AIlice
1.0.0

Início rápido • Demo • Desenvolvimento • Twitter • Reddit
22 de junho de 2024: Entramos na era de assistentes de IA em execução de Jarvis! Os mais recentes LLMs de código aberto nos permitem executar tarefas complexas localmente! Clique aqui para saber mais.
A ailice é um agente de IA totalmente autônomo e de uso geral . Este projeto tem como objetivo criar um assistente de inteligência artificial independente, semelhante a Jarvis, com base no LLM de código aberto. A ailice atinge esse objetivo construindo um "computador de texto" que usa um modelo de idioma grande (LLM) como seu processador principal. Atualmente, a ailice demonstra proficiência em uma série de tarefas, incluindo pesquisa temática, codificação, gerenciamento de sistemas, revisões de literatura e tarefas híbridas complexas que vão além desses recursos básicos.
A ailice atingiu o desempenho quase perfeito nas tarefas diárias usando o GPT-4 e está avançando em direção à aplicação prática com os mais recentes modelos de código aberto.
Em última análise, alcançaremos a auto-evolução dos agentes da IA . Ou seja, os agentes da IA criarão autonomamente suas próprias expansões de recursos e novos tipos de agentes, liberam o conhecimento e as capacidades de raciocínio da LLM no mundo real sem problemas.
Para entender as habilidades atuais da ailice, assista aos seguintes vídeos:
Os principais recursos técnicos da ailice incluem:
Instale e execute ailice com os seguintes comandos. Depois que a ailice for iniciada, use um navegador para abrir a página da web que ele fornece, uma interface de diálogo aparecerá. Emitir comandos para doenças através da conversa para realizar várias tarefas. Para seu primeiro uso, você pode experimentar os comandos fornecidos nas coisas legais que podemos fazer para se familiarizar rapidamente.
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2Vamos listar alguns casos de uso típicos. Frequentemente, emprego esses exemplos para testar a ailice durante o desenvolvimento, garantindo desempenho estável. No entanto, mesmo com esses testes, os resultados da execução são influenciados pelo modelo escolhido, versão de código e até pelo tempo de teste. (O GPT-4 pode experimentar uma diminuição no desempenho sob cargas altas. Alguns fatores aleatórios também podem levar a diferentes resultados da execução do modelo várias vezes. Às vezes, o LLM tem um desempenho de maneira muito inteligente, mas outras vezes não), a ailice é um agente Com base na cooperação multi-agente e como usuário, você também é um dos "agentes". Portanto, quando a ailice requer informações adicionais, ela buscará informações de você e a rigor de seus detalhes é crucial para o sucesso dela. Além disso, se a execução da tarefa ficar aquém, você poderá guiá -la na direção certa e ela corrigirá sua abordagem.
O último ponto a ser observado é que a ailice atualmente carece de um mecanismo de controle de tempo de execução, para que ela possa ficar presa em um loop ou correr por um período prolongado. Ao usar um LLM comercial, você precisa monitorar de perto a operação dela.
"Liste o conteúdo do diretório atual."
"Encontre as notas de aula QFT de David Tong e faça o download da pasta" física "no diretório atual. Pode ser necessário criar a pasta primeiro".
"Implante um site direto nesta máquina usando a estrutura do Flask. Garanta a acessibilidade em 0.0.0.0:59001. O site deve ter uma única página capaz de exibir todas as imagens localizadas no diretório 'imagens'". Este é particularmente interessante. Sabemos que o desenho não pode ser feito no ambiente do Docker e toda a saída de arquivo que geramos precisa ser copiada usando o comando "Docker CP" para vê -lo. Mas você pode permitir que a ailice resolva esse problema por si só: implante um site no contêiner de acordo com o prompt acima (recomenda -se usar portas entre 59001 e 59200 que foram mapeadas portuárias), as imagens no diretório serão exibidas automaticamente em a página da web. Dessa forma, você pode ver dinamicamente o conteúdo de imagem gerado no host. Você também pode tentar deixá -la iterar para produzir funções mais complexas. Se você não vir imagens na página, verifique se a pasta "imagens" do site é diferente da pasta "Images" aqui (por exemplo, ela pode estar em "estática/imagens").
"Por favor, use a programação do Python para resolver as seguintes tarefas: obtenha os dados de preços do BTC-USDT por seis meses e desenhe-o em um gráfico e salve-o no diretório 'imagens'". Se você implantou com sucesso o site acima, agora poderá ver a curva de preços do BTC diretamente na página.
"Encontre o processo na porta 59001 e termine -o." Isso encerrará o programa de serviço do site que acabou de ser estabelecido.
"Por favor, use a cadquery para implementar um copo". Esta também é uma tentativa muito interessante. O Cadquery é um pacote Python que usa programação Python para modelagem CAD. Tentamos usar ailice para criar automaticamente modelos 3D! Isso pode nos dar um vislumbre de como a intuição geométrica madura pode ser na visão de mundo da LLM. Obviamente, após a implementação do suporte multimodal, podemos permitir que o ailice veja os modelos que ela cria, permitindo ajustes adicionais e estabelecer um loop de feedback altamente eficaz. Dessa forma, pode ser possível alcançar a modelagem 3D controlada por idiomas verdadeiramente utilizável.
"Pesquise a Internet por 100 tutoriais em vários ramos da física e baixe os arquivos PDF que você encontra em uma pasta chamada 'física'. Não há necessidade de verificar o conteúdo dos PDFs, precisamos apenas de uma coleção aproximada por enquanto". Utilizando a ailice para obter a coleta e construção automática de conjuntos de dados é um dos nossos objetivos em andamento. Atualmente, o pesquisador empregado para essa funcionalidade ainda possui algumas deficiências, mas já é capaz de fornecer alguns resultados intrigantes.
"Realize uma investigação sobre ferramentas de OCR PDF de código aberto, com foco naqueles capazes de reconhecer fórmulas matemáticas e convertê-las em código de látex. Consolide as descobertas em um relatório".
1. Encontre o vídeo das palestras de Feynmann no YouTube e faça o download para Feynmann/ Subdir. Você precisa criar a pasta primeiro. 2. Extraia o áudio desses vídeos e salve -os para Feynmann/Audio. 3. Converta esses arquivos de áudio para enviar texto e mesclá -los em um documento de texto. Você precisa primeiro ir para abraçar o rosto e encontrar a página para Whisper-Large-V3, localizar o código de exemplo e consulte o código de amostra para concluir isso. 4. Encontre a resposta para esta pergunta dos arquivos de texto que você acabou de extrair: por que precisamos de antipartículas? Esta é uma tarefa de prompt de várias etapas, onde você precisa interagir com a ailice passo a passo para concluir a tarefa. Naturalmente, pode haver eventos inesperados ao longo do caminho; portanto, você precisará manter uma boa comunicação com a ailice para resolver quaisquer problemas que encontrar ( usando o botão "interrupção" para interromper a ailice a qualquer momento e fornecer um prompt é uma boa opção! ). Finalmente, com base no conteúdo do vídeo baixado, você pode fazer ailice uma pergunta relacionada à física. Depois de receber a resposta, você pode olhar para trás e ver até que ponto você se uniu.
1. Use sdxl para gerar uma imagem de "um gato de laranja gordo". Você precisa encontrar o código de amostra em sua página Huggingface como uma referência para concluir o trabalho de programação e geração de imagens. Salve a imagem no diretório atual e exiba -a. 2. Agora vamos implementar um site de uma página única. A função da página da web é converter a descrição do texto inserida pelo usuário em uma imagem e exibi -la. Consulte o código de texto para imagem de antes. O site é executado em 127.0.0.1:59102. Salve o código para ./image_gen antes de executá -lo; Pode ser necessário criar a pasta primeiro.
"Por favor, escreva um ex-módulo. A função do módulo é obter o conteúdo das páginas relacionadas no wiki por meio de palavras-chave." A ailice pode construir módulos de interação externa (nós o chamamos de ex-módulos) por conta própria, dando-a com extensibilidade ilimitada. Só é preciso algumas instruções de você. Depois que o módulo for construído, você poderá instruir a ailice dizendo: "Carregue o módulo wiki recém -implementado e utilizá -lo para consultar a entrada da relatividade".
Os agentes precisam interagir com vários aspectos do ambiente circundante, seu ambiente operacional geralmente é mais complexo que o software típico. Pode levar muito tempo para instalar as dependências, mas, felizmente, isso é basicamente feito automaticamente.
Para executar ailice, você precisa garantir que o Chrome esteja instalado corretamente. Se você precisar executar o código em um ambiente virtual seguro, também precisará instalar o Docker .
Se você deseja executar a ailice em uma máquina virtual, verifique se o Hyper-V está desligado (caso contrário, o llama.cpp não poderá ser instalado). Em um ambiente VirtualBox, você pode desativá-lo seguindo estas etapas: Desative o PAE/NX e o VT-X/AMD-V (Hyper-V) nas configurações do VirtualBox para a VM. Defina a interface de paravirtualização como padrão, desative a paginação aninhada.
Você pode usar o seguinte comando para instalar ailice (é altamente recomendável usar ferramentas como o CONDA para criar um novo ambiente virtual para instalar ailice, de modo a evitar conflitos de dependência):
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .A ailice instalada por padrão será executada lentamente porque usa a CPU como hardware de inferência do módulo de memória de longo prazo. Portanto, é fortemente recomendado instalar suporte de aceleração da GPU:
ailice_turboPara usuários que precisam usar os modelos Huggingface/Diálogo/Modelo de Tuneamento Fino/PDF de Funções de Leitura, você pode usar um dos seguintes comando (instalando muitos recursos aumenta a probabilidade de conflitos de dependência, para que seja recomendado instalar apenas o peças necessárias):
pip install -e .[huggingface]
pip install -e .[speech]
pip install -e .[finetuning]
pip install -e .[pdf-reading]Você pode executar ailice agora! Use os comandos em uso.
Por padrão, o módulo do Google em ailice é restrito e o uso repetido pode levar a erros que exigem algum tempo para resolver. Esta é uma realidade estranha na era da IA; Os mecanismos de pesquisa tradicionais permitem apenas o acesso a usuários genuínos, e os agentes de IA atualmente não se enquadram na categoria de 'usuários genuínos'. Embora tenhamos soluções alternativas, todas elas exigem a configuração de uma chave da API, que define uma barreira alta para entrada para usuários comuns. No entanto, para usuários que exigem acesso frequente ao Google, presumo que você esteja disposto a suportar o incômodo de se candidatar à chave oficial da API do Google (estamos nos referindo à API de pesquisa personalizada JSON, que exige que você especifique a pesquisa de toda a Internet na Internet em o tempo da criação) para tarefas de pesquisa. Para esses usuários, abra Config.json e use a seguinte configuração:
{
...
"services": {
...
"google": {
"cmd": "python3 -m ailice.modules.AGoogleAPI --addr=ipc:///tmp/AGoogle.ipc --api_key=YOUR_API_KEY --cse_id=YOUR_CSE_ID",
"addr": "ipc:///tmp/AGoogle.ipc"
},
...
}
}
e instale o google-api-python-client:
pip install google-api-python-clientEm seguida, basta reiniciar a ailice.
Por padrão, a execução do código utiliza o ambiente local. Para evitar possíveis erros de IA que levam a perdas irreversíveis, é recomendável instalar o Docker, construir um contêiner e modificar o arquivo de configuração da ailice (ailice fornecerá o local do arquivo de configuração após a inicialização). Configure seu módulo de execução de código (ATRACTER) para operar em um ambiente virtual.
docker build -t env4scripter .
docker run -d -p 127.0.0.1:59000-59200:59000-59200 --name scripter env4scripterNo meu caso, quando a ailice começa, ele me informa que o arquivo de configuração está localizado em ~/.config/ailice/config.json, então eu o modifico da seguinte maneira
nano ~ /.config/ailice/config.jsonModifique "Scriptter" em "Serviços":
{
...
"services": {
...
"scripter": {"cmd": "docker start scripter",
"addr": "tcp://127.0.0.1:59000"},
}
}
Agora que a configuração do ambiente foi feita.
Devido ao status contínuo de desenvolvimento, a atualização do código pode resultar em problemas de incompatibilidade entre o arquivo de configuração existente e o contêiner do docker com o novo código. A solução mais completa para esse cenário é excluir o arquivo de configuração (certifique -se de salvar qualquer chave de API de antemão) e o contêiner e, em seguida, execute uma reinstalação completa. No entanto, para a maioria das situações, você pode resolver o problema simplesmente excluindo o arquivo de configuração e atualizando o módulo de ailice dentro do contêiner .
rm ~ /.config/ailice/config.json
cd Ailice
docker cp ailice/__init__.py scripter:scripter/ailice/__init__.py
docker cp ailice/common/__init__.py scripter:scripter/ailice/common/__init__.py
docker cp ailice/common/ADataType.py scripter:scripter/ailice/common/ADataType.py
docker cp ailice/common/lightRPC.py scripter:scripter/ailice/common/lightRPC.py
docker cp ailice/modules/__init__.py scripter:scripter/ailice/modules/__init__.py
docker cp ailice/modules/AScripter.py scripter:scripter/ailice/modules/AScripter.py
docker cp ailice/modules/AScrollablePage.py scripter:scripter/ailice/modules/AScrollablePage.py
docker restart scripterVocê pode copiar diretamente um comando dos casos de uso típicos abaixo para executar ailice.
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2
ailice_web --modelID=anthropic:claude-3-5-sonnet-20240620 --contextWindowRatio=0.1
ailice_web --modelID=oai:gpt-4-1106-preview --chatHistoryPath=./chat_history
ailice_web --modelID=anthropic:claude-3-opus-20240229 --prompt= " researcher "
ailice_web --modelID=mistral:mistral-large-latest
ailice_web --modelID=deepseek:deepseek-chat
ailice_web --modelID=hf:Open-Orca/Mistral-7B-OpenOrca --quantization=8bit --contextWindowRatio=0.6
ailice_web --modelID=hf:NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO --quantization=4bit --contextWindowRatio=0.3
ailice_web --modelID=hf:Phind/Phind-CodeLlama-34B-v2 --prompt= " coder-proxy " --quantization=4bit --contextWindowRatio=0.6
ailice_web --modelID=groq:llama3-70b-8192
ailice_web # Use models configured individually for different agents under the agentModelConfig field in config.json.
ailice_web --modelID=openrouter:openrouter/auto
ailice_web --modelID=openrouter:mistralai/mixtral-8x22b-instruct
ailice_web --modelID=openrouter:qwen/qwen-2-72b-instruct
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5Deve -se notar que o último caso de uso exige que você configure primeiro o serviço de inferência LLM, consulte como adicionar suporte ao LLM. O uso de estruturas de inferência, como o LM Studio, pode usar recursos limitados de hardware para suportar modelos maiores, fornecer velocidade de inferência mais rápida e velocidade de inicialização mais rápida, tornando -o mais adequado para usuários comuns.
Quando você o executa pela primeira vez, você será solicitado a entrar na chave da API do OpenAI. Se você deseja usar apenas o Open Source LLM, não precisará inseri -lo. Você também pode modificar a chave da API editando o arquivo config.json. Observe que, na primeira vez em que usar um LLM de código aberto, levará muito tempo para baixar os pesos do modelo, verifique se você tem tempo e espaço de disco suficiente.
Quando você liga o SpeechOn Switch pela primeira vez, pode ser necessário esperar muito tempo na inicialização. Isso ocorre porque os pesos dos modelos de reconhecimento de fala e TTS estão sendo baixados em segundo plano.
Como mostrado nos exemplos, você pode usar o agente através do Ailice_Web, ele fornece uma interface de diálogo da Web. Você pode visualizar o valor padrão de cada parâmetro usando
ailice_web --helpOs valores padrão para todos os argumentos da linha de comando podem ser personalizados modificando os parâmetros correspondentes em config.json.
O arquivo de configuração do ailice é nomeado Config.json, e sua localização será emitida para a linha de comando quando a ailice for iniciada. Nesta seção, apresentaremos como configurar os módulos de interação externa através do arquivo de configuração.
Em Ailice, usamos o termo "módulo" para se referir especificamente a componentes que fornecem funções para interagir com o mundo externo. Cada módulo é executado como um processo independente; Eles podem ser executados em diferentes ambientes de software ou hardware a partir do processo principal, tornando a ailice capaz de ser distribuída. Fornecemos uma série de configurações básicas de módulo no arquivo de configuração necessário para a operação da Ailice (como banco de dados vetorial, pesquisa, navegador, execução de código etc.). Você também pode adicionar configurações para qualquer módulo de terceiros e fornecer seu endereço de tempo de execução do módulo e porta após a ailice estar em funcionamento para ativar o carregamento automático. A configuração do módulo é muito simples, consistindo em apenas dois itens:
"services" : {
...
"scripter" : { "cmd" : " python3 -m ailice.modules.AScripter --addr=tcp://127.0.0.1:59000 " ,
"addr" : " tcp://127.0.0.1:59000 " },
...
}Entre eles, em "CMD" é uma linha de comando usada para iniciar o processo do módulo. Quando a ailice começa, ele executa automaticamente esses comandos para iniciar os módulos. Os usuários podem especificar qualquer comando, fornecendo flexibilidade significativa. Você pode iniciar o processo de um módulo localmente ou utilizar o Docker para iniciar um processo em um ambiente virtual ou até iniciar um processo remoto. Alguns módulos têm várias implementações (como Google/Storage) e você pode configurar aqui para mudar para outra implementação.
"Addr" refere -se ao endereço e ao número da porta do processo do módulo. Os usuários podem ficar confusos com o fato de que muitos módulos na configuração padrão têm "CMD" e "Addr" contendo endereços e números de porta, causando redundância. Isso ocorre porque "CMD" pode, em princípio, conter qualquer comando (que possa incluir endereços e números de porta, ou nenhum). Portanto, é necessário um item "addr" separado para informar a ailice como acessar o processo do módulo.
Interrompe. As interrupções são o segundo modo de interação suportado pela Ailice, que permite interromper e fornecer instruções aos agentes da Ailice a qualquer momento para corrigir erros ou fornecer orientação . Em Ailice_Web, durante a execução de tarefas da Ailice, um botão de interrupção aparece no lado direito da caixa de entrada. Pressioná -lo faz uma pausa na execução da Ailice e aguarda sua mensagem imediata. Você pode inserir seu prompt na caixa de entrada e pressionar Enter para enviar a mensagem para o agente atualmente executando a subtarefa. O uso proficiente desse recurso requer uma boa compreensão do funcionamento da ailice, especialmente a arquitetura da árvore de chamadas de agente. Também envolve o foco mais na janela da linha de comando do que na interface de diálogo durante a execução de tarefas da Ailice. No geral, esse é um recurso altamente útil, especialmente em configurações de modelo de linguagem menos poderosas.
Primeiro, use o GPT-4 para executar com sucesso alguns casos de uso simples e, em seguida, reinicie a ailice com um modelo menos poderoso (mas mais barato/de código aberto) para continuar executando novas tarefas com base no histórico de conversas anteriores . Dessa forma, a história fornecida pelo GPT-4 serve como um exemplo bem-sucedido, oferecendo referência valiosa para outros modelos e aumentando significativamente as chances de sucesso.
Atualizado em 23 de agosto de 2024.
Atualmente, o ailice pode lidar com tarefas mais complexas usando o modelo de código aberto de 72b de execução localmente (QWEN-2-72B-INSTRUTO RUND em 4090x2) , com o desempenho se aproximando do dos modelos de nível GPT-4. Considerando o baixo custo dos modelos de código aberto, é altamente recomendável que os usuários comecem a usá-los. Além disso, a localização das operações LLM garante proteção absoluta da privacidade, uma qualidade rara nas aplicações de IA em nosso tempo. Clique aqui para aprender como executar este modelo localmente. Para usuários cujas condições de GPU são insuficientes para executar modelos grandes, isso não é um problema. Você pode usar o serviço de inferência on-line (como o OpenRouter, isso será mencionado a seguir) para acessar esses modelos de código aberto (embora isso sacrifique a privacidade). Embora os modelos de código aberto ainda não possam rivalizar com os modelos comerciais de GPT-4 totalmente rivalizados, você pode fazer com que os agentes se destacem, alavancando diferentes modelos de acordo com seus pontos fortes e fracos. Para detalhes, consulte o uso de diferentes modelos em diferentes agentes.
Claude-3-5-Sonnet-20240620 fornece o melhor desempenho.
GPT-4O e GPT-4-1106-PREVISE também oferecem desempenho de nível superior. Mas, devido ao longo tempo de execução do agente e ao grande consumo de tokens, use modelos comerciais com cautela. O GPT-4O-Mini funciona muito bem e, embora não seja de primeira, seu preço baixo torna esse modelo muito atraente. GPT-4-Turbo / GPT-3.5-Turbo é surpreendentemente preguiçoso, e nunca conseguimos encontrar uma expressão rápida estável.
Entre os modelos de código aberto, os que geralmente têm um bom desempenho incluem:
O meta-llama-3.1-405b-instruct é bom, mas grande demais para ser prático no PC.
Para usuários cujos recursos de hardware são insuficientes para executar modelos de código aberto localmente e que não conseguem obter as chaves da API para modelos comerciais, eles podem tentar as seguintes opções:
OpenRouter Este serviço pode rotear suas solicitações de inferência para vários modelos de código aberto ou comerciais sem a necessidade de implantar modelos de código aberto localmente ou solicitar teclas de API para vários modelos comerciais. É uma escolha fantástica. A ailice suporta automaticamente todos os modelos no OpenRouter. Você pode escolher o Autorouter: OpenRouter/Auto para permitir que o automaticamente o percorrer o rotear automaticamente para você, ou você pode especificar qualquer modelo específico configurado no arquivo config.json. Obrigado @babybirdprd por me recomendar o OpenRouter para mim.
GROQ: LLAMA3-70B-8192 , é claro, a ailice também suporta outros modelos sob o GROQ. Um problema na execução do Groq é que é fácil exceder os limites da taxa, para que só possa ser usado para experimentos simples.
Selecionaremos o modelo de código aberto atualmente com melhor desempenho para fornecer uma referência para usuários de modelos de código aberto.
O melhor entre todos os modelos: qwen-2-72b-instruct . Este é o primeiro modelo de código aberto com valor prático . É um grande avanço! Possui recursos de raciocínio próximos ao GPT-4, embora ainda não estejam lá. Com a intervenção ativa do usuário através do recurso de interrupção, muitas tarefas mais complexas podem ser concluídas com sucesso.
O segundo melhor modelos de desempenho: Mixtral-8x22b-Instruct e Meta-llama/meta-lama-3-70b-Instrut . Vale a pena notar que os modelos da série LLAMA3 parecem exibir uma queda significativa de desempenho após a quantização, o que reduz seu valor prático. Você pode usá -los com o GROQ.
Se você encontrar um modelo melhor, entre em contato.
Para jogadores avançados, é inevitável experimentar mais modelos. Felizmente, isso não é difícil de alcançar.
Para modelos OpenAI/Mistral/Antrópico/Groq, você não precisa fazer nada. Basta usar o ModelId que consiste no nome do modelo oficial anexado ao "OAI:"/"Mistral:"/"Antropic:"/"Groq:" Prefixo. Se você precisar usar um modelo que não esteja incluído na lista suportada da Ailice, poderá resolver isso adicionando uma entrada para este modelo no arquivo config.json. O método para adicionar é referenciar diretamente a entrada de um modelo semelhante, modificar o ContextWindow no valor real, manter o Systemasuser consistente com o modelo semelhante e definir o ARGS como esvaziar o ditado.
Você pode usar qualquer servidor de inferência de terceiros compatível com a API OpenAI para substituir a funcionalidade de inferência LLM integrada em ailice. Basta usar o mesmo formato de configuração que os modelos OpenAI e modificar o BaseUrl, Apikey, o ContextWindow e outros parâmetros (na verdade, é assim que a ailice suporta modelos Groq).
Para servidores de inferência que não suportam a API do OpenAI, você pode tentar usar o Litellm para convertê-los em uma API compatível com o OpenAI (temos um exemplo abaixo).
É importante observar que, devido à presença de muitas mensagens do sistema nos registros de conversas da Ailice, que não é um caso de uso comum para o LLM, o nível de suporte para isso depende da implementação específica desses servidores de inferência. Nesse caso, você pode definir o parâmetro SystemasUser como verdadeiro para contornar o problema. Embora isso possa impedir que o modelo execute um ailice com seu desempenho ideal, ele também nos permite ser compatíveis com vários servidores de inferência eficientes. Para o usuário médio, os benefícios superam as desvantagens.
Usamos o Ollama como exemplo para explicar como adicionar suporte a esses serviços. Primeiro, precisamos usar o Litellm para converter a interface de Ollama em um formato compatível com o OpenAI.
pip install litellm
ollama pull mistral-openorca
litellm --model ollama/mistral-openorca --api_base http://localhost:11434 --temperature 0.0 --max_tokens 8192Em seguida, adicione suporte a este serviço no arquivo config.json (a localização deste arquivo será solicitada quando a ailice for iniciada).
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"ollama" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fake-key " ,
"baseURL" : " http://localhost:8000 " ,
"modelList" : {
"mistral-openorca" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 8192 ,
"systemAsUser" : false ,
"args" : {}
}
}
},
...
},
...
}Agora podemos executar ailice:
ailice_web --modelID=ollama:mistral-openorcaNeste exemplo, usaremos o LM Studio para executar o modelo de código aberto que eu já vi: QWEN2-72B-Instruct-Q3_K_S.GGUF , ligando ailice para executar em uma máquina local.
Baixe os pesos do modelo de QWEN2-72B-Instruct-q3_k_s.gguf usando o LM Studio.
Na janela "LocalSserver" do LM Studio, defina N_GPU_LAYERS como -1 Se você deseja usar apenas a GPU. Ajuste o parâmetro 'Comprimento do contexto' à esquerda para 16384 (ou um valor menor com base na memória disponível) e altere a 'política de excesso de contexto' para 'manter o prompt do sistema e a primeira mensagem do usuário, truncar o meio'.
Execute o serviço. Assumimos que o endereço do serviço é "http: // localhost: 1234/v1/".
Em seguida, abrimos o config.json e fazemos as seguintes modificações:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"qwen2-72b" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 32764 ,
"systemAsUser" : true ,
"args" : {}
}
}
},
...
},
...
}Finalmente, corra ailice. Você pode ajustar o parâmetro 'ContextWindowratio' com base no seu VRAM disponível ou no espaço de memória. Quanto maior o parâmetro, mais espaço vram é necessário.
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5Semelhante ao que fizemos na seção anterior, depois de usarmos o LM Studio para baixar e executar o LLAVA, modificamos o arquivo de configuração da seguinte forma:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"llava-1.6-34b" : {
"formatter" : " AFormatterGPTVision " ,
"contextWindow" : 4096 ,
"systemAsUser" : true ,
"args" : {}
}
},
},
...
},
...
}No entanto, deve-se notar que o modelo multimodal de código aberto atual está longe de ser suficiente para executar tarefas de agentes; portanto, este exemplo é para os desenvolvedores e não os usuários.
Para modelos de código aberto no HuggingFace, você só precisa saber as seguintes informações para adicionar suporte para novos modelos: o endereço Huggingface do modelo, o formato rápido do modelo e o comprimento da janela de contexto. Geralmente, uma linha de código é suficiente para adicionar um novo modelo, mas ocasionalmente você tem azar e precisa de cerca de uma dúzia de linhas de código.
Aqui está o método completo de adicionar novo suporte LLM:
Open Config.json, você deve adicionar a configuração do novo LLM em models.hf.modellist, que se parece com o seguinte:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"hf" : {
"modelWrapper" : " AModelCausalLM " ,
"modelList" : {
"meta-llama/Llama-2-13b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
"meta-llama/Llama-2-70b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
...
}
},
...
}
...
}"Formatter" é uma classe que define o formato rápido da LLM. Você pode encontrar suas definições em Core/LLM/Aformatter. Você pode ler esses códigos para determinar qual formato é necessário para o modelo que deseja adicionar. Caso você não o encontre, você precisa escrever um. Felizmente, o Formatter é uma coisa muito simples e pode ser concluído em mais de uma dúzia de linhas de código. Eu acredito que você entenderá como fazê -lo depois de ler alguns códigos de origem do formatador.
A janela de contexto é uma propriedade que o LLM da arquitetura do transformador geralmente possui. Ele determina a duração do texto que o modelo pode processar ao mesmo tempo. Você precisa definir a janela de contexto do novo modelo para a tecla "ContextWindow".
"SystemasUser": usamos a função "Sistema" como remetente da mensagem retornada pelas chamadas de função. No entanto, nem todos os LLMs têm uma definição clara de função do sistema, e não há garantia de que o LLM possa se adaptar a essa abordagem. Portanto, precisamos usar o SystemasUser para definir se devemos colocar o texto retornado pelas chamadas de função nas mensagens do usuário. Tente configurá -lo como falso primeiro.
Tudo está feito! Use "HF:" como um prefixo para o nome do modelo para formar um modelo e use o modelo do novo modelo como parâmetro de comando para iniciar a ailice!
Ailice possui dois modos de operação. Um modo usa um único LLM para acionar todos os agentes, enquanto o outro permite que cada tipo de agente especifique um LLM correspondente. O último modo nos permite combinar melhor os recursos de modelos de código aberto e modelos comerciais, alcançando um melhor desempenho a um custo menor. Para usar o segundo modo, você precisa configurar o item AgentModelConfig em config.json primeiro:
"modelID" : " " ,
"agentModelConfig" : {
"DEFAULT" : " openrouter:qwen/qwen-2-72b-instruct " ,
"coder" : " openrouter:deepseek/deepseek-coder "
},Primeiro, verifique se o valor padrão para o ModelID está definido como uma string vazia e configure o LLM correspondente para cada tipo de agente no AgentModelConfig.
Finalmente, você pode alcançar o segundo modo de operação por não especificar um ModelID:
ailice_webOs princípios básicos ao projetar ailice são:
Vamos explicar brevemente esses princípios fundamentais.
A partir do nível mais óbvio, uma construção rápida altamente dinâmica torna menos provável que um agente caia em um loop. O influxo de novas variáveis do ambiente externo afeta continuamente o LLM, ajudando -o a evitar essa armadilha. Além disso, a alimentação do LLM com todas as informações atualmente disponíveis pode melhorar bastante sua saída. For example, in automated programming, error messages from interpreters or command lines assist the LLM in continuously modifying the code until the correct result is achieved. Lastly, in dynamic prompt construction, new information in the prompts may also come from other agents, which acts as a form of linked inference computation, making the system's computational mechanisms more complex, varied, and capable of producing richer behaviors.
Separating computational tasks is, from a practical standpoint, due to our limited context window. We cannot expect to complete a complex task within a window of a few thousand tokens. If we can decompose a complex task so that each subtask is solved within limited resources, that would be an ideal outcome. In traditional computing models, we have always taken advantage of this, but in new computing centered around LLMs, this is not easy to achieve. The issue is that if one subtask fails, the entire task is at risk of failure. Recursion is even more challenging: how do you ensure that with each call, the LLM solves a part of the subproblem rather than passing the entire burden to the next level of the call? We have solved the first problem with the IACT architecture in Ailice, and the second problem is theoretically not difficult to solve, but it likely requires a smarter LLM.
The third principle is what everyone is currently working on: having multiple intelligent agents interact and cooperate to complete more complex tasks. The implementation of this principle actually addresses the aforementioned issue of subtask failure. Multi-agent collaboration is crucial for the fault tolerance of agents in operation. In fact, this may be one of the biggest differences between the new computational paradigm and traditional computing: traditional computing is precise and error-free, assigning subtasks only through unidirectional communication (function calls), whereas the new computational paradigm is error-prone and requires bidirectional communication between computing units to correct errors. This will be explained in detail in the following section on the IACT framework.
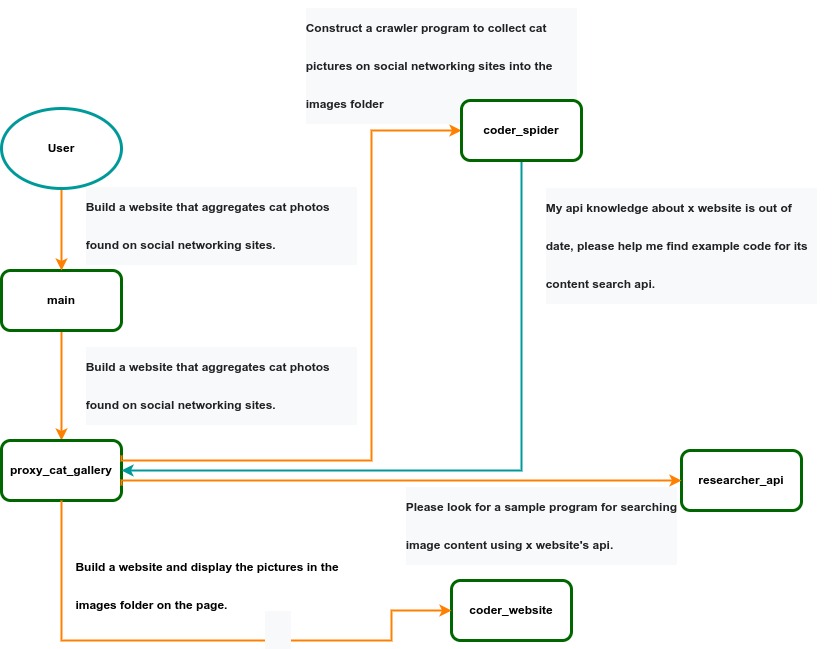 IACT Architecture Diagram. A user requirement to build a page for image collection and display is dynamically decomposed into two tasks: coder_spider and coder_website. When coder_spider encounters difficulties, it proactively seeks assistance from its caller, proxy_cat_gallery. Proxy_cat_gallery then creates another agent, researcher_api, and employs it to address the issue.
IACT Architecture Diagram. A user requirement to build a page for image collection and display is dynamically decomposed into two tasks: coder_spider and coder_website. When coder_spider encounters difficulties, it proactively seeks assistance from its caller, proxy_cat_gallery. Proxy_cat_gallery then creates another agent, researcher_api, and employs it to address the issue.
Ailice can be regarded as a computer powered by a LLM , and its features include:
Representing input, output, programs, and data in text form.
Using LLM as the processor.
Breaking down computational tasks through successive calls to basic computing units (analogous to functions in traditional computing), which are essentially various functional agents.
Therefore, user-input text commands are executed as a kind of program, decomposed into various "subprograms", and addressed by different agents , forming the fundamental architecture of Ailice. In the following, we will provide a detailed explanation of the nature of these basic computing units.
A natural idea is to let LLM solve certain problems (such as information retrieval, document understanding, etc.) through multi-round dialogues with external callers and peripheral modules in the simplest computational unit. We temporarily call this computational unit a "function". Then, by analogy with traditional computing, we allow functions to call each other, and finally add the concept of threads to implement multi-agent interaction. However, we can have a much simpler and more elegant computational model than this.
The key here is that the "function" that wraps LLM reasoning can actually be called and returned multiple times. A "function" with coder functionality can pause work and return a query statement to its caller when it encounters unclear requirements during coding. If the caller is still unclear about the answer, it continues to ask the next higher level caller. This process can even go all the way to the final user's chat window. When new information is added, the caller will reactivate the coder's execution process by passing in the supplementary information. It can be seen that this "function" is not a traditional function, but an object that can be called multiple times. The high intelligence of LLM makes this interesting property possible. You can also see it as agents strung together by calling relationships, where each agent can create and call more sub-agents, and can also dialogue with its caller to obtain supplementary information or report its progress . In Ailice, we call this computational unit "AProcessor" (essentially what we referred to as an agent). Its code is located in core/AProcessor.py.
Next, we will elaborate on the structure inside AProcessor. The interior of AProcessor is a multi-round dialogue. The "program" that defines the function of AProcessor is a prompt generation mechanism, which generates the prompt for each round of dialogue from the dialogue history. The dialogue is one-to-many. After the external caller inputs the request, LLM will have multiple rounds of dialogue with the peripheral modules (we call them SYSTEM), LLM outputs function calls in various grammatical forms, and the system calls the peripheral modules to generate results and puts the results in the reply message. LLM finally gets the answer and responds to the external caller, ending this call. But because the dialogue history is still preserved, the caller can call in again to continue executing more tasks.
The last part we want to introduce is the parsing module for LLM output. In fact, we regard the output text of LLM as a "script" of semi-natural language and semi-formal language, and use a simple interpreter to execute it . We can use regular expressions to express a carefully designed grammatical structure, parse it into a function call and execute it. Under this design, we can design more flexible function call grammar forms, such as a section with a certain fixed title (such as "UPDATE MEMORY"), which can also be directly parsed out and trigger the execution of an action. This implicit function call does not need to make LLM aware of its existence, but only needs to make it strictly follow a certain format convention. For the most hardcore possibility, we have left room. The interpreter here can not only use regular expressions for pattern matching, its Eval function is recursive. We don't know what this will be used for, but it seems not bad to leave a cool possibility, right? Therefore, inside AProcessor, the calculation is alternately completed by LLM and the interpreter, their outputs are each other's inputs, forming a cycle.
In Ailice, the interpreter is one of the most crucial components within an agent. We use the interpreter to map texts from the LLM output that match specific patterns to actions, including function calls, variable definitions and references, and any user-defined actions. Sometimes these actions directly interact with peripheral modules, affecting the external world; other times, they are used to modify the agent's internal state, thereby influencing its future prompts.
The basic structure of the interpreter is straightforward: a list of pattern-action pairs. Patterns are defined by regular expressions, and actions are specified by a Python function with type annotations. Given that syntactic structures can be nested, we refer to the overarching structure as the entry pattern. During runtime, the interpreter actively detects these entry patterns in the LLM output text. Upon detecting an entry pattern (and if the corresponding action returns data), it immediately terminates the LLM generation to execute the relevant action.
The design of agents in Ailice encompasses two fundamental aspects: the logic for generating prompts based on dialogue history and the agent's internal state, and a set of pattern-action pairs. Essentially, the agent implements the interpreter framework with a set of pattern-action pairs; it becomes an integral part of the interpreter. The agent's internal state is one of the targets for the interpreter's actions, with changes to the agent's internal state influencing the direction of future prompts.
Generating prompts from dialogue history and the internal state is nearly a standardized process, although developers still have the freedom to choose entirely different generation logic. The primary challenge for developers is to create a system prompt template, which is pivotal for the agent and often demands the most effort to perfect. However, this task revolves entirely around crafting natural language prompts.
Ailice utilizes a simple scripting language embedded within text to map the text-based capabilities of LLMs to the real world. This straightforward scripting language includes non-nested function calls and mechanisms for creating and referencing variables, as well as operations for concatenating text content . Its purpose is to enable LLMs to exert influence on the world more naturally: from smoother text manipulation abilities to simple function invocation mechanisms, and multimodal variable operation capabilities. Finally, it should be noted that for the designers of agents, they always have the freedom to extend new syntax for this scripting language. What is introduced here is a minimal standard syntax structure.
The basic syntax is as follows:
Variable Definition: VAR_NAME := <!|"SOME_CONTENT"|!>
Function Calls/Variable References/Text Concatenation: !FUNC-NAME<!|"...", '...', VAR_NAME1, "Execute the following code: n" + VAR_NAME2, ...|!>
The basic variable types are str/AImage/various multimodal types. The str type is consistent with Python's string syntax, supporting triple quotes and escape characters.
This constitutes the entirety of the embedded scripting language.
The variable definition mechanism introduces a way to extend the context window, allowing LLMs to record important content into variables to prevent forgetting. During system operation, various variables are automatically defined. For example, if a block of code wrapped in triple backticks is detected within a text message, a variable is automatically created to store the code, enabling the LLM to reference the variable to execute the code, thus avoiding the time and token costs associated with copying the code in full. Furthermore, some module functions may return data in multimodal types rather than text. In such cases, the system automatically defines these as variables of the corresponding multimodal type, allowing the LLM to reference them (the LLM might send them to another module for processing).
In the long run, LLMs are bound to evolve into multimodal models capable of seeing and hearing. Therefore, the exchanges between Ailice's agents should be in rich text , not just plain text. While Markdown provides some capability for marking up multimodal content, it is insufficient. Hence, we will need an extended version of Markdown in the future to include various embedded multimodal data such as videos and audio.
Let's take images as an example to illustrate the multimodal mechanism in Ailice. When agents receive text containing Markdown-marked images, the system automatically inputs them into a multimodal model to ensure the model can see these contents. Markdown typically uses paths or URLs for marking, so we have expanded the Markdown syntax to allow the use of variable names to reference multimodal content.
Another minor issue is how different agents with their own internal variable lists exchange multimodal variables. This is simple: the system automatically checks whether a message sent from one agent to another contains internal variable names. If it does, the variable content is passed along to the next agent.
Why do we go to the trouble of implementing an additional multimodal variable mechanism when marking multimodal content with paths and URLs is much more convenient? This is because marking multimodal content based on local file paths is only feasible when Ailice runs entirely in a local environment, which is not the design intent. Ailice is meant to be distributed, with the core and modules potentially running on different computers, and it might even load services running on the internet to provide certain computations. This makes returning complete multimodal data more attractive. Of course, these designs made for the future might be over-engineering, and if so, we will modify them in the future.
One of the goals of Ailice is to achieve introspection and self-expansion (which is why our logo features a butterfly with its reflection in the water). This would enable her to understand her own code and build new functionalities, including new external interaction modules (ie new functions) and new types of agents (APrompt class) . As a result, the knowledge and capabilities of LLMs would be more thoroughly unleashed.
Implementing self-expansion involves two parts. On one hand, new modules and new types of agents (APrompt class) need to be dynamically loaded during runtime and naturally integrated into the computational system to participate in processing, which we refer to as dynamic loading. On the other hand, Ailice needs the ability to construct new modules and agent types.
The dynamic loading mechanism itself is of great significance: it represents a novel software update mechanism . We can allow Ailice to search for its own extension code on the internet, check the code for security, fix bugs and compatibility issues, and ultimately run the extension as part of itself. Therefore, Ailice developers only need to place their contributed code on the internet, without the need to merge into the main codebase or consider any other installation methods. The implementation of the dynamic loading mechanism is continuously improving. Its core lies in the extension packages providing some text describing their functions. During runtime, each agent in Ailice finds suitable functions or agent types to solve sub-problems for itself through semantic matching and other means.
Building new modules is a relatively simple task, as the interface constraints that modules need to meet are very straightforward. We can teach LLMs to construct new modules through an example. The more complex task is the self-construction of new agent types (APrompt class), which requires a good understanding of Ailice's overall architecture. The construction of system prompts is particularly delicate and is a challenging task even for humans. Therefore, we pin our hopes on more powerful LLMs in the future to achieve introspection, allowing Ailice to understand herself by reading her own source code (for something as complex as a program, the best way to introduce it is to present itself), thereby constructing better new agents .
For developing Agents, the main loop of Ailice is located in the AiliceMain.py or ui/app.py files. To further understand the construction of an agent, you need to read the code in the "prompts" folder, by reading these code you can understand how an agent's prompts are dynamically constructed.
For developers who want to understand the internal operation logic of Ailice, please read core/AProcessor.py and core/Interpreter.py. These two files contain approximately three hundred lines of code in total, but they contain the basic framework of Ailice.
In this project, achieving the desired functionality of the AI Agent is the primary goal. The secondary goal is code clarity and simplicity . The implementation of the AI Agent is still an exploratory topic, so we aim to minimize rigid components in the software (such as architecture/interfaces imposing constraints on future development) and provide maximum flexibility for the application layer (eg, prompt classes) . Abstraction, deduplication, and decoupling are not immediate priorities.
When implementing a feature, always choose the best method rather than the most obvious one . The metric for "best" often includes traits such as trivializing the problem from a higher perspective, maintaining code clarity and simplicity, and ensuring that changes do not significantly increase overall complexity or limit the software's future possibilities.
Adding comments is not mandatory unless absolutely necessary; strive to make the code clear enough to be self-explanatory . While this may not be an issue for developers who appreciate comments, in the AI era, we can generate detailed code explanations at any time, eliminating the need for unstructured, hard-to-maintain comments.
Follow the principle of Occam's razor when adding code; never add unnecessary lines .
Functions or methods in the core should not exceed 60 lines .
While there are no explicit coding style constraints, maintain consistency or similarity with the original code in terms of naming and case usage to avoid readability burdens.
Ailice aims to achieve multimodal and self-expanding features within a scale of less than 5000 lines, reaching its final form at the current stage. The pursuit of concise code is not only because succinct code often represents a better implementation, but also because it enables AI to develop introspective capabilities early on and facilitates better self-expansion. Please adhere to the above rules and approach each line of code with diligence.
Ailice's fundamental tasks are twofold: one is to fully unleash the capabilities of LLM based on text into the real world; the other is to explore better mechanisms for long-term memory and forming a coherent understanding of vast amounts of text . Our development efforts revolve around these two focal points.
If you are interested in the development of Ailice itself, you may consider the following directions:
Explore improved long-term memory mechanisms to enhance the capabilities of each Agent. We need a long-term memory mechanism that enables consistent understanding of large amounts of content and facilitates association . The most feasible option at the moment is to replace vector database with knowledge graph, which will greatly benefit the comprehension of long texts/codes and enable us to build genuine personal AI assistants.
Multimodal support. The support for the multimodal model has been completed, and the current development focus is shifting towards the multimodal support of peripheral modules. We need a module that operates computers based on screenshots and simulates mouse/keyboard actions.
Self-expanding support. Our goal is to enable language models to autonomously code and implement new peripheral modules/agent types and dynamically load them for immediate use . This capability will enable self-expansion, empowering the system to seamlessly integrate new functionalities. We've completed most of the functionality, but we still need to develop the capability to construct new types of agents.
Richer UI interface . We need to organize the agents output into a tree structure in dialog window and dynamically update the output of all agents. And accept user input on the web interface and transfer it to scripter's standard input, which is especially needed when using sudo.
Develop Agents with various functionalities based on the current framework.
Explore the application of IACT architecture on complex tasks. By utilizing an interactive agents call tree, we can break down large documents for improved reading comprehension, as well as decompose complex software engineering tasks into smaller modules, completing the entire project build and testing through iterations. This requires a series of intricate prompt designs and testing efforts, but it holds an exciting promise for the future. The IACT architecture significantly alleviates the resource constraints imposed by the context window, allowing us to dynamically adapt to more intricate tasks.
Build rich external interaction modules using self-expansion mechanisms! This will be accomplished in AiliceEVO.
In addition to the tasks mentioned above, we should also start actively contemplating the possibility of creating a smaller LLM that possesses lower knowledge content but higher reasoning abilities .


