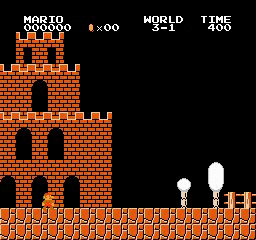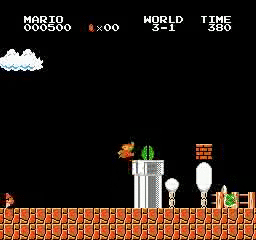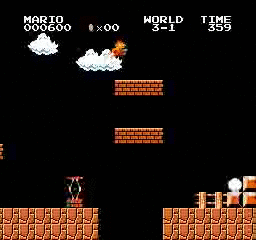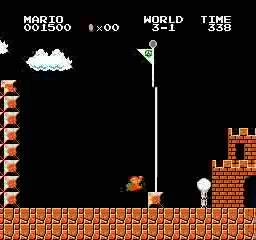
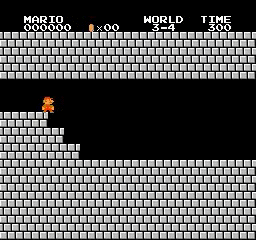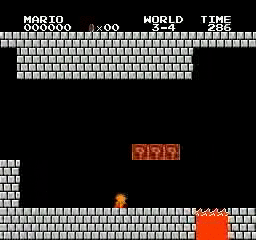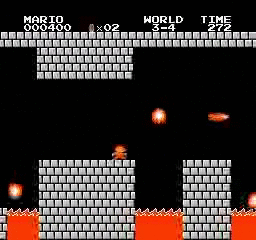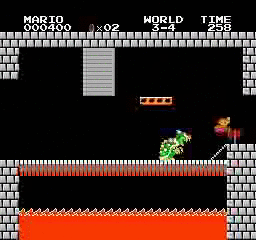
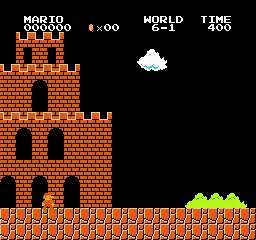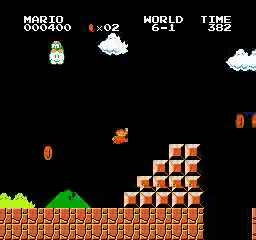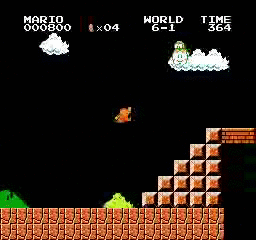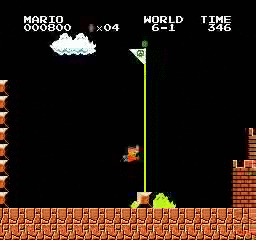
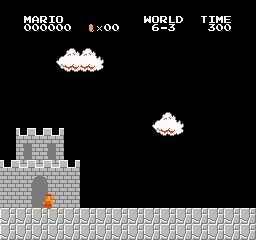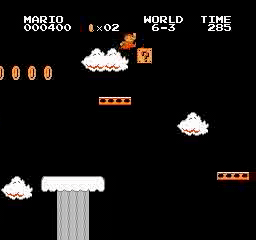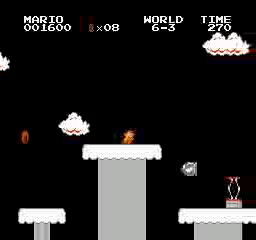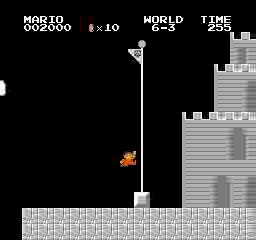
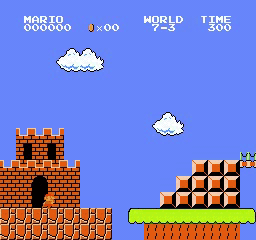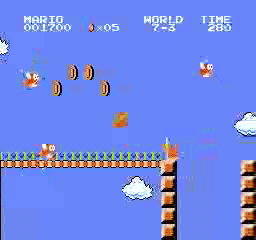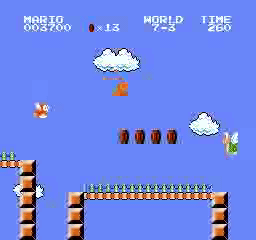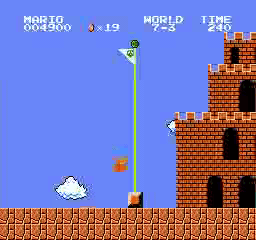
Hasil sampel
Sebelum saya mengimplementasikan proyek ini, ada beberapa repositori yang mereproduksi hasil kertas dengan cukup baik, dalam kerangka pembelajaran mendalam yang berbeda seperti TensorFlow, Keras dan Pytorch. Menurut pendapat saya, kebanyakan dari mereka hebat. Namun, mereka tampaknya terlalu rumit di banyak bagian termasuk pra-pemrosesan gambar, pengaturan lingkungan dan inisialisasi berat, yang mengalihkan perhatian pengguna dari hal-hal yang lebih penting. Oleh karena itu, saya memutuskan untuk menulis kode yang lebih bersih, yang menyederhanakan bagian yang tidak penting, sementara masih mengikuti kertas secara ketat. Seperti yang Anda lihat, dengan pengaturan minimal dan inisialisasi jaringan sederhana, selama Anda menerapkan algoritma dengan benar, agen akan mengajari dirinya sendiri bagaimana berinteraksi dengan lingkungan dan secara bertahap mencari tahu cara untuk mencapai tujuan akhir.
Jika Anda sudah akrab dengan pembelajaran penguatan secara umum dan A3C pada khususnya, Anda dapat melewatkan bagian ini. Saya menulis bagian ini untuk menjelaskan apa itu algoritma A3C, bagaimana dan mengapa itu bekerja, kepada orang -orang yang tertarik atau ingin tahu tentang A3C atau implementasi saya, tetapi tidak memahami mekanisme di baliknya. Oleh karena itu, Anda tidak memerlukan pengetahuan prasyarat untuk membaca bagian ini
Jika Anda mencari di internet, ada banyak artikel yang memperkenalkan atau menjelaskan A3C, beberapa bahkan memberikan kode sampel. Namun, saya ingin mengambil pendekatan lain: memecah nama agen aktor-kritik asinkron menjadi bagian yang lebih kecil dan menjelaskan secara agregat.
Agen Anda memiliki 2 bagian yang disebut aktor dan kritikus , dan tujuannya adalah membuat kedua bagian lebih baik dari waktu ke waktu dengan menjelajahi dan mengeksploitasi lingkungan. Bayangkan seorang anak kecil nakal ( aktor ) menemukan dunia yang menakjubkan di sekitarnya, sementara ayahnya ( kritikus ) mengawasi dia, untuk memastikan bahwa dia tidak melakukan sesuatu yang berbahaya. Setiap kali anak itu melakukan sesuatu yang baik, ayahnya akan memuji dan mendorongnya untuk mengulangi tindakan itu di masa depan. Dan tentu saja, ketika anak itu melakukan sesuatu yang berbahaya, dia akan mendapatkan peringatan dari ayahnya. Semakin banyak anak berinteraksi dengan dunia, dan mengambil tindakan yang berbeda, semakin banyak umpan balik, baik positif maupun negatif, ia mendapatkan dari ayahnya. Tujuan anak itu adalah, untuk mengumpulkan umpan balik positif sebanyak mungkin dari ayahnya, sementara tujuan ayah adalah untuk mengevaluasi tindakan putranya dengan lebih baik. Dengan kata lain, kami memiliki hubungan win-win antara anak dan ayahnya, atau setara antara aktor dan kritikus .
Untuk membuat anak itu belajar lebih cepat, dan lebih stabil, ayah, alih -alih memberi tahu putranya betapa baiknya tindakannya, akan memberi tahu dia seberapa baik atau lebih buruk tindakannya dibandingkan dengan tindakan lain (atau tindakan rata -rata "virtual" ). Contohnya bernilai ribuan kata. Mari kita bandingkan 2 pasang ayah dan anak. Ayah pertama memberi putranya 10 permen untuk permen kelas 10 dan 1 untuk kelas 1 di sekolah. Ayah kedua, di sisi lain, memberi putranya 5 permen untuk kelas 10, dan "menghukum" putranya dengan tidak mengizinkannya menonton serial TV favoritnya untuk hari ketika dia mendapatkan kelas 1. Bagaimana menurutmu? Ayah kedua tampaknya sedikit lebih pintar, kan? Memang, Anda jarang bisa mencegah tindakan buruk, jika Anda masih "mendorong" mereka dengan hadiah kecil.
Jika agen menemukan lingkungan saja, proses pembelajaran akan lambat. Lebih serius, agen mungkin bias untuk solusi suboptimal tertentu, yang tidak diinginkan. Apa yang terjadi jika Anda memiliki banyak agen yang secara bersamaan menemukan bagian lingkungan yang berbeda dan memperbarui pengetahuan baru mereka yang diperoleh satu sama lain secara berkala? Persisnya ide aktor asinkron . Sekarang anak dan teman -temannya di taman kanak -kanak memiliki perjalanan ke pantai yang indah (dengan guru mereka, tentu saja). Tugas mereka adalah membangun kastil pasir yang hebat. Anak yang berbeda akan membangun bagian kastil yang berbeda, diawasi oleh guru. Masing-masing dari mereka akan memiliki tugas yang berbeda, dengan tujuan akhir yang sama adalah kastil yang kuat dan menarik. Tentu saja, peran guru sekarang sama dengan ayah dalam contoh sebelumnya. Satu -satunya perbedaan adalah yang pertama lebih sibuk?
Dengan kode saya, Anda dapat:
Anda dapat menemukan beberapa model terlatih yang telah saya latih dalam model terlatih Super Mario Bros A3C
Pada awalnya, saya hanya bisa melatih agen saya untuk menyelesaikan 9 tahap. Kemudian @Davincibj menunjukkan bahwa 19 tahap dapat diselesaikan dan mengirimi saya bobot terlatih. Terima kasih banyak atas temuannya!


