Super mario bros A3C pytorch
1.0.0
다음은 Super Mario Bros를 연주하는 에이전트를 훈련하기위한 내 파이썬 소스 코드입니다. 심층 강화 학습 용지를위한 논문 비동기 방법 에 도입 된 비동기 우위 ACTOR-CRITIC (A3C) 알고리즘을 사용함으로써.
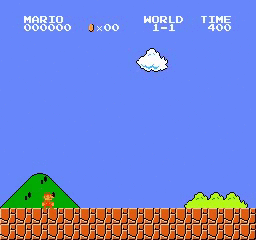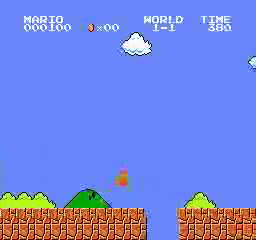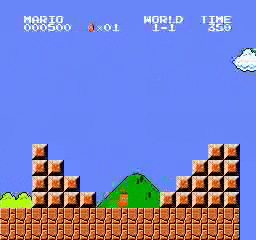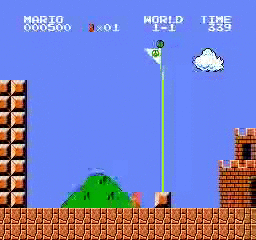
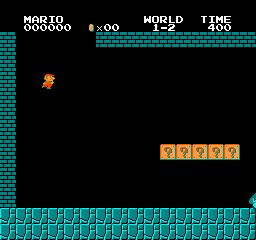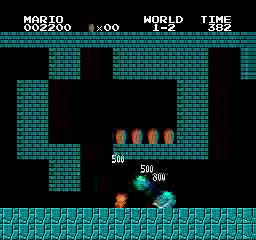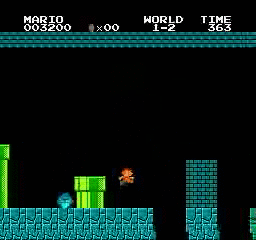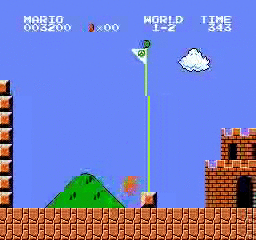

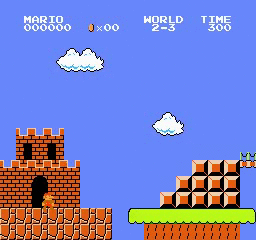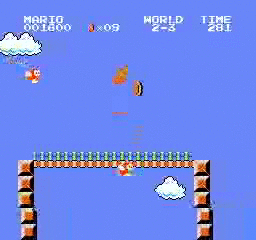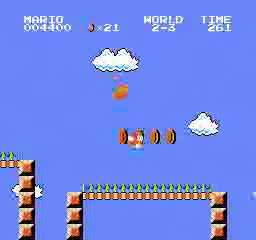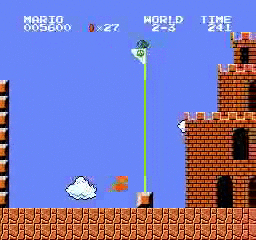
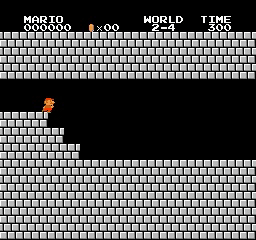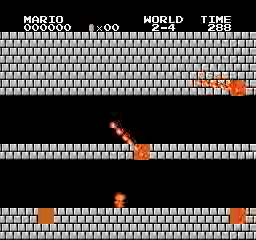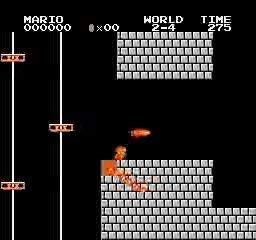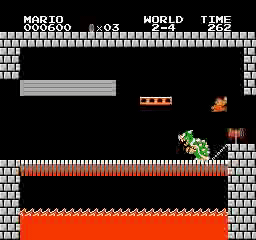
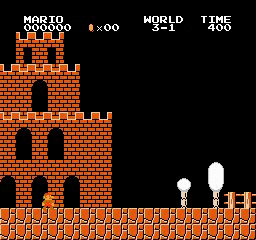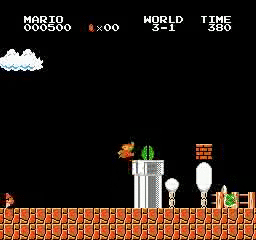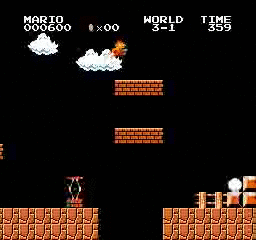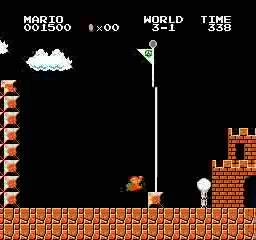
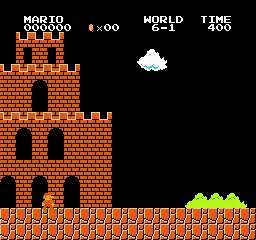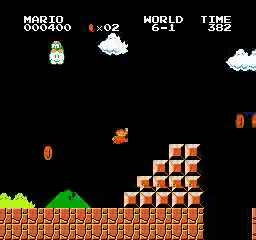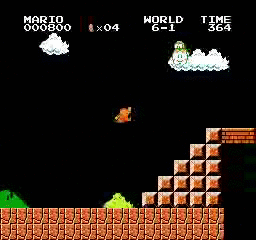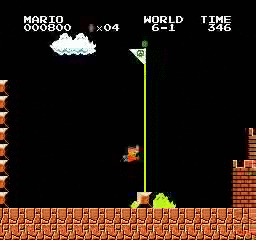
샘플 결과
이 프로젝트를 구현하기 전에 Tensorflow, Keras 및 Pytorch와 같은 다른 일반적인 딥 러닝 프레임 워크에서 논문의 결과를 잘 재현하는 몇 가지 저장소가 있습니다. 제 생각에는 대부분은 훌륭합니다. 그러나 이미지의 사전 프로세싱, 환경 설정 및 무게 초기화를 포함하여 많은 부분에서는 사용자의 관심을 더 중요한 문제로부터 산만하게합니다. 따라서 클리너 코드를 작성하기로 결정했습니다. 보시다시피, 최소한의 설정과 간단한 네트워크의 초기화로 알고리즘을 올바르게 구현하는 한 에이전트는 환경과 상호 작용하는 방법을 가르치고 최종 목표에 도달하는 방법을 점차적으로 찾을 수 있습니다.
이미 일반적으로 학습을 강화하는 데 익숙하고 특히 A3C 가이 부분을 건너 뛸 수 있습니다. A3C 알고리즘이 무엇인지, 어떻게 그리고 왜 작동하는지, A3C 또는 내 구현에 관심이 있거나 궁금한 사람들에게이 부분을 작성하기 위해이 부분을 씁니다. 따라서이 부분을 읽을 수있는 전제 조건 지식이 필요하지 않습니다.
인터넷에서 검색하는 경우 A3C를 소개하거나 설명하는 수많은 기사가 있으며 일부는 샘플 코드도 제공합니다. 그러나 나는 또 다른 접근 방식을 취하고 싶습니다. 비동기 액터-비법 제 를 작은 부분으로 나누고 집계 된 방식으로 설명하십시오.
에이전트에는 배우 와 비평가 라는 두 부분이 있으며, 목표는 환경을 탐구하고 악용하여 시간이 지남에 따라 두 부분을 더 잘 만들어내는 것입니다. 작은 장난 꾸러기 아이 ( 배우 )가 그 주변의 놀라운 세상을 발견하고있는 반면, 그의 아빠 ( 비평가 )는 그를 감독하여 위험한 일을하지 않도록합니다. 아이가 좋은 일을 할 때마다 아빠는 미래에 그 행동을 반복하도록 칭찬하고 격려 할 것입니다. 물론, 아이가 해로운 일을하면 아빠로부터 경고를받을 것입니다. 아이가 세상과 상호 작용하고 다른 행동을 취하고 긍정적이고 부정적인 피드백이 더 많을수록 아빠에게서 얻습니다. 아이의 목표는 아빠로부터 가능한 한 많은 긍정적 인 피드백을 모으는 반면, 아빠의 목표는 아들의 행동을 더 잘 평가하는 것입니다. 다시 말해, 우리는 아이와 그의 아빠 사이에 상생 관계가 있거나 배우 와 비평가 사이에 동등하게 관계가 있습니다.
아이가 더 빨리 배우고 안정적으로 배우게하기 위해 아빠는 아들에게 자신의 행동이 얼마나 좋은지 알려주는 대신 다른 행동 (또는 "가상"평균 행동 )에 비해 자신의 행동이 얼마나 더 좋거나 악화되는지 알려줄 것입니다. 예는 천 단어의 가치가 있습니다. 아빠와 아들 2 쌍을 비교해 봅시다. 첫 번째 아빠는 그의 아들에게 10 학년에 10 개의 사탕을, 학교에서 1 학년 1 개를 제공합니다. 반면에 두 번째 아빠는 아들 10 학년을 위해 아들 5 개의 사탕을 주었고, 1 학년이 될 때 가장 좋아하는 TV 시리즈를 보지 못하게함으로써 아들을 "처벌"합니다. 어떻게 생각하십니까? 두 번째 아빠는 조금 더 똑똑한 것 같습니다. 실제로, 당신은 여전히 작은 보상으로 그들을 "격려"한다면 나쁜 행동을 거의 막을 수 없습니다.
에이전트가 환경 만 발견하면 학습 과정이 느려집니다. 더 진지하게, 에이전트는 아마도 특정 차선책에 편향 될 수 있으며, 이는 바람직하지 않다. 환경의 다른 부분을 동시에 발견하고 새로운 지식을 정기적으로 업데이트하는 많은 에이전트가 있다면 어떻게됩니까? 그것은 비동기 우위 액터 크리티어 의 아이디어입니다. 이제 유치원의 아이와 그의 동료들은 아름다운 해변으로 여행합니다 (물론 선생님과 함께). 그들의 임무는 훌륭한 모래 성을 짓는 것입니다. 다른 어린이는 교사가 감독하는 성의 다른 부분을 건설 할 것입니다. 그들 각각은 다른 작업을 가질 것이며, 같은 최종 목표는 강력하고 시선을 사로 잡는 성입니다. 확실히, 이제 교사의 역할은 이전 예에서 아빠와 동일합니다. 유일한 차이점은 전자가 더 바쁘다는 것입니다.
내 코드를 사용하면 다음을 수행 할 수 있습니다.
Super Mario Bros A3C 훈련 된 모델에서 훈련 한 훈련 된 모델을 찾을 수 있습니다.
처음에는 에이전트 만 훈련하여 9 단계를 완료 할 수있었습니다. 그런 다음 @davincibj는 19 단계가 완성 될 수 있고 훈련 된 무게를 보냈다고 지적했습니다. 발견 해주셔서 감사합니다!


