Super mario bros A3C pytorch
1.0.0
这是我的Python源代码,用于培训代理商扮演超级马里奥兄弟。通过使用异步参与者 - 批评(A3C)算法,在论文异步方法中引入了深钢筋学习论文中。
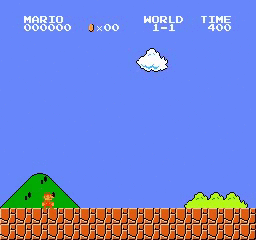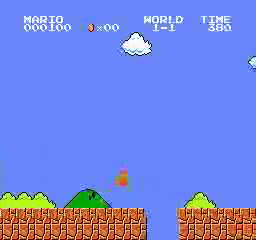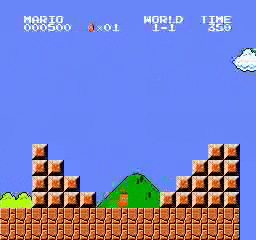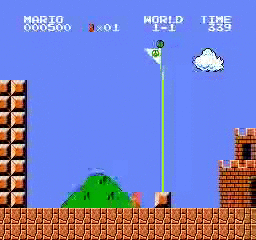
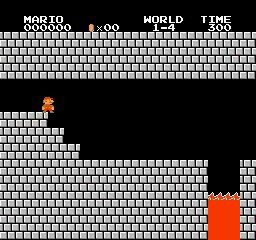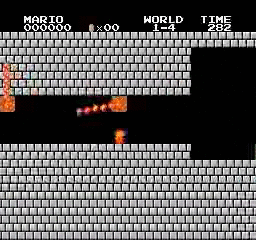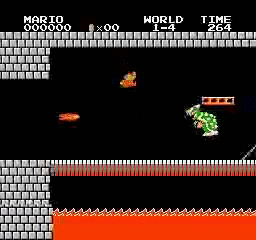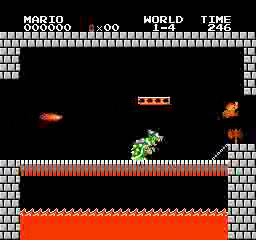

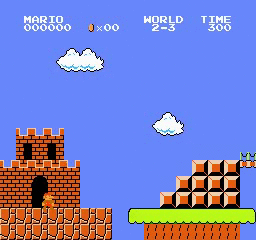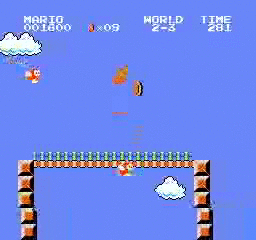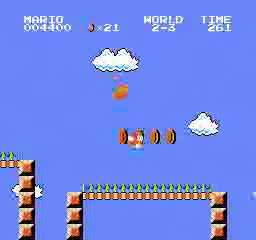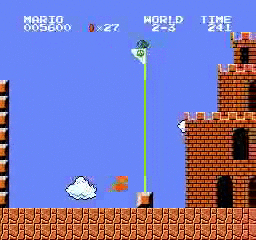
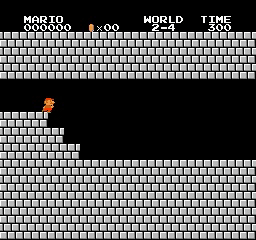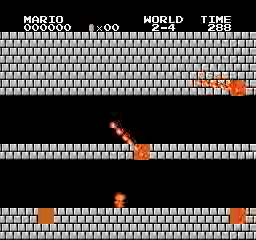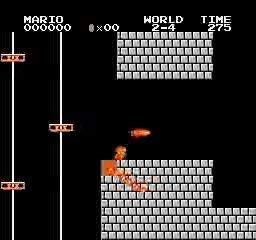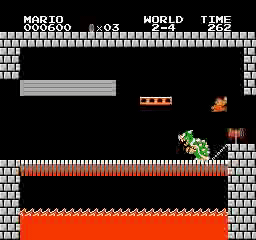
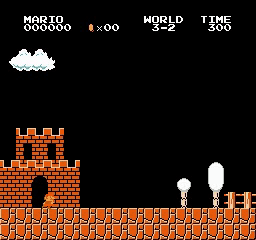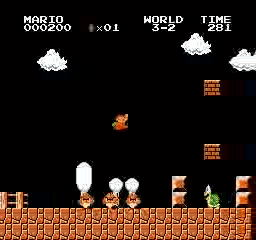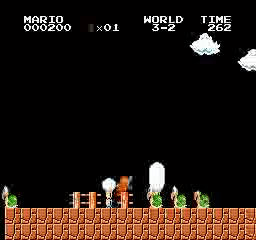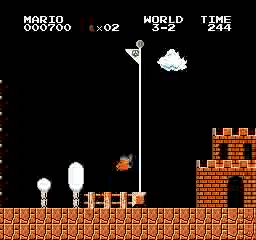
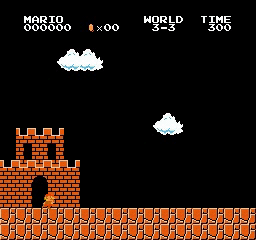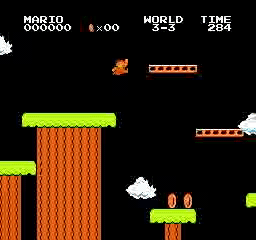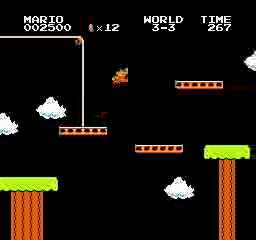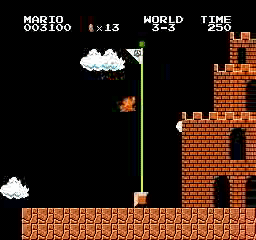
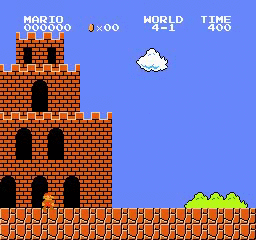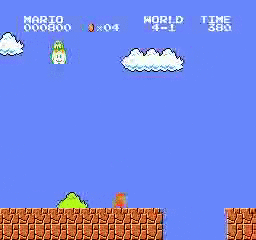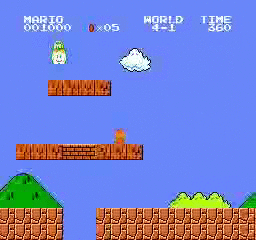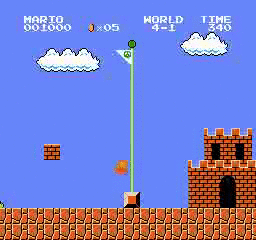
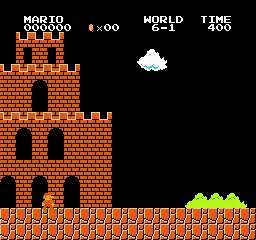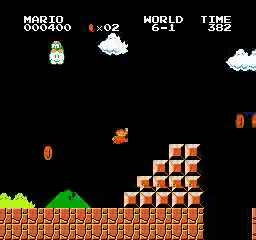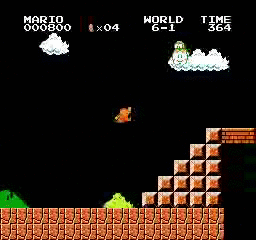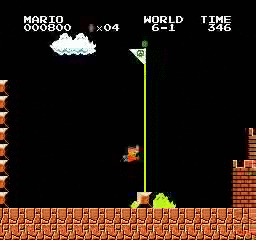
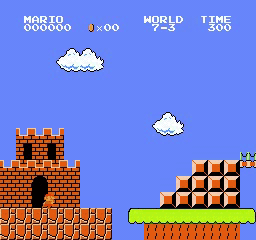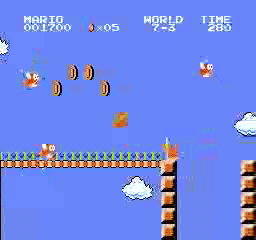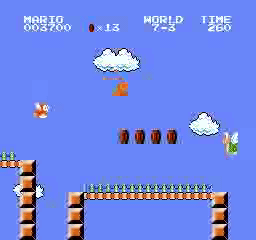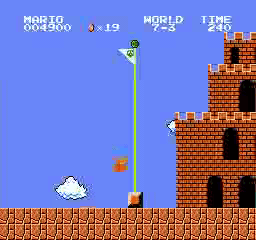
样本结果
在实施该项目之前,有几个存储库很好地复制了本文的结果,在不同的常见深度学习框架中,例如Tensorflow,Keras和Pytorch。我认为,其中大多数都很棒。但是,它们在许多部分中似乎过于复杂,包括图像的预处理,环境设置和权重初始化,这使用户的注意力分散了更重要的问题。因此,我决定编写一个清洁代码,这简化了不重要的部分,而仍然严格遵循论文。如您所见,只要您正确实现算法,代理就会教会自己如何与环境交互,并逐渐找到达到最终目标的方法,只要您正确实现算法,就可以看到最小的设置和简单网络的初始化。
如果您已经熟悉加强学习,尤其是A3C,则可以跳过此部分。我写了这部分,以解释什么是A3C算法,如何以及为什么起作用,对对A3C或我的实施感兴趣或好奇的人,但不了解背后的机制。因此,您不需要任何前知识知识来阅读此部分
如果您在Internet上搜索,则有许多文章介绍或解释A3C,有些甚至提供示例代码。但是,我想采取另一种方法:将异步演员的名称分解为较小的部分,并以汇总方式解释。
您的经纪人有2个名为Actor and Critic的部分,其目标是通过探索和利用环境,随着时间的流逝,这两个部分都会变得更好。想象一个小小的顽皮的孩子(演员)正在发现他周围的惊人世界,而他的父亲(评论家)则监督他,以确保他没有做任何危险的事情。每当孩子做任何好事时,他的父亲都会赞扬并鼓励他将来重复这一行动。当然,当孩子做任何有害的事情时,他会从父亲那里得到警告。孩子与世界互动越多,采取不同的行动,他从父亲那里得到的反馈就越积极和消极。孩子的目标是,从父亲那里收集尽可能多的积极反馈,而父亲的目标是更好地评估儿子的行动。换句话说,我们在孩子和他的父亲之间或演员和评论家之间有双赢的关系。
为了使孩子的学习速度更快,更稳定,父亲没有告诉儿子的行为有多好,而是要告诉他与其他行动相比(或“虚拟”平均动作)的行为更好或更糟。一个例子是一千个字。让我们比较2对爸爸和儿子。第一位爸爸给儿子10年级的10糖和1年级的糖果送给了1年级的一年级。另一方面,第二个父亲给了他的儿子5次10年级的糖果,并通过不允许他观看他最喜欢的电视连续剧的一天来“惩罚”他的儿子。您怎么看?第二个爸爸似乎有点聪明,对吧?确实,如果您仍然以少量奖励“鼓励”他们,则很少会防止不良行动。
如果代理人仅发现环境,学习过程就会很慢。更严重的是,代理可能对特定的次优溶液有偏见,这是不可取的。如果您有一堆代理商同时发现环境的不同部分并定期将其新的知识更新到彼此之间,该怎么办?这正是异步优势参与者评论的想法。现在,孩子和他的伴侣在幼儿园里去了一个美丽的海滩(当然,和他们的老师一起)。他们的任务是建造一座伟大的沙堡。不同的孩子将建造由老师监督的城堡的不同部分。他们每个人都会有不同的任务,最终目标是一个强大而醒目的城堡。当然,在上一个示例中,老师的角色与父亲相同。唯一的区别是前者更忙?
使用我的代码,您可以:
您可以找到我在超级Mario Bros A3C训练的模型中训练的训练有素的型号
一开始,我只能训练我的经纪人完成9个阶段。然后@DavinCibj指出,可以完成19个阶段,并将训练有素的权重寄给我。非常感谢您的发现!


