AIlice
1.0.0

快速啟動•演示•開發•Twitter•reddit
2024年6月22日:我們進入了當地運行的類似Jarvis的AI助手的時代!最新的開源LLMS使我們能夠在本地執行複雜的任務!單擊此處以了解更多信息。
AILICE是一種完全自主的通用AI代理。該項目旨在根據開源LLM創建與Jarvis類似的獨立人工智能助理。 Ailice通過構建使用大型語言模型(LLM)作為其核心處理器的“文本計算機”來實現這一目標。目前,AILICE展示了一系列任務的熟練程度,包括主題研究,編碼,系統管理,文獻評論以及超出這些基本功能的複雜混合任務。
AILICE在日常任務中使用GPT-4達到了幾乎完美的表現,並正在通過最新的開源型號進行實用。
我們最終將實現AI代理的自我發展。也就是說,AI代理人將自主建立自己的功能擴展和新型代理,將LLM的知識和推理能力釋放到現實世界中。
要了解Ailice的當前能力,請觀看以下視頻:
AILICE的關鍵技術特徵包括:
使用以下命令安裝並運行AILICE。啟動AILICE後,請使用瀏覽器打開其提供的網頁,將出現對話接口。通過對話向AILICE發出命令,以完成各種任務。對於您的首次使用,您可以嘗試在我們可以做的酷些命令中提供的命令,以快速熟悉。
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2讓我們列出一些典型的用例。我經常使用這些示例在開發過程中測試AILICE,以確保穩定的性能。但是,即使有這些測試,執行結果也會受到所選模型,代碼版本甚至測試時間的影響。 (GPT-4在高載荷下的性能可能會下降。某些隨機因素也可能導致多次運行模型的結果。有時LLM的性能非常聰明,但其他時間則沒有)。基於多機構合作,作為用戶,您也是“代理人”之一。因此,當Ailice需要其他信息時,它將尋求您的意見,並且您的詳細信息對她的成功至關重要。此外,如果任務執行不足,您可以指導她朝著正確的方向指導,她將糾正她的方法。
要注意的最後一點是,Ailice當前缺乏運行的時間控制機制,因此她可能會陷入循環或跑步延長。使用商業LLM時,您需要密切監視她的操作。
“請列出當前目錄的內容。”
“找到David Tong的QFT講義,然後將其下載到當前目錄中的“物理”文件夾中。您可能需要先創建文件夾。”
“使用燒瓶框架在該計算機上部署一個直接的網站。確保可訪問性在0.0.0.0:59001。該網站應具有一個能夠顯示“圖像”目錄中的所有圖像的單個頁面。這個特別有趣。我們知道繪圖無法在Docker環境中完成,並且需要使用“ Docker CP”命令複製我們生成的所有文件輸出才能看到它。但是您可以讓AILICE本身解決此問題:根據上述提示在容器中部署網站(建議使用端口映射的59001和59200之間的端口),目錄中的圖像將自動顯示網頁。這樣,您可以動態地查看主機上生成的圖像內容。您也可以嘗試讓她迭代以產生更複雜的功能。如果您在頁面上沒有看到任何圖像,請檢查網站的“圖像”文件夾是否與此處的“圖像”文件夾不同(例如,它可能在“ static/aimages”下)。
“請使用Python編程來解決以下任務:獲取BTC-USDT的價格數據六個月並將其繪製到圖表中,並將其保存在'Images'目錄中。”如果您成功部署了上述網站,則可以直接在頁面上查看BTC價格曲線。
“在端口59001上找到該過程並終止它。”這將終止剛剛建立的網站服務計劃。
“請使用Cadquery實施杯子。”這也是一個非常有趣的嘗試。 Cadquery是一個Python軟件包,使用Python編程進行CAD建模。我們嘗試使用Ailice自動構建3D型號!這可以讓我們了解LLM的世界觀中如何成熟的幾何直覺。當然,在實施多模式支持之後,我們可以使Ailice能夠看到她創建的模型,從而進一步調整併建立高效的反饋循環。這樣,可以實現真正可用的語言控制的3D建模。
“請在Internet上搜索各種物理分支中的100個教程,並下載您發現的PDF文件,您發現的PDF文件''''''''''''''''''''' '''''無需驗證PDF的內容,我們現在只需要一個粗略的收集。”利用AILICE實現自動數據集收集和構建是我們正在進行的目標之一。目前,該功能的研究人員仍然有一些缺陷,但是它已經能夠提供一些有趣的結果。
“請對開源PDF OCR工具進行調查,重點關注能夠識別數學公式並將其轉換為乳膠代碼的人。將調查結果合併為報告。”
1。在YouTube上找到Feynmann演講的視頻,然後下載到Feynmann/ Subdir。您需要先創建文件夾。 2.從這些視頻中提取音頻,然後將其保存到Feynmann/Audio中。 3。將這些音頻文件轉換為文本並將其合併到文本文檔中。您需要首先轉到擁抱面孔,並找到Whisper-Large-V3的頁面,找到示例代碼,然後參考示例代碼以完成此操作。 4。從您剛提取的文本文件中找到此問題的答案:為什麼我們需要反粒子?這是一個基於多步驟的任務,您需要逐步與AILICE進行交互以完成任務。自然,沿途可能會有意外的事件,因此您需要與AILICE保持良好的溝通以解決您遇到的任何問題(使用“中斷”按鈕隨時在任何時候中斷ailice並給出提示是一個不錯的選擇! ) 。最後,根據下載的視頻的內容,您可以向Ailice提出與物理相關的問題。收到答案後,您可以回頭看看自己走了多遠。
1。使用SDXL生成“胖橙貓”的圖像。您需要在其擁抱面頁面上找到示例代碼,作為完成編程和圖像生成工作的參考。將圖像保存到當前目錄並顯示。 2。現在,讓我們實現一個單頁網站。網頁的功能是將用戶輸入的文本描述轉換為圖像並顯示。從之前請參閱文本到圖像代碼。該網站在127.0.0.1:59102上運行。運行之前,將代碼保存到./image_gen;您可能需要先創建文件夾。
“請編寫一個Ext-Module。模塊的功能是通過關鍵字在Wiki上獲得相關頁面的內容。” AILICE可以自己構建外部交互模塊(我們稱其為Ext-Modules),從而賦予她無限的擴展性。它只需要您的一些提示。構造模塊後,您可以說:“請加載新實施的Wiki模塊,並利用其在相對論上查詢條目。”
代理需要與周圍環境的各個方面進行互動,其操作環境通常比典型軟件更複雜。我們可能需要很長時間安裝依賴項,但是幸運的是,這基本上是自動完成的。
要運行AILICE,您需要確保正確安裝Chrome 。如果您需要在安全的虛擬環境中執行代碼,則還需要安裝Docker 。
如果要在虛擬機中運行AILICE,請確保關閉Hyper-V (否則無法安裝Llama.cpp)。在虛擬盒環境中,您可以按照以下步驟禁用它:在VM的VirtualBox設置上禁用PAE/NX和VT-X/AMD-V(HYPER-V)。將paravirtualization接口設置為默認,禁用嵌套分頁。
您可以使用以下命令安裝AILICE(強烈建議使用Conda等工具來創建新的虛擬環境來安裝AILICE,以避免依賴關係衝突):
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .默認安裝的AILICE將緩慢運行,因為它使用CPU作為長期內存模塊的推理硬件。因此,強烈建議安裝GPU加速支持:
ailice_turbo對於需要使用HuggingFace模型/語音對話/模型微調/PDF閱讀功能的用戶,您可以使用以下命令之一(安裝太多功能會增加依賴關係衝突的可能性,因此建議僅安裝該命令必要的零件):
pip install -e .[huggingface]
pip install -e .[speech]
pip install -e .[finetuning]
pip install -e .[pdf-reading]您現在可以運行Ailice!在使用中使用命令。
默認情況下,AILICE中的Google模塊受到限制,重複使用可能會導致錯誤需要一些時間來解決。這是AI時代的尷尬現實。傳統搜索引擎僅允許訪問真正的用戶,而AI代理當前不屬於“真正用戶”的類別。儘管我們有其他解決方案,但它們都需要配置API鍵,這為普通用戶設定了高障礙。但是,對於需要頻繁訪問Google的用戶,我認為您願意忍受申請Google官方API密鑰的麻煩(我們是指自定義搜索JSON API創建時間)用於搜索任務。對於這些用戶,請打開config.json並使用以下配置:
{
...
"services": {
...
"google": {
"cmd": "python3 -m ailice.modules.AGoogleAPI --addr=ipc:///tmp/AGoogle.ipc --api_key=YOUR_API_KEY --cse_id=YOUR_CSE_ID",
"addr": "ipc:///tmp/AGoogle.ipc"
},
...
}
}
並安裝Google-Api-Python-Client:
pip install google-api-python-client然後只是重新啟動ailice。
默認情況下,代碼執行使用本地環境。為了防止潛在的AI錯誤導致不可逆轉的損失,建議安裝Docker,構建容器並修改Ailice的配置文件(AILICE將在啟動時提供配置文件位置)。配置其代碼執行模塊(ascripter)以在虛擬環境中運行。
docker build -t env4scripter .
docker run -d -p 127.0.0.1:59000-59200:59000-59200 --name scripter env4scripter就我而言,當ailice啟動時,它告訴我配置文件位於〜/.config/ailice/config.json,所以我以以下方式對其進行修改
nano ~ /.config/ailice/config.json修改“服務”下的“腳本”:
{
...
"services": {
...
"scripter": {"cmd": "docker start scripter",
"addr": "tcp://127.0.0.1:59000"},
}
}
現在已經完成了環境配置。
由於AILICE的持續開發狀態,更新代碼可能會導致現有配置文件與Docker容器與新代碼之間的不兼容問題。對於這種情況,最徹底的解決方案是刪除配置文件(確保事先保存任何API鍵)和容器,然後執行完整的重新安裝。但是,對於大多數情況,您可以通過簡單地刪除配置文件並更新容器中的AILICE模塊來解決問題。
rm ~ /.config/ailice/config.json
cd Ailice
docker cp ailice/__init__.py scripter:scripter/ailice/__init__.py
docker cp ailice/common/__init__.py scripter:scripter/ailice/common/__init__.py
docker cp ailice/common/ADataType.py scripter:scripter/ailice/common/ADataType.py
docker cp ailice/common/lightRPC.py scripter:scripter/ailice/common/lightRPC.py
docker cp ailice/modules/__init__.py scripter:scripter/ailice/modules/__init__.py
docker cp ailice/modules/AScripter.py scripter:scripter/ailice/modules/AScripter.py
docker cp ailice/modules/AScrollablePage.py scripter:scripter/ailice/modules/AScrollablePage.py
docker restart scripter您可以直接從下面的典型用例中復制命令以運行AILICE。
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2
ailice_web --modelID=anthropic:claude-3-5-sonnet-20240620 --contextWindowRatio=0.1
ailice_web --modelID=oai:gpt-4-1106-preview --chatHistoryPath=./chat_history
ailice_web --modelID=anthropic:claude-3-opus-20240229 --prompt= " researcher "
ailice_web --modelID=mistral:mistral-large-latest
ailice_web --modelID=deepseek:deepseek-chat
ailice_web --modelID=hf:Open-Orca/Mistral-7B-OpenOrca --quantization=8bit --contextWindowRatio=0.6
ailice_web --modelID=hf:NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO --quantization=4bit --contextWindowRatio=0.3
ailice_web --modelID=hf:Phind/Phind-CodeLlama-34B-v2 --prompt= " coder-proxy " --quantization=4bit --contextWindowRatio=0.6
ailice_web --modelID=groq:llama3-70b-8192
ailice_web # Use models configured individually for different agents under the agentModelConfig field in config.json.
ailice_web --modelID=openrouter:openrouter/auto
ailice_web --modelID=openrouter:mistralai/mixtral-8x22b-instruct
ailice_web --modelID=openrouter:qwen/qwen-2-72b-instruct
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5應該注意的是,最後一個用例要求您首先配置LLM推理服務,請參閱如何添加LLM支持。使用推理框架(例如LM Studio)可以使用有限的硬件資源來支持較大的模型,提供更快的推理速度和更快的AILICE啟動速度,從而使其更適合普通用戶。
首次運行它時,將要求您進入OpenAI的API-KEY。如果您只想使用開源LLM,則無需輸入它。您也可以通過編輯config.json文件來修改API-KEY。請注意,首次使用開源LLM時,下載型號的權重需要很長時間,請確保您有足夠的時間和磁盤空間。
當您第一次打開Secemon Switch時,您可能需要在啟動時等待很長時間。這是因為語音識別和TTS模型的權重正在後台下載。
如示例所示,您可以通過AILICE_WEB使用代理,它提供了Web對話接口。您可以使用
ailice_web --help可以通過修改config.json中的相應參數來自定義所有命令行參數的默認值。
AILICE的配置文件命名為Config.json,其位置將在啟動AILICE時輸出到命令行。在本節中,我們將介紹如何通過配置文件配置外部交互模塊。
在AILICE中,我們使用“模塊”一詞來專門指的是提供與外部世界互動功能的組件。每個模塊作為一個獨立的過程運行;它們可以從核心過程中的不同軟件或硬件環境中運行,從而使AILICE能夠分發。我們在AILICE操作所需的配置文件中提供了一系列基本模塊配置(例如向量數據庫,搜索,瀏覽器,代碼執行等)。您還可以為任何第三方模塊添加配置,並在AILICE啟動並運行以啟用自動加載後提供其模塊運行時地址和端口。模塊配置非常簡單,僅由兩個項目組成:
"services" : {
...
"scripter" : { "cmd" : " python3 -m ailice.modules.AScripter --addr=tcp://127.0.0.1:59000 " ,
"addr" : " tcp://127.0.0.1:59000 " },
...
}其中, “ CMD”下是用於啟動模塊過程的命令行。當Ailice啟動時,它會自動運行這些命令來啟動模塊。用戶可以指定任何命令,提供明顯的靈活性。您可以在本地啟動模塊的過程,也可以利用Docker在虛擬環境中啟動過程,甚至啟動遠程進程。一些模塊具有多個實現(例如Google/Storage),您可以在此處配置以切換到另一個實現。
“ ADDR”是指模塊進程的地址和端口號。用戶可能會因為默認配置中的許多模塊都具有包含地址和端口號的“ CMD”和“ ADDR”,從而引起冗餘。這是因為“ CMD”原則上可以包含任何命令(可能包括地址和端口號,或根本不包含任何命令)。因此,需要單獨的“ ADDR”項目,以告知AILICE如何訪問模塊流程。
中斷。中斷是AILICE支持的第二個交互模式,它使您可以隨時向Ailice代理提供提示,以糾正錯誤或提供指導。在AILICE_WEB中,在AILICE的任務執行過程中,輸入框的右側出現了一個中斷按鈕。按下它會暫停AILICE的執行,並等待您的提示消息。您可以在輸入框中輸入提示,然後按Enter將消息發送給當前執行子任務的代理。熟練使用此功能需要很好地了解Ailice的工作,尤其是Agent Call Tree Architecture。它還涉及更多地關注命令行窗口,而不是在AILICE的任務執行過程中的對話接口。總體而言,這是一個非常有用的功能,尤其是在功能較低的語言模型設置上。
首先使用GPT-4成功運行一些簡單的用例,然後以功率較小(但更便宜/開源)模型重新啟動Ailice,以繼續根據以前的對話歷史記錄繼續運行新任務。這樣,GPT-4提供的歷史是一個成功的例子,為其他模型提供了寶貴的參考,並顯著增加了成功的機會。
於2024年8月23日更新。
當前,AILICE可以使用本地運行的72B開源型號(QWEN-2-72B-INSTRUCTION在4090x2上運行)處理更複雜的任務,並且性能接近GPT-4級型號。考慮到開源型號的低成本,我們強烈建議用戶開始使用它們。此外,本地化LLM操作可確保絕對的隱私保護,這是當時AI應用中罕見的質量。單擊此處以了解如何在本地運行此模型。對於GPU條件不足以運行大型型號的用戶,這不是問題。您可以使用在線推理服務(例如OpenRouter,下一步將提到)來訪問這些開源模型(儘管這犧牲了隱私)。儘管開源模型尚無法完全與商業GPT-4級別模型完全匹配,但您可以根據其優勢和劣勢來利用不同的模型來使代理商表現出色。有關詳細信息,請參考不同代理中使用不同型號。
Claude-3-5-Sonnet-20240620提供了最佳性能。
GPT-4O和GPT-4-1106-PREVIEW還提供頂級性能。但是由於代理商的運行時間很長,並且代幣的大量消費,請謹慎使用商業模型。 GPT-4O-Mini運行良好,儘管它不是一流的,但其低價使該模型非常吸引人。 GPT-4-Turbo / GPT-3.5-Turbo令人驚訝地懶惰,我們從來沒有找到穩定的及時表達。
在開源型號中,通常表現良好的模型包括:
meta-llama-3.1-405b-教學很好,但是太大了,無法在PC上實用。
對於那些硬件功能不足以在本地運行開源模型並且無法獲得商業模型的API鍵的用戶,他們可以嘗試以下選項:
OpenRouter此服務可以將您的推理請求路由到各種開源或商業模型,而無需在本地部署開源模型或為各種商業模型申請API鍵。這是一個絕佳的選擇。 AILICE自動支持OpenRouter中的所有型號。您可以選擇AutorOuter:OpenRouter/Auto,讓Autorouter自動為您路由,也可以指定在Config.json文件中配置的任何特定模型。感謝@babybirdprd向我推薦OpenRouter。
GROQ:Llama3-70B-8192當然,Ailice還支持Groq下的其他型號。在GROQ下運行的一個問題是,它易於超過速率限制,因此只能用於簡單的實驗。
我們將選擇當前表現最好的開源模型,為開源模型的用戶提供參考。
在所有型號中最好的: QWEN-2-72B-INSTRUCTY 。這是第一個具有實用價值的開源模型。這是一個很大的進步!它具有接近GPT-4的推理功能,儘管還沒有。通過通過中斷功能進行主動的用戶干預,可以成功完成許多更複雜的任務。
第二好的表演模型: Mixtral-8x22b-Instruct和Meta-llama/Meta-llama-3-70b-Instruct 。值得注意的是,Llama3系列模型在量化後似乎表現出顯著的性能下降,從而降低了其實際價值。您可以將它們與groq一起使用。
如果您找到更好的模型,請告訴我。
對於高級玩家來說,嘗試更多模型是不可避免的。幸運的是,這並不難。
對於OpenAI/Mistral/Anthropic/Groq型號,您無需做任何事情。只需使用由“ OAI:”/“ MISTRAL:”/“ ANTHROPIC:”/“ GROQ:”前綴附加到“ OAI:”/“ MISTRAL:”的官方模型名稱組成的模型ID。如果您需要使用AILICE支持的列表中未包含的模型,則可以通過在Config.json文件中添加此模型的條目來解決此問題。添加的方法是直接引用類似模型的輸入,將上下文窗口修改為實際值,使SystemAsuser與類似的模型保持一致,並將args設置為空dict。
您可以使用與OpenAI API兼容的任何第三方推理服務器來替換AILICE中內置的LLM推理功能。只需使用與OpenAI模型相同的配置格式,然後修改baseurl,apikey,ContextWindow和其他參數(實際上,這就是Ailice支持GROQ模型的方式)。
對於不支持OpenAI API的推理服務器,您可以嘗試使用Litellm將其轉換為兼容OpenAI兼容的API(我們有下面的示例)。
重要的是要注意,由於AILICE的對話記錄中存在許多系統消息,這不是LLM的常見用例,因此對此的支持水平取決於這些推理服務器的特定實現。在這種情況下,您可以將SystemAsuser參數設置為真實,以規避問題。儘管這可能會阻止該模型以其最佳性能運行,但它也使我們能夠與各種有效的推理服務器兼容。對於普通用戶,好處大於缺點。
我們以Ollama為例來解釋如何增加對此類服務的支持。首先,我們需要使用Litellm將Ollama的界面轉換為與OpenAI兼容的格式。
pip install litellm
ollama pull mistral-openorca
litellm --model ollama/mistral-openorca --api_base http://localhost:11434 --temperature 0.0 --max_tokens 8192然後,在config.json文件中添加對此服務的支持(啟動AILICE時將提示此文件的位置)。
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"ollama" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fake-key " ,
"baseURL" : " http://localhost:8000 " ,
"modelList" : {
"mistral-openorca" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 8192 ,
"systemAsUser" : false ,
"args" : {}
}
}
},
...
},
...
}現在我們可以運行Ailice:
ailice_web --modelID=ollama:mistral-openorca在此示例中,我們將使用LM Studio運行我見過的最開源的模型: QWEN2-72B-INSTRUCT-Q3_K_S.S.GGUF ,為AILICE提供動力在本地計算機上運行。
使用LM Studio下載Qwen2-72b-instruct-q3_k_s.gguf的型號權重。
在LM Studio的“ Localserver”窗口中,如果僅使用GPU,將N_GPU_LAYERS設置為-1。將左側的“上下文長度”參數調整為16384(或根據可用內存的較小值),然後更改“上下文溢出策略”以“保持系統提示和第一個用戶消息,截斷中間”。
運行服務。我們假設該服務的地址為“ http:// localhost:1234/v1/”。
然後,我們打開config.json並進行以下修改:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"qwen2-72b" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 32764 ,
"systemAsUser" : true ,
"args" : {}
}
}
},
...
},
...
}最後,運行ailice。您可以根據可用的VRAM或內存空間調整“上下文Windowratio”參數。參數越大,需要越多的VRAM空間。
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5類似於我們在上一節中所做的事情,在使用LM Studio下載並運行LLAVA之後,我們將配置文件修改如下:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"llava-1.6-34b" : {
"formatter" : " AFormatterGPTVision " ,
"contextWindow" : 4096 ,
"systemAsUser" : true ,
"args" : {}
}
},
},
...
},
...
}但是,應該注意的是,當前的開源多模式模型遠非足以執行代理任務,因此此示例是針對開發人員而不是用戶的。
對於HuggingFace上的開源模型,您只需要了解以下信息即可添加對新模型的支持:模型的擁抱面,模型的提示格式和上下文窗口長度。通常,一行代碼足以添加一個新型號,但是有時您不幸,您需要十幾行代碼。
這是添加新LLM支持的完整方法:
打開config.json,您應該將新llm的配置添加到Models.hf.modellist中,看起來如下:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"hf" : {
"modelWrapper" : " AModelCausalLM " ,
"modelList" : {
"meta-llama/Llama-2-13b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
"meta-llama/Llama-2-70b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
...
}
},
...
}
...
}“格式化”是定義LLM及時格式的類。您可以在Core/LLM/Aformatter中找到它們的定義。您可以讀取這些代碼以確定要添加的模型所需的格式。如果您沒有找到它,則需要自己寫一個。幸運的是,格式器是一件非常簡單的事情,可以在十幾行代碼中完成。我相信您將在閱讀一些格式源代碼後就可以理解如何做到這一點。
上下文窗口是變壓器體系結構通常具有的LLM的屬性。它確定模型可以一次處理的文本長度。您需要將新模型的上下文窗口設置為“ ContextWindow”鍵。
“ SystemAsuser”:我們將“系統”角色用作函數調用返回的消息的發件人。但是,並非所有LLM都對系統角色有明確的定義,並且不能保證LLM可以適應這種方法。因此,我們需要使用SystemAsuser設置是否將函數調用返回的文本放入用戶消息中。嘗試將其設置為假。
一切都完成了!使用“ HF:”作為模型名稱的前綴以形成模型ID,並使用新模型的模型ID作為命令參數來啟動ailice!
Ailice有兩種操作模式。一種模式使用單個LLM驅動所有代理,而另一種允許每種類型的代理商指定相應的LLM。後一種模式使我們能夠更好地結合開源型號和商業型號的功能,以較低的成本實現更好的性能。要使用第二種模式,您需要在Config.json中配置AgentModelConfig項目:
"modelID" : " " ,
"agentModelConfig" : {
"DEFAULT" : " openrouter:qwen/qwen-2-72b-instruct " ,
"coder" : " openrouter:deepseek/deepseek-coder "
},首先,確保將ModelID的默認值設置為一個空字符串,然後在AgentModelConfig中為每種類型的代理配置相應的LLM。
最後,您可以通過不指定模型ID來實現第二個操作模式:
ailice_web設計疾病時的基本原理是:
讓我們簡要解釋這些基本原則。
從最明顯的水平開始,高度動態的提示構造使代理商陷入循環的可能性較小。來自外部環境的新變量的湧入會不斷影響LLM,從而避免了這一陷阱。此外,使用當前所有可用信息餵養LLM可以大大提高其輸出。例如,在自動編程中,來自口譯人員或命令行的錯誤消息有助於LLM不斷修改代碼,直到達到正確的結果為止。最後,在動態及時構造中,提示中的新信息也可能來自其他代理,這些信息充當鏈接推理計算的一種形式,使系統的計算機制更加複雜,多樣化,並且能夠產生更豐富的行為。
從實際的角度來看,由於我們有限的上下文窗口,將計算任務分開。我們不能期望在幾千個令牌的窗口內完成複雜的任務。如果我們可以分解一個複雜的任務,以便在有限的資源中解決每個子任務,那將是理想的結果。在傳統的計算模型中,我們始終利用這一點,但是在以LLM為中心的新計算中,這並不容易實現。問題是,如果一個子任務失敗,則整個任務都是失敗的風險。遞歸更具挑戰性:您如何確保每次呼叫,LLM解決子問題的一部分,而不是將整個負擔轉移到呼叫的下一個級別上?我們解決了AILICE中IACT體系結構的第一個問題,第二個問題在理論上並不難解決,但可能需要更智能的LLM。
第三個原則是每個人當前正在從事的工作:讓多個智能代理商進行交互和合作以完成更複雜的任務。該原則的實施實際上解決了上述子任務失敗的問題。多代理協作對於操作中的代理的容錯至關重要。實際上,這可能是新的計算範式和傳統計算之間最大的區別之一:傳統計算是精確且無錯誤的,僅通過單向通信(函數呼叫)分配子任務(函數調用),而新的計算範式是錯誤的,並且是錯誤的,並且是錯誤的。需要在計算單元之間進行雙向通信以糾正錯誤。這將在以下關於IACT框架的部分中詳細說明。
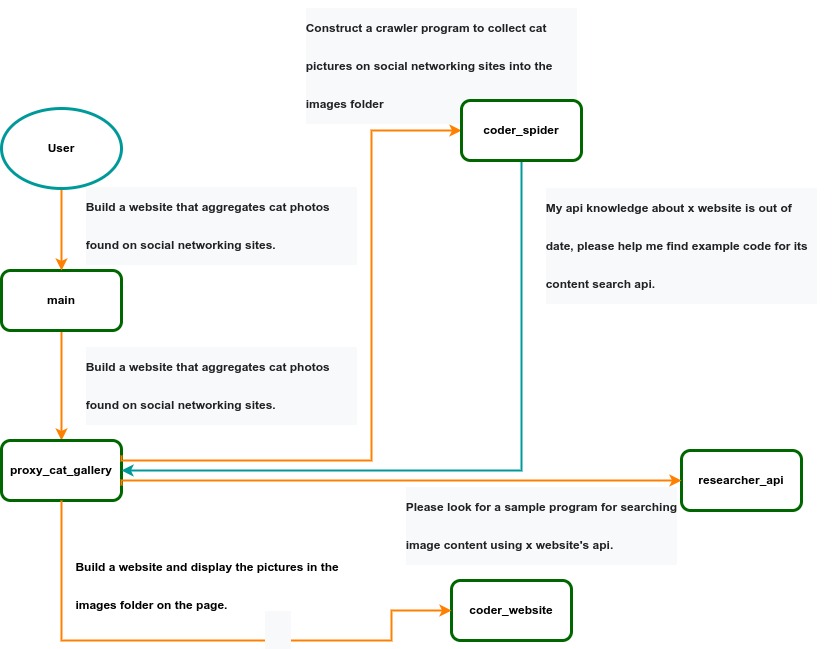 IACT架構圖。用戶要求構建圖像收集和顯示頁面的頁面被動態分解為兩個任務:coder_spider和coder_website。當Coder_spider遇到困難時,它會主動尋求其呼叫者proxy_cat_gallery的幫助。然後,Proxy_cat_gallery創建了另一個代理,Researcher_API,並採用它來解決問題。
IACT架構圖。用戶要求構建圖像收集和顯示頁面的頁面被動態分解為兩個任務:coder_spider和coder_website。當Coder_spider遇到困難時,它會主動尋求其呼叫者proxy_cat_gallery的幫助。然後,Proxy_cat_gallery創建了另一個代理,Researcher_API,並採用它來解決問題。
AILICE可以被視為由LLM提供動力的計算機,其功能包括:
表示文本形式的輸入,輸出,程序和數據。
使用LLM作為處理器。
通過連續調用基本計算單元(類似於傳統計算中的功能)來分解計算任務,這些計算單元基本上是各種功能代理。
因此,用戶輸入文本命令作為一種程序執行,分解為各種“子程序”,並由不同的代理解決,形成了AILICE的基本體系結構。在下文中,我們將對這些基本計算單元的性質提供詳細的解釋。
一個自然的想法是讓LLM通過與最簡單的計算單元中的外部呼叫者和外圍模塊的多輪對話解決某些問題(例如信息檢索,文檔理解等)。我們暫時將此計算單元稱為“函數”。然後,通過與傳統計算的類比,我們允許函數互相呼叫,最後添加線程概念以實現多代理交互。但是,我們可以比這更簡單,更優雅的計算模型。
這裡的關鍵是包裝LLM推理的“函數”實際上可以多次調用並返回。使用編碼器功能的“功能”可以暫停工作,並在編碼過程中遇到不清楚的要求時,將查詢語句返回其呼叫者。如果呼叫者仍然尚不清楚答案,它將繼續詢問下一個更高級別的呼叫者。這個過程甚至可以一直到最終用戶的聊天窗口。添加新信息後,呼叫者將通過通過補充信息來重新激活編碼人員的執行過程。可以看出,此“函數”不是傳統函數,而是可以多次調用的對象。 LLM的高智能使這一有趣的屬性成為可能。您還可以將其視為通過呼叫關係串在一起的代理,每個代理可以在這裡創建和呼叫更多子代理,也可以與呼叫者對話以獲取補充信息或報告其進度。在AILICE中,我們將此計算單元稱為“ AproCessor” (本質上是我們稱為代理商)。它的代碼位於core/aprocessor.py中。
接下來,我們將詳細說明AproCessor內部的結構。 Aprocessor的內部是多輪對話。定義AproCessor功能的“程序”是一種迅速的生成機制,該機制為對話歷史記錄中的每一輪對話生成了提示。對話是一對一的。在外部呼叫者輸入請求之後,LLM將與外圍模塊進行多輪對話(我們將其稱為系統),LLM輸出以各種語法形式呼叫,並且系統調用外圍模塊以生成結果並將結果放入答复消息。 LLM最終得到答案,並響應外部呼叫者,結束此通話。但是,由於對話歷史記錄仍然保存,因此呼叫者可以再次致電以繼續執行更多任務。
我們要介紹的最後一部分是LLM輸出的解析模塊。實際上,我們將LLM的輸出文本視為半自然語言和半正式語言的“腳本”,並使用簡單的解釋器來執行它。我們可以使用正則表達式表達精心設計的語法結構,將其解析為函數調用並執行它。在此設計下,我們可以設計更靈活的功能呼叫語法表格,例如具有一定固定標題的部分(例如“更新內存”),該曲線也可以直接解析並觸發操作的執行。此隱式函數調用無需使LLM意識到其存在,而只需要嚴格遵循某種格式的約定即可。對於最頑固的可能性,我們離開了空間。這裡的解釋器不僅可以使用正則表達式進行模式匹配,而且其評估功能是遞歸的。我們不知道這將是什麼用途,但是留下很酷的可能性似乎還不錯,對嗎?因此,在Aprocessor內部,LLM和解釋器交替完成計算,它們的輸出是彼此的輸入,形成一個週期。
在AILICE中,解釋器是代理商中最關鍵的組成部分之一。我們使用解釋器從LLM輸出中映射文本,將特定模式與操作匹配,包括功能調用,可變定義和參考以及任何用戶定義的操作。有時,這些動作直接與外圍模塊相互作用,影響外部世界。其他時候,它們被用來修改代理商的內部狀態,從而影響其未來的提示。
解釋器的基本結構很簡單:模式成對的列表。模式由正則表達式定義,並且操作由帶有類型註釋的Python函數指定。鑑於句法結構可以嵌套,我們將總體結構稱為入口模式。在運行時,解釋器會在LLM輸出文本中積極檢測這些輸入模式。在檢測到條目模式(如果相應的操作返回數據)後,它立即終止LLM生成以執行相關操作。
AILICE中代理的設計涵蓋了兩個基本方面:基於對話歷史記錄和代理的內部狀態生成提示的邏輯,以及一組模式成對。本質上,代理使用一組模式成對實現解釋器框架;它成為口譯員的組成部分。代理商的內部狀態是口譯員行動的目標之一,對代理人的內部狀態的變化影響了未來提示的方向。
從對話歷史和內部狀態中生成提示幾乎是一個標準化過程,儘管開發人員仍然可以自由選擇完全不同的一代邏輯。開發人員的主要挑戰是創建一個系統提示模板,這對代理商至關重要,並且通常需要最大的努力才能完善。但是,這項任務完全圍繞製作自然語言提示。
Ailice利用文本中嵌入的簡單腳本語言將LLM的基於文本的功能映射到現實世界中。這種簡單的腳本語言包括非嵌套功能調用和用於創建和引用變量的機制,以及用於串聯文本內容的操作。它的目的是使LLMS能夠更自然地發揮影響:從更平滑的文本操縱能力到簡單的功能調用機制,再到多模式可變操作功能。最後,應該指出的是,對於代理商的設計師,他們總是可以自由地擴展這種腳本語言的新語法。這裡介紹的是最小的標準語法結構。
基本語法如下:
變量定義:var_name:= <!|“ some_content” |!>
函數調用/變量引用/文本串聯:!func-name <!|“ ...”,'...',var_name1,“執行以下代碼: n” + var_name2,... |!>
基本變量類型是STR/Aimage/各種多模式類型。 STR類型與Python的字符串語法一致,支持三引號和逃生字符。
這構成了整個嵌入式腳本語言。
變量定義機制引入了一種擴展上下文窗口的方法,允許LLMS將重要內容記錄到變量中以防止忘記。在系統操作期間,自動定義了各種變量。例如,如果在文本消息中檢測到以三重背景為單位包裹的代碼塊,則會自動創建變量來存儲代碼,從而使LLM能夠引用變量以執行代碼,從而避免與時間和與代碼成本相關聯的時間和令牌成本完整復制代碼。此外,某些模塊功能可能會以多模式類型而不是文本返回數據。在這種情況下,系統會自動將其定義為相應的多模式類型的變量,從而允許LLM引用它們(LLM可能會將其發送到另一個模塊進行處理)。
從長遠來看,LLM勢必會演變為能夠看到和聽力的多模式模型。因此, AILICE代理之間的交流應在豐富的文本中,而不僅僅是純文本。儘管Markdown提供了一些標記多模式內容的功能,但它不足。因此,將來我們將需要擴展版本的Markdown版本,以包括各種嵌入式的多模式數據,例如視頻和音頻。
讓我們以圖像為例,以說明AILICE中的多模式機制。當代理接收包含標記圖像的文本時,系統會自動將它們輸入到多模式模型中,以確保模型可以看到這些內容。 Markdown通常使用路徑或URL進行標記,因此我們已經擴展了Markdown語法,以允許使用變量名稱參考多模式內容。
另一個次要的問題是如何使用其內部變量列表的不同代理交換多模式變量。這很簡單:系統會自動檢查從一個代理髮送到另一個代理的消息是否包含內部變量名稱。如果確實如此,則變量內容將傳遞給下一個代理。
為什麼在用路徑和URL標記多模式內容時,我們會遇到實現其他多模式變量機制的麻煩?這是因為只有在AILICE完全在本地環境中運行(不是設計意圖)時,基於本地文件路徑的多模式內容才可行。 AILICE的分佈方式可能是在不同計算機上運行的核心和模塊,甚至可能會加載在Internet上運行的服務以提供某些計算。這使得返回完整的多模式數據更具吸引力。當然,這些為未來製定的設計可能是過度工程的,如果是的話,我們將來會修改它們。
AILICE的目標之一是實現內省和自我擴張(這就是為什麼我們的徽標具有蝴蝶在水中反射的蝴蝶的原因)。這將使她能夠理解自己的代碼並構建新功能,包括新的外部交互模塊(即新功能)和新型代理(APROMPT類) 。結果,LLM的知識和能力將得到更徹底的釋放。
實施自我擴張涉及兩個部分。一方面,需要在運行時動態加載新的模塊和新類型的代理(APROMPT類),並自然集成到計算系統中,以參與處理,我們將其稱為動態加載。另一方面,AILICE需要能夠構建新模塊和代理類型的能力。
動態加載機製本身俱有重要意義:它代表了一種新穎的軟件更新機制。我們可以允許AILICE在Internet上搜索自己的擴展代碼,檢查代碼是否有安全性,修復錯誤和兼容性問題,並最終將擴展程序作為其本身的一部分運行。因此,AILICE開發人員只需要在Internet上放置其貢獻代碼,而無需合併到主代碼庫中或考慮任何其他安裝方法。動態加載機制的實現正在不斷改進。它的核心在於擴展程序包提供了一些描述其功能的文本。在運行時,AILICE中的每個代理都可以通過語義匹配和其他方式找到合適的功能或代理類型來為自己解決子問題。
構建新模塊是一個相對簡單的任務,因為模塊需要滿足的接口約束非常簡單。我們可以教LLM通過一個示例來構建新模塊。更複雜的任務是新代理類型(APROMPT類)的自我建設,這需要對Ailice的整體體系結構有很好的了解。系統提示的構建特別精緻,即使對於人類來說,也是一項具有挑戰性的任務。因此,我們將希望將來寄託在更強大的LLM上,以實現內省,允許Ailice通過閱讀自己的源代碼來理解自己(對於像程序這樣的複雜的東西,介紹它的最佳方法是展示自己)構建更好的新代理商。
對於開發代理,AILICE的主環位於ailicemain.py或ui/app.py文件中。為了進一步了解代理的構造,您需要在“提示”文件夾中讀取代碼,通過讀取這些代碼,您可以了解如何動態構造代理的提示。
對於想要了解AILICE內部操作邏輯的開發人員,請閱讀core/aprocessor.py和core/interneTer.py。這兩個文件總共包含大約三百行代碼,但它們包含AILICE的基本框架。
在這個項目中,實現AI代理的所需功能是主要目標。次要目標是代碼清晰度和簡單性。 AI代理的實現仍然是一個探索性主題,因此我們旨在最大程度地減少軟件中的剛性組件(例如,對未來開發構成約束的架構/接口),並為應用程序層(例如,提示類)提供最大的靈活性。抽象,重複數據刪除和脫鉤不是直接的優先級。
實現功能時,請始終選擇最明顯的方法。 “最佳”的指標通常包括從較高的角度來看問題的特徵,例如維護代碼的清晰度和簡單性,並確保更改不會顯著提高整體複雜性或限制軟件的未來可能性。
除非絕對必要,否則添加評論不是強制性的;努力使代碼變得足夠清晰,以使其具有自我解釋。儘管對於欣賞評論的開發人員而言,這可能不是一個問題,但在AI時代,我們可以隨時生成詳細的代碼解釋,從而消除了對非結構化,難以維護的評論的需求。
添加代碼時,請按照Occam剃須刀的原理;切勿添加不必要的線條。
核心中的功能或方法不應超過60行。
儘管沒有明確的編碼樣式約束,但就命名和案例用法保持了與原始代碼的一致性或相似性,以避免可讀性負擔。
AILICE旨在在少於5000條線的比例內實現多模式和自擴展的特徵,並在當前階段達到其最終形式。對簡潔代碼的追求不僅是因為簡潔的代碼通常代表了更好的實施,還因為它使AI能夠儘早發展自省的能力並促進更好的自我膨脹。請遵守上述規則,並勤奮地接近每條代碼。
Ailice的基本任務是雙重的:一個是根據文本完全釋放LLM的功能;另一個是探索長期記憶的更好機制,並形成對大量文本的連貫理解。我們的發展努力圍繞著這兩個焦點。
如果您對ailice本身的發展感興趣,則可以考慮以下方向:
探索改進的長期記憶機制,以增強每個代理的能力。我們需要一種長期的記憶機制,使能夠始終了解大量內容並促進關聯。目前,最可行的選擇是用知識圖替換矢量數據庫,這將極大地有助於對長文本/代碼的理解,並使我們能夠建立真正的個人AI助手。
多模式支持。對多模式模型的支持已經完成,目前的開發重點正在轉向外圍模塊的多模式支持。我們需要一個模塊,該模塊根據屏幕截圖操作計算機並模擬鼠標/鍵盤操作。
自我擴展的支持。我們的目標是啟用語言模型自主編碼和實現新的外圍模塊/代理類型,並動態加載它們以立即使用。這種功能將使自我擴張,使系統能夠無縫整合新功能。我們已經完成了大部分功能,但是我們仍然需要開發構建新型代理類型的功能。
富含UI接口。我們需要在對話框窗口中將代理輸出到樹結構中,並動態更新所有代理的輸出。並在Web界面上接受用戶輸入,然後將其傳輸到腳本的標準輸入中,在使用sudo時,尤其需要。
根據當前框架開發具有各種功能的代理。
探索IACT體系結構在復雜任務上的應用。通過使用交互式代理調用樹,我們可以分解大量文檔,以改善閱讀理解,並將復雜的軟件工程任務分解為較小的模塊,從而完成整個項目的構建和測試。這需要一系列複雜的及時設計和測試工作,但對未來有一個令人興奮的希望。 IACT體系結構可大大減輕上下文窗口施加的資源約束,使我們能夠動態適應更複雜的任務。
使用自擴展機制構建豐富的外部交互模塊!這將在ailiceevo中完成。
除了上述任務外,我們還應該開始積極考慮創建具有較低知識內容但推理能力較高的較小LLM的可能性。


