Super mario bros A3C pytorch
1.0.0
นี่คือซอร์สโค้ด Python ของฉันสำหรับการฝึกอบรมตัวแทนเพื่อเล่น Super Mario Bros โดยใช้อัลกอริทึมนักแสดง Asynchronous Advantage-Critic (A3C) ที่แนะนำใน วิธีการแบบอะซิงโครนัสกระดาษสำหรับกระดาษเรียนรู้การเสริมแรงลึก
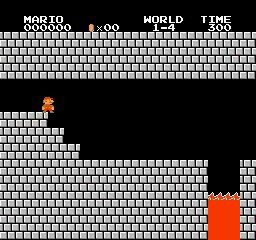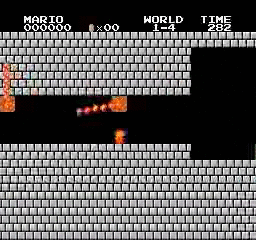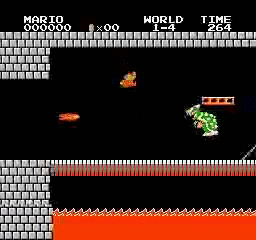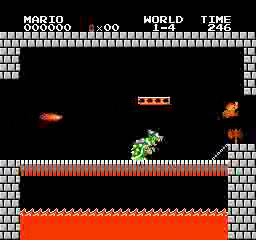

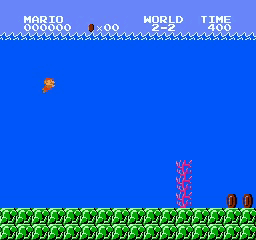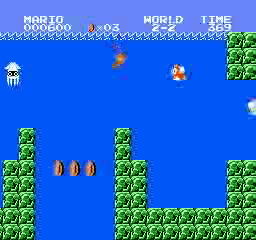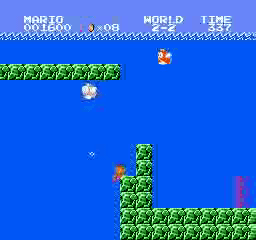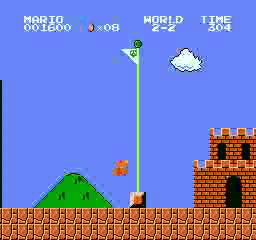
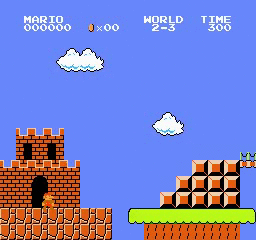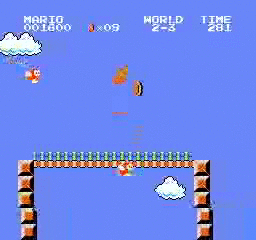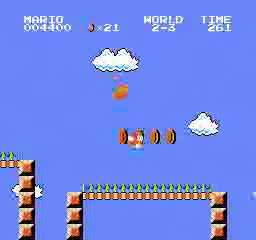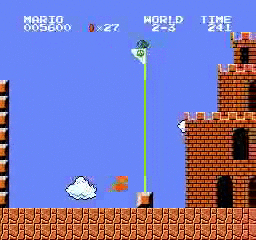
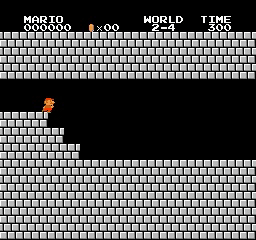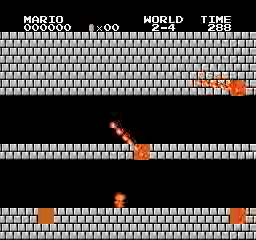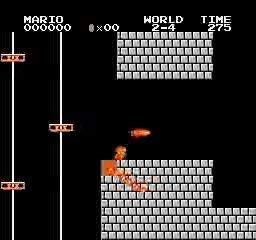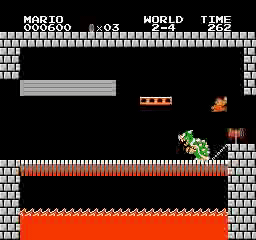
ตัวอย่างผลลัพธ์
ก่อนที่ฉันจะดำเนินโครงการนี้มีที่เก็บหลายแห่งที่ทำซ้ำผลลัพธ์ของกระดาษค่อนข้างดีในกรอบการเรียนรู้ที่ลึกซึ้งทั่วไปเช่น Tensorflow, Keras และ Pytorch ในความคิดของฉันส่วนใหญ่ของพวกเขายอดเยี่ยม อย่างไรก็ตามดูเหมือนว่าพวกเขาจะซับซ้อนมากเกินไปในหลาย ๆ ส่วนรวมถึงการประมวลผลล่วงหน้าของ Image การตั้งค่าสภาพแวดล้อมและการเริ่มต้นน้ำหนักซึ่งเบี่ยงเบนความสนใจของผู้ใช้จากเรื่องที่สำคัญกว่า ดังนั้นฉันตัดสินใจที่จะเขียนรหัสที่สะอาดซึ่งทำให้ชิ้นส่วนที่ไม่สำคัญง่ายขึ้นในขณะที่ยังคงติดตามกระดาษอย่างเคร่งครัด อย่างที่คุณเห็นด้วยการตั้งค่าขั้นต่ำและการเริ่มต้นของเครือข่ายอย่างง่ายตราบใดที่คุณใช้อัลกอริทึมอย่างถูกต้องตัวแทนจะสอนตัวเองถึงวิธีการโต้ตอบกับสภาพแวดล้อมและค่อยๆหาวิธีบรรลุเป้าหมายสุดท้าย
หากคุณคุ้นเคยกับการเสริมแรงการเรียนรู้โดยทั่วไปและ A3C โดยเฉพาะคุณสามารถข้ามส่วนนี้ได้ ฉันเขียนส่วนนี้เพื่ออธิบายอัลกอริทึม A3C คืออะไรและทำไมมันถึงทำงานได้อย่างไรกับคนที่สนใจหรืออยากรู้อยากเห็นเกี่ยวกับ A3C หรือการใช้งานของฉัน แต่ไม่เข้าใจกลไกเบื้องหลัง ดังนั้นคุณไม่จำเป็นต้องมีความรู้เบื้องต้นในการอ่านส่วนนี้
หากคุณค้นหาบนอินเทอร์เน็ตมีบทความมากมายที่แนะนำหรืออธิบาย A3C บางบทความยังให้รหัสตัวอย่าง อย่างไรก็ตามฉันต้องการใช้วิธีการอื่น: ทำลายชื่อ ตัวแทนนักแสดงนักแสดงแบบอะซิงโครนัส ออกเป็นส่วนเล็ก ๆ และอธิบายในลักษณะที่รวม
ตัวแทนของคุณมี 2 ส่วนที่เรียกว่า นักแสดง และ นักวิจารณ์ และเป้าหมายของมันคือการทำให้ทั้งสองส่วนสมบูรณ์ดีขึ้นเมื่อเวลาผ่านไปโดยการสำรวจและใช้ประโยชน์จากสิ่งแวดล้อม ให้ลองนึกภาพเด็กซุกซนเล็ก ๆ ( นักแสดง ) กำลังค้นพบโลกที่น่าอัศจรรย์รอบตัวเขาในขณะที่พ่อของเขา ( นักวิจารณ์ ) ดูแลเขาเพื่อให้แน่ใจว่าเขาไม่ได้ทำอะไรที่อันตราย เมื่อใดก็ตามที่เด็กทำสิ่งที่ดีพ่อของเขาจะสรรเสริญและกระตุ้นให้เขาทำซ้ำการกระทำนั้นในอนาคต และแน่นอนเมื่อเด็กทำอะไรที่เป็นอันตรายเขาจะได้รับคำเตือนจากพ่อของเขา ยิ่งเด็กมีปฏิสัมพันธ์กับโลกมากขึ้นและดำเนินการที่แตกต่างกันการตอบรับมากขึ้นทั้งในเชิงบวกและเชิงลบเขาได้รับจากพ่อของเขา เป้าหมายของเด็กคือการรวบรวมข้อเสนอแนะในเชิงบวกให้มากที่สุดจากพ่อของเขาในขณะที่เป้าหมายของพ่อคือการประเมินการกระทำของลูกชายของเขาดีขึ้น กล่าวอีกนัยหนึ่งเรามีความสัมพันธ์ที่ชนะระหว่างเด็กกับพ่อของเขาหรือเทียบเท่าระหว่าง นักแสดง และ นักวิจารณ์
เพื่อให้เด็กเรียนรู้ได้เร็วขึ้นและมีเสถียรภาพมากขึ้นพ่อแทนที่จะบอกลูกชายว่าการกระทำของเขาดีแค่ไหนจะบอกเขาว่าการกระทำของเขาดีขึ้นหรือแย่ลงเมื่อเทียบกับการกระทำอื่น ๆ (หรือ การกระทำโดยเฉลี่ย "เสมือนจริง" ) ตัวอย่างมีค่าหนึ่งพันคำ มาเปรียบเทียบพ่อและลูกชาย 2 คู่กันเถอะ พ่อคนแรกให้ลูกกวาด 10 ลูกของเขาสำหรับลูกกวาดเกรด 10 และ 1 สำหรับเกรด 1 ในโรงเรียน ในทางกลับกันพ่อคนที่สองให้ลูกอม 5 ลูกของเขาสำหรับเกรด 10 และ "ลงโทษ" ลูกชายของเขาโดยไม่อนุญาตให้เขาดูซีรีย์ทีวีที่เขาชื่นชอบเป็นเวลาหนึ่งวันเมื่อเขาได้เกรด 1 คุณคิดอย่างไร? พ่อคนที่สองดูเหมือนจะฉลาดขึ้นนิดหน่อยใช่มั้ย แน่นอนคุณไม่ค่อยป้องกันการกระทำที่ไม่ดีหากคุณยังคง "สนับสนุน" พวกเขาด้วยรางวัลเล็ก ๆ
หากตัวแทนค้นพบสภาพแวดล้อมเพียงอย่างเดียวกระบวนการเรียนรู้จะช้า อย่างจริงจังมากขึ้นตัวแทนอาจมีอคติต่อการแก้ปัญหาที่ไม่ดีโดยเฉพาะซึ่งไม่พึงประสงค์ จะเกิดอะไรขึ้นถ้าคุณมีตัวแทนจำนวนมากที่ค้นพบส่วนต่าง ๆ ของสภาพแวดล้อมและอัปเดตความรู้ใหม่ที่ได้รับจากกันเป็นระยะ? มันเป็นความคิดของ นักแสดงที่ได้เปรียบแบบอะซิงโครนัส ตอนนี้เด็กและเพื่อนของเขาในโรงเรียนอนุบาลมีการเดินทางไปยังชายหาดที่สวยงาม (กับครูของพวกเขาแน่นอน) งานของพวกเขาคือการสร้างปราสาททรายอันยิ่งใหญ่ เด็กที่แตกต่างกันจะสร้างส่วนต่าง ๆ ของปราสาทภายใต้การดูแลของครู แต่ละคนจะมีงานที่แตกต่างกันโดยมีเป้าหมายสุดท้ายเดียวกันคือปราสาทที่แข็งแกร่งและสะดุดตา แน่นอนว่าบทบาทของครูตอนนี้เหมือนกับพ่อในตัวอย่างก่อนหน้านี้ ความแตกต่างเพียงอย่างเดียวคืออดีตยุ่งกว่านี้?
ด้วยรหัสของฉันคุณสามารถ:
คุณสามารถหารุ่นที่ผ่านการฝึกอบรมบางอย่างที่ฉันได้รับการฝึกฝนในรุ่นที่ผ่านการฝึกอบรมมาแล้ว Super Mario Bros A3C
ในตอนแรกฉันสามารถฝึกอบรมตัวแทนของฉันให้เสร็จสมบูรณ์ 9 ขั้นตอน จากนั้น @davincibj ชี้ให้เห็นว่า 19 ขั้นตอนอาจเสร็จสมบูรณ์และส่งน้ำหนักที่ผ่านการฝึกอบรมมาให้ฉัน ขอบคุณมากสำหรับการค้นพบ!


