AIlice
1.0.0

Quick Start • Demo • Разработка • Twitter • Reddit
22 июня 2024 года. Мы вошли в эпоху местных помощников, похожих на Джарвис! Последние LLMS с открытым исходным кодом позволяют нам выполнять сложные задачи на местном уровне! Нажмите здесь, чтобы узнать больше.
Ailice-полностью автономный, общий агент ИИ . Этот проект направлен на создание автономного помощника искусственного интеллекта, аналогичного Джарвису, основанному на LLM с открытым исходным кодом. Ailice достигает этой цели, создавая «текстовый компьютер», который использует большую языковую модель (LLM) в качестве основного процессора. В настоящее время Ailice демонстрирует мастерство в ряде задач, включая тематические исследования, кодирование, управление системой, обзоры литературы и сложные гибридные задачи , которые выходят за рамки этих основных возможностей.
Ailice достигла почти идеальной производительности в повседневных задачах с использованием GPT-4 и делает шаги в отношении практического применения с последними моделями с открытым исходным кодом.
В конечном итоге мы достигнем самоиволюции агентов ИИ . То есть агенты искусственного интеллекта будут автономно создавать свои собственные расширения функций и новые типы агентов, развязать знания LLM и рассуждения в реальном мире плавно.
Чтобы понять нынешние способности Ailice, посмотрите следующие видео:
Ключевые технические особенности Ailice включают:
Установите и запустите Ailice со следующими командами. После запуска Ailice используйте браузер, чтобы открыть веб -страницу, которую он предоставляет, появится интерфейс диалога. Выполните команды, чтобы по -разному через разговор для выполнения различных задач. Для вашего первого использования вы можете попробовать команды, представленные в разделе классных вещей, которые мы можем сделать, чтобы быстро познакомиться.
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2Давайте перечислим некоторые типичные варианты использования. Я часто использую эти примеры для тестирования поэтапности во время разработки, обеспечивая стабильную производительность. Однако даже при этих тестах на результаты выполнения влияют выбранная модель, кодовая версия и даже время тестирования. (GPT-4 может испытывать снижение производительности при высоких нагрузках. Некоторые случайные факторы также могут привести к различным результатам запуска модели несколько раз. Иногда LLM работает очень разумно, но в других случаях это не так). Основываясь на многоагентном сотрудничестве и как пользователь, вы также являетесь одним из «агентов». Следовательно, когда AILICE требует дополнительной информации, она будет искать у вас вклад, и тщательность ваших данных имеет решающее значение для ее успеха. Кроме того, если выполнение задачи не достигнет, вы можете направить ее в правильном направлении, и она исправят свой подход.
Последний момент, который следует отметить, заключается в том, что в настоящее время у Айлиса не хватает механизма контроля времени выполнения, поэтому она может застрять в петле или запустить в течение длительного периода. При использовании коммерческого LLM вам нужно внимательно следить за ее работой.
«Пожалуйста, перечислите содержимое текущего каталога».
«Найдите заметки о лекции Дэвида Тонга и загрузите их в папку« Физика »в текущем каталоге. Возможно, вам понадобится сначала создать папку».
«Разверните простой веб -сайт на этой машине, используя Frame Framework. Убедитесь, что доступность на 0.0.0.0:59001. На сайте должна быть одна страница, способная отображать все изображения, расположенные в каталоге« изображения ». Это особенно интересно. Мы знаем, что рисунок не может быть сделан в среде Docker, и все выходные данные, которые мы генерируем, необходимо скопировать с помощью команды «Docker CP», чтобы увидеть ее. Но вы можете позволить Ailice решить эту проблему само по себе: развернуть веб -сайт в контейнере в соответствии с вышеупомянутой подсказкой (рекомендуется использовать порты между 59001 и 59200, которые были отображены), изображения в каталоге будут автоматически отображаться на веб -страница. Таким образом, вы можете динамически увидеть сгенерированное содержание изображения на хосте. Вы также можете попытаться позволить ей итерации произвести более сложные функции. Если вы не видите никаких изображений на странице, пожалуйста, проверьте, отличается ли папка «изображения» веб -сайта от папки «Изображения» здесь (например, она может быть под «статичными/изображениями»).
«Пожалуйста, используйте программирование Python для решения следующих задач: Получите данные о ценах BTC-USDT в течение шести месяцев, нарисуйте его в график, и сохраните их в каталоге« изображения ». Если вы успешно развернули приведенный выше веб -сайт, теперь вы можете увидеть кривую цены BTC непосредственно на странице.
«Найдите процесс на порту 59001 и прекратите его». Это завершит программу обслуживания веб -сайтов, которая была только что создана.
«Пожалуйста, используйте Cadquery для реализации чашки». Это также очень интересная попытка. Cadquery - это пакет Python, который использует программирование Python для моделирования CAD. Мы стараемся использовать Ailice для автоматического создания 3D -моделей! Это может дать нам представление о том, как зрелая геометрическая интуиция может быть в мировоззрении LLM. Конечно, после внедрения мультимодальной поддержки мы можем позволить Айлисе увидеть модели, которые она создает, позволяя для дальнейших корректировок и установив высокоэффективную петлю обратной связи. Таким образом, можно было бы достичь действительно полезного 3D-моделирования, контролируемого языком.
«Пожалуйста, найдите в Интернете 100 учебных пособий в различных филиалах физики и загрузите файлы PDF, которые вы найдете в папку с именем« Физика ». Нет необходимости проверять содержание PDF, нам нужна только грубая коллекция». Использование AILICE для достижения автоматического сбора и конструкции набора данных является одной из наших текущих целей. В настоящее время исследователь, используемый для этой функции, по -прежнему имеет некоторые недостатки, но он уже способен предоставить некоторые интригующие результаты.
«Пожалуйста, проведите исследование инструментов PDF с открытым исходным кодом, с акцентом на тех, кто способен распознавать математические формулы и преобразовать их в код латексного кода. Консолидайте выводы в отчет».
1. Найдите видео лекций Фейнманна на YouTube и загрузите их в Feynmann/ Subdir. вам нужно сначала создать папку. 2. Извлеките звук из этих видео и сохраните его в Feynmann/Audio. 3. Преобразовать эти аудиофайлы в текст и объединить их в текстовый документ. Вам нужно сначала перейти к обнимающему лицом и найти страницу для Whisper-Large-V3, найти пример кода и обратиться к примеру кода, чтобы сделать это. 4. Найдите ответ на этот вопрос из текстовых файлов, которые вы только что извлекли: зачем нам нужны античастицы? Это многоэтапная задача, основанная на приглашении, в которой вам нужно взаимодействовать с пошаговыми поэтапными, чтобы выполнить задачу. Естественно, на этом пути могут быть неожиданные события, поэтому вам нужно будет поддерживать хорошее общение с Ailice, чтобы решить любые проблемы, с которыми вы сталкиваетесь ( использование кнопки «прерывание», чтобы в любое время прервать деликацию, и дать подсказку - хороший вариант! ) Наконец, на основе содержания загруженного видео, вы можете задать Ailice вопрос, связанный с физикой. Как только вы получите ответ, вы можете оглянуться назад и посмотреть, как далеко вы собрались вместе.
1. Используйте SDXL, чтобы генерировать изображение «жирного оранжевого кота». Вам необходимо найти пример кода на странице Huggingface в качестве ссылки для завершения работы программирования и генерации изображений. Сохраните изображение в текущий каталог и отобразите его. 2. Теперь давайте внедрим веб-сайт на одну страницу. Функция веб -страницы состоит в том, чтобы преобразовать текстовое описание, введенное пользователем в изображение и отобразить его. Обратитесь к коду текста к изображению от до. Веб -сайт работает 127.0.0.1:59102. Сохраните код в ./image_gen, прежде чем запустить его; Возможно, вам нужно сначала создать папку.
«Пожалуйста, напишите Ext-Module. Функция модуля состоит в том, чтобы получить содержание связанных страниц на вики через ключевые слова». Ailice может построить модули внешнего взаимодействия (мы называем это Ext-Modules) самостоятельно, тем самым придавая ей неограниченную расширяемость. Все, что нужно, это несколько подсказок от вас. После того, как модуль будет построен, вы можете проинструктировать поэлику, сказав: «Пожалуйста, загрузите недавно реализованный модуль вики и использовать его для запроса записи о относительности».
Агенты должны взаимодействовать с различными аспектами окружающей среды, их операционная среда часто более сложна, чем типичное программное обеспечение. Для установки зависимостей нам может потребоваться много времени, но, к счастью, это в основном делается автоматически.
Чтобы запустить AILICE, вам необходимо убедиться, что Chrome правильно установлен. Если вам нужно выполнить код в безопасной виртуальной среде, вам также необходимо установить Docker .
Если вы хотите запустить Ailice в виртуальной машине, убедитесь, что Hyper-V выключен (в противном случае Llama.cpp не может быть установлен). В среде VirtualBox вы можете отключить его, выполнив эти шаги: отключить PAE/NX и VT-X/AMD-V (Hyper-V) в настройках VirtualBox для виртуальной машины. Установите интерфейс паравиртуализации по умолчанию, отключите вложенную пейджинг.
Вы можете использовать следующую команду для установки Dielice (настоятельно рекомендуется использовать такие инструменты, как Conda, для создания новой виртуальной среды для установки Dielice, чтобы избежать конфликтов зависимости):
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .Ailice, установленная по умолчанию, будет работать медленно, потому что он использует процессор в качестве аппаратного обеспечения логирования модуля долговременной памяти. Поэтому настоятельно рекомендуется установить поддержку ускорения графического процессора:
ailice_turboДля пользователей, которым необходимо использовать модели HuggingFace Models/Voice Dialogue/Model Fine-Tuning/PDF-функции, вы можете использовать одну из следующих команд (установка слишком много функций увеличивает вероятность конфликтов зависимости, поэтому рекомендуется установить только необходимые детали):
pip install -e .[huggingface]
pip install -e .[speech]
pip install -e .[finetuning]
pip install -e .[pdf-reading]Вы можете бегать по делу сейчас! Используйте команды в использовании.
По умолчанию модуль Google в Ailice ограничен, и повторное использование может привести к ошибкам, требующим некоторого времени для разрешения. Это неловкая реальность в эпоху ИИ; Традиционные поисковые системы позволяют только доступ к подлинным пользователям, и агенты искусственного интеллекта в настоящее время не попадают в категорию «подлинных пользователей». Хотя у нас есть альтернативные решения, все они требуют настройки ключа API, который устанавливает высокий барьер для входа для обычных пользователей. Тем не менее, для пользователей, которым требуется частый доступ к Google, я предполагаю, что вы будете готовы терпеть неприятности по подаче заявки на официальный ключ Google API (мы имеем в виду пользовательский поиск JSON API, который требует от вас указать поиск всего Интернета в время творения) для поисковых задач. Для этих пользователей, пожалуйста, откройте config.json и используйте следующую конфигурацию:
{
...
"services": {
...
"google": {
"cmd": "python3 -m ailice.modules.AGoogleAPI --addr=ipc:///tmp/AGoogle.ipc --api_key=YOUR_API_KEY --cse_id=YOUR_CSE_ID",
"addr": "ipc:///tmp/AGoogle.ipc"
},
...
}
}
и установить Google-Api-Python-Client:
pip install google-api-python-clientЗатем просто перезапустите Ailice.
По умолчанию выполнение кода использует локальную среду. Чтобы предотвратить потенциальные ошибки искусственного интеллекта, приводя к необратимым потерям, рекомендуется установить Docker, создать контейнер и изменить файл конфигурации Ailice (Ailice предоставит местоположение файла конфигурации при запуске). Настройте его модуль выполнения кода (ASCRIPTER) для работы в виртуальной среде.
docker build -t env4scripter .
docker run -d -p 127.0.0.1:59000-59200:59000-59200 --name scripter env4scripterВ моем случае, когда начинается Ailice, он сообщает мне, что файл конфигурации расположен по адресу ~/.config/ailice/config.json, поэтому я изменяю его следующим образом
nano ~ /.config/ailice/config.jsonИзмените «Сценарий» в разделе «Сервисы»:
{
...
"services": {
...
"scripter": {"cmd": "docker start scripter",
"addr": "tcp://127.0.0.1:59000"},
}
}
Теперь, когда конфигурация среды была сделана.
Из -за постоянного состояния разработки Ailice обновление кода может привести к проблемам несовместимости между существующим файлом конфигурации и контейнером Docker с новым кодом. Наиболее тщательным решением для этого сценария является удаление файла конфигурации (обязательно сохранить любые ключи API заранее) и контейнер, а затем выполнить полную переустановку. Однако для большинства ситуаций вы можете решить проблему, просто удалив файл конфигурации и обновив модуль Ailice в контейнере .
rm ~ /.config/ailice/config.json
cd Ailice
docker cp ailice/__init__.py scripter:scripter/ailice/__init__.py
docker cp ailice/common/__init__.py scripter:scripter/ailice/common/__init__.py
docker cp ailice/common/ADataType.py scripter:scripter/ailice/common/ADataType.py
docker cp ailice/common/lightRPC.py scripter:scripter/ailice/common/lightRPC.py
docker cp ailice/modules/__init__.py scripter:scripter/ailice/modules/__init__.py
docker cp ailice/modules/AScripter.py scripter:scripter/ailice/modules/AScripter.py
docker cp ailice/modules/AScrollablePage.py scripter:scripter/ailice/modules/AScrollablePage.py
docker restart scripterВы можете напрямую скопировать команду из типичных вариантов использования ниже, чтобы запустить AILICE.
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2
ailice_web --modelID=anthropic:claude-3-5-sonnet-20240620 --contextWindowRatio=0.1
ailice_web --modelID=oai:gpt-4-1106-preview --chatHistoryPath=./chat_history
ailice_web --modelID=anthropic:claude-3-opus-20240229 --prompt= " researcher "
ailice_web --modelID=mistral:mistral-large-latest
ailice_web --modelID=deepseek:deepseek-chat
ailice_web --modelID=hf:Open-Orca/Mistral-7B-OpenOrca --quantization=8bit --contextWindowRatio=0.6
ailice_web --modelID=hf:NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO --quantization=4bit --contextWindowRatio=0.3
ailice_web --modelID=hf:Phind/Phind-CodeLlama-34B-v2 --prompt= " coder-proxy " --quantization=4bit --contextWindowRatio=0.6
ailice_web --modelID=groq:llama3-70b-8192
ailice_web # Use models configured individually for different agents under the agentModelConfig field in config.json.
ailice_web --modelID=openrouter:openrouter/auto
ailice_web --modelID=openrouter:mistralai/mixtral-8x22b-instruct
ailice_web --modelID=openrouter:qwen/qwen-2-72b-instruct
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5Следует отметить, что в последнем использовании необходимо сначала настройка службы вывода LLM, пожалуйста, см., Как добавить поддержку LLM. Использование фреймворков вывода, таких как LM Studio, может использовать ограниченные аппаратные ресурсы для поддержки более крупных моделей, обеспечить более высокую скорость вывода и более высокую скорость запуска по борьбе, что делает их более подходящими для обычных пользователей.
Когда вы запустите его в первый раз, вас попросят войти в Api-Key of Openai. Если вы хотите использовать только LLM с открытым исходным кодом, вам не нужно вводить его. Вы также можете изменить Api-Key, редактируя файл config.json. Обратите внимание, что в первый раз при использовании LLM с открытым исходным кодом потребуется много времени для загрузки веса модели, убедитесь, что у вас достаточно времени и дискового пространства.
Когда вы включите переключатель речи в первый раз, вам, возможно, придется ждать долгое время при запуске. Это связано с тем, что веса моделей распознавания речи и TTS загружаются в фоновом режиме.
Как показано в примерах, вы можете использовать агента через Ailice_web, он предоставляет интерфейс веб -диалога. Вы можете просмотреть значение по умолчанию каждого параметра с помощью
ailice_web --helpЗначения по умолчанию для всех аргументов командной строки могут быть настроены путем изменения соответствующих параметров в config.json.
Файл конфигурации Ailice называется config.json, и его местоположение будет выводиться в командную строку при запуске Ailice. В этом разделе мы представим, как настроить модули внешнего взаимодействия через файл конфигурации.
В DieLice мы используем термин «модуль», чтобы специально ссылаться на компоненты, которые предоставляют функции для взаимодействия с внешним миром. Каждый модуль работает как независимый процесс; Они могут работать в различных программных или аппаратных средах из основного процесса, делая боли, способную распределять. Мы предоставляем серию конфигураций базовых модулей в файле конфигурации, необходимых для работы Ailice (например, векторная база данных, поиск, браузер, выполнение кода и т. Д.). Вы также можете добавить конфигурации для любых сторонних модулей и предоставить их адрес времени выполнения модуля и порт после того, как Ailice будет запущена, чтобы обеспечить автоматическую загрузку. Конфигурация модуля очень проста, состоящая только из двух элементов:
"services" : {
...
"scripter" : { "cmd" : " python3 -m ailice.modules.AScripter --addr=tcp://127.0.0.1:59000 " ,
"addr" : " tcp://127.0.0.1:59000 " },
...
}Среди них под «cmd» находится командная строка, используемая для запуска процесса модуля. Когда начинается Ailice, автоматически запускает эти команды для запуска модулей. Пользователи могут указать любую команду, обеспечивая значительную гибкость. Вы можете запустить процесс модуля локально или использовать Docker, чтобы запустить процесс в виртуальной среде или даже начать удаленный процесс. Некоторые модули имеют несколько реализаций (например, Google/Storage), и вы можете настроить здесь переключение на другую реализацию.
«Addr» относится к адресу и номеру порта процесса модуля. Пользователи могут быть смущены тем фактом, что многие модули в конфигурации по умолчанию имеют как «CMD», так и «ADDR», содержащие адреса и номера портов, что вызывает избыточность. Это связано с тем, что «cmd» может, в принципе, содержать любую команду (которая может включать адреса и номера портов, или вообще нет). Следовательно, отдельный элемент «ADDR» необходим для информирования о том, как получить доступ к процессу модуля.
Прерывания. Прерывания - это второй режим взаимодействия, поддерживаемый Ailice, который позволяет вам прерывать и предоставлять подсказки агентам Ailice в любое время для исправления ошибок или предоставления руководства . В Ailice_Web во время выполнения задачи Dielice кнопка прерывания появляется в правой части блока ввода. Нажатие на него приостанавливает выполнение AILICE и ждет вашего подсказкого сообщения. Вы можете ввести свою подсказку в поле ввода и нажать Enter, чтобы отправить сообщение агенту, в настоящее время выполняющему подзадача. Опытное использование этой функции требует хорошего понимания работы Ailice, особенно архитектуры дерева вызова агента. Это также включает в себя больше внимания к окну командной строки, а не на интерфейсе диалога во время выполнения задачи Dielice. В целом, это очень полезная функция, особенно на менее мощных настройках языковых моделей.
Сначала используйте GPT-4 для успешного запуска некоторых простых вариантов использования, а затем перезапустите Delice с менее мощной (но более дешевой/открытым источником), чтобы продолжить выполнение новых задач на основе предыдущей истории разговора . Таким образом, история, предоставленная GPT-4, служит успешным примером, предлагая ценную ссылку для других моделей и значительно увеличивая шансы на успех.
Обновлено 23 августа 2024 года.
В настоящее время AILICE может выполнять более сложные задачи, используя модель с открытым исходным кодом Locally Run (QWEN-2-72B-инструкт, работающий на 4090x2) , причем производительность приближается к моделям уровня GPT-4. Учитывая низкую стоимость моделей с открытым исходным кодом, мы настоятельно рекомендуем пользователям начать их использовать. Кроме того, локализация операций LLM обеспечивает абсолютную защиту конфиденциальности, редкое качество в приложениях ИИ в наше время. Нажмите здесь, чтобы узнать, как запустить эту модель локально. Для пользователей, чьи условия графического процессора недостаточны для запуска больших моделей, это не проблема. Вы можете использовать онлайн-сервис вывода (например, OpenRouter, это будет упомянуто дальше), чтобы получить доступ к этим моделям с открытым исходным кодом (хотя это жертвует конфиденциальность). Хотя модели с открытым исходным кодом не могут полностью конкурировать с коммерческими моделями уровня GPT-4, вы можете сделать агенты преуспеть, используя различные модели в соответствии с их сильными и слабыми сторонами. Для получения подробной информации, пожалуйста, обратитесь к использованию разных моделей в разных агентах.
Claude-3-5-Sonnet-201240620 обеспечивает наилучшую производительность.
GPT-4O и GPT-4-1106-Preview также предлагают производительность высшего уровня. Но из -за долгого времени агента и большого потребления токенов, пожалуйста, используйте коммерческие модели с осторожностью. GPT-4O-Mini работает очень хорошо, и, хотя он не является первоклассным, ее низкая цена делает эту модель очень привлекательной. GPT-4-Turbo / GPT-3.5-Turbo удивительно ленив, и мы никогда не смогли найти стабильное быстрое выражение.
Среди моделей с открытым исходным кодом, те, которые обычно работают хорошо, включают:
Meta-Llama-3.1-405B-Instruct хороша, но слишком большая, чтобы быть практичным на ПК.
Для пользователей, чьи аппаратные возможности недостаточны для запуска моделей с открытым исходным кодом локально, и которые не могут получить клавиши API для коммерческих моделей, они могут попробовать следующие варианты:
OpenRouter Эта услуга может направлять ваши запросы на вывод на различные модели с открытым исходным кодом или коммерческие модели без необходимости развертывания моделей с открытым исходным кодом или подавать заявку на ключи API для различных коммерческих моделей. Это фантастический выбор. Ailice автоматически поддерживает все модели в OpenRouter. Вы можете выбрать Autorouter: OpenRouter/Auto, чтобы Autorouter автоматически направлялся для вас, или вы можете указать любую конкретную модель, настроенную в файле config.json. Спасибо @babybirdprd за рекомендацию OpenRouter мне.
GROQ: Llama3-70B-8192 Конечно, Ailice также поддерживает другие модели под Groq. Одна из проблем с запуском под Groq заключается в том, что его легко превышать ограничения по скорости, поэтому его можно использовать только для простых экспериментов.
Мы выберем современную модель с открытым исходным кодом в настоящее время, чтобы предоставить ссылку для пользователей моделей с открытым исходным кодом.
Лучшее среди всех моделей: QWEN-2-72B-Instruct . Это первая модель с открытым исходным кодом с практической ценностью . Это отличное продвижение! У него есть возможности рассуждений, близкие к GPT-4, хотя еще не совсем там. При активном пользовательском вмешательстве с помощью функции прерывания можно успешно выполнить гораздо более сложные задачи.
Вторые лучшие модели выполнения: Mixtral-8x22b-Instruct и Meta-Llama/Meta-Llama-3-70B-Instruct . Стоит отметить, что модели серии Llama3, похоже, демонстрируют значительное падение производительности после квантования, что снижает их практическую ценность. Вы можете использовать их с Groq.
Если вы найдете лучшую модель, пожалуйста, дайте мне знать.
Для продвинутых игроков неизбежно попробовать больше моделей. К счастью, этого не сложно достичь.
Для моделей Openai/Mistral/Anpropic/Groq вам не нужно ничего делать. Просто используйте модель, состоящую из официального имени модели, добавленного к префиксу «oai:»/«mistral:»/«antropic:»/«groq:». Если вам нужно использовать модель, которая не включена в списки поддерживаемого Dielice, вы можете разрешить это, добавив запись для этой модели в файле config.json. Метод для добавления является непосредственной ссылкой на запись аналогичной модели, изменить контекст -WINDOW до фактического значения, сохранить системную систему в соответствии с аналогичной моделью и установить ARGS на пустой DICT.
Вы можете использовать любой сторонний сервер вывода, совместимый с API OpenAI, чтобы заменить встроенную функцию вывода LLM в Dielice. Просто используйте тот же формат конфигурации, что и модели OpenAI, и измените BaseUrl, Apikey, ContextWindow и другие параметры (на самом деле, именно так AILICE поддерживает модели GROQ).
Для серверов вывода, которые не поддерживают API OpenAI, вы можете попробовать использовать Litellm для преобразования их в API-совместимый с OpenAI (у нас есть пример ниже).
Важно отметить, что из -за наличия многих системных сообщений в записях разговоров Dielice, что не является общим вариантом использования для LLM, уровень поддержки для этого зависит от конкретной реализации этих серверов вывода. В этом случае вы можете установить параметр SystemAsuser на True, чтобы обойти проблему. Хотя это может помешать модели запускать Ailice при оптимальной производительности, она также позволяет нам совместимы с различными эффективными серверами вывода. Для среднего пользователя преимущества перевешивают недостатки.
Мы используем Ollama в качестве примера, чтобы объяснить, как добавить поддержку для таких услуг. Во -первых, нам нужно использовать Litellm для преобразования интерфейса Ollama в формат, совместимый с OpenAI.
pip install litellm
ollama pull mistral-openorca
litellm --model ollama/mistral-openorca --api_base http://localhost:11434 --temperature 0.0 --max_tokens 8192Затем добавьте поддержку этой службы в файле config.json (местоположение этого файла будет вызвана при запуске Ailice).
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"ollama" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fake-key " ,
"baseURL" : " http://localhost:8000 " ,
"modelList" : {
"mistral-openorca" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 8192 ,
"systemAsUser" : false ,
"args" : {}
}
}
},
...
},
...
}Теперь мы можем запустить AILICE:
ailice_web --modelID=ollama:mistral-openorcaВ этом примере мы будем использовать LM Studio для запуска самой модели с открытым исходным кодом, которую я когда-либо видел: QWEN2-72B-Instruct-Q3_K_S.GGUF , питающий AILICE для работы на локальной машине.
Загрузите веса модели QWEN2-72B-Instruct-Q3_K_S.GGUF с использованием LM Studio.
В окне LM Studio "LocalServer" установите N_GPU_Layers на -1, если вы хотите использовать только графический процессор. Отрегулируйте параметр «длины контекста» слева до 16384 (или меньшее значение, основанное на вашей доступной памяти), и измените «Политику переполнения контекста», чтобы «сохранить системную подсказку и первое сообщение пользователя, усечение среднего».
Запустить сервис. Мы предполагаем, что адрес службы: http: // localhost: 1234/v1/».
Затем мы открываем config.json и делаем следующие изменения:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"qwen2-72b" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 32764 ,
"systemAsUser" : true ,
"args" : {}
}
}
},
...
},
...
}Наконец, бегите по делу. Вы можете настроить параметр «ContextWindowRatio» на основе вашего доступного VRAM или пространства памяти. Чем больше параметр, тем больше места VRAM требуется.
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5Подобно тому, что мы сделали в предыдущем разделе, после того, как мы используем LM Studio для загрузки и запуска Llava, мы изменяем файл конфигурации следующим образом:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"llava-1.6-34b" : {
"formatter" : " AFormatterGPTVision " ,
"contextWindow" : 4096 ,
"systemAsUser" : true ,
"args" : {}
}
},
},
...
},
...
}Тем не менее, следует отметить, что текущая мультимодальная модель с открытым исходным кодом далеко не достаточна для выполнения задач агента, поэтому этот пример предназначен для разработчиков, а не для пользователей.
Для моделей с открытым исходным кодом на Huggingface вам нужно только знать следующую информацию, чтобы добавить поддержку новых моделей: адрес huggingface модели, формат приглашения модели и длину окна контекста. Обычно одной строки кода достаточно, чтобы добавить новую модель, но иногда вам не повезло, и вам нужно около дюжины строк кода.
Вот полный метод добавления новой поддержки LLM:
Откройте config.json, вы должны добавить конфигурацию нового LLM в модели.hf.modellist, которая выглядит следующим образом:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"hf" : {
"modelWrapper" : " AModelCausalLM " ,
"modelList" : {
"meta-llama/Llama-2-13b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
"meta-llama/Llama-2-70b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
...
}
},
...
}
...
}«Форматтер» - это класс, который определяет формат быстрого подсказования LLM. Вы можете найти их определения в Core/LLM/PARMATTER. Вы можете прочитать эти коды, чтобы определить, какой формат требуется для модели, которую вы хотите добавить. Если вы не найдете его, вам нужно написать его самостоятельно. К счастью, Форматтер - очень простая вещь и может быть завершена в более чем дюжине строк кода. Я считаю, что вы поймете, как это сделать после прочтения нескольких исходных кодов форматирования.
Контекстное окно - это свойство, которое обычно имеет LLM архитектуры трансформатора. Он определяет длину текста, которую модель может обрабатывать за один раз. Вам необходимо установить окно контекста новой модели на ключ "ContextWindow".
«SystemAsuser»: мы используем роль «системы» в качестве отправителя сообщения, возвращаемого функциональными вызовами. Тем не менее, не все LLM имеют четкое определение роли системы, и нет никакой гарантии, что LLM может адаптироваться к этому подходу. Таким образом, нам нужно использовать SystemAsuser, чтобы установить, можно ли установить текст, возвращаемый функцией вызовов в сообщения пользователя. Попробуйте сначала установить его на ложь.
Все сделано! Используйте «HF:» в качестве префикса к имени модели, чтобы сформировать модель, и используйте модель новой модели в качестве параметра команды, чтобы запустить Dielice!
Ailice имеет два режима эксплуатации. В одном режиме используется один LLM для управления всеми агентами, в то время как другой позволяет каждому типу агента указать соответствующий LLM. Последний режим позволяет нам лучше объединить возможности моделей с открытым исходным кодом и коммерческих моделей, достигая лучшей производительности за более низкую стоимость. Чтобы использовать второй режим, вам необходимо настроить элемент AgentModelConfig в config.json Сначала:
"modelID" : " " ,
"agentModelConfig" : {
"DEFAULT" : " openrouter:qwen/qwen-2-72b-instruct " ,
"coder" : " openrouter:deepseek/deepseek-coder "
},Сначала убедитесь, что значение по умолчанию для ModelID установлено на пустую строку, а затем настройте соответствующий LLM для каждого типа агента в AgentModelConfig.
Наконец, вы можете достичь второго режима работы, не указав модель:
ailice_webОсновными принципами при разработке AILICE являются:
Давайте кратко объясним эти фундаментальные принципы.
Начиная с наиболее очевидного уровня, очень динамичная строительная конструкция позволяет агенту попасть в петлю. Приток новых переменных из внешней среды непрерывно влияет на LLM, помогая ему избежать этой ловушки. Кроме того, кормление LLM со всей доступной в настоящее время информацией может значительно улучшить ее выпуск. For example, in automated programming, error messages from interpreters or command lines assist the LLM in continuously modifying the code until the correct result is achieved. Lastly, in dynamic prompt construction, new information in the prompts may also come from other agents, which acts as a form of linked inference computation, making the system's computational mechanisms more complex, varied, and capable of producing richer behaviors.
Separating computational tasks is, from a practical standpoint, due to our limited context window. We cannot expect to complete a complex task within a window of a few thousand tokens. If we can decompose a complex task so that each subtask is solved within limited resources, that would be an ideal outcome. In traditional computing models, we have always taken advantage of this, but in new computing centered around LLMs, this is not easy to achieve. The issue is that if one subtask fails, the entire task is at risk of failure. Recursion is even more challenging: how do you ensure that with each call, the LLM solves a part of the subproblem rather than passing the entire burden to the next level of the call? We have solved the first problem with the IACT architecture in Ailice, and the second problem is theoretically not difficult to solve, but it likely requires a smarter LLM.
The third principle is what everyone is currently working on: having multiple intelligent agents interact and cooperate to complete more complex tasks. The implementation of this principle actually addresses the aforementioned issue of subtask failure. Multi-agent collaboration is crucial for the fault tolerance of agents in operation. In fact, this may be one of the biggest differences between the new computational paradigm and traditional computing: traditional computing is precise and error-free, assigning subtasks only through unidirectional communication (function calls), whereas the new computational paradigm is error-prone and requires bidirectional communication between computing units to correct errors. This will be explained in detail in the following section on the IACT framework.
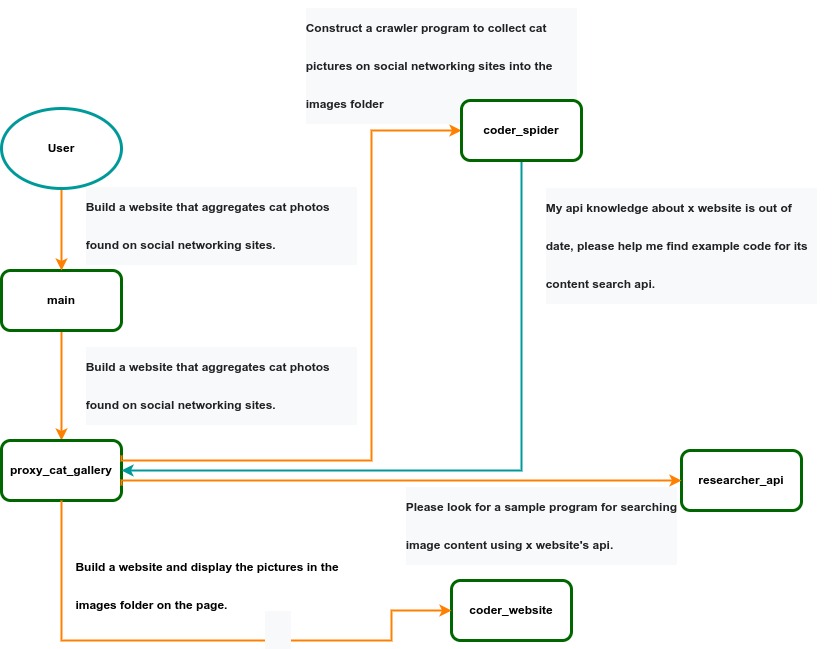 IACT Architecture Diagram. A user requirement to build a page for image collection and display is dynamically decomposed into two tasks: coder_spider and coder_website. When coder_spider encounters difficulties, it proactively seeks assistance from its caller, proxy_cat_gallery. Proxy_cat_gallery then creates another agent, researcher_api, and employs it to address the issue.
IACT Architecture Diagram. A user requirement to build a page for image collection and display is dynamically decomposed into two tasks: coder_spider and coder_website. When coder_spider encounters difficulties, it proactively seeks assistance from its caller, proxy_cat_gallery. Proxy_cat_gallery then creates another agent, researcher_api, and employs it to address the issue.
Ailice can be regarded as a computer powered by a LLM , and its features include:
Representing input, output, programs, and data in text form.
Using LLM as the processor.
Breaking down computational tasks through successive calls to basic computing units (analogous to functions in traditional computing), which are essentially various functional agents.
Therefore, user-input text commands are executed as a kind of program, decomposed into various "subprograms", and addressed by different agents , forming the fundamental architecture of Ailice. In the following, we will provide a detailed explanation of the nature of these basic computing units.
A natural idea is to let LLM solve certain problems (such as information retrieval, document understanding, etc.) through multi-round dialogues with external callers and peripheral modules in the simplest computational unit. We temporarily call this computational unit a "function". Then, by analogy with traditional computing, we allow functions to call each other, and finally add the concept of threads to implement multi-agent interaction. However, we can have a much simpler and more elegant computational model than this.
The key here is that the "function" that wraps LLM reasoning can actually be called and returned multiple times. A "function" with coder functionality can pause work and return a query statement to its caller when it encounters unclear requirements during coding. If the caller is still unclear about the answer, it continues to ask the next higher level caller. This process can even go all the way to the final user's chat window. When new information is added, the caller will reactivate the coder's execution process by passing in the supplementary information. It can be seen that this "function" is not a traditional function, but an object that can be called multiple times. The high intelligence of LLM makes this interesting property possible. You can also see it as agents strung together by calling relationships, where each agent can create and call more sub-agents, and can also dialogue with its caller to obtain supplementary information or report its progress . In Ailice, we call this computational unit "AProcessor" (essentially what we referred to as an agent). Its code is located in core/AProcessor.py.
Next, we will elaborate on the structure inside AProcessor. The interior of AProcessor is a multi-round dialogue. The "program" that defines the function of AProcessor is a prompt generation mechanism, which generates the prompt for each round of dialogue from the dialogue history. The dialogue is one-to-many. After the external caller inputs the request, LLM will have multiple rounds of dialogue with the peripheral modules (we call them SYSTEM), LLM outputs function calls in various grammatical forms, and the system calls the peripheral modules to generate results and puts the results in the reply message. LLM finally gets the answer and responds to the external caller, ending this call. But because the dialogue history is still preserved, the caller can call in again to continue executing more tasks.
The last part we want to introduce is the parsing module for LLM output. In fact, we regard the output text of LLM as a "script" of semi-natural language and semi-formal language, and use a simple interpreter to execute it . We can use regular expressions to express a carefully designed grammatical structure, parse it into a function call and execute it. Under this design, we can design more flexible function call grammar forms, such as a section with a certain fixed title (such as "UPDATE MEMORY"), which can also be directly parsed out and trigger the execution of an action. This implicit function call does not need to make LLM aware of its existence, but only needs to make it strictly follow a certain format convention. For the most hardcore possibility, we have left room. The interpreter here can not only use regular expressions for pattern matching, its Eval function is recursive. We don't know what this will be used for, but it seems not bad to leave a cool possibility, right? Therefore, inside AProcessor, the calculation is alternately completed by LLM and the interpreter, their outputs are each other's inputs, forming a cycle.
In Ailice, the interpreter is one of the most crucial components within an agent. We use the interpreter to map texts from the LLM output that match specific patterns to actions, including function calls, variable definitions and references, and any user-defined actions. Sometimes these actions directly interact with peripheral modules, affecting the external world; other times, they are used to modify the agent's internal state, thereby influencing its future prompts.
The basic structure of the interpreter is straightforward: a list of pattern-action pairs. Patterns are defined by regular expressions, and actions are specified by a Python function with type annotations. Given that syntactic structures can be nested, we refer to the overarching structure as the entry pattern. During runtime, the interpreter actively detects these entry patterns in the LLM output text. Upon detecting an entry pattern (and if the corresponding action returns data), it immediately terminates the LLM generation to execute the relevant action.
The design of agents in Ailice encompasses two fundamental aspects: the logic for generating prompts based on dialogue history and the agent's internal state, and a set of pattern-action pairs. Essentially, the agent implements the interpreter framework with a set of pattern-action pairs; it becomes an integral part of the interpreter. The agent's internal state is one of the targets for the interpreter's actions, with changes to the agent's internal state influencing the direction of future prompts.
Generating prompts from dialogue history and the internal state is nearly a standardized process, although developers still have the freedom to choose entirely different generation logic. The primary challenge for developers is to create a system prompt template, which is pivotal for the agent and often demands the most effort to perfect. However, this task revolves entirely around crafting natural language prompts.
Ailice utilizes a simple scripting language embedded within text to map the text-based capabilities of LLMs to the real world. This straightforward scripting language includes non-nested function calls and mechanisms for creating and referencing variables, as well as operations for concatenating text content . Its purpose is to enable LLMs to exert influence on the world more naturally: from smoother text manipulation abilities to simple function invocation mechanisms, and multimodal variable operation capabilities. Finally, it should be noted that for the designers of agents, they always have the freedom to extend new syntax for this scripting language. What is introduced here is a minimal standard syntax structure.
The basic syntax is as follows:
Variable Definition: VAR_NAME := <!|"SOME_CONTENT"|!>
Function Calls/Variable References/Text Concatenation: !FUNC-NAME<!|"...", '...', VAR_NAME1, "Execute the following code: n" + VAR_NAME2, ...|!>
The basic variable types are str/AImage/various multimodal types. The str type is consistent with Python's string syntax, supporting triple quotes and escape characters.
This constitutes the entirety of the embedded scripting language.
The variable definition mechanism introduces a way to extend the context window, allowing LLMs to record important content into variables to prevent forgetting. During system operation, various variables are automatically defined. For example, if a block of code wrapped in triple backticks is detected within a text message, a variable is automatically created to store the code, enabling the LLM to reference the variable to execute the code, thus avoiding the time and token costs associated with copying the code in full. Furthermore, some module functions may return data in multimodal types rather than text. In such cases, the system automatically defines these as variables of the corresponding multimodal type, allowing the LLM to reference them (the LLM might send them to another module for processing).
In the long run, LLMs are bound to evolve into multimodal models capable of seeing and hearing. Therefore, the exchanges between Ailice's agents should be in rich text , not just plain text. While Markdown provides some capability for marking up multimodal content, it is insufficient. Hence, we will need an extended version of Markdown in the future to include various embedded multimodal data such as videos and audio.
Let's take images as an example to illustrate the multimodal mechanism in Ailice. When agents receive text containing Markdown-marked images, the system automatically inputs them into a multimodal model to ensure the model can see these contents. Markdown typically uses paths or URLs for marking, so we have expanded the Markdown syntax to allow the use of variable names to reference multimodal content.
Another minor issue is how different agents with their own internal variable lists exchange multimodal variables. This is simple: the system automatically checks whether a message sent from one agent to another contains internal variable names. If it does, the variable content is passed along to the next agent.
Why do we go to the trouble of implementing an additional multimodal variable mechanism when marking multimodal content with paths and URLs is much more convenient? This is because marking multimodal content based on local file paths is only feasible when Ailice runs entirely in a local environment, which is not the design intent. Ailice is meant to be distributed, with the core and modules potentially running on different computers, and it might even load services running on the internet to provide certain computations. This makes returning complete multimodal data more attractive. Of course, these designs made for the future might be over-engineering, and if so, we will modify them in the future.
One of the goals of Ailice is to achieve introspection and self-expansion (which is why our logo features a butterfly with its reflection in the water). This would enable her to understand her own code and build new functionalities, including new external interaction modules (ie new functions) and new types of agents (APrompt class) . As a result, the knowledge and capabilities of LLMs would be more thoroughly unleashed.
Implementing self-expansion involves two parts. On one hand, new modules and new types of agents (APrompt class) need to be dynamically loaded during runtime and naturally integrated into the computational system to participate in processing, which we refer to as dynamic loading. On the other hand, Ailice needs the ability to construct new modules and agent types.
The dynamic loading mechanism itself is of great significance: it represents a novel software update mechanism . We can allow Ailice to search for its own extension code on the internet, check the code for security, fix bugs and compatibility issues, and ultimately run the extension as part of itself. Therefore, Ailice developers only need to place their contributed code on the internet, without the need to merge into the main codebase or consider any other installation methods. The implementation of the dynamic loading mechanism is continuously improving. Its core lies in the extension packages providing some text describing their functions. During runtime, each agent in Ailice finds suitable functions or agent types to solve sub-problems for itself through semantic matching and other means.
Building new modules is a relatively simple task, as the interface constraints that modules need to meet are very straightforward. We can teach LLMs to construct new modules through an example. The more complex task is the self-construction of new agent types (APrompt class), which requires a good understanding of Ailice's overall architecture. The construction of system prompts is particularly delicate and is a challenging task even for humans. Therefore, we pin our hopes on more powerful LLMs in the future to achieve introspection, allowing Ailice to understand herself by reading her own source code (for something as complex as a program, the best way to introduce it is to present itself), thereby constructing better new agents .
For developing Agents, the main loop of Ailice is located in the AiliceMain.py or ui/app.py files. To further understand the construction of an agent, you need to read the code in the "prompts" folder, by reading these code you can understand how an agent's prompts are dynamically constructed.
For developers who want to understand the internal operation logic of Ailice, please read core/AProcessor.py and core/Interpreter.py. These two files contain approximately three hundred lines of code in total, but they contain the basic framework of Ailice.
In this project, achieving the desired functionality of the AI Agent is the primary goal. The secondary goal is code clarity and simplicity . The implementation of the AI Agent is still an exploratory topic, so we aim to minimize rigid components in the software (such as architecture/interfaces imposing constraints on future development) and provide maximum flexibility for the application layer (eg, prompt classes) . Abstraction, deduplication, and decoupling are not immediate priorities.
When implementing a feature, always choose the best method rather than the most obvious one . The metric for "best" often includes traits such as trivializing the problem from a higher perspective, maintaining code clarity and simplicity, and ensuring that changes do not significantly increase overall complexity or limit the software's future possibilities.
Adding comments is not mandatory unless absolutely necessary; strive to make the code clear enough to be self-explanatory . While this may not be an issue for developers who appreciate comments, in the AI era, we can generate detailed code explanations at any time, eliminating the need for unstructured, hard-to-maintain comments.
Follow the principle of Occam's razor when adding code; never add unnecessary lines .
Functions or methods in the core should not exceed 60 lines .
While there are no explicit coding style constraints, maintain consistency or similarity with the original code in terms of naming and case usage to avoid readability burdens.
Ailice aims to achieve multimodal and self-expanding features within a scale of less than 5000 lines, reaching its final form at the current stage. The pursuit of concise code is not only because succinct code often represents a better implementation, but also because it enables AI to develop introspective capabilities early on and facilitates better self-expansion. Please adhere to the above rules and approach each line of code with diligence.
Ailice's fundamental tasks are twofold: one is to fully unleash the capabilities of LLM based on text into the real world; the other is to explore better mechanisms for long-term memory and forming a coherent understanding of vast amounts of text . Our development efforts revolve around these two focal points.
If you are interested in the development of Ailice itself, you may consider the following directions:
Explore improved long-term memory mechanisms to enhance the capabilities of each Agent. We need a long-term memory mechanism that enables consistent understanding of large amounts of content and facilitates association . The most feasible option at the moment is to replace vector database with knowledge graph, which will greatly benefit the comprehension of long texts/codes and enable us to build genuine personal AI assistants.
Multimodal support. The support for the multimodal model has been completed, and the current development focus is shifting towards the multimodal support of peripheral modules. We need a module that operates computers based on screenshots and simulates mouse/keyboard actions.
Self-expanding support. Our goal is to enable language models to autonomously code and implement new peripheral modules/agent types and dynamically load them for immediate use . This capability will enable self-expansion, empowering the system to seamlessly integrate new functionalities. We've completed most of the functionality, but we still need to develop the capability to construct new types of agents.
Richer UI interface . We need to organize the agents output into a tree structure in dialog window and dynamically update the output of all agents. And accept user input on the web interface and transfer it to scripter's standard input, which is especially needed when using sudo.
Develop Agents with various functionalities based on the current framework.
Explore the application of IACT architecture on complex tasks. By utilizing an interactive agents call tree, we can break down large documents for improved reading comprehension, as well as decompose complex software engineering tasks into smaller modules, completing the entire project build and testing through iterations. This requires a series of intricate prompt designs and testing efforts, but it holds an exciting promise for the future. The IACT architecture significantly alleviates the resource constraints imposed by the context window, allowing us to dynamically adapt to more intricate tasks.
Build rich external interaction modules using self-expansion mechanisms! This will be accomplished in AiliceEVO.
In addition to the tasks mentioned above, we should also start actively contemplating the possibility of creating a smaller LLM that possesses lower knowledge content but higher reasoning abilities .


