AIlice
1.0.0

Schnellstart • Demo • Entwicklung • Twitter • Reddit
22. Juni 2024: Wir sind in die Ära der lokal laufenden Jarvis-ähnlichen AI-Assistenten eingetreten! Mit den neuesten Open-Source-LLMs können wir komplexe Aufgaben lokal ausführen! Klicken Sie hier, um mehr zu erfahren.
Stütze ist ein voll autonomer AI-Agent für allgemeine Purpose . Dieses Projekt zielt darauf ab, einen eigenständigen Assistenten für künstliche Intelligenz zu schaffen, ähnlich wie Jarvis, basierend auf der Open-Source-LLM. Ailice erreicht dieses Ziel, indem er einen "Textcomputer" erstellt, der ein großes Sprachmodell (LLM) als Kernprozessor verwendet. Derzeit zeigt die Querleistung Kenntnisse in einer Reihe von Aufgaben, einschließlich thematischer Forschung, Kodierung, Systemmanagement, Literaturübersicht und komplexen hybriden Aufgaben, die über diese grundlegenden Funktionen hinausgehen.
Die Striche hat in alltäglichen Aufgaben mit GPT-4 nahezu perfekte Leistung erzielt und macht mit den neuesten Open-Source-Modellen Fortschritte auf die praktische Anwendung.
Wir werden letztendlich die Selbstbewertung von AI-Agenten erreichen. Das heißt, AI -Agenten werden ihre eigenen Feature -Erweiterungen und neue Arten von Agenten autonom aufbauen und die Wissens- und Argumentationsfähigkeiten von LLM nahtlos in die reale Welt aussagen.
Sehen Sie sich die folgenden Videos an:
Zu den wichtigsten technischen Merkmalen von Stranken gehören:
Installieren und Ausführen von den folgenden Befehlen. Sobald die Ablagerung gestartet ist, öffnen Sie einen Browser, um die von ihnen bereitgestellte Webseite zu öffnen, eine Dialogschnittstelle wird angezeigt. Führen Sie Befehle an, um das Gespräch durchzuführen, um verschiedene Aufgaben zu erledigen. Für Ihren ersten Gebrauch können Sie die Befehle in den coolen Dingen, die wir ausführen, ausprobieren, um schnell vertraut zu werden.
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2Listen wir einige typische Anwendungsfälle auf. Ich verwende diese Beispiele häufig, um die Stranken während der Entwicklung zu testen und eine stabile Leistung zu gewährleisten. Trotz dieser Tests werden die Ausführungsergebnisse jedoch von der ausgewählten Modell, der Codeversion und sogar der Testzeit beeinflusst. (GPT-4 kann unter hohen Belastungen eine Leistungsabnahme verzeichnen. Einige zufällige Faktoren können auch zu unterschiedlichen Ergebnissen führen, wenn das Modell mehrmals ausgeführt wird. Manchmal funktioniert die LLM sehr intelligent, aber manchmal nicht) ist die Streben Basierend auf der Zusammenarbeit mit mehreren Agenten und als Benutzer sind Sie auch einer der "Agenten". Wenn Stranken zusätzliche Informationen benötigt, wird daher Input von Ihnen eingebracht, und die Gründlichkeit Ihrer Details ist entscheidend für ihren Erfolg. Wenn die Aufgabenausführung nicht zu kurz ist, können Sie sie in die richtige Richtung führen und sie korrigiert ihren Ansatz.
Der letzte Punkt ist zu beachten, dass die Streben derzeit einen Laufzeitkontrollmechanismus fehlen, sodass sie möglicherweise in einer Schleife stecken bleibt oder längere Zeit läuft. Wenn Sie einen kommerziellen LLM verwenden, müssen Sie ihren Betrieb genau überwachen.
"Bitte listen Sie den Inhalt des aktuellen Verzeichnisses auf."
"Finden Sie David Tongs QFT -Vorlesungsnotizen und laden Sie sie in den Ordner" Physik "im aktuellen Verzeichnis herunter. Möglicherweise müssen Sie zuerst den Ordner erstellen."
"Bereiten Sie eine einfache Website auf diesem Computer mit dem Flask -Framework ein. Stellen Sie sicher, dass die Zugänglichkeit unter 0,0.0.0:59001 gewährleistet ist. Auf der Website sollte über eine einzelne Seite verfügen, die alle Bilder im Verzeichnis" Bilder "anzeigen kann." Dieser ist besonders interessant. Wir wissen, dass das Zeichnen in der Docker -Umgebung nicht erfolgen kann, und die gesamte Dateiausgabe, die wir generieren, muss mit dem Befehl "Docker CP" kopiert werden, um es zu sehen. Sie können dieses Problem jedoch selbst lösen lassen: Bereitstellen einer Website im Container gemäß der obigen Eingabeaufforderung (es wird empfohlen, Ports zwischen 59001 und 59200 zu verwenden, die portiert wurden). Die Bilder im Verzeichnis werden automatisch angezeigt Die Webseite. Auf diese Weise können Sie den generierten Bildinhalt auf dem Host dynamisch sehen. Sie können auch versuchen, sie iterieren zu lassen, um komplexere Funktionen zu erzeugen. Wenn Sie keine Bilder auf der Seite sehen, überprüfen Sie bitte, ob sich der Ordner "Bilder" der Website von dem Ordner "Images" unterscheidet (z. B. kann er sich unter "Static/Images" befinden).
"Bitte verwenden Sie die Python-Programmierung, um die folgenden Aufgaben zu lösen: Erhalten Sie die Preisdaten von BTC-UsDT für sechs Monate und ziehen Sie sie in ein Diagramm und speichern Sie sie im Verzeichnis" Bilder "." Wenn Sie die obige Website erfolgreich bereitgestellt haben, können Sie jetzt die BTC -Preiskurve direkt auf der Seite sehen.
"Finden Sie den Prozess auf Port 59001 und beenden Sie ihn." Dadurch wird das gerade festgelegte Website -Serviceprogramm beendet.
"Bitte verwenden Sie CadQuery, um einen Pokal zu implementieren." Dies ist auch ein sehr interessanter Versuch. CadQuery ist ein Python -Paket, das die Python -Programmierung für die CAD -Modellierung verwendet. Wir versuchen, Striche zu verwenden, um 3D -Modelle automatisch zu erstellen! Dies kann uns einen Einblick geben, wie reife geometrische Intuition im Weltbild von LLM sein kann. Natürlich können wir nach der Implementierung einer multimodalen Unterstützung ermöglichen, die von ihr erstellten Modelle zu sehen, um weitere Anpassungen zu erhalten und eine hochwirksame Rückkopplungsschleife festzulegen. Auf diese Weise könnte es möglich sein, eine wirklich verwendbare Sprachmodellierung zu erreichen.
"Bitte suchen Sie im Internet nach 100 Tutorials in verschiedenen Physikzweigen und laden Sie die PDF -Dateien herunter, die Sie finden, in einem Ordner namens" Physik ". Es ist nicht erforderlich, den Inhalt von PDFs zu überprüfen. Wir benötigen für den Moment nur eine grobe Sammlung." Die Verwendung von Strichen zur Erreichung der automatischen Datensatzsammlung und -konstruktion ist eines unserer fortlaufenden Ziele. Derzeit hat der für diese Funktionalität verwendete Forscher immer noch einige Mängel, kann jedoch bereits einige faszinierende Ergebnisse liefern.
"Bitte führen Sie eine Untersuchung zu Open-Source-PDF-OCR-Tools durch, wobei der Schwerpunkt auf denjenigen liegt, die mathematische Formeln erkennen und in Latexcode umwandeln können. Konsolidieren Sie die Ergebnisse in einen Bericht."
1. Finden Sie das Video von Feynmanns Vorträgen auf YouTube und laden Sie sie nach Feynmann/ Subdir herunter. Sie müssen zuerst den Ordner erstellen. 2. Extrahieren Sie das Audio aus diesen Videos und speichern Sie sie vor Feynmann/Audio. 3. Konvertieren Sie diese Audiodateien in Text und fusionieren Sie sie in ein Textdokument. Sie müssen zuerst zum Umarmungsgesicht gehen und die Seite für Whisper-Large-V3 suchen, den Beispielcode finden und auf den Beispielcode verweisen, um dies zu erledigen. 4. Finden Sie die Antwort auf diese Frage aus den gerade extrahierten Textdateien: Warum brauchen wir Antipartikel? Dies ist eine multi-stufige Eingabeaufgabe, bei der Sie Schritt für Schritt mit der Querstriche interagieren müssen, um die Aufgabe zu erledigen. Natürlich gibt es möglicherweise unerwartete Ereignisse auf dem Weg, sodass Sie eine gute Kommunikation mit der Striche aufrechterhalten müssen, um alle Probleme zu lösen, die Sie begegnen ( mit der Taste "Interrupt", um die Striche jederzeit zu unterbrechen und eine Eingabeaufforderung zu geben, ist eine gute Option! ). Basierend auf dem Inhalt des heruntergeladenen Videos können Sie die Frage einer physikbezogenen Frage stellen. Sobald Sie die Antwort erhalten haben, können Sie zurückblicken und sehen, wie weit Sie zusammengekommen sind.
1. Verwenden Sie SDXL, um ein Bild von "einer fetten Orangenkatze" zu erzeugen. Sie müssen den Beispielcode auf seiner Seite mit der Umarmung als Referenz finden, um die Arbeiten und Bildgenerierung zu vervollständigen. Speichern Sie das Bild im aktuellen Verzeichnis und anzeigen Sie es an. 2. Lassen Sie uns nun eine einseitige Website implementieren. Die Funktion der Webseite besteht darin, die vom Benutzer eingegebene Textbeschreibung in ein Bild zu konvertieren und sie anzuzeigen. Siehe den Text-zu-Image-Code von zuvor. Die Website läuft unter 127.0.0.1:59102. Speichern Sie den Code auf ./image_gen, bevor Sie ihn ausführen. Möglicherweise müssen Sie zuerst den Ordner erstellen.
"Bitte schreiben Sie ein Ext-Modul. Die Funktion des Moduls besteht darin, den Inhalt der zugehörigen Seiten auf dem Wiki über Schlüsselwörter zu erhalten." Streben können externe Interaktionsmodule (wir nennen es ext-modules) alleine konstruieren, wodurch sie unbegrenzt eine unbegrenzte Erweiterbarkeit ausbringt. Alles was es braucht sind ein paar Eingaben von Ihnen. Sobald das Modul konstruiert ist, können Sie die Streitarbeit unterweisen, indem Sie sagen: "Bitte laden Sie das neu implementierte Wiki -Modul und verwenden Sie es, um den Eintrag zur Relativitätstheorie abzufragen."
Agenten müssen mit verschiedenen Aspekten der Umgebung interagieren, ihre Betriebsumgebung ist häufig komplexer als eine typische Software. Es kann lange dauern, die Abhängigkeiten zu installieren, aber zum Glück wird dies im Grunde genommen automatisch durchgeführt.
Um die Streitigkeit auszuführen, müssen Sie sicherstellen, dass die Chrom korrekt installiert ist. Wenn Sie Code in einer sicheren virtuellen Umgebung ausführen müssen, müssen Sie auch Docker installieren.
Wenn Sie Streben in einer virtuellen Maschine ausführen möchten, stellen Sie sicher, dass Hyper-V ausgeschaltet ist (ansonsten kann Lama.cpp nicht installiert werden). In einer VirtualBox-Umgebung können Sie diese deaktivieren, indem Sie folgende Schritte befolgen: Deaktivieren Sie PAE/NX und VT-X/AMD-V (Hyper-V) für VirtualBox-Einstellungen für die VM. Setzen Sie die paravirtualisierende Schnittstelle auf standardmäßig, deaktivieren Sie verschachtelte Paging.
Sie können den folgenden Befehl zur Installation von Strichen verwenden (es wird dringend empfohlen, Tools wie Conda zu verwenden, um eine neue virtuelle Umgebung zur Installation von Stragen zu erstellen, um Abhängigkeitskonflikte zu vermeiden):
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .Die standardmäßige Installation von Strichen wird langsam ausgeführt, da CPU als Inferenzhardware des Langzeitspeichermoduls verwendet wird. Daher wird dringend empfohlen, die GPU -Beschleunigungsunterstützung zu installieren:
ailice_turboFür Benutzer, die die Huggingface-Modelle/Sprachdialog/Modell-Feinabstimmungs-/PDF-Lesefunktionen verwenden müssen, können Sie einen der folgenden Befehle verwenden (die Installation von zu vielen Funktionen erhöht die Wahrscheinlichkeit von Abhängigkeitskonflikten, sodass nur die Installation nur die installieren wird notwendige Teile):
pip install -e .[huggingface]
pip install -e .[speech]
pip install -e .[finetuning]
pip install -e .[pdf-reading]Sie können jetzt eine Striche rennen! Verwenden Sie die Befehle in der Verwendung.
Standardmäßig ist das Google -Modul in der Querleistung eingeschränkt, und die wiederholte Verwendung kann zu Fehlern führen, die einige Zeit für die Lösung erfordern. Dies ist eine unangenehme Realität in der KI -Ära; Traditionelle Suchmaschinen ermöglichen nur den Zugriff auf echte Benutzer, und AI -Agenten fallen derzeit nicht in die Kategorie der „echten Benutzer“. Während wir alternative Lösungen haben, müssen alle einen API -Schlüssel konfigurieren, der ein hohes Hindernis für den Eintritt für normale Benutzer festlegt. Für Benutzer, die häufiger Zugriff auf Google benötigen, gehen Sie jedoch davon aus, dass Sie bereit wären, den Aufwand für die Bewerbung für die offizielle API -Taste eines Google zu ertragen (wir beziehen uns auf die benutzerdefinierte Suche JSON -API, mit der Sie das gesamte Internet bei der Suche nach dem gesamten Internet angeben müssen die Zeit der Schöpfung) für Suchaufgaben. Für diese Benutzer öffnen Sie bitte config.json und verwenden Sie die folgende Konfiguration:
{
...
"services": {
...
"google": {
"cmd": "python3 -m ailice.modules.AGoogleAPI --addr=ipc:///tmp/AGoogle.ipc --api_key=YOUR_API_KEY --cse_id=YOUR_CSE_ID",
"addr": "ipc:///tmp/AGoogle.ipc"
},
...
}
}
und installieren Sie Google-API-Python-Client:
pip install google-api-python-clientStarten Sie dann einfach die Streben.
Standardmäßig nutzt die Codeausführung die lokale Umgebung. Um potenzielle KI -Fehler zu verhindern, die zu irreversiblen Verlusten führen, wird empfohlen, Docker zu installieren, einen Container zu erstellen und die Konfigurationsdatei von Ailice zu ändern (die Erkrankung stellt beim Start den Ort der Konfigurationsdatei bereit). Konfigurieren Sie das Code -Ausführungsmodul (Incripter), um in einer virtuellen Umgebung zu arbeiten.
docker build -t env4scripter .
docker run -d -p 127.0.0.1:59000-59200:59000-59200 --name scripter env4scripterIn meinem Fall, wenn Quer start
nano ~ /.config/ailice/config.jsonÄndern Sie "Scripter" unter "Services":
{
...
"services": {
...
"scripter": {"cmd": "docker start scripter",
"addr": "tcp://127.0.0.1:59000"},
}
}
Jetzt, da die Umgebungskonfiguration durchgeführt wurde.
Aufgrund des laufenden Entwicklungsstatus von Stranken kann die Aktualisierung des Codes zu Inkompatibilitätsproblemen zwischen vorhandenen Konfigurationsdateien und Docker -Container mit dem neuen Code führen. Die gründlichste Lösung für dieses Szenario ist das Löschen der Konfigurationsdatei (sicherstellen, dass API -Schlüssel vorher speichern) und den Container und dann eine vollständige Neuinstallation durchführen. In den meisten Situationen können Sie das Problem jedoch beheben, indem Sie einfach die Konfigurationsdatei löschen und das Luftangriffsmodul im Container aktualisieren .
rm ~ /.config/ailice/config.json
cd Ailice
docker cp ailice/__init__.py scripter:scripter/ailice/__init__.py
docker cp ailice/common/__init__.py scripter:scripter/ailice/common/__init__.py
docker cp ailice/common/ADataType.py scripter:scripter/ailice/common/ADataType.py
docker cp ailice/common/lightRPC.py scripter:scripter/ailice/common/lightRPC.py
docker cp ailice/modules/__init__.py scripter:scripter/ailice/modules/__init__.py
docker cp ailice/modules/AScripter.py scripter:scripter/ailice/modules/AScripter.py
docker cp ailice/modules/AScrollablePage.py scripter:scripter/ailice/modules/AScrollablePage.py
docker restart scripterSie können einen Befehl direkt aus den typischen Anwendungsfällen nachstehend kopieren, um die Striche auszuführen.
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2
ailice_web --modelID=anthropic:claude-3-5-sonnet-20240620 --contextWindowRatio=0.1
ailice_web --modelID=oai:gpt-4-1106-preview --chatHistoryPath=./chat_history
ailice_web --modelID=anthropic:claude-3-opus-20240229 --prompt= " researcher "
ailice_web --modelID=mistral:mistral-large-latest
ailice_web --modelID=deepseek:deepseek-chat
ailice_web --modelID=hf:Open-Orca/Mistral-7B-OpenOrca --quantization=8bit --contextWindowRatio=0.6
ailice_web --modelID=hf:NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO --quantization=4bit --contextWindowRatio=0.3
ailice_web --modelID=hf:Phind/Phind-CodeLlama-34B-v2 --prompt= " coder-proxy " --quantization=4bit --contextWindowRatio=0.6
ailice_web --modelID=groq:llama3-70b-8192
ailice_web # Use models configured individually for different agents under the agentModelConfig field in config.json.
ailice_web --modelID=openrouter:openrouter/auto
ailice_web --modelID=openrouter:mistralai/mixtral-8x22b-instruct
ailice_web --modelID=openrouter:qwen/qwen-2-72b-instruct
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5Es ist zu beachten, dass der letzte Anwendungsfall erforderlich ist, dass Sie den LLM -Inferenzdienst zuerst konfigurieren. Weitere Informationen zu LLM -Support erhalten. Durch die Verwendung von Inferenz -Frameworks wie LM Studio können begrenzte Hardware -Ressourcen zur Unterstützung größerer Modelle verwendet werden, um eine schnellere Inferenzgeschwindigkeit und eine schnellere Startgeschwindigkeit zu ermöglichen, wodurch sie für normale Benutzer besser geeignet sind.
Wenn Sie es zum ersten Mal ausführen, werden Sie gebeten, den Api-Key of OpenAI einzugeben. Wenn Sie nur Open Source LLM verwenden möchten, müssen Sie es nicht eingeben. Sie können den API-Key auch ändern, indem Sie die Datei config.json bearbeiten. Bitte beachten Sie, dass das erste Mal bei der Verwendung eines Open -Source -LLM lange dauern wird, bis die Modellgewichte heruntergeladen werden. Bitte haben Sie sicher, dass Sie genügend Zeit und Speicherplatz haben.
Wenn Sie den Sprachschalter zum ersten Mal einschalten, müssen Sie möglicherweise lange beim Start warten. Dies liegt daran, dass die Gewichte der Spracherkennung und der TTS -Modelle im Hintergrund heruntergeladen werden.
Wie in den Beispielen gezeigt, können Sie den Agenten über AILICE_WEB verwenden und eine Web -Dialog -Schnittstelle bietet. Sie können den Standardwert jedes Parameters durch Verwendung anzeigen
ailice_web --helpDie Standardwerte für alle Befehlszeilenargumente können angepasst werden, indem die entsprechenden Parameter in config.json geändert werden.
Die Konfigurationsdatei von Seltsamen heißt Config.Json, und ihr Standort wird an der Befehlszeile ausgegeben, wenn die Strichung gestartet wird. In diesem Abschnitt werden wir vorstellen, wie die externen Interaktionsmodule über die Konfigurationsdatei konfiguriert werden.
In der Querformung verwenden wir den Begriff "Modul", um speziell auf Komponenten zu verweisen, die Funktionen für die Interaktion mit der externen Welt bieten. Jedes Modul wird als unabhängiger Prozess ausgeführt. Sie können in verschiedenen Software- oder Hardware -Umgebungen aus dem Kernprozess ausgeführt werden, sodass die Krankheit verteilt werden kann. Wir stellen eine Reihe grundlegender Modulkonfigurationen in der für den Betrieb von Ailice erforderlichen Konfigurationsdatei (z. B. Vektordatenbank, Suche, Browser, Codeausführung usw.) an. Sie können auch Konfigurationen für alle Drittanbietermodule hinzufügen und ihre Laufzeitadresse und -anschluss angeben, nachdem die Strichung in Betrieb genommen wird, um automatisch zu laden. Die Modulkonfiguration ist sehr einfach und besteht aus nur zwei Elementen:
"services" : {
...
"scripter" : { "cmd" : " python3 -m ailice.modules.AScripter --addr=tcp://127.0.0.1:59000 " ,
"addr" : " tcp://127.0.0.1:59000 " },
...
}Unter "CMD" befindet sich eine Befehlszeile, mit der der Prozess des Moduls gestartet wird. Wenn die Strichung beginnt, wird diese Befehle automatisch ausgeführt, um die Module zu starten. Benutzer können jeden Befehl angeben und erhebliche Flexibilität bieten. Sie können den Prozess eines Moduls lokal starten oder Docker verwenden, um einen Prozess in einer virtuellen Umgebung zu starten oder sogar einen Remote -Prozess zu starten. Einige Module verfügen über mehrere Implementierungen (z. B. Google/Storage), und Sie können hier konfigurieren, um zu einer anderen Implementierung umzusteigen.
"ADDR" bezieht sich auf die Adresse und Portnummer des Modulprozesses. Benutzer könnten durch die Tatsache verwirrt sein, dass viele Module in der Standardkonfiguration sowohl "CMD" als auch "ADDR" mit Adressen und Portnummern enthalten, was zu Redundanz führt. Dies liegt daran, dass "CMD" im Prinzip einen Befehl enthalten kann (der Adressen und Portnummern oder überhaupt keine enthalten kann). Daher ist ein separates "ADDR" -Olement erforderlich, um die Streben zu informieren, wie er auf den Modulprozess zugreift.
Interrupts. Interrupts sind der zweite Interaktionsmodus, der von der Abrechnung unterstützt wird und die Sie jederzeit unterbrechen und den Agenten von Ailice auffordern können, um Fehler zu korrigieren oder Anleitung zu geben . In Ailice_Web wird während der Aufgabenausführung von Ailice auf der rechten Seite des Eingabefelds eine Interrupt -Taste angezeigt. Wenn Sie es drücken, pausiert die Ausführung von Ailice und wartet auf Ihre schnelle Nachricht. Sie können Ihre Eingabeaufforderung in das Eingabefeld eingeben und die Eingabetaste drücken, um die Nachricht an den Agenten zu senden, der derzeit die Subtask ausführt. Eine kompetente Nutzung dieser Funktion erfordert ein gutes Verständnis der Funktionsweise von Ailice, insbesondere der Architektur von Agent Call Tree. Es umfasst auch mehr auf das Fenster des Befehlszeilens als auf die Dialoginterface während der Aufgabenausführung von Ailice. Insgesamt ist dies eine sehr nützliche Funktion, insbesondere bei weniger leistungsstarken Sprachmodell -Setups.
Verwenden Sie zuerst GPT-4, um einige einfache Anwendungsfälle erfolgreich durchzuführen, und starten Sie dann die Striche mit einem weniger leistungsstarken (aber billigeren/offenen) Modell neu, um neue Aufgaben weiterhin auf der Grundlage der vorherigen Gesprächsgeschichte auszuführen . Auf diese Weise dient die von GPT-4 bereitgestellte Geschichte als ein erfolgreiches Beispiel, das wertvolle Referenz für andere Modelle bietet und die Erfolgschancen erheblich erhöht.
Aktualisiert am 23. August 2024.
Derzeit kann Querstriche komplexere Aufgaben mit dem lokal ausgeführten 72B Open-Source-Modell (QWEN-2-72B-ISTRECT-ISTRECT DURCH 4090X2) erledigen , wobei die Leistung dem von Modellen der GPT-4-Ebene nähert. In Anbetracht der niedrigen Kosten für Open-Source-Modelle empfehlen wir den Benutzern dringend, sie zu verwenden. Darüber hinaus gewährleistet die Lokalisierung von LLM -Operationen einen absoluten Datenschutzschutz, eine seltene Qualität in AI -Anwendungen in unserer Zeit. Klicken Sie hier, um zu erfahren, wie Sie dieses Modell lokal ausführen. Für Benutzer, deren GPU -Bedingungen nicht ausreichen, um große Modelle auszuführen, ist dies kein Problem. Sie können den Online-Inferenzdienst verwenden (z. B. OpenRouter, dies wird als nächstes erwähnt), um auf diese Open-Source-Modelle zuzugreifen (obwohl dies die Privatsphäre opfert). Obwohl Open-Source-Modelle noch keine kommerziellen Modelle der GPT-4-Ebene auf GPT-4-Stufe nicht vollständig konkurrieren können, können Sie Agenten hervorrufen, indem Sie unterschiedliche Modelle entsprechend ihren Stärken und Schwächen nutzen. Weitere Informationen finden Sie unter Verwendung verschiedener Modelle in verschiedenen Agenten.
Claude-3-5-SONNET-20240620 bietet die beste Leistung.
GPT-4O und GPT-4-1106-Präview bieten ebenfalls die Leistung auf höchster Ebene. Aufgrund der langen Laufzeit des Agenten und des großen Verbrauchs von Tokens verwenden Sie jedoch kommerzielle Modelle mit Vorsicht. GPT-4O-Mini funktioniert sehr gut, und obwohl es nicht erstklassig ist, macht sein niedriger Preis dieses Modell sehr attraktiv. GPT-4-Turbo / GPT-3,5-Turbo ist überraschend faul, und wir konnten noch nie einen stabilen sofortigen Ausdruck finden.
Zu den Open-Source-Modellen gehören diejenigen, die normalerweise gut abschneiden, Folgendes:
Meta-Llama-3.1-405B-Instruktur ist schön, aber zu groß, um auf dem PC praktisch zu sein.
Für Benutzer, deren Hardwarefunktionen nicht ausreichen, um Open-Source-Modelle lokal auszuführen, und die nicht in der Lage sind, API-Schlüssel für kommerzielle Modelle zu erhalten, können sie die folgenden Optionen ausprobieren:
OpenRouter Dieser Service kann Ihre Inferenzanfragen an verschiedene Open-Source- oder Handelsmodelle weiterleiten, ohne dass Open-Source-Modelle lokal bereitgestellt oder API-Schlüssel für verschiedene kommerzielle Modelle angewendet werden müssen. Es ist eine fantastische Wahl. Ailice unterstützt automatisch alle Modelle im OpenRouter. Sie können Autorouter: OpenRouter/Auto auswählen, um den Autorouter automatisch für Sie weiterzuleiten, oder Sie können ein bestimmtes Modell angeben, das in der Datei config.json konfiguriert ist. Vielen Dank an @babybirdprd für die Empfehlung von OpenRouter.
GREQ: LLAMA3-70B-8192 unterstützt natürlich auch andere Modelle unter GROQ. Ein Problem beim Laufen unter GROQ ist, dass es einfach ist, die Ratengrenzen zu überschreiten, sodass es nur für einfache Experimente verwendet werden kann.
Wir werden das derzeit am besten erbringende Open-Source-Modell auswählen, um Benutzer von Open-Source-Modellen eine Referenz bereitzustellen.
Das Beste unter allen Modellen: QWEN-2-72B-Struktur . Dies ist das erste Open-Source-Modell mit praktischem Wert . Es ist ein großartiger Fortschritt! Es hat Argumentationsfunktionen in der Nähe von GPT-4, wenn auch noch nicht ganz da. Mit aktivem Benutzerintervention durch die Interrupt -Funktion können viele komplexere Aufgaben erfolgreich erledigt werden.
Die zweitbesten darstellenden Modelle: Mixtral-8x22b-Instruktur und Meta-Llama/Meta-Llama-3-70B-Instruktur . Es ist erwähnenswert, dass die Modelle der LLAMA3 -Serie nach der Quantisierung einen erheblichen Leistungsabfall zu zeigen scheinen, was ihren praktischen Wert verringert. Sie können sie mit GRQ verwenden.
Wenn Sie ein besseres Modell finden, lassen Sie es mich bitte wissen.
Für fortgeschrittene Spieler ist es unvermeidlich, mehr Modelle auszuprobieren. Glücklicherweise ist dies nicht schwer zu erreichen.
Für OpenAI/Mistral/Anthropic/GROQ -Modelle müssen Sie nichts tun. Verwenden Sie einfach die ModellID, die aus dem offiziellen Modellnamen besteht, der dem "OAI:"/"Mistral:"/"Anthropic:"/"GREQ:" Prefix angehängt ist. Wenn Sie ein Modell verwenden müssen, das nicht in der unterstützten Liste von Ailice enthalten ist, können Sie dies beheben, indem Sie einen Eintrag für dieses Modell in der Datei config.json hinzufügen. Die Methode zum Hinzufügen besteht darin, den Eintrag eines ähnlichen Modells direkt zu verweisen, den Kontextwindow auf den tatsächlichen Wert zu ändern, den Systemasuser mit dem ähnlichen Modell übereinzustimmen und Args auf leeres DICT festzulegen.
Sie können jeden Drittanbieter-Inferenzserver verwenden, der mit der OpenAI-API kompatibel ist, um die integrierte LLM-Inferenzfunktionen in der Luft zu ersetzen. Verwenden Sie einfach dasselbe Konfigurationsformat wie die OpenAI -Modelle und ändern Sie die BaseURL, Apikey, Contextwindow und andere Parameter (tatsächlich unterstützt die Belüftung GROQ -Modelle).
Für Inferenzserver, die die OpenAI-API nicht unterstützen, können Sie versuchen , sie in eine OpenAI-kompatible API zu verwandeln (wir haben unten ein Beispiel).
Es ist wichtig zu beachten, dass aufgrund des Vorhandenseins vieler Systemnachrichten in den Konversationsdatensätzen von Ailice, was für LLM kein häufiger Anwendungsfall ist, von der Unterstützung für die spezifische Implementierung dieser Inferenzserver abhängt. In diesem Fall können Sie den SystemaSuser -Parameter auf treu einstellen, um das Problem zu umgehen. Dies kann zwar verhindern, dass das Modell bei seiner optimalen Leistung die Beliebtheit ausführt, ermöglicht es uns auch, mit verschiedenen effizienten Inferenzservern kompatibel zu sein. Für den durchschnittlichen Benutzer überwiegen die Vorteile die Nachteile.
Wir verwenden Ollama als Beispiel, um zu erklären, wie Sie Unterstützung für solche Dienste hinzufügen. Zunächst müssen wir Litellm verwenden, um die Schnittstelle von Ollama in ein mit OpenAI kompatibeler Format umzuwandeln.
pip install litellm
ollama pull mistral-openorca
litellm --model ollama/mistral-openorca --api_base http://localhost:11434 --temperature 0.0 --max_tokens 8192Fügen Sie dann Unterstützung für diesen Dienst in der Datei config.json hinzu (der Speicherort dieser Datei wird aufgefordert, wenn die Strichung gestartet wird).
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"ollama" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fake-key " ,
"baseURL" : " http://localhost:8000 " ,
"modelList" : {
"mistral-openorca" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 8192 ,
"systemAsUser" : false ,
"args" : {}
}
}
},
...
},
...
}Jetzt können wir Streben führen:
ailice_web --modelID=ollama:mistral-openorcaIn diesem Beispiel werden wir LM Studio verwenden, um das open-Source-Modell auszuführen, das ich je gesehen habe: QWEN2-72B-ISTRUCT-q3_K_S.GGUF , und die Striche auf einer lokalen Maschine ausführen.
Download Modellgewichte von QWEN2-72B-Instruct-Q3_K_S.GGUF mit LM Studio.
Setzen Sie im Fenster "Localerver" des LM Studios N_GPU_Layers auf -1, wenn Sie nur GPU verwenden möchten. Passen Sie den Parameter „Kontextlänge“ links auf 16384 (oder einen kleineren Wert basierend auf Ihrem verfügbaren Speicher) an und ändern Sie die "Kontextüberlauf -Richtlinie", um die Systemaufforderung und die erste Benutzernachricht zu behalten, abschneidern Mitte ".
Den Service ausführen. Wir gehen davon aus, dass die Adresse des Dienstes "http: // localhost: 1234/v1/" lautet.
Dann öffnen wir config.json und stellen die folgenden Änderungen vor:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"qwen2-72b" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 32764 ,
"systemAsUser" : true ,
"args" : {}
}
}
},
...
},
...
}Schließlich leiten Sie die Streben. Sie können den Parameter "Contextwindowratio" basierend auf Ihrem verfügbaren VRAM oder Speicherplatz anpassen. Je größer der Parameter ist, desto mehr VRAM -Raum ist erforderlich.
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5Ähnlich wie im vorherigen Abschnitt haben wir nach dem Herunterladen und Ausführen von LLAVA LM Studio die Konfigurationsdatei wie folgt geändert:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"llava-1.6-34b" : {
"formatter" : " AFormatterGPTVision " ,
"contextWindow" : 4096 ,
"systemAsUser" : true ,
"args" : {}
}
},
},
...
},
...
}Es ist jedoch zu beachten, dass das aktuelle Open-Source-Multi-Modal-Modell bei weitem nicht ausreicht, um Agentenaufgaben auszuführen. Dieses Beispiel ist also eher für Entwickler als für Benutzer.
Für Open -Source -Modelle für das Huggingface müssen Sie nur die folgenden Informationen kennen, um neue Modelle zu unterstützen: die Abmeldungsadresse des Modells, das Eingabeaufforderungformat des Modells und die Kontextfensterlänge. Normalerweise reicht eine Codezeile aus, um ein neues Modell hinzuzufügen, aber gelegentlich haben Sie Pech und Sie benötigen ungefähr ein Dutzend Codezeilen.
Hier ist die vollständige Methode zum Hinzufügen einer neuen LLM -Unterstützung:
Open config.json, Sie sollten die Konfiguration neuer LLM in Models.hf.Modellist hinzufügen, das wie folgt aussieht:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"hf" : {
"modelWrapper" : " AModelCausalLM " ,
"modelList" : {
"meta-llama/Llama-2-13b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
"meta-llama/Llama-2-70b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
...
}
},
...
}
...
}"Formatierer" ist eine Klasse, die das Eingabeaufforderungformat von LLM definiert. Sie können ihre Definitionen in Core/LLM/Aformatter finden. Sie können diese Codes lesen, um festzustellen, welches Format für das Modell erforderlich ist, das Sie hinzufügen möchten. Falls Sie es nicht finden, müssen Sie selbst eine schreiben. Glücklicherweise ist Formatatter eine sehr einfache Sache und kann in mehr als einem Dutzend Codezeilen abgeschlossen werden. Ich glaube, Sie werden verstehen, wie man es macht, nachdem Sie ein paar Formatter -Quellcodes gelesen haben.
Das Kontextfenster ist eine Eigenschaft, die die LLM der Transformatorarchitektur normalerweise hat. Es bestimmt die Textlänge, die das Modell gleichzeitig verarbeiten kann. Sie müssen das Kontextfenster des neuen Modells auf den Schlüssel "Contextwindow" festlegen.
"Systemasuser": Wir verwenden die "System" -Rolle als Absender der Nachricht, die von den Funktionsaufrufen zurückgegeben wird. Allerdings haben nicht alle LLMs eine klare Definition der Systemrolle, und es gibt keine Garantie dafür, dass sich das LLM an diesen Ansatz anpassen kann. Daher müssen wir Systemasuser verwenden, um festzustellen, ob der von den Funktionsaufrufen zurückgegebene Text in Benutzernachrichten eingestellt werden soll. Versuchen Sie, es zuerst auf false zu setzen.
Alles ist fertig! Verwenden Sie "HF:" als Präfix für den Modellnamen, um eine ModellID zu bilden, und verwenden Sie die ModellID des neuen Modells als Befehlsparameter, um die Belüftung zu starten!
Die Streben haben zwei Betriebsmodi. In einem Modus wird ein einzelnes LLM verwendet, um alle Agenten zu treiben, während der andere mit jedem Agententyp eine entsprechende LLM angeben kann. Der letztere Modus ermöglicht es uns, die Fähigkeiten von Open-Source-Modellen und kommerziellen Modellen besser zu kombinieren und eine bessere Leistung zu geringeren Kosten zu erzielen. Um den zweiten Modus zu verwenden, müssen Sie das AgentModelConfig -Element zuerst in config.json konfigurieren:
"modelID" : " " ,
"agentModelConfig" : {
"DEFAULT" : " openrouter:qwen/qwen-2-72b-instruct " ,
"coder" : " openrouter:deepseek/deepseek-coder "
},Stellen Sie zunächst sicher, dass der Standardwert für ModellID auf eine leere Zeichenfolge eingestellt ist, und konfigurieren Sie dann den entsprechenden LLM für jeden Agententyp in AgentModelConfig.
Schließlich können Sie den zweiten Betriebsmodus erreichen, indem Sie keine ModellID angeben:
ailice_webDie Grundprinzipien beim Entwerfen von Streben sind:
Lassen Sie uns diese grundlegenden Prinzipien kurz erklären.
Ausgehend von der offensichtlichsten Ebene ist eine hochdynamische Eingabeaufforderung weniger wahrscheinlich, dass ein Agent in eine Schleife fällt. Der Zustrom neuer Variablen aus der externen Umgebung wirkt sich kontinuierlich auf die LLM aus und hilft ihm, diese Gefahr zu vermeiden. Darüber hinaus kann die Fütterung des LLM mit allen derzeit verfügbaren Informationen die Ausgabe erheblich verbessern. For example, in automated programming, error messages from interpreters or command lines assist the LLM in continuously modifying the code until the correct result is achieved. Lastly, in dynamic prompt construction, new information in the prompts may also come from other agents, which acts as a form of linked inference computation, making the system's computational mechanisms more complex, varied, and capable of producing richer behaviors.
Separating computational tasks is, from a practical standpoint, due to our limited context window. We cannot expect to complete a complex task within a window of a few thousand tokens. If we can decompose a complex task so that each subtask is solved within limited resources, that would be an ideal outcome. In traditional computing models, we have always taken advantage of this, but in new computing centered around LLMs, this is not easy to achieve. The issue is that if one subtask fails, the entire task is at risk of failure. Recursion is even more challenging: how do you ensure that with each call, the LLM solves a part of the subproblem rather than passing the entire burden to the next level of the call? We have solved the first problem with the IACT architecture in Ailice, and the second problem is theoretically not difficult to solve, but it likely requires a smarter LLM.
The third principle is what everyone is currently working on: having multiple intelligent agents interact and cooperate to complete more complex tasks. The implementation of this principle actually addresses the aforementioned issue of subtask failure. Multi-agent collaboration is crucial for the fault tolerance of agents in operation. In fact, this may be one of the biggest differences between the new computational paradigm and traditional computing: traditional computing is precise and error-free, assigning subtasks only through unidirectional communication (function calls), whereas the new computational paradigm is error-prone and requires bidirectional communication between computing units to correct errors. This will be explained in detail in the following section on the IACT framework.
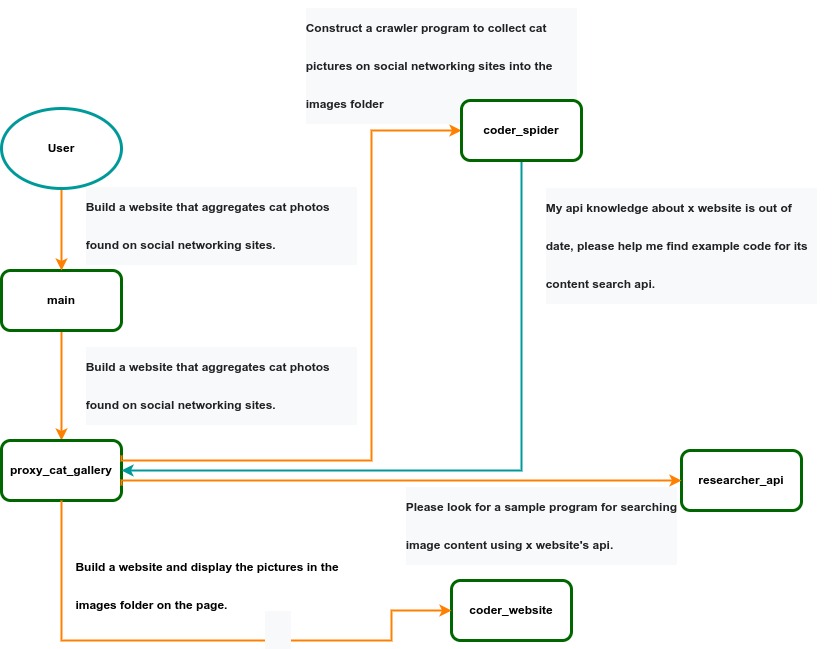 IACT Architecture Diagram. A user requirement to build a page for image collection and display is dynamically decomposed into two tasks: coder_spider and coder_website. When coder_spider encounters difficulties, it proactively seeks assistance from its caller, proxy_cat_gallery. Proxy_cat_gallery then creates another agent, researcher_api, and employs it to address the issue.
IACT Architecture Diagram. A user requirement to build a page for image collection and display is dynamically decomposed into two tasks: coder_spider and coder_website. When coder_spider encounters difficulties, it proactively seeks assistance from its caller, proxy_cat_gallery. Proxy_cat_gallery then creates another agent, researcher_api, and employs it to address the issue.
Ailice can be regarded as a computer powered by a LLM , and its features include:
Representing input, output, programs, and data in text form.
Using LLM as the processor.
Breaking down computational tasks through successive calls to basic computing units (analogous to functions in traditional computing), which are essentially various functional agents.
Therefore, user-input text commands are executed as a kind of program, decomposed into various "subprograms", and addressed by different agents , forming the fundamental architecture of Ailice. In the following, we will provide a detailed explanation of the nature of these basic computing units.
A natural idea is to let LLM solve certain problems (such as information retrieval, document understanding, etc.) through multi-round dialogues with external callers and peripheral modules in the simplest computational unit. We temporarily call this computational unit a "function". Then, by analogy with traditional computing, we allow functions to call each other, and finally add the concept of threads to implement multi-agent interaction. However, we can have a much simpler and more elegant computational model than this.
The key here is that the "function" that wraps LLM reasoning can actually be called and returned multiple times. A "function" with coder functionality can pause work and return a query statement to its caller when it encounters unclear requirements during coding. If the caller is still unclear about the answer, it continues to ask the next higher level caller. This process can even go all the way to the final user's chat window. When new information is added, the caller will reactivate the coder's execution process by passing in the supplementary information. It can be seen that this "function" is not a traditional function, but an object that can be called multiple times. The high intelligence of LLM makes this interesting property possible. You can also see it as agents strung together by calling relationships, where each agent can create and call more sub-agents, and can also dialogue with its caller to obtain supplementary information or report its progress . In Ailice, we call this computational unit "AProcessor" (essentially what we referred to as an agent). Its code is located in core/AProcessor.py.
Next, we will elaborate on the structure inside AProcessor. The interior of AProcessor is a multi-round dialogue. The "program" that defines the function of AProcessor is a prompt generation mechanism, which generates the prompt for each round of dialogue from the dialogue history. The dialogue is one-to-many. After the external caller inputs the request, LLM will have multiple rounds of dialogue with the peripheral modules (we call them SYSTEM), LLM outputs function calls in various grammatical forms, and the system calls the peripheral modules to generate results and puts the results in the reply message. LLM finally gets the answer and responds to the external caller, ending this call. But because the dialogue history is still preserved, the caller can call in again to continue executing more tasks.
The last part we want to introduce is the parsing module for LLM output. In fact, we regard the output text of LLM as a "script" of semi-natural language and semi-formal language, and use a simple interpreter to execute it . We can use regular expressions to express a carefully designed grammatical structure, parse it into a function call and execute it. Under this design, we can design more flexible function call grammar forms, such as a section with a certain fixed title (such as "UPDATE MEMORY"), which can also be directly parsed out and trigger the execution of an action. This implicit function call does not need to make LLM aware of its existence, but only needs to make it strictly follow a certain format convention. For the most hardcore possibility, we have left room. The interpreter here can not only use regular expressions for pattern matching, its Eval function is recursive. We don't know what this will be used for, but it seems not bad to leave a cool possibility, right? Therefore, inside AProcessor, the calculation is alternately completed by LLM and the interpreter, their outputs are each other's inputs, forming a cycle.
In Ailice, the interpreter is one of the most crucial components within an agent. We use the interpreter to map texts from the LLM output that match specific patterns to actions, including function calls, variable definitions and references, and any user-defined actions. Sometimes these actions directly interact with peripheral modules, affecting the external world; other times, they are used to modify the agent's internal state, thereby influencing its future prompts.
The basic structure of the interpreter is straightforward: a list of pattern-action pairs. Patterns are defined by regular expressions, and actions are specified by a Python function with type annotations. Given that syntactic structures can be nested, we refer to the overarching structure as the entry pattern. During runtime, the interpreter actively detects these entry patterns in the LLM output text. Upon detecting an entry pattern (and if the corresponding action returns data), it immediately terminates the LLM generation to execute the relevant action.
The design of agents in Ailice encompasses two fundamental aspects: the logic for generating prompts based on dialogue history and the agent's internal state, and a set of pattern-action pairs. Essentially, the agent implements the interpreter framework with a set of pattern-action pairs; it becomes an integral part of the interpreter. The agent's internal state is one of the targets for the interpreter's actions, with changes to the agent's internal state influencing the direction of future prompts.
Generating prompts from dialogue history and the internal state is nearly a standardized process, although developers still have the freedom to choose entirely different generation logic. The primary challenge for developers is to create a system prompt template, which is pivotal for the agent and often demands the most effort to perfect. However, this task revolves entirely around crafting natural language prompts.
Ailice utilizes a simple scripting language embedded within text to map the text-based capabilities of LLMs to the real world. This straightforward scripting language includes non-nested function calls and mechanisms for creating and referencing variables, as well as operations for concatenating text content . Its purpose is to enable LLMs to exert influence on the world more naturally: from smoother text manipulation abilities to simple function invocation mechanisms, and multimodal variable operation capabilities. Finally, it should be noted that for the designers of agents, they always have the freedom to extend new syntax for this scripting language. What is introduced here is a minimal standard syntax structure.
The basic syntax is as follows:
Variable Definition: VAR_NAME := <!|"SOME_CONTENT"|!>
Function Calls/Variable References/Text Concatenation: !FUNC-NAME<!|"...", '...', VAR_NAME1, "Execute the following code: n" + VAR_NAME2, ...|!>
The basic variable types are str/AImage/various multimodal types. The str type is consistent with Python's string syntax, supporting triple quotes and escape characters.
This constitutes the entirety of the embedded scripting language.
The variable definition mechanism introduces a way to extend the context window, allowing LLMs to record important content into variables to prevent forgetting. During system operation, various variables are automatically defined. For example, if a block of code wrapped in triple backticks is detected within a text message, a variable is automatically created to store the code, enabling the LLM to reference the variable to execute the code, thus avoiding the time and token costs associated with copying the code in full. Furthermore, some module functions may return data in multimodal types rather than text. In such cases, the system automatically defines these as variables of the corresponding multimodal type, allowing the LLM to reference them (the LLM might send them to another module for processing).
In the long run, LLMs are bound to evolve into multimodal models capable of seeing and hearing. Therefore, the exchanges between Ailice's agents should be in rich text , not just plain text. While Markdown provides some capability for marking up multimodal content, it is insufficient. Hence, we will need an extended version of Markdown in the future to include various embedded multimodal data such as videos and audio.
Let's take images as an example to illustrate the multimodal mechanism in Ailice. When agents receive text containing Markdown-marked images, the system automatically inputs them into a multimodal model to ensure the model can see these contents. Markdown typically uses paths or URLs for marking, so we have expanded the Markdown syntax to allow the use of variable names to reference multimodal content.
Another minor issue is how different agents with their own internal variable lists exchange multimodal variables. This is simple: the system automatically checks whether a message sent from one agent to another contains internal variable names. If it does, the variable content is passed along to the next agent.
Why do we go to the trouble of implementing an additional multimodal variable mechanism when marking multimodal content with paths and URLs is much more convenient? This is because marking multimodal content based on local file paths is only feasible when Ailice runs entirely in a local environment, which is not the design intent. Ailice is meant to be distributed, with the core and modules potentially running on different computers, and it might even load services running on the internet to provide certain computations. This makes returning complete multimodal data more attractive. Of course, these designs made for the future might be over-engineering, and if so, we will modify them in the future.
One of the goals of Ailice is to achieve introspection and self-expansion (which is why our logo features a butterfly with its reflection in the water). This would enable her to understand her own code and build new functionalities, including new external interaction modules (ie new functions) and new types of agents (APrompt class) . As a result, the knowledge and capabilities of LLMs would be more thoroughly unleashed.
Implementing self-expansion involves two parts. On one hand, new modules and new types of agents (APrompt class) need to be dynamically loaded during runtime and naturally integrated into the computational system to participate in processing, which we refer to as dynamic loading. On the other hand, Ailice needs the ability to construct new modules and agent types.
The dynamic loading mechanism itself is of great significance: it represents a novel software update mechanism . We can allow Ailice to search for its own extension code on the internet, check the code for security, fix bugs and compatibility issues, and ultimately run the extension as part of itself. Therefore, Ailice developers only need to place their contributed code on the internet, without the need to merge into the main codebase or consider any other installation methods. The implementation of the dynamic loading mechanism is continuously improving. Its core lies in the extension packages providing some text describing their functions. During runtime, each agent in Ailice finds suitable functions or agent types to solve sub-problems for itself through semantic matching and other means.
Building new modules is a relatively simple task, as the interface constraints that modules need to meet are very straightforward. We can teach LLMs to construct new modules through an example. The more complex task is the self-construction of new agent types (APrompt class), which requires a good understanding of Ailice's overall architecture. The construction of system prompts is particularly delicate and is a challenging task even for humans. Therefore, we pin our hopes on more powerful LLMs in the future to achieve introspection, allowing Ailice to understand herself by reading her own source code (for something as complex as a program, the best way to introduce it is to present itself), thereby constructing better new agents .
For developing Agents, the main loop of Ailice is located in the AiliceMain.py or ui/app.py files. To further understand the construction of an agent, you need to read the code in the "prompts" folder, by reading these code you can understand how an agent's prompts are dynamically constructed.
For developers who want to understand the internal operation logic of Ailice, please read core/AProcessor.py and core/Interpreter.py. These two files contain approximately three hundred lines of code in total, but they contain the basic framework of Ailice.
In this project, achieving the desired functionality of the AI Agent is the primary goal. The secondary goal is code clarity and simplicity . The implementation of the AI Agent is still an exploratory topic, so we aim to minimize rigid components in the software (such as architecture/interfaces imposing constraints on future development) and provide maximum flexibility for the application layer (eg, prompt classes) . Abstraction, deduplication, and decoupling are not immediate priorities.
When implementing a feature, always choose the best method rather than the most obvious one . The metric for "best" often includes traits such as trivializing the problem from a higher perspective, maintaining code clarity and simplicity, and ensuring that changes do not significantly increase overall complexity or limit the software's future possibilities.
Adding comments is not mandatory unless absolutely necessary; strive to make the code clear enough to be self-explanatory . While this may not be an issue for developers who appreciate comments, in the AI era, we can generate detailed code explanations at any time, eliminating the need for unstructured, hard-to-maintain comments.
Follow the principle of Occam's razor when adding code; never add unnecessary lines .
Functions or methods in the core should not exceed 60 lines .
While there are no explicit coding style constraints, maintain consistency or similarity with the original code in terms of naming and case usage to avoid readability burdens.
Ailice aims to achieve multimodal and self-expanding features within a scale of less than 5000 lines, reaching its final form at the current stage. The pursuit of concise code is not only because succinct code often represents a better implementation, but also because it enables AI to develop introspective capabilities early on and facilitates better self-expansion. Please adhere to the above rules and approach each line of code with diligence.
Ailice's fundamental tasks are twofold: one is to fully unleash the capabilities of LLM based on text into the real world; the other is to explore better mechanisms for long-term memory and forming a coherent understanding of vast amounts of text . Our development efforts revolve around these two focal points.
If you are interested in the development of Ailice itself, you may consider the following directions:
Explore improved long-term memory mechanisms to enhance the capabilities of each Agent. We need a long-term memory mechanism that enables consistent understanding of large amounts of content and facilitates association . The most feasible option at the moment is to replace vector database with knowledge graph, which will greatly benefit the comprehension of long texts/codes and enable us to build genuine personal AI assistants.
Multimodal support. The support for the multimodal model has been completed, and the current development focus is shifting towards the multimodal support of peripheral modules. We need a module that operates computers based on screenshots and simulates mouse/keyboard actions.
Self-expanding support. Our goal is to enable language models to autonomously code and implement new peripheral modules/agent types and dynamically load them for immediate use . This capability will enable self-expansion, empowering the system to seamlessly integrate new functionalities. We've completed most of the functionality, but we still need to develop the capability to construct new types of agents.
Richer UI interface . We need to organize the agents output into a tree structure in dialog window and dynamically update the output of all agents. And accept user input on the web interface and transfer it to scripter's standard input, which is especially needed when using sudo.
Develop Agents with various functionalities based on the current framework.
Explore the application of IACT architecture on complex tasks. By utilizing an interactive agents call tree, we can break down large documents for improved reading comprehension, as well as decompose complex software engineering tasks into smaller modules, completing the entire project build and testing through iterations. This requires a series of intricate prompt designs and testing efforts, but it holds an exciting promise for the future. The IACT architecture significantly alleviates the resource constraints imposed by the context window, allowing us to dynamically adapt to more intricate tasks.
Build rich external interaction modules using self-expansion mechanisms! This will be accomplished in AiliceEVO.
In addition to the tasks mentioned above, we should also start actively contemplating the possibility of creating a smaller LLM that possesses lower knowledge content but higher reasoning abilities .


