Super mario bros A3C pytorch
1.0.0
Aqui está o meu código -fonte do Python para treinar um agente para jogar Super Mario Bros. Usando o algoritmo de ator-crítico (A3C) assíncrono, introduzido nos métodos assíncronos de papel para o papel de aprendizado de reforço profundo .
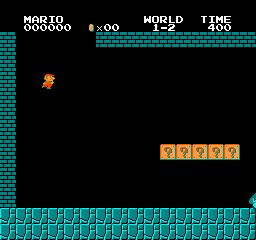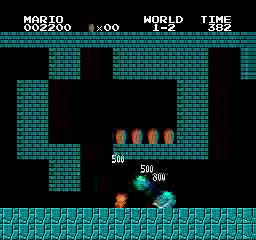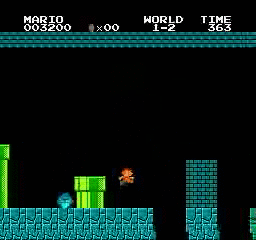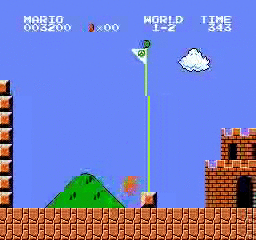
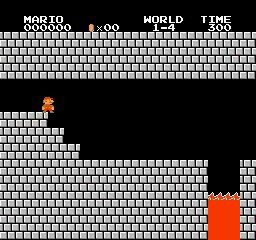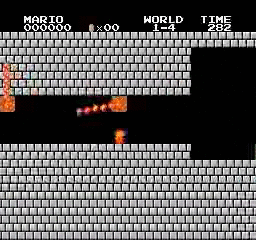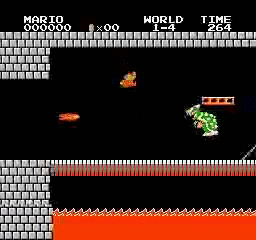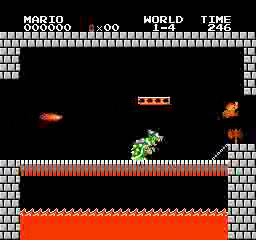

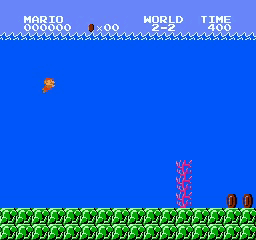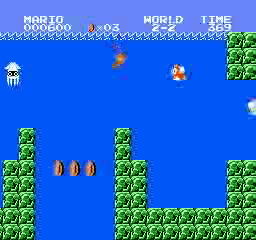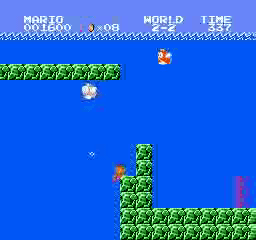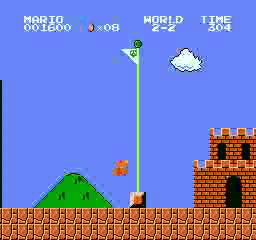
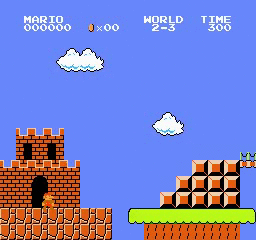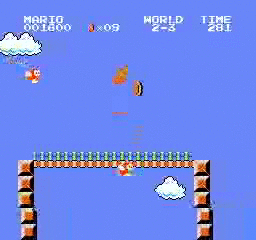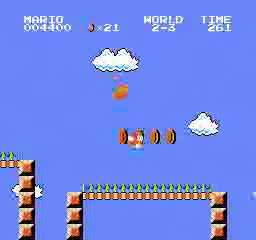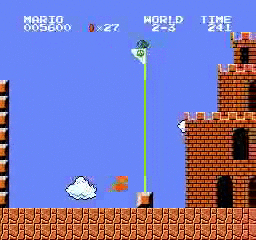
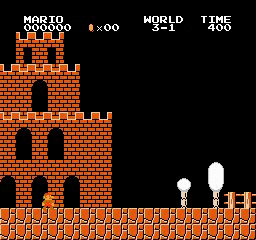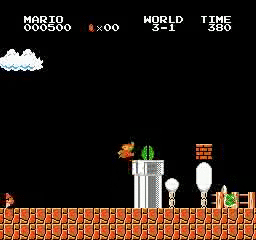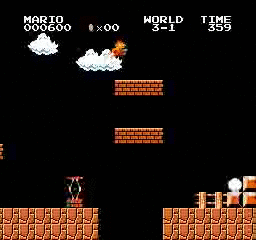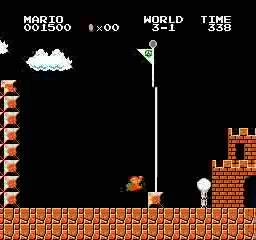
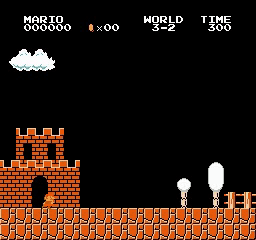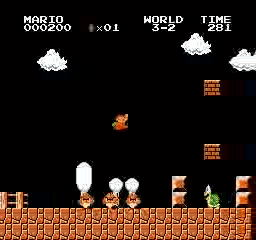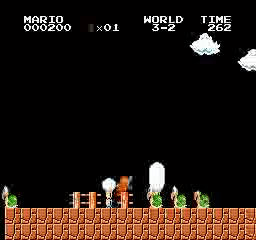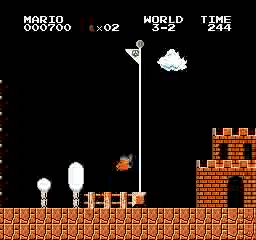
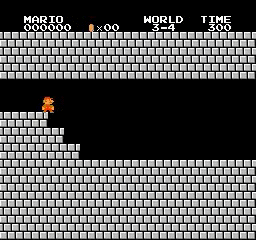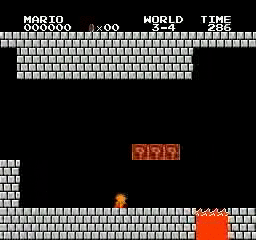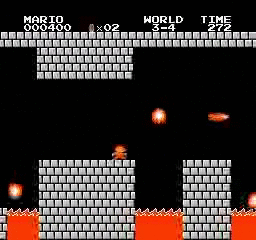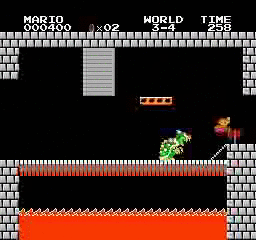
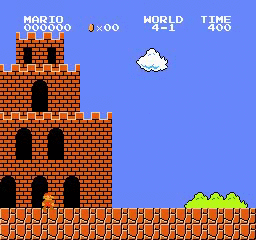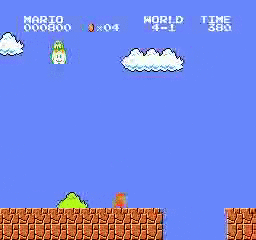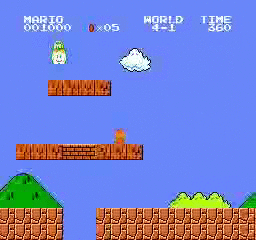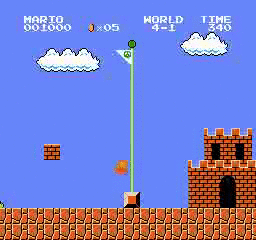
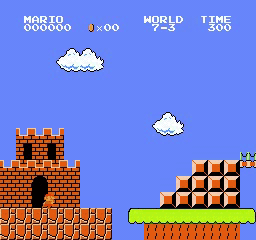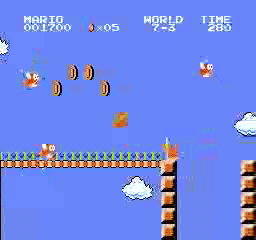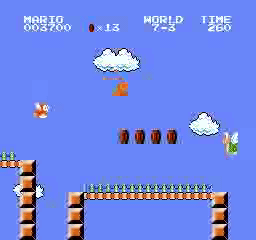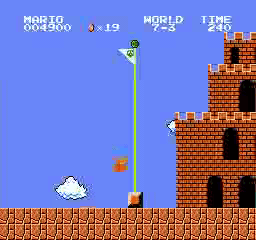
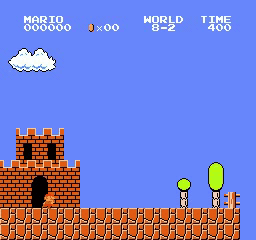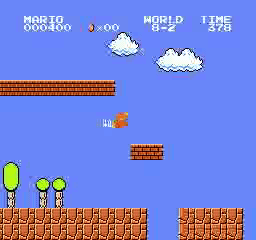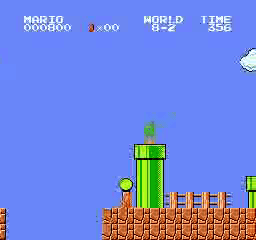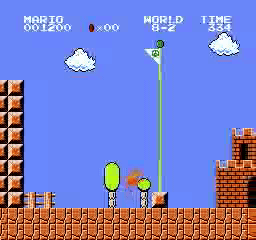
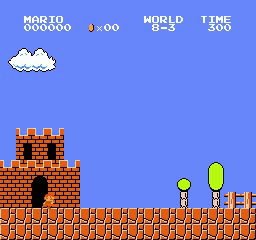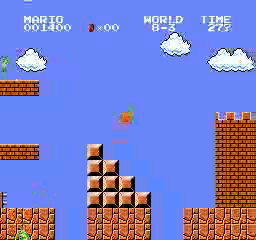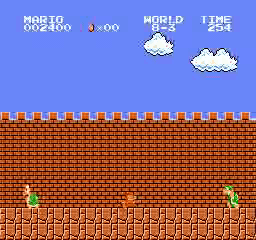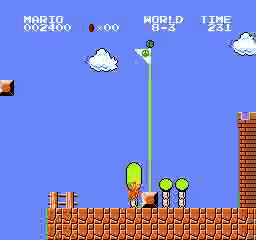
Resultados da amostra
Antes de implementar este projeto, existem vários repositórios reproduzindo muito bem o resultado do artigo, em diferentes estruturas de aprendizado profundo comuns, como Tensorflow, Keras e Pytorch. Na minha opinião, a maioria deles é ótima. No entanto, eles parecem ser excessivamente complicados em muitas partes, incluindo a configuração de pré-processamento da Image, a configuração do ambiente e a inicialização do peso, o que distrai a atenção do usuário de assuntos mais importantes. Portanto, eu decido escrever um código mais limpo, que simplifica peças sem importância, enquanto ainda segue o artigo estritamente. Como você pode ver, com configuração mínima e inicialização simples da rede, desde que você implemente o algoritmo corretamente, um agente ensinará a interagir com o ambiente e descobrir gradualmente o caminho para atingir a meta final.
Se você já conhece o aprendizado de reforço em geral e o A3C em particular, pode pular esta parte. Escrevo esta parte para explicar o que é o algoritmo A3C, como e por que funciona, para pessoas que estão interessadas ou curiosas sobre o A3C ou minha implementação, mas não entendem o mecanismo por trás. Portanto, você não precisa de nenhum conhecimento pré -requisito para ler esta parte
Se você pesquisar na Internet, existem inúmeros artigo introduzindo ou explicando o A3C, alguns até fornecem código de amostra. No entanto, gostaria de adotar outra abordagem: quebrar o nome de agentes atores críticos de ator em partes menores e explicar de maneira agregada.
Seu agente tem duas partes chamadas ator e crítico , e seu objetivo é melhorar as duas partes ao longo do tempo, explorando e explorando o meio ambiente. Que imagine uma pequena criança travessa ( ator ) está descobrindo o mundo incrível ao seu redor, enquanto seu pai ( crítico ) o supervisiona, para garantir que ele não faça nada perigoso. Sempre que o garoto faz algo de bom, seu pai elogia e o encoraja a repetir essa ação no futuro. E, claro, quando o garoto faz qualquer coisa prejudicial, ele receberá um aviso de seu pai. Quanto mais o garoto interage para o mundo e toma ações diferentes, mais feedback, positivo e negativo, ele recebe de seu pai. O objetivo do garoto é coletar o maior número possível de feedback positivo de seu pai, enquanto o objetivo do pai é avaliar melhor a ação de seu filho. Em outra palavra, temos um relacionamento em que todos saem ganhando entre o garoto e seu pai, ou equivalentemente entre ator e crítico .
Para que o garoto aprenda mais rápido e mais estável, o pai, em vez de dizer ao filho como sua ação é boa, dirá a ele o quão melhor ou pior sua ação em comparação com outras ações (ou uma ação média "virtual" ). Um exemplo vale mais que mil palavras. Vamos comparar 2 pares de pai e filho. O primeiro pai dá a seu filho 10 doces para o 10º e 1 Candy para a 1ª série na escola. O segundo pai, por outro lado, dá ao filho 5 doces para a 10ª série, e "pune" seu filho por não permitir que ele assista sua série de TV favorita por um dia em que ele recebe o primeiro grau. Como você acha? O segundo pai parece ser um pouco mais inteligente, certo? De fato, você raramente poderia impedir ações ruins, se ainda "incentivá -las" com pequena recompensa.
Se um agente descobrir o ambiente sozinho, o processo de aprendizado seria lento. Mais seriamente, o agente pode ser influenciado a uma solução subótima específica, o que é indesejável. O que acontece se você tem um monte de agentes que descobrem simultaneamente diferentes parte do ambiente e atualizam seu novo conhecimento obtido um para o outro periodicamente? É exatamente a idéia de ator de vantagem assíncrona . Agora, o garoto e seus companheiros no jardim de infância fazem uma viagem a uma bela praia (com o professor, é claro). A tarefa deles é construir um ótimo castelo de areia. Criança diferente construirá diferentes partes do castelo, supervisionadas pelo professor. Cada um deles terá uma tarefa diferente, com o mesmo objetivo final é um castelo forte e atraente. Certamente, o papel do professor agora é o mesmo que o pai no exemplo anterior. A única diferença é que o primeiro é mais ocupado?
Com meu código, você pode:
Você pode encontrar alguns modelos treinados que treinei em modelos treinados Super Mario Bros A3C
No começo, eu só podia treinar meu agente para completar 9 etapas. Então @davincibj apontou que 19 etapas poderiam ser concluídas e me enviaram os pesos treinados. Muito obrigado pela descoberta!


