Super mario bros A3C pytorch
1.0.0
Voici mon code source Python pour la formation d'un agent pour jouer à Super Mario Bros. En utilisant un algorithme ASynchrone Advantage acteur-critique (A3C) introduit dans le papier Méthodes asynchrones pour le papier d'apprentissage en renforcement profond .

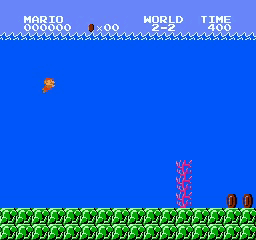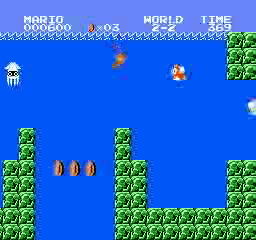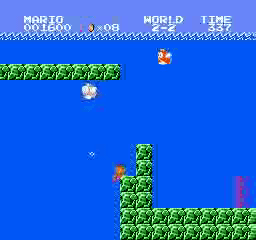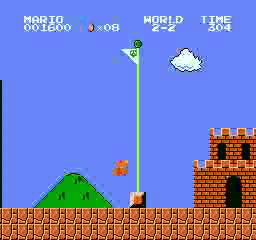
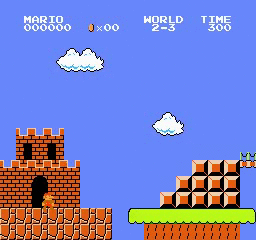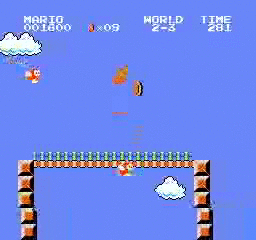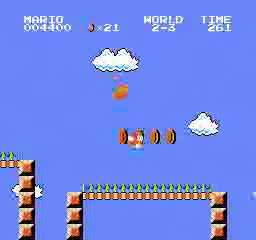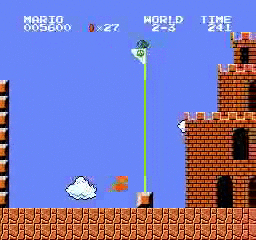
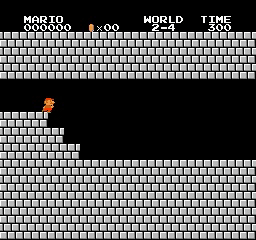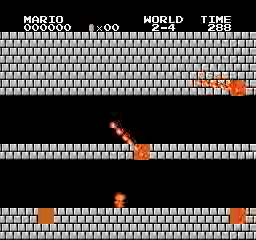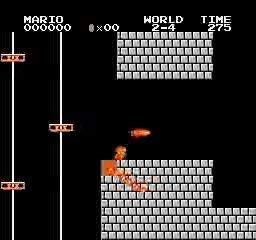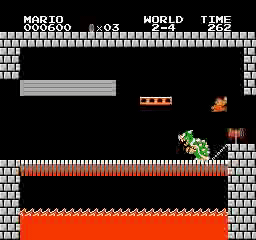
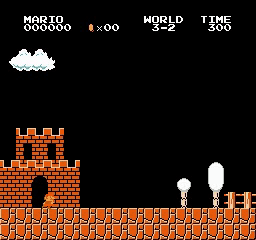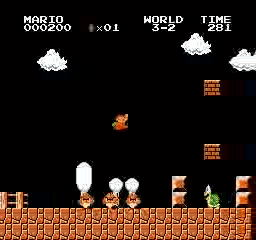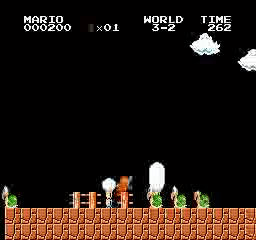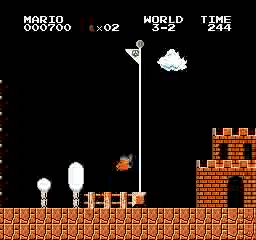
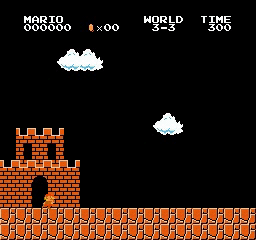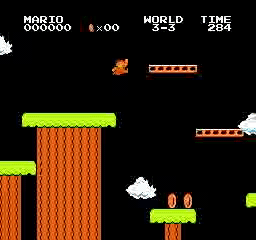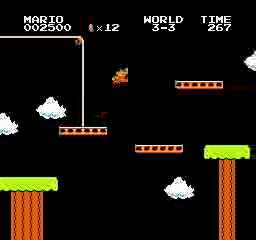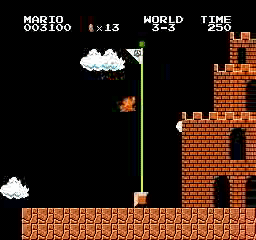
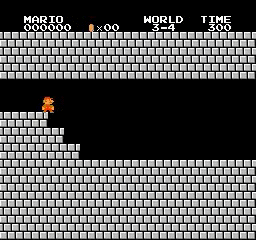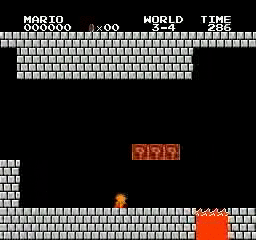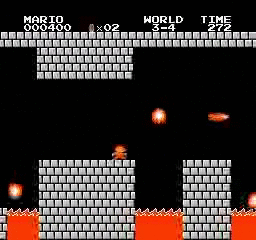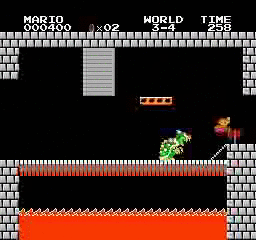
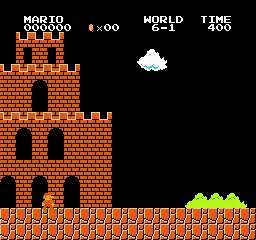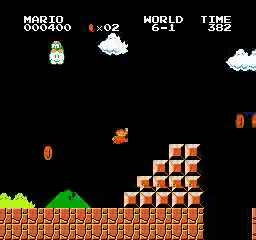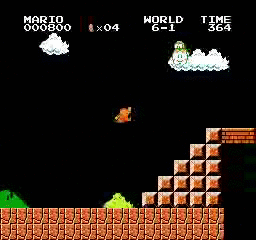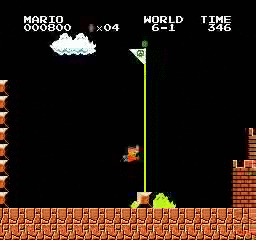
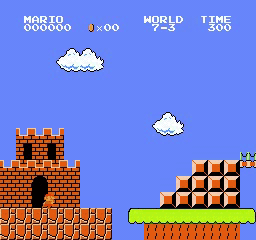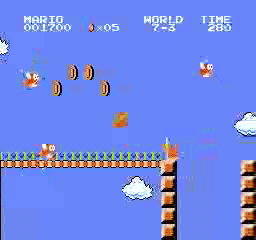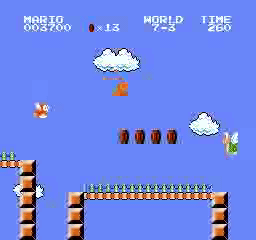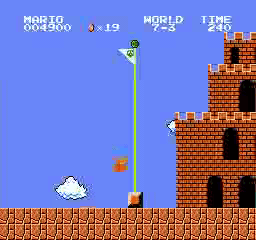
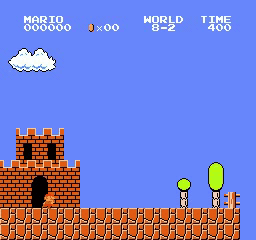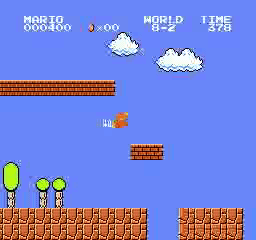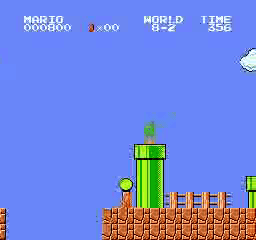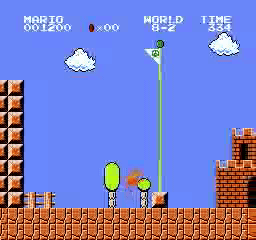
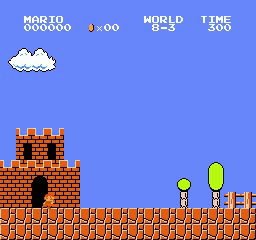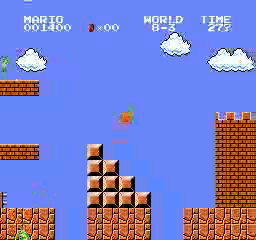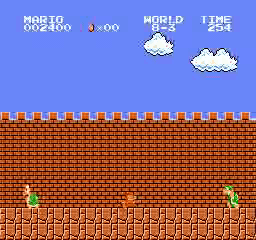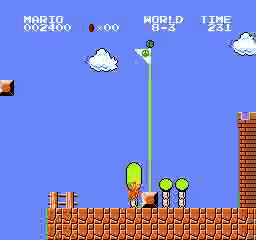
Exemples de résultats
Avant de mettre en œuvre ce projet, plusieurs référentiels reproduisant assez bien le résultat du document, dans différents cadres d'apprentissage en profondeur communs tels que TensorFlow, Keras et Pytorch. À mon avis, la plupart d'entre eux sont super. Cependant, ils semblent être trop compliqués dans de nombreuses parties, notamment le prétraitement de l'image, la configuration de l'environnement et l'initialisation de poids, qui distrait l'attention de l'utilisateur des questions plus importantes. Par conséquent, je décide d'écrire un code plus propre, qui simplifie les pièces sans importance, tout en suit strictement le papier. Comme vous pouvez le voir, avec une configuration minimale et l'initialisation du réseau simple, tant que vous implémentez correctement l'algorithme, un agent s'apprendra à interagir avec l'environnement et à découvrir progressivement le moyen d'atteindre l'objectif final.
Si vous êtes déjà familier à l'apprentissage du renforcement en général et à A3C en particulier, vous pouvez ignorer cette partie. J'écris cette partie pour expliquer ce qu'est l'algorithme A3C, comment et pourquoi cela fonctionne, aux personnes qui s'intéressent ou qui sont curieuses à propos de l'A3C ou de ma mise en œuvre, mais ne comprennent pas le mécanisme derrière. Par conséquent, vous n'avez pas besoin de connaissances préalables pour lire cette partie
Si vous recherchez sur Internet, il existe de nombreux articles introduisant ou expliquant A3C, certains fournissent même un exemple de code. Cependant, je voudrais adopter une autre approche: décomposer le nom des agents acteurs asynchrones-critiques en parties plus petites et expliquer de manière agrégée.
Votre agent a 2 parties appelé acteur et critique , et son objectif est d'améliorer les deux pièces au fil du temps en explorant et en exploitant l'environnement. Imaginez un petit enfant espiègle ( acteur ) découvre le monde incroyable autour de lui, tandis que son père ( critique ) le supervise, pour s'assurer qu'il ne fait rien de dangereux. Chaque fois que l'enfant fait quelque chose de bien, son père le louera et l'encourage à répéter cette action à l'avenir. Et bien sûr, lorsque l'enfant fera quelque chose de nocif, il obtiendra un avertissement de son père. Plus l'enfant interagit au monde et prend différentes actions, plus il y a de commentaires, à la fois positifs et négatifs, il obtient de son père. Le but de l'enfant est de collecter autant de commentaires positifs que possible de son père, tandis que le but du père est d'évaluer mieux l'action de son fils. En un autre mot, nous avons une relation gagnant-gagnant entre l'enfant et son père, ou équivalemment entre l'acteur et le critique .
Pour que l'enfant apprenne plus vite et plus stable, le père, au lieu de dire à son fils à quel point son action est bonne, lui dira à quel point son action est meilleure ou pireuse par rapport à d'autres actions (ou une action moyenne "virtuelle" ). Un exemple vaut mille mots. Comparons 2 paires de papas et de fils. Le premier papa donne à son fils 10 bonbons pour la 10e année et 1 bonbons pour la première année à l'école. Le deuxième père, en revanche, donne à son fils 5 bonbons pour la 10e année et "punit" son fils en ne lui permettant pas de regarder sa série télévisée préférée pendant une journée quand il obtient une année 1. Comment pensez-vous? Le deuxième papa semble être un peu plus intelligent, non? En effet, vous pourriez rarement empêcher de mauvaises actions, si vous les "encouragez" avec une petite récompense.
Si un agent découvre seul l'environnement, le processus d'apprentissage serait lent. Plus sérieusement, l'agent pourrait être éventuellement biaisé à une solution sous-optimale particulière, qui n'est pas souhaitable. Que se passe-t-il si vous avez un tas d'agents qui découvrent simultanément une partie de l'environnement et mettent à jour leurs nouvelles connaissances obtenues les unes avec les autres? C'est exactement l'idée de l'avantage asynchrone acteur-critique . Maintenant, l'enfant et ses amis à la maternelle ont un voyage sur une belle plage (avec leur professeur, bien sûr). Leur tâche consiste à construire un grand château de sable. Différents enfants construiront différentes parties du château, supervisée par l'enseignant. Chacun d'eux aura une tâche différente, le même objectif final est un château fort et accrocheur. Certes, le rôle de l'enseignant est maintenant le même que le père dans l'exemple précédent. La seule différence est que le premier est plus occupé?
Avec mon code, vous pouvez:
Vous pourriez trouver des modèles qualifiés que j'ai formés aux modèles formés Super Mario Bros A3C
Au début, je ne pouvais entraîner mon agent que pour terminer 9 étapes. Ensuite, @davincibj a souligné que 19 étapes pouvaient être achevées et m'ont envoyé les poids formés. Merci beaucoup pour la découverte!


