Super mario bros A3C pytorch
1.0.0
Вот мой исходный код Python для обучения агента для игры Super Mario Bros. Используя алгоритм Asynchronous Advantage Actor-Critic (A3C), введенный в статье асинхронные методы для глубокого подкрепления .
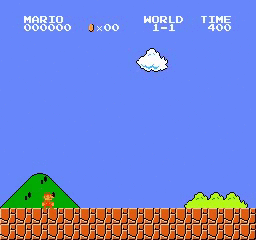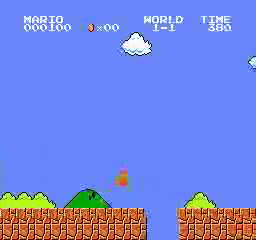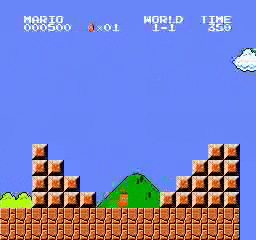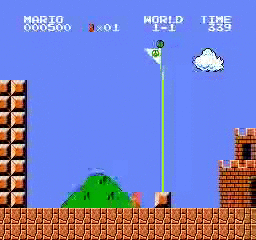
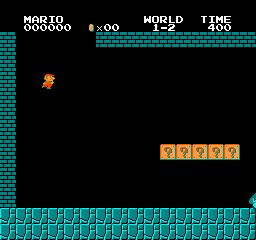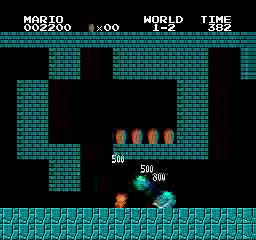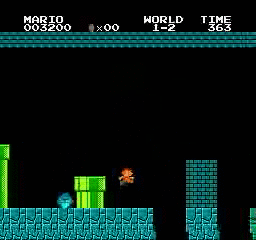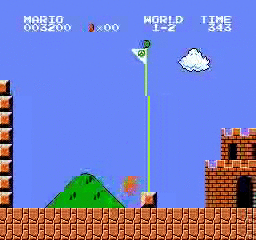
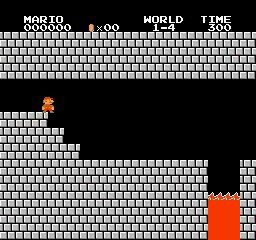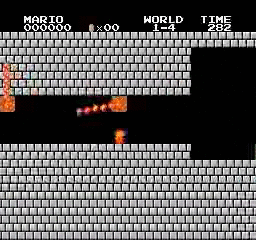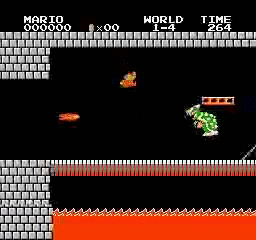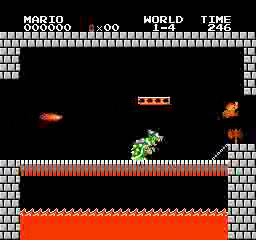

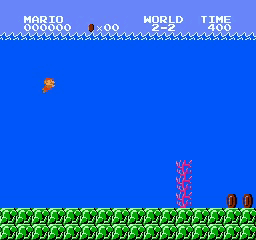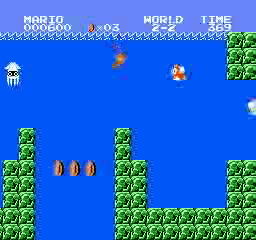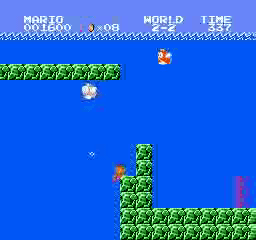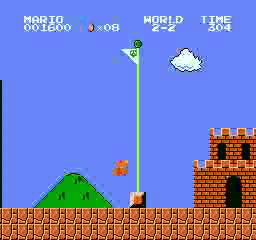
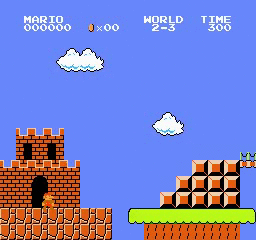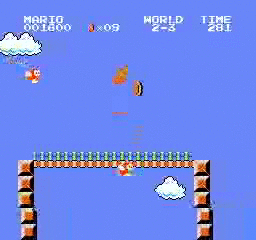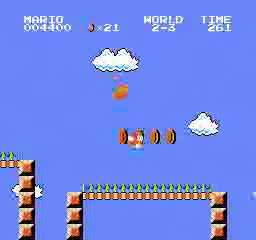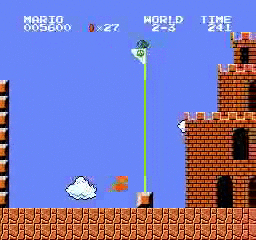
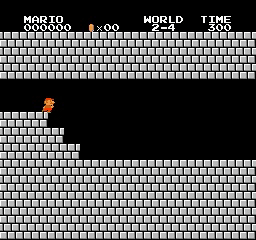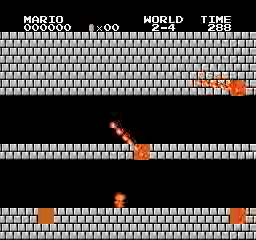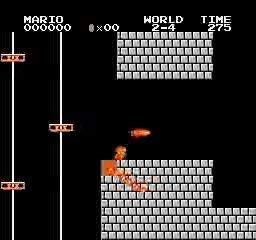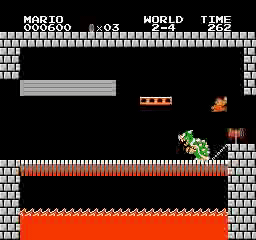
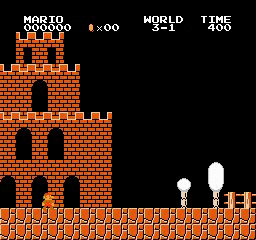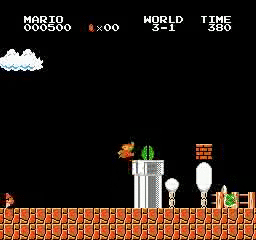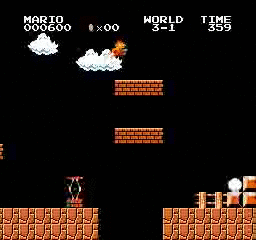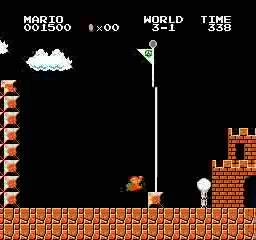
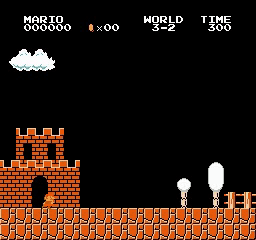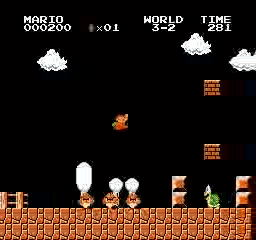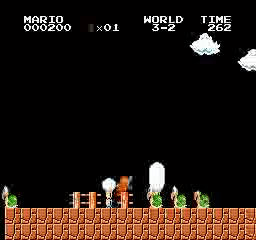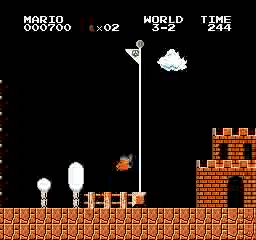
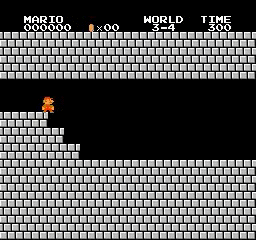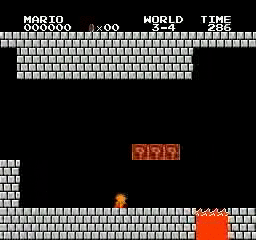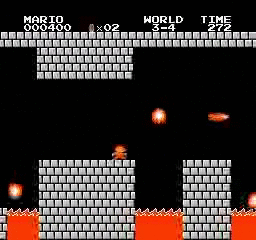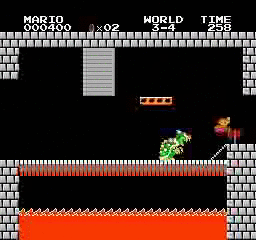
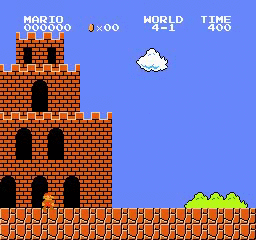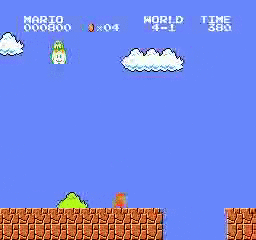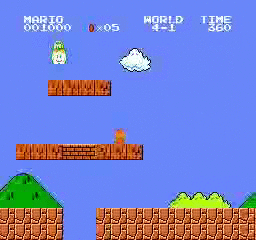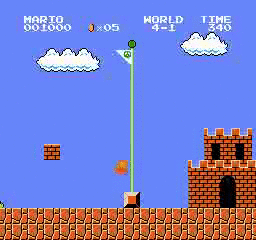
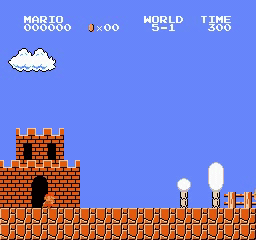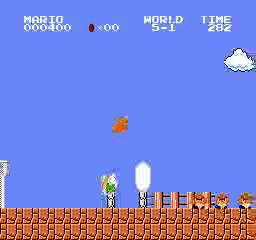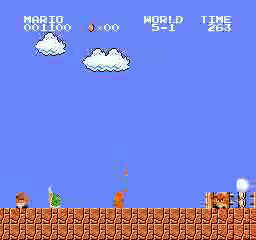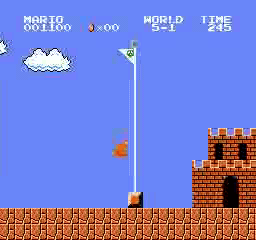
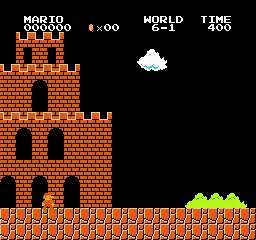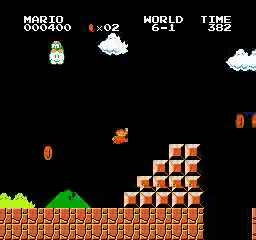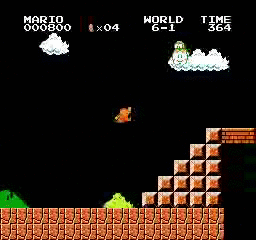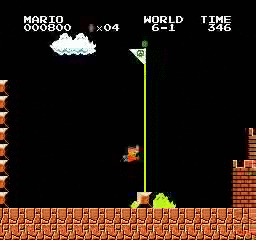
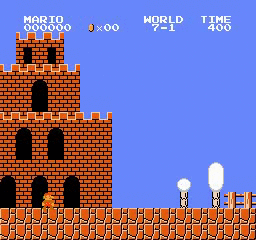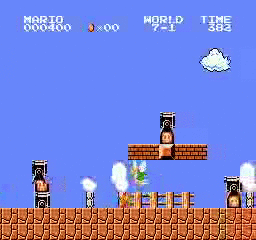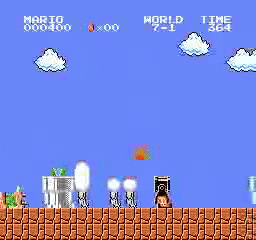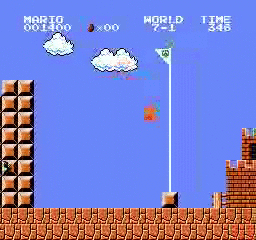
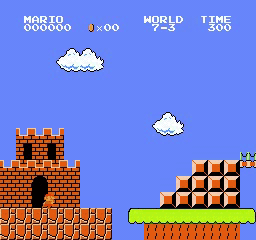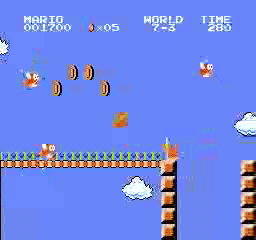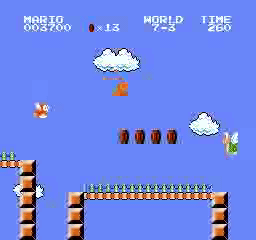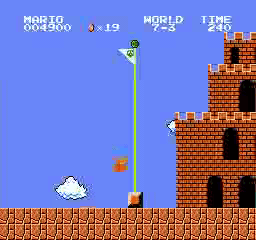
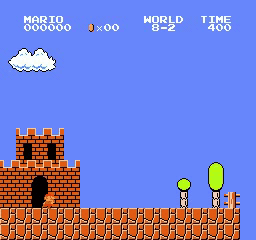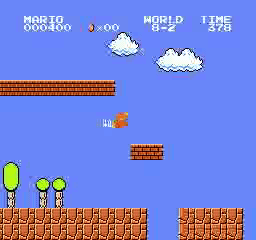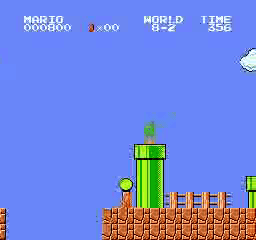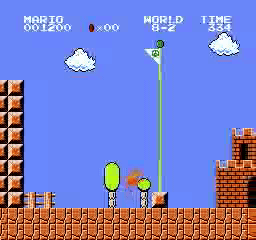
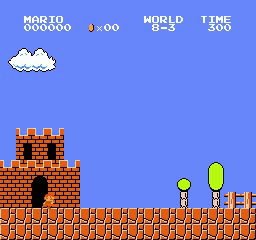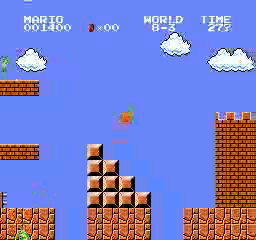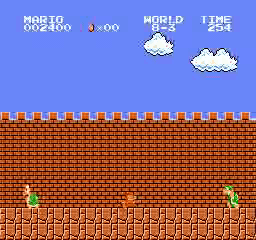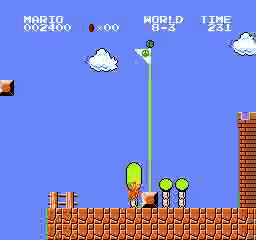
Образец результатов
Прежде чем я внедрил этот проект, существует несколько репозиториев, воспроизводящих результат статьи, в различных общих структурах глубокого обучения, таких как Tensorflow, Keras и Pytorch. На мой взгляд, большинство из них великолепны. Тем не менее, они, по-видимому, чрезмерно сложны во многих частях, включая предварительную обработку Image, настройку окружающей среды и инициализацию веса, которые отвлекают внимание пользователя от более важных вопросов. Поэтому я решаю написать более чистый код, который упрощает неважные детали, в то время как все еще строго следует за бумагой. Как вы могли видеть, с минимальной настройкой и инициализацией Simple Network, если вы правильно реализуете алгоритм, агент научит себя взаимодействовать с окружающей средой и постепенно выяснить, как достичь конечной цели.
Если вы уже знакомы с подкреплением обучения в целом и A3C в частности, вы можете пропустить эту часть. Я пишу эту часть для объяснения того, что такое алгоритм A3C, как и почему она работает, для людей, которые заинтересованы или любопытны в отношении A3C или моей реализации, но не понимаю механизм. Поэтому вам не нужны какие -либо предварительные знания для чтения этой части
Если вы ищете в Интернете, есть многочисленные статьи, вводя или объясняющие A3C, некоторые даже предоставляют пример кода. Тем не менее, я хотел бы использовать другой подход: разбить имя асинхронных актерских агентов на более мелкие части и объяснить агрегированным образом.
У вашего агента есть две части, называемые актером и критиком , и его цель - сделать обе части лучше со временем, исследуя и эксплуатируя окружающую среду. Дайте представить, что маленький озорной ребенок ( актер ) обнаруживает удивительный мир вокруг него, в то время как его отец ( критик ) наблюдает за ним, чтобы убедиться, что он не делает ничего опасного. Всякий раз, когда ребенок делает что -то хорошее, его отец будет хвалит и побуждает его повторить это действие в будущем. И, конечно, когда ребенок делает что -то вредное, он получит предупреждение от своего отца. Чем больше ребенок взаимодействует с миром и предпринимает разные действия, тем больше отзывов, как положительных, так и отрицательных, он получает от своего отца. Цель ребенка состоит в том, чтобы собрать как можно больше положительных отзывов от своего отца, в то время как цель отца - лучше оценить действия его сына. Другими словами, у нас есть беспроигрышные отношения между ребенком и его отцом, или эквивалентно между актером и критиком .
Чтобы ребенок учился быстрее и более стабильным, папа, вместо того, чтобы рассказать своему сыну, насколько хороши его действия, скажет ему, как лучше или хуже его действия по сравнению с другими действиями (или «виртуальным» средним действием ). Пример стоит тысячи слов. Давайте сравним 2 пары папы и сына. Первый папа дает своему сыну 10 конфет для 10 и 1 конфет для 1 класса в школе. Второй папа, с другой стороны, дает своему сыну 5 конфет на 10 класс и «наказывает» своего сына, не позволяя ему смотреть свой любимый сериал в течение дня, когда он получает 1 класс. Как вы думаете? Второй папа кажется немного умнее, верно? Действительно, вы можете редко предотвратить плохие действия, если вы все еще «поощряете» их с небольшой наградой.
Если агент обнаружит только окружающую среду, процесс обучения будет медленным. Более серьезно, агент может быть, возможно, предвзятость к конкретному субоптимальному решению, которое нежелательно. Что произойдет, если у вас есть куча агентов, которые одновременно обнаруживают другую часть окружающей среды и периодически обновляют их новые знания друг другу? Это именно идея асинхронного преимущества актер-критического . Теперь ребенок и его товарищи в детском саду совершают поездку на прекрасный пляж (конечно, со своим учителем). Их задача - построить отличный песчаный замок. Различный ребенок будет строить разные части замка, под контролем учителя. Каждый из них будет иметь разные задачи, с одной и той же конечной целью является сильный и привлекательный замок. Конечно, роль учителя сейчас такая же, как у папы в предыдущем примере. Единственная разница в том, что первое более оживленное?
С помощью моего кода вы можете:
Вы могли бы найти несколько обученных моделей, которые я обучил в обученных моделях Super Mario Bros A3C
Вначале я мог только обучить своего агента, чтобы завершить 9 этапов. Затем @davincibj отметил, что 19 этапов могут быть завершены и прислали мне обученные веса. Большое спасибо за поиск!


