AIlice
1.0.0

Démarrage rapide • Demo • Développement • Twitter • Reddit
22 juin 2024: Nous sommes entrés dans l'ère des assistants AI de type Jarvis en cours d'exécution! Les derniers LLMS open-source nous permettent d'effectuer des tâches complexes localement! Cliquez ici pour en savoir plus.
Ailice est un agent d'IA à usage général entièrement autonome . Ce projet vise à créer un assistant d'intelligence artificielle autonome, similaire à Jarvis, basé sur le LLM open-source. Ailice atteint cet objectif en construisant un "ordinateur de texte" qui utilise un modèle grand langage (LLM) comme processeur de base. Actuellement, Ailice démontre une compétence dans une gamme de tâches, notamment la recherche thématique, le codage, la gestion du système, les revues de littérature et les tâches hybrides complexes qui vont au-delà de ces capacités de base.
Ailice a atteint des performances presque parfaites dans les tâches quotidiennes à l'aide de GPT-4 et fait des progrès vers une application pratique avec les derniers modèles open source.
Nous allons finalement réaliser l'auto-évolution des agents de l'IA . C'est-à-dire que les agents de l'IA construisent de manière autonome leurs propres extensions de fonctionnalités et de nouveaux types d'agents, libérant les connaissances et les capacités de raisonnement de LLM dans le monde réel de manière transparente.
Pour comprendre les capacités actuelles d'Ailice, regardez les vidéos suivantes:
Les principales caractéristiques techniques de l'alice comprennent:
Installez et exécutez un ailice avec les commandes suivantes. Une fois le lancement de l'analyse, utilisez un navigateur pour ouvrir la page Web qu'il fournit, une interface de dialogue apparaîtra. Fixez des commandes à AILIPE à travers la conversation pour accomplir diverses tâches. Pour votre première utilisation, vous pouvez essayer les commandes fournies dans la section Cool Things que nous pouvons faire pour vous familiariser rapidement.
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2Énumérons certains cas d'utilisation typiques. J'utilise fréquemment ces exemples pour tester l'alice pendant le développement, assurant des performances stables. Cependant, même avec ces tests, les résultats de l'exécution sont influencés par le modèle choisi, la version de code et même le temps de test. (GPT-4 peut subir une diminution des performances sous des charges élevées. Certains facteurs aléatoires peuvent également conduire à des résultats différents de l'exécution du modèle plusieurs fois. Parfois, le LLM fonctionne très intelligemment, mais d'autres fois, ce n'est pas le cas) en outre, Ailice est un agent Sur la base de la coopération multi-agents et en tant qu'utilisateur, vous êtes également l'un des "agents". Par conséquent, lorsque l'Ailice nécessite des informations supplémentaires, elle demandera les commentaires de votre part et la minutie de vos coordonnées est cruciale pour son succès. De plus, si l'exécution de la tâche échoue, vous pouvez la guider dans la bonne direction et qu'elle rectifiera son approche.
Le dernier point à noter est que l'Ailice n'a actuellement pas de mécanisme de contrôle du temps d'exécution, donc elle pourrait rester coincée dans une boucle ou fonctionner pendant une période prolongée. Lorsque vous utilisez un LLM commercial, vous devez surveiller de près ses opérations.
"Veuillez énumérer le contenu du répertoire actuel."
"Trouvez les notes de conférence QFT de David Tong et téléchargez-les dans le dossier" Physics "dans le répertoire actuel. Vous devrez peut-être d'abord créer le dossier."
"Déployez un site Web simple sur cette machine à l'aide du framework Flask. Assurer l'accessibilité à 0.0.0.0:59001. Le site Web devrait avoir une seule page capable d'afficher toutes les images situées dans le répertoire 'Images'." Celui-ci est particulièrement intéressant. Nous savons que le dessin ne peut pas être fait dans l'environnement Docker, et toutes les sorties de fichier que nous générons doivent être copiées à l'aide de la commande "Docker CP" pour le voir. Mais vous pouvez laisser l'alice résoudre ce problème par lui-même: déployez un site Web dans le conteneur en fonction de l'invite ci-dessus (il est recommandé d'utiliser des ports entre 59001 et 59200 qui ont été mappés de port), les images du répertoire seront automatiquement affichées sur la page Web. De cette façon, vous pouvez voir dynamiquement le contenu d'image généré sur l'hôte. Vous pouvez également essayer de la laisser itérer pour produire des fonctions plus complexes. Si vous ne voyez aucune image sur la page, veuillez vérifier si le dossier "Images" du site Web est différent du dossier "Images" ici (par exemple, il pourrait être sous "statique / images").
"Veuillez utiliser la programmation Python pour résoudre les tâches suivantes: Obtenez les données de prix de BTC-USDT pendant six mois et dessinez-la dans un graphique, et enregistrez-la dans le répertoire 'Images'." Si vous avez déployé avec succès le site Web ci-dessus, vous pouvez désormais voir la courbe de prix BTC directement sur la page.
"Trouvez le processus sur le port 59001 et terminez-le." Cela mettra fin au programme de services de site Web qui vient d'être établi.
"Veuillez utiliser CadQuery pour mettre en œuvre une tasse." C'est aussi une tentative très intéressante. CadQuery est un package Python qui utilise la programmation Python pour la modélisation CAO. Nous essayons d'utiliser une ailice pour créer automatiquement des modèles 3D! Cela peut nous donner un aperçu de la façon dont l'intuition géométrique peut être mature dans la vision du monde de LLM. Bien sûr, après avoir mis en œuvre un support multimodal, nous pouvons permettre à Ailice de voir les modèles qu'elle crée, permettant de nouveaux ajustements et établissant une boucle de rétroaction très efficace. De cette façon, il pourrait être possible d'obtenir une modélisation 3D contrôlée par le langage vraiment utilisable.
"Veuillez rechercher sur Internet 100 tutoriels dans diverses branches de la physique et télécharger les fichiers PDF que vous trouvez dans un dossier nommé« Physique ». Il n'est pas nécessaire de vérifier le contenu des PDF, nous n'avons besoin que d'une collection approximative pour l'instant." L'utilisation de l'Ailice pour réaliser la collecte et la construction des ensembles de données automatiques est l'un de nos objectifs en cours. Actuellement, le chercheur employé pour cette fonctionnalité a encore des lacunes, mais il est déjà capable de fournir des résultats intrigants.
"Veuillez mener une enquête sur les outils PDF open source, en mettant l'accent sur ceux capables de reconnaître les formules mathématiques et de les convertir en code de latex. Consolider les résultats en rapport."
1. Trouvez la vidéo des conférences de Feynmann sur YouTube et téléchargez-les sur Feynmann / Subdir. Vous devez d'abord créer le dossier. 2. Extraire l'audio de ces vidéos et les enregistrer sur Feynmann / Audio. 3. Convertissez ces fichiers audio en texte et fusionnez-les en document texte. Vous devez d'abord aller à l'étreinte Face et trouver la page pour Whisper-Large-V3, localiser l'exemple de code et consulter l'exemple de code pour le faire. 4. Trouvez la réponse à cette question à partir des fichiers texte que vous venez d'extraire: pourquoi avons-nous besoin d'antiparticules? Il s'agit d'une tâche invite en plusieurs étapes où vous devez interagir avec l'analyse étape par étape pour terminer la tâche. Naturellement, il peut y avoir des événements inattendus en cours de route, vous devrez donc maintenir une bonne communication avec un ailice pour résoudre tous les problèmes que vous rencontrez ( en utilisant le bouton "Interrompre" pour interrompre l'allice à tout moment et donner une invite est une bonne option! ). Enfin, sur la base du contenu de la vidéo téléchargée, vous pouvez poser une question liée à l'Ailice une question liée à la physique. Une fois que vous avez reçu la réponse, vous pouvez regarder en arrière et voir jusqu'où vous vous êtes réunis.
1. Utilisez SDXL pour générer une image de "A Fat Orange Cat". Vous devez trouver l'exemple de code sur sa page HuggingFace comme référence pour terminer le travail de programmation et de génération d'images. Enregistrez l'image dans le répertoire actuel et affichez-le. 2. Maintenant, implémentons un site Web d'une seule page. La fonction de la page Web est de convertir la description du texte entrée par l'utilisateur en une image et de l'afficher. Reportez-vous au code du texte à l'image d'avant. Le site Web fonctionne sur 127.0.0.1:59102. Enregistrez le code sur ./image_gen avant de l'exécuter; Vous devrez peut-être d'abord créer le dossier.
"Veuillez écrire un extrémité extraordinaire. La fonction du module est d'obtenir le contenu des pages connexes sur le wiki via des mots clés." Ailice peut construire des modules d'interaction externes (nous l'appelons des modules extrémistes) par elle-même, lui donnant ainsi une extensibilité illimitée. Tout ce qu'il faut, ce sont quelques invites de vous. Une fois le module construit, vous pouvez instruire l'alilice en disant: "Veuillez charger le module wiki nouvellement implémenté et l'utiliser pour interroger l'entrée sur la relativité."
Les agents doivent interagir avec divers aspects de l'environnement environnant, leur environnement de fonctionnement est souvent plus complexe que les logiciels typiques. Il peut nous prendre beaucoup de temps pour installer les dépendances, mais heureusement, cela se fait automatiquement.
Pour exécuter une ailice, vous devez vous assurer que le chrome est correctement installé. Si vous devez exécuter du code dans un environnement virtuel sécurisé, vous devez également installer Docker .
Si vous souhaitez exécuter une ailice dans une machine virtuelle, assurez-vous que Hyper-V est désactivé (sinon LLAMA.CPP ne peut pas être installé). Dans un environnement VirtualBox, vous pouvez le désactiver en suivant ces étapes: Désactiver PAE / NX et VT-X / AMD-V (Hyper-V) sur les paramètres VirtualBox pour la machine virtuelle. Définissez l'interface de paravirtualisation par défaut, désactivez la pagination imbriquée.
Vous pouvez utiliser la commande suivante pour installer une ailice (il est fortement recommandé d'utiliser des outils tels que Conda pour créer un nouvel environnement virtuel pour installer une ailice, afin d'éviter les conflits de dépendance):
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .L'Ailice installée par défaut s'exécutera lentement car il utilise le CPU comme matériel d'inférence du module de mémoire à long terme. Par conséquent, il est fortement recommandé d'installer le support d'accélération du GPU:
ailice_turboPour les utilisateurs qui ont besoin d'utiliser les fonctions HuggingFace Modèles / Dialogue vocale / modélisation des fonctions de réglage fin / PDF, vous pouvez utiliser l'une des commandes suivantes (l'installation de trop de fonctionnalités augmente la probabilité de conflits de dépendance, il est donc recommandé d'installer uniquement le parties nécessaires):
pip install -e .[huggingface]
pip install -e .[speech]
pip install -e .[finetuning]
pip install -e .[pdf-reading]Vous pouvez courir l'allice maintenant! Utilisez les commandes en usage.
Par défaut, le module Google dans AILICE est restreint et l'utilisation répétée peut entraîner des erreurs nécessitant un certain temps pour résoudre. C'est une réalité maladroite à l'ère AI; Les moteurs de recherche traditionnels permettent uniquement d'accès aux utilisateurs authentiques, et les agents de l'IA ne font actuellement pas partie de la catégorie des «utilisateurs authentiques». Bien que nous ayons des solutions alternatives, elles nécessitent toutes la configuration d'une clé API, ce qui définit une barrière élevée pour l'entrée pour les utilisateurs ordinaires. Cependant, pour les utilisateurs qui ont besoin d'un accès fréquent à Google, je suppose que vous seriez prêt à supporter les tracas de la demande de la clé API officielle d'une L'heure de la création) pour les tâches de recherche. Pour ces utilisateurs, veuillez ouvrir config.json et utiliser la configuration suivante:
{
...
"services": {
...
"google": {
"cmd": "python3 -m ailice.modules.AGoogleAPI --addr=ipc:///tmp/AGoogle.ipc --api_key=YOUR_API_KEY --cse_id=YOUR_CSE_ID",
"addr": "ipc:///tmp/AGoogle.ipc"
},
...
}
}
et installer google-api-python-client:
pip install google-api-python-clientEnsuite, redémarrez simplement l'allice.
Par défaut, l'exécution du code utilise l'environnement local. Pour éviter les erreurs d'IA potentielles conduisant à des pertes irréversibles, il est recommandé d'installer Docker, de créer un conteneur et de modifier le fichier de configuration de l'Ailice (Ailice fournira l'emplacement du fichier de configuration au démarrage). Configurez son module d'exécution de code (ASCRIPTER) pour fonctionner dans un environnement virtuel.
docker build -t env4scripter .
docker run -d -p 127.0.0.1:59000-59200:59000-59200 --name scripter env4scripterDans mon cas, lorsque l'Ailice démarre, cela m'informe que le fichier de configuration est situé à ~ / .config / ailice / config.json, donc je le modifie de la manière suivante
nano ~ /.config/ailice/config.jsonModifier "Scripteur" sous "Services":
{
...
"services": {
...
"scripter": {"cmd": "docker start scripter",
"addr": "tcp://127.0.0.1:59000"},
}
}
Maintenant que la configuration de l'environnement a été effectuée.
En raison de l'état de développement continu de l'analyse, la mise à jour du code peut entraîner des problèmes d'incompatibilité entre le fichier de configuration existant et le conteneur Docker avec le nouveau code. La solution la plus approfondie pour ce scénario consiste à supprimer le fichier de configuration (en s'assurant d'enregistrer les touches API au préalable) et le conteneur, puis à effectuer une réinstallation complète. Cependant, pour la plupart des situations, vous pouvez résoudre le problème en supprimant simplement le fichier de configuration et en mettant à jour le module de l'alice dans le conteneur .
rm ~ /.config/ailice/config.json
cd Ailice
docker cp ailice/__init__.py scripter:scripter/ailice/__init__.py
docker cp ailice/common/__init__.py scripter:scripter/ailice/common/__init__.py
docker cp ailice/common/ADataType.py scripter:scripter/ailice/common/ADataType.py
docker cp ailice/common/lightRPC.py scripter:scripter/ailice/common/lightRPC.py
docker cp ailice/modules/__init__.py scripter:scripter/ailice/modules/__init__.py
docker cp ailice/modules/AScripter.py scripter:scripter/ailice/modules/AScripter.py
docker cp ailice/modules/AScrollablePage.py scripter:scripter/ailice/modules/AScrollablePage.py
docker restart scripterVous pouvez copier directement une commande à partir des cas d'utilisation typiques ci-dessous pour exécuter une ailice.
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2
ailice_web --modelID=anthropic:claude-3-5-sonnet-20240620 --contextWindowRatio=0.1
ailice_web --modelID=oai:gpt-4-1106-preview --chatHistoryPath=./chat_history
ailice_web --modelID=anthropic:claude-3-opus-20240229 --prompt= " researcher "
ailice_web --modelID=mistral:mistral-large-latest
ailice_web --modelID=deepseek:deepseek-chat
ailice_web --modelID=hf:Open-Orca/Mistral-7B-OpenOrca --quantization=8bit --contextWindowRatio=0.6
ailice_web --modelID=hf:NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO --quantization=4bit --contextWindowRatio=0.3
ailice_web --modelID=hf:Phind/Phind-CodeLlama-34B-v2 --prompt= " coder-proxy " --quantization=4bit --contextWindowRatio=0.6
ailice_web --modelID=groq:llama3-70b-8192
ailice_web # Use models configured individually for different agents under the agentModelConfig field in config.json.
ailice_web --modelID=openrouter:openrouter/auto
ailice_web --modelID=openrouter:mistralai/mixtral-8x22b-instruct
ailice_web --modelID=openrouter:qwen/qwen-2-72b-instruct
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5Il convient de noter que le dernier cas d'utilisation vous oblige à configurer d'abord le service d'inférence LLM, veuillez vous référer à la façon d'ajouter la prise en charge de LLM. L'utilisation de cadres d'inférence tels que LM Studio peut utiliser des ressources matérielles limitées pour prendre en charge les modèles plus importants, offrir une vitesse d'inférence plus rapide et une vitesse de démarrage de l'aiili plus rapide, ce qui le rend plus adapté aux utilisateurs ordinaires.
Lorsque vous l'exécutez pour la première fois, il vous sera demandé de saisir la touche API d'Openai. Si vous souhaitez seulement utiliser Open Source LLM, vous n'avez pas besoin de l'entrer. Vous pouvez également modifier l'api-key en modifiant le fichier config.json. Veuillez noter que la première fois que lorsque vous utilisez un LLM open source, il faudra beaucoup de temps pour télécharger les poids du modèle, veuillez vous assurer d'avoir suffisamment de temps et d'espace disque.
Lorsque vous allumez l'interrupteur de discours pour la première fois, vous devrez peut-être attendre longtemps au démarrage. En effet, les poids des modèles de reconnaissance vocale et de TTS sont téléchargés en arrière-plan.
Comme le montre les exemples, vous pouvez utiliser l'agent via Ailice_Web, il fournit une interface de dialogue Web. Vous pouvez afficher la valeur par défaut de chaque paramètre en utilisant
ailice_web --helpLes valeurs par défaut pour tous les arguments de ligne de commande peuvent être personnalisées en modifiant les paramètres correspondants dans config.json.
Le fichier de configuration de Ailice est nommé config.json, et son emplacement sera sorti sur la ligne de commande au démarrage de l'Ailice. Dans cette section, nous présenterons comment configurer les modules d'interaction externes via le fichier de configuration.
Dans une autre, nous utilisons le terme "module" pour se référer spécifiquement aux composants qui fournissent des fonctions pour interagir avec le monde externe. Chaque module fonctionne comme un processus indépendant; Ils peuvent s'exécuter dans différents logiciels ou environnements matériels à partir du processus de base, ce qui rend l'alice capable d'être distribué. Nous fournissons une série de configurations de modules de base dans le fichier de configuration requis pour le fonctionnement d'Ailice (tels que la base de données vectorielle, la recherche, le navigateur, l'exécution de code, etc.). Vous pouvez également ajouter des configurations pour tous les modules tiers et fournir leur adresse d'exécution et leur port de module après l'exécution de l'Ailice pour activer le chargement automatique. La configuration du module est très simple, composée de seulement deux éléments:
"services" : {
...
"scripter" : { "cmd" : " python3 -m ailice.modules.AScripter --addr=tcp://127.0.0.1:59000 " ,
"addr" : " tcp://127.0.0.1:59000 " },
...
}Parmi ceux-ci, sous "CMD" se trouve une ligne de commande utilisée pour démarrer le processus du module. Lorsque l'Ailice démarre, il exécute automatiquement ces commandes pour lancer les modules. Les utilisateurs peuvent spécifier n'importe quelle commande, offrant une flexibilité significative. Vous pouvez démarrer le processus d'un module localement ou utiliser Docker pour démarrer un processus dans un environnement virtuel, ou même démarrer un processus distant. Certains modules ont plusieurs implémentations (tels que Google / Storage), et vous pouvez vous configurer ici pour passer à une autre implémentation.
"Addr" fait référence à l'adresse et au numéro de port du processus du module. Les utilisateurs peuvent être confus par le fait que de nombreux modules de la configuration par défaut ont à la fois "CMD" et "ADDR" contenant des adresses et des numéros de port, provoquant une redondance. En effet, "CMD" peut, en principe, contenir n'importe quelle commande (qui peut inclure des adresses et des numéros de port, ou aucune du tout). Par conséquent, un élément "ADDR" distinct est nécessaire pour informer l'alice comment accéder au processus du module.
Interruptions. Les interruptions sont le deuxième mode d'interaction pris en charge par Ailice, qui vous permet d'interrompre et de fournir des invites aux agents d'Ailice à tout moment pour corriger les erreurs ou fournir des conseils . Dans Ailice_Web, lors de l'exécution de la tâche d'Ailice, un bouton d'interruption apparaît sur le côté droit de la zone d'entrée. Appuyer sur lui, une pause de l'exécution d'Ailice et attend votre message rapide. Vous pouvez saisir votre invite dans la zone d'entrée et appuyer sur Entrée pour envoyer le message à l'agent exécutant actuellement la sous-tâche. L'utilisation compétente de cette fonctionnalité nécessite une bonne compréhension du fonctionnement de l'Ailice, en particulier de l'architecture de l'arborescence des appels d'agent. Cela implique également de se concentrer davantage sur la fenêtre de ligne de commande plutôt que sur l'interface de dialogue lors de l'exécution de la tâche d'Ailice. Dans l'ensemble, il s'agit d'une fonctionnalité très utile, en particulier sur les configurations de modèle de langue moins puissantes.
Utilisez d'abord GPT-4 pour exécuter avec succès certains cas d'utilisation simples, puis redémarrez l'once avec un modèle moins puissant (mais moins cher / open-source) pour continuer à exécuter de nouvelles tâches en fonction de l'historique de conversation précédent . De cette façon, l'histoire fournie par GPT-4 sert d'exemple réussi, offrant une référence précieuse pour d'autres modèles et augmentant considérablement les chances de succès.
Mis à jour le 23 août 2024.
Actuellement, Ailice peut gérer des tâches plus complexes en utilisant le modèle open-source Locally Run 72B (QWEN-2-72B-INSTRUCT fonctionnant sur 4090x2) , avec des performances approchant celles des modèles de niveau GPT-4. Compte tenu du faible coût des modèles open source, nous recommandons fortement aux utilisateurs de commencer à les utiliser. De plus, la localisation des opérations LLM assure une protection absolue de confidentialité, une qualité rare dans les applications d'IA à notre époque. Cliquez ici pour apprendre à exécuter ce modèle localement. Pour les utilisateurs dont les conditions GPU sont insuffisantes pour exécuter de grands modèles, ce n'est pas un problème. Vous pouvez utiliser le service d'inférence en ligne (comme OpenRouter, cela sera mentionné ensuite) pour accéder à ces modèles open source (bien que cela sacrifie la confidentialité). Bien que les modèles open-source ne puissent pas encore rivaliser entièrement pour les modèles de niveau GPT-4 commerciaux, vous pouvez faire exceller les agents en tirant parti de différents modèles en fonction de leurs forces et de leurs faiblesses. Pour plus de détails, veuillez vous référer à l'utilisation de différents modèles dans différents agents.
Claude-3-5-Sonnet-20240620 offre les meilleures performances.
GPT-4O et GPT-4-1106-Preview offrent également des performances de niveau supérieur. Mais en raison de la longue durée de l'agent et de la grande consommation de jetons, veuillez utiliser des modèles commerciaux avec prudence. GPT-4O-MINI fonctionne très bien, et bien qu'il ne soit pas de premier ordre, son prix bas rend ce modèle très attrayant. GPT-4-Turbo / GPT-3.5-Turbo est étonnamment paresseux, et nous n'avons jamais pu trouver une expression rapide stable.
Parmi les modèles open source, ceux qui fonctionnent généralement bien incluent:
Meta-Llama-3.1-405B-Istruct est agréable, mais trop grand pour être pratique sur PC.
Pour les utilisateurs dont les capacités matérielles sont insuffisantes pour exécuter des modèles open source localement et qui ne sont pas en mesure d'obtenir des clés d'API pour les modèles commerciaux, ils peuvent essayer les options suivantes:
OpenRouter Ce service peut acheminer vos demandes d'inférence vers divers modèles open source ou commerciaux sans avoir besoin de déployer des modèles open source localement ou de demander des clés API pour divers modèles commerciaux. C'est un choix fantastique. Ailice prend automatiquement en charge tous les modèles dans OpenRouter. Vous pouvez choisir Autorouter: OpenRouter / Auto pour permettre à l'autorouter d'acheter automatiquement pour vous, ou vous pouvez spécifier n'importe quel modèle spécifique configuré dans le fichier config.json. Merci @BabyBirdPrd de m'avoir recommandé OpenRouter.
GROQ: LLAMA3-70B-8192 Bien sûr, Ailice prend également en charge d'autres modèles sous GROQ. Un problème avec la course sous GROQ est qu'il est facile de dépasser les limites de taux, il ne peut donc être utilisé que pour des expériences simples.
Nous sélectionnerons le modèle open source actuellement le mieux performant pour fournir une référence aux utilisateurs de modèles open source.
Le meilleur parmi tous les modèles: QWEN-2-72B-INSTRUCT . Il s'agit du premier modèle open-source avec une valeur pratique . C'est un grand progrès! Il a des capacités de raisonnement proches de GPT-4, mais pas encore là. Avec l'intervention de l'utilisateur actif via la fonction d'interruption, de nombreuses tâches plus complexes peuvent être effectuées avec succès.
Le deuxième meilleur modèle de performance: Mixtral-8x22B-Istruct et méta-llama / méta-llama-3-70b-instruct . Il convient de noter que les modèles de la série LLAMA3 semblent présenter une baisse significative des performances après la quantification, ce qui réduit leur valeur pratique. Vous pouvez les utiliser avec du grooq.
Si vous trouvez un meilleur modèle, faites-le moi savoir.
Pour les joueurs avancés, il est inévitable d'essayer plus de modèles. Heureusement, ce n'est pas difficile à réaliser.
Pour les modèles Openai / Mistral / Anthropic / Groq, vous n'avez rien à faire. Utilisez simplement le modèle composé du nom officiel du modèle annexé sur le "oai:" / "Mistral:" / "anthropic:" / "Groq:" Prefix. Si vous devez utiliser un modèle qui n'est pas inclus dans la liste pris en charge d'Ailice, vous pouvez résoudre ce problème en ajoutant une entrée pour ce modèle dans le fichier config.json. La méthode d'ajout est de référencer directement l'entrée d'un modèle similaire, de modifier le contextwindow à la valeur réelle, de garder le SystemAsUser cohérent avec le modèle similaire et de définir des args sur un dict vide.
Vous pouvez utiliser n'importe quel serveur d'inférence tiers compatible avec l'API OpenAI pour remplacer la fonctionnalité d'inférence LLM intégrée dans Ailice. Utilisez simplement le même format de configuration que les modèles OpenAI et modifiez les paramètres de baseurl, apikey, contextwindow et autres (en fait, c'est ainsi que l'atelice prend en charge les modèles GROQ).
Pour les serveurs d'inférence qui ne prennent pas en charge l'API OpenAI, vous pouvez essayer d'utiliser Litellm pour les convertir en une API compatible OpenAI (nous avons un exemple ci-dessous).
Il est important de noter qu'en raison de la présence de nombreux messages système dans les enregistrements de conversation d'Ailice, qui n'est pas un cas d'utilisation courant pour LLM, le niveau de soutien à cela dépend de l'implémentation spécifique de ces serveurs d'inférence. Dans ce cas, vous pouvez définir le paramètre SystemAsUser sur True pour contourner le problème. Bien que cela puisse empêcher le modèle d'exécuter un ailice à ses performances optimales, cela nous permet également d'être compatibles avec divers serveurs d'inférence efficaces. Pour l'utilisateur moyen, les avantages l'emportent sur les inconvénients.
Nous utilisons Olllama comme exemple pour expliquer comment ajouter le support pour ces services. Tout d'abord, nous devons utiliser Litellm pour convertir l'interface d'Olllama en un format compatible avec OpenAI.
pip install litellm
ollama pull mistral-openorca
litellm --model ollama/mistral-openorca --api_base http://localhost:11434 --temperature 0.0 --max_tokens 8192Ensuite, ajoutez la prise en charge de ce service dans le fichier config.json (l'emplacement de ce fichier sera invité à la lancement de l'aiili).
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"ollama" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fake-key " ,
"baseURL" : " http://localhost:8000 " ,
"modelList" : {
"mistral-openorca" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 8192 ,
"systemAsUser" : false ,
"args" : {}
}
}
},
...
},
...
}Maintenant, nous pouvons exécuter une ailice:
ailice_web --modelID=ollama:mistral-openorcaDans cet exemple, nous utiliserons LM Studio pour exécuter le modèle le plus open source que j'ai jamais vu: QWEN2-72B-Instruct-Q3_K_S.GGUF , alimentant Ailice pour fonctionner sur une machine locale.
Téléchargez les poids du modèle de QWEN2-72B-Instruct-Q3_K_S.GGUF à l'aide de LM Studio.
Dans la fenêtre "LocalServer" du Studio LM, définissez n_gpu_layers sur -1 si vous souhaitez utiliser uniquement GPU. Ajustez le paramètre «Longueur de contexte» sur la gauche à 16384 (ou une valeur plus petite en fonction de votre mémoire disponible) et modifiez la «politique de débordement de contexte» pour «garder l'invite du système et le premier message utilisateur, truncate middle».
Exécutez le service. Nous supposons que l'adresse du service est "http: // localhost: 1234 / v1 /".
Ensuite, nous ouvrons config.json et apportons les modifications suivantes:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"qwen2-72b" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 32764 ,
"systemAsUser" : true ,
"args" : {}
}
}
},
...
},
...
}Enfin, courez de l'allice. Vous pouvez ajuster le paramètre «contextwindowratio» en fonction de votre VRAM ou de votre espace mémoire disponible. Plus le paramètre est grand, plus l'espace VRAM est nécessaire.
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5Semblable à ce que nous avons fait dans la section précédente, après avoir utilisé LM Studio pour télécharger et exécuter Llava, nous modifions le fichier de configuration comme suit:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"llava-1.6-34b" : {
"formatter" : " AFormatterGPTVision " ,
"contextWindow" : 4096 ,
"systemAsUser" : true ,
"args" : {}
}
},
},
...
},
...
}Cependant, il convient de noter que le modèle multimodal open source actuel est loin d'être suffisant pour effectuer des tâches d'agent, donc cet exemple est pour les développeurs plutôt que pour les utilisateurs.
Pour les modèles open source sur HuggingFace, il vous suffit de connaître les informations suivantes pour ajouter la prise en charge des nouveaux modèles: l'adresse HuggingFace du modèle, le format rapide du modèle et la longueur de la fenêtre de contexte. Habituellement, une ligne de code est suffisante pour ajouter un nouveau modèle, mais parfois vous avez malchanceux et vous avez besoin d'une douzaine de lignes de code.
Voici la méthode complète pour ajouter un nouveau support LLM:
Ouvrir config.json, vous devez ajouter la configuration de New LLM dans Models.hf.Modellist, qui ressemble à ce qui suit:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"hf" : {
"modelWrapper" : " AModelCausalLM " ,
"modelList" : {
"meta-llama/Llama-2-13b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
"meta-llama/Llama-2-70b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
...
}
},
...
}
...
}"Formatter" est une classe qui définit le format rapide de LLM. Vous pouvez trouver leurs définitions dans Core / LLM / AFORmatter. Vous pouvez lire ces codes pour déterminer le format requis pour le modèle que vous souhaitez ajouter. Si vous ne le trouveriez pas, vous devez en écrire un vous-même. Heureusement, le formateur est une chose très simple et peut être achevé dans plus d'une douzaine de lignes de code. Je crois que vous comprendrez comment le faire après avoir lu quelques codes source de format.
La fenêtre de contexte est une propriété que la LLM de l'architecture du transformateur propose généralement. Il détermine la longueur du texte que le modèle peut traiter à la fois. Vous devez définir la fenêtre de contexte du nouveau modèle sur la clé "ContextWindow".
"SystemAsUser": Nous utilisons le rôle "Système" comme l'expéditeur du message renvoyé par les appels de fonction. Cependant, tous les LLM n'ont pas une définition claire du rôle du système, et rien ne garantit que le LLM peut s'adapter à cette approche. Nous devons donc utiliser SystemAsUser pour définir s'il faut mettre le texte renvoyé par les appels de fonction dans les messages utilisateur. Essayez de le régler sur FAUX en premier.
Tout est fait! Utilisez "HF:" comme préfixe du nom du modèle pour former un modélide, et utilisez le modèle du nouveau modèle comme paramètre de commande pour démarrer l'allice!
Ailice a deux modes de fonctionnement. Un mode utilise un seul LLM pour conduire tous les agents, tandis que l'autre permet à chaque type d'agent de spécifier un LLM correspondant. Ce dernier mode nous permet de mieux combiner les capacités des modèles open source et des modèles commerciaux, réalisant de meilleures performances à moindre coût. Pour utiliser le deuxième mode, vous devez configurer l'élément AgentModelConfig dans config.json d'abord:
"modelID" : " " ,
"agentModelConfig" : {
"DEFAULT" : " openrouter:qwen/qwen-2-72b-instruct " ,
"coder" : " openrouter:deepseek/deepseek-coder "
},Tout d'abord, assurez-vous que la valeur par défaut de ModeLID est définie sur une chaîne vide, puis configurez le LLM correspondant pour chaque type d'agent dans AgentModelConfig.
Enfin, vous pouvez obtenir le deuxième mode de fonctionnement en ne spécifiant pas un modèle:
ailice_webLes principes de base lors de la conception de l'aiili sont:
Expliquons brièvement ces principes fondamentaux.
À partir du niveau le plus évident, une construction rapide très dynamique rend moins probable qu'un agent tombe dans une boucle. L'afflux de nouvelles variables de l'environnement externe a un impact en permanence sur le LLM, l'aidant à éviter ce piège. De plus, l'alimentation du LLM avec toutes les informations actuellement disponibles peut considérablement améliorer sa sortie. For example, in automated programming, error messages from interpreters or command lines assist the LLM in continuously modifying the code until the correct result is achieved. Lastly, in dynamic prompt construction, new information in the prompts may also come from other agents, which acts as a form of linked inference computation, making the system's computational mechanisms more complex, varied, and capable of producing richer behaviors.
Separating computational tasks is, from a practical standpoint, due to our limited context window. We cannot expect to complete a complex task within a window of a few thousand tokens. If we can decompose a complex task so that each subtask is solved within limited resources, that would be an ideal outcome. In traditional computing models, we have always taken advantage of this, but in new computing centered around LLMs, this is not easy to achieve. The issue is that if one subtask fails, the entire task is at risk of failure. Recursion is even more challenging: how do you ensure that with each call, the LLM solves a part of the subproblem rather than passing the entire burden to the next level of the call? We have solved the first problem with the IACT architecture in Ailice, and the second problem is theoretically not difficult to solve, but it likely requires a smarter LLM.
The third principle is what everyone is currently working on: having multiple intelligent agents interact and cooperate to complete more complex tasks. The implementation of this principle actually addresses the aforementioned issue of subtask failure. Multi-agent collaboration is crucial for the fault tolerance of agents in operation. In fact, this may be one of the biggest differences between the new computational paradigm and traditional computing: traditional computing is precise and error-free, assigning subtasks only through unidirectional communication (function calls), whereas the new computational paradigm is error-prone and requires bidirectional communication between computing units to correct errors. This will be explained in detail in the following section on the IACT framework.
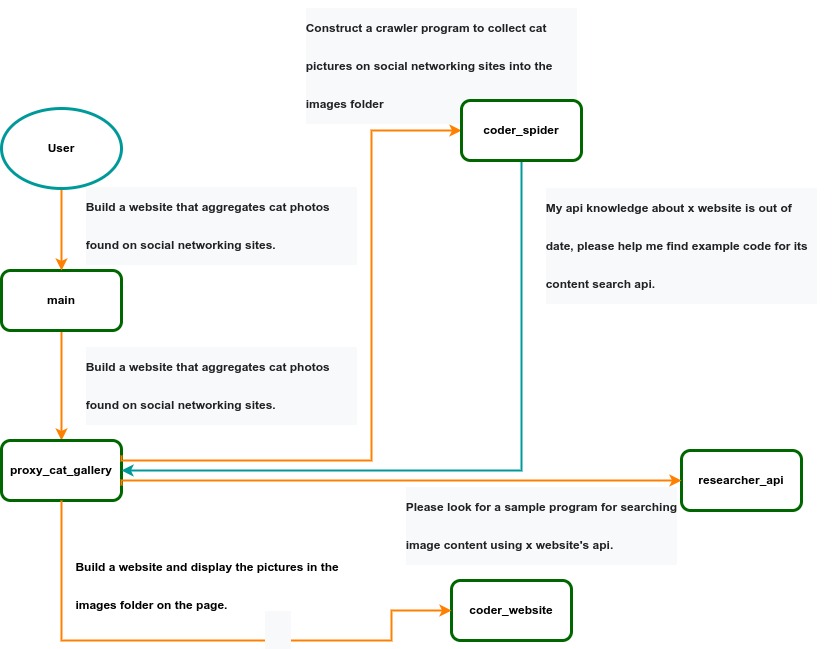 IACT Architecture Diagram. A user requirement to build a page for image collection and display is dynamically decomposed into two tasks: coder_spider and coder_website. When coder_spider encounters difficulties, it proactively seeks assistance from its caller, proxy_cat_gallery. Proxy_cat_gallery then creates another agent, researcher_api, and employs it to address the issue.
IACT Architecture Diagram. A user requirement to build a page for image collection and display is dynamically decomposed into two tasks: coder_spider and coder_website. When coder_spider encounters difficulties, it proactively seeks assistance from its caller, proxy_cat_gallery. Proxy_cat_gallery then creates another agent, researcher_api, and employs it to address the issue.
Ailice can be regarded as a computer powered by a LLM , and its features include:
Representing input, output, programs, and data in text form.
Using LLM as the processor.
Breaking down computational tasks through successive calls to basic computing units (analogous to functions in traditional computing), which are essentially various functional agents.
Therefore, user-input text commands are executed as a kind of program, decomposed into various "subprograms", and addressed by different agents , forming the fundamental architecture of Ailice. In the following, we will provide a detailed explanation of the nature of these basic computing units.
A natural idea is to let LLM solve certain problems (such as information retrieval, document understanding, etc.) through multi-round dialogues with external callers and peripheral modules in the simplest computational unit. We temporarily call this computational unit a "function". Then, by analogy with traditional computing, we allow functions to call each other, and finally add the concept of threads to implement multi-agent interaction. However, we can have a much simpler and more elegant computational model than this.
The key here is that the "function" that wraps LLM reasoning can actually be called and returned multiple times. A "function" with coder functionality can pause work and return a query statement to its caller when it encounters unclear requirements during coding. If the caller is still unclear about the answer, it continues to ask the next higher level caller. This process can even go all the way to the final user's chat window. When new information is added, the caller will reactivate the coder's execution process by passing in the supplementary information. It can be seen that this "function" is not a traditional function, but an object that can be called multiple times. The high intelligence of LLM makes this interesting property possible. You can also see it as agents strung together by calling relationships, where each agent can create and call more sub-agents, and can also dialogue with its caller to obtain supplementary information or report its progress . In Ailice, we call this computational unit "AProcessor" (essentially what we referred to as an agent). Its code is located in core/AProcessor.py.
Next, we will elaborate on the structure inside AProcessor. The interior of AProcessor is a multi-round dialogue. The "program" that defines the function of AProcessor is a prompt generation mechanism, which generates the prompt for each round of dialogue from the dialogue history. The dialogue is one-to-many. After the external caller inputs the request, LLM will have multiple rounds of dialogue with the peripheral modules (we call them SYSTEM), LLM outputs function calls in various grammatical forms, and the system calls the peripheral modules to generate results and puts the results in the reply message. LLM finally gets the answer and responds to the external caller, ending this call. But because the dialogue history is still preserved, the caller can call in again to continue executing more tasks.
The last part we want to introduce is the parsing module for LLM output. In fact, we regard the output text of LLM as a "script" of semi-natural language and semi-formal language, and use a simple interpreter to execute it . We can use regular expressions to express a carefully designed grammatical structure, parse it into a function call and execute it. Under this design, we can design more flexible function call grammar forms, such as a section with a certain fixed title (such as "UPDATE MEMORY"), which can also be directly parsed out and trigger the execution of an action. This implicit function call does not need to make LLM aware of its existence, but only needs to make it strictly follow a certain format convention. For the most hardcore possibility, we have left room. The interpreter here can not only use regular expressions for pattern matching, its Eval function is recursive. We don't know what this will be used for, but it seems not bad to leave a cool possibility, right? Therefore, inside AProcessor, the calculation is alternately completed by LLM and the interpreter, their outputs are each other's inputs, forming a cycle.
In Ailice, the interpreter is one of the most crucial components within an agent. We use the interpreter to map texts from the LLM output that match specific patterns to actions, including function calls, variable definitions and references, and any user-defined actions. Sometimes these actions directly interact with peripheral modules, affecting the external world; other times, they are used to modify the agent's internal state, thereby influencing its future prompts.
The basic structure of the interpreter is straightforward: a list of pattern-action pairs. Patterns are defined by regular expressions, and actions are specified by a Python function with type annotations. Given that syntactic structures can be nested, we refer to the overarching structure as the entry pattern. During runtime, the interpreter actively detects these entry patterns in the LLM output text. Upon detecting an entry pattern (and if the corresponding action returns data), it immediately terminates the LLM generation to execute the relevant action.
The design of agents in Ailice encompasses two fundamental aspects: the logic for generating prompts based on dialogue history and the agent's internal state, and a set of pattern-action pairs. Essentially, the agent implements the interpreter framework with a set of pattern-action pairs; it becomes an integral part of the interpreter. The agent's internal state is one of the targets for the interpreter's actions, with changes to the agent's internal state influencing the direction of future prompts.
Generating prompts from dialogue history and the internal state is nearly a standardized process, although developers still have the freedom to choose entirely different generation logic. The primary challenge for developers is to create a system prompt template, which is pivotal for the agent and often demands the most effort to perfect. However, this task revolves entirely around crafting natural language prompts.
Ailice utilizes a simple scripting language embedded within text to map the text-based capabilities of LLMs to the real world. This straightforward scripting language includes non-nested function calls and mechanisms for creating and referencing variables, as well as operations for concatenating text content . Its purpose is to enable LLMs to exert influence on the world more naturally: from smoother text manipulation abilities to simple function invocation mechanisms, and multimodal variable operation capabilities. Finally, it should be noted that for the designers of agents, they always have the freedom to extend new syntax for this scripting language. What is introduced here is a minimal standard syntax structure.
The basic syntax is as follows:
Variable Definition: VAR_NAME := <!|"SOME_CONTENT"|!>
Function Calls/Variable References/Text Concatenation: !FUNC-NAME<!|"...", '...', VAR_NAME1, "Execute the following code: n" + VAR_NAME2, ...|!>
The basic variable types are str/AImage/various multimodal types. The str type is consistent with Python's string syntax, supporting triple quotes and escape characters.
This constitutes the entirety of the embedded scripting language.
The variable definition mechanism introduces a way to extend the context window, allowing LLMs to record important content into variables to prevent forgetting. During system operation, various variables are automatically defined. For example, if a block of code wrapped in triple backticks is detected within a text message, a variable is automatically created to store the code, enabling the LLM to reference the variable to execute the code, thus avoiding the time and token costs associated with copying the code in full. Furthermore, some module functions may return data in multimodal types rather than text. In such cases, the system automatically defines these as variables of the corresponding multimodal type, allowing the LLM to reference them (the LLM might send them to another module for processing).
In the long run, LLMs are bound to evolve into multimodal models capable of seeing and hearing. Therefore, the exchanges between Ailice's agents should be in rich text , not just plain text. While Markdown provides some capability for marking up multimodal content, it is insufficient. Hence, we will need an extended version of Markdown in the future to include various embedded multimodal data such as videos and audio.
Let's take images as an example to illustrate the multimodal mechanism in Ailice. When agents receive text containing Markdown-marked images, the system automatically inputs them into a multimodal model to ensure the model can see these contents. Markdown typically uses paths or URLs for marking, so we have expanded the Markdown syntax to allow the use of variable names to reference multimodal content.
Another minor issue is how different agents with their own internal variable lists exchange multimodal variables. This is simple: the system automatically checks whether a message sent from one agent to another contains internal variable names. If it does, the variable content is passed along to the next agent.
Why do we go to the trouble of implementing an additional multimodal variable mechanism when marking multimodal content with paths and URLs is much more convenient? This is because marking multimodal content based on local file paths is only feasible when Ailice runs entirely in a local environment, which is not the design intent. Ailice is meant to be distributed, with the core and modules potentially running on different computers, and it might even load services running on the internet to provide certain computations. This makes returning complete multimodal data more attractive. Of course, these designs made for the future might be over-engineering, and if so, we will modify them in the future.
One of the goals of Ailice is to achieve introspection and self-expansion (which is why our logo features a butterfly with its reflection in the water). This would enable her to understand her own code and build new functionalities, including new external interaction modules (ie new functions) and new types of agents (APrompt class) . As a result, the knowledge and capabilities of LLMs would be more thoroughly unleashed.
Implementing self-expansion involves two parts. On one hand, new modules and new types of agents (APrompt class) need to be dynamically loaded during runtime and naturally integrated into the computational system to participate in processing, which we refer to as dynamic loading. On the other hand, Ailice needs the ability to construct new modules and agent types.
The dynamic loading mechanism itself is of great significance: it represents a novel software update mechanism . We can allow Ailice to search for its own extension code on the internet, check the code for security, fix bugs and compatibility issues, and ultimately run the extension as part of itself. Therefore, Ailice developers only need to place their contributed code on the internet, without the need to merge into the main codebase or consider any other installation methods. The implementation of the dynamic loading mechanism is continuously improving. Its core lies in the extension packages providing some text describing their functions. During runtime, each agent in Ailice finds suitable functions or agent types to solve sub-problems for itself through semantic matching and other means.
Building new modules is a relatively simple task, as the interface constraints that modules need to meet are very straightforward. We can teach LLMs to construct new modules through an example. The more complex task is the self-construction of new agent types (APrompt class), which requires a good understanding of Ailice's overall architecture. The construction of system prompts is particularly delicate and is a challenging task even for humans. Therefore, we pin our hopes on more powerful LLMs in the future to achieve introspection, allowing Ailice to understand herself by reading her own source code (for something as complex as a program, the best way to introduce it is to present itself), thereby constructing better new agents .
For developing Agents, the main loop of Ailice is located in the AiliceMain.py or ui/app.py files. To further understand the construction of an agent, you need to read the code in the "prompts" folder, by reading these code you can understand how an agent's prompts are dynamically constructed.
For developers who want to understand the internal operation logic of Ailice, please read core/AProcessor.py and core/Interpreter.py. These two files contain approximately three hundred lines of code in total, but they contain the basic framework of Ailice.
In this project, achieving the desired functionality of the AI Agent is the primary goal. The secondary goal is code clarity and simplicity . The implementation of the AI Agent is still an exploratory topic, so we aim to minimize rigid components in the software (such as architecture/interfaces imposing constraints on future development) and provide maximum flexibility for the application layer (eg, prompt classes) . Abstraction, deduplication, and decoupling are not immediate priorities.
When implementing a feature, always choose the best method rather than the most obvious one . The metric for "best" often includes traits such as trivializing the problem from a higher perspective, maintaining code clarity and simplicity, and ensuring that changes do not significantly increase overall complexity or limit the software's future possibilities.
Adding comments is not mandatory unless absolutely necessary; strive to make the code clear enough to be self-explanatory . While this may not be an issue for developers who appreciate comments, in the AI era, we can generate detailed code explanations at any time, eliminating the need for unstructured, hard-to-maintain comments.
Follow the principle of Occam's razor when adding code; never add unnecessary lines .
Functions or methods in the core should not exceed 60 lines .
While there are no explicit coding style constraints, maintain consistency or similarity with the original code in terms of naming and case usage to avoid readability burdens.
Ailice aims to achieve multimodal and self-expanding features within a scale of less than 5000 lines, reaching its final form at the current stage. The pursuit of concise code is not only because succinct code often represents a better implementation, but also because it enables AI to develop introspective capabilities early on and facilitates better self-expansion. Please adhere to the above rules and approach each line of code with diligence.
Ailice's fundamental tasks are twofold: one is to fully unleash the capabilities of LLM based on text into the real world; the other is to explore better mechanisms for long-term memory and forming a coherent understanding of vast amounts of text . Our development efforts revolve around these two focal points.
If you are interested in the development of Ailice itself, you may consider the following directions:
Explore improved long-term memory mechanisms to enhance the capabilities of each Agent. We need a long-term memory mechanism that enables consistent understanding of large amounts of content and facilitates association . The most feasible option at the moment is to replace vector database with knowledge graph, which will greatly benefit the comprehension of long texts/codes and enable us to build genuine personal AI assistants.
Multimodal support. The support for the multimodal model has been completed, and the current development focus is shifting towards the multimodal support of peripheral modules. We need a module that operates computers based on screenshots and simulates mouse/keyboard actions.
Self-expanding support. Our goal is to enable language models to autonomously code and implement new peripheral modules/agent types and dynamically load them for immediate use . This capability will enable self-expansion, empowering the system to seamlessly integrate new functionalities. We've completed most of the functionality, but we still need to develop the capability to construct new types of agents.
Richer UI interface . We need to organize the agents output into a tree structure in dialog window and dynamically update the output of all agents. And accept user input on the web interface and transfer it to scripter's standard input, which is especially needed when using sudo.
Develop Agents with various functionalities based on the current framework.
Explore the application of IACT architecture on complex tasks. By utilizing an interactive agents call tree, we can break down large documents for improved reading comprehension, as well as decompose complex software engineering tasks into smaller modules, completing the entire project build and testing through iterations. This requires a series of intricate prompt designs and testing efforts, but it holds an exciting promise for the future. The IACT architecture significantly alleviates the resource constraints imposed by the context window, allowing us to dynamically adapt to more intricate tasks.
Build rich external interaction modules using self-expansion mechanisms! This will be accomplished in AiliceEVO.
In addition to the tasks mentioned above, we should also start actively contemplating the possibility of creating a smaller LLM that possesses lower knowledge content but higher reasoning abilities .


