AIlice
1.0.0

Mulai Cepat • Demo • Pengembangan • Twitter • Reddit
22 Jun 2024: Kami telah memasuki era asisten AI seperti Jarvis yang menjalankan secara lokal! LLM open-source terbaru memungkinkan kami untuk melakukan tugas-tugas kompleks secara lokal! Klik di sini untuk mempelajari lebih lanjut.
Ailice adalah agen AI yang sepenuhnya otonom dan serba guna . Proyek ini bertujuan untuk menciptakan asisten kecerdasan buatan mandiri, mirip dengan Jarvis, berdasarkan LLM sumber terbuka. Ailice mencapai tujuan ini dengan membangun "komputer teks" yang menggunakan model bahasa besar (LLM) sebagai prosesor intinya. Saat ini, Ailice menunjukkan kemahiran dalam berbagai tugas, termasuk penelitian tematik, pengkodean, manajemen sistem, tinjauan literatur, dan tugas hibrida kompleks yang melampaui kemampuan dasar ini.
Ailice telah mencapai kinerja yang hampir sempurna dalam tugas sehari-hari menggunakan GPT-4 dan membuat langkah menuju aplikasi praktis dengan model open-source terbaru.
Kami pada akhirnya akan mencapai evolusi diri agen AI . Artinya, agen AI akan secara mandiri membangun ekspansi fitur mereka sendiri dan jenis agen baru, melepaskan pengetahuan dan kemampuan penalaran LLM ke dunia nyata dengan mulus.
Untuk memahami kemampuan Ailice saat ini, tonton video berikut:
Fitur teknis utama Ailice meliputi:
Instal dan jalankan ailice dengan perintah berikut. Setelah Ailice diluncurkan, gunakan browser untuk membuka halaman web yang disediakannya, antarmuka dialog akan muncul. Masalah perintah ke Ailice melalui percakapan untuk menyelesaikan berbagai tugas. Untuk penggunaan pertama Anda, Anda dapat mencoba perintah yang disediakan dalam hal -hal keren yang dapat kami lakukan untuk dengan cepat terbiasa.
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2Mari kita daftarkan beberapa kasus penggunaan yang khas. Saya sering menggunakan contoh -contoh ini untuk menguji Ailice selama pengembangan, memastikan kinerja yang stabil. Namun, bahkan dengan tes ini, hasil eksekusi dipengaruhi oleh model yang dipilih, versi kode, dan bahkan waktu pengujian. (GPT-4 mungkin mengalami penurunan kinerja di bawah beban tinggi. Beberapa faktor acak juga dapat menyebabkan hasil yang berbeda dari menjalankan model beberapa kali. Kadang-kadang LLM melakukan dengan sangat cerdas, tetapi di lain waktu tidak) juga, Ailice adalah agen Berdasarkan kerja sama multi-agen, dan sebagai pengguna, Anda juga salah satu "agen". Oleh karena itu, ketika Ailice membutuhkan informasi tambahan, ia akan mencari masukan dari Anda, dan ketelitian detail Anda sangat penting untuk keberhasilannya. Selain itu, jika eksekusi tugas gagal, Anda dapat membimbingnya ke arah yang benar, dan dia akan memperbaiki pendekatannya.
Poin terakhir yang perlu diperhatikan adalah bahwa Ailice saat ini tidak memiliki mekanisme kontrol waktu lari, jadi dia mungkin terjebak dalam loop atau dijalankan untuk waktu yang lama. Saat menggunakan LLM komersial, Anda perlu memantau operasinya dengan cermat.
"Tolong daftarkan isi direktori saat ini."
"Temukan catatan kuliah QFT David Tong dan unduh ke folder" Fisika "di direktori saat ini. Anda mungkin perlu membuat folder terlebih dahulu."
"Menyebarkan situs web langsung pada mesin ini menggunakan kerangka flask. Pastikan aksesibilitas di 0,0.0.0:59001. Situs web harus memiliki satu halaman yang mampu menampilkan semua gambar yang terletak di direktori 'gambar'." Yang ini sangat menarik. Kita tahu bahwa menggambar tidak dapat dilakukan di lingkungan Docker, dan semua output file yang kami hasilkan perlu disalin menggunakan perintah "Docker CP" untuk melihatnya. Tetapi Anda dapat membiarkan ailice menyelesaikan masalah ini dengan sendirinya: Menyebarkan situs web dalam wadah sesuai dengan prompt di atas (disarankan untuk menggunakan port antara 59001 dan 59200 yang telah dipetakan port), gambar dalam direktori akan ditampilkan secara otomatis pada secara otomatis halaman web. Dengan cara ini, Anda dapat secara dinamis melihat konten gambar yang dihasilkan pada host. Anda juga dapat mencoba membiarkannya beralih untuk menghasilkan fungsi yang lebih kompleks. Jika Anda tidak melihat gambar apa pun di halaman, silakan periksa apakah folder "gambar" situs web berbeda dari folder "gambar" di sini (misalnya, mungkin di bawah "statis/gambar").
"Silakan gunakan pemrograman Python untuk menyelesaikan tugas-tugas berikut: dapatkan data harga BTC-USDT selama enam bulan dan menariknya ke dalam grafik, dan simpan di direktori 'gambar'." Jika Anda berhasil menggunakan situs web di atas, Anda sekarang dapat melihat kurva harga BTC secara langsung di halaman.
"Temukan proses di port 59001 dan hentikan." Ini akan mengakhiri program layanan situs web yang baru saja ditetapkan.
"Silakan gunakan Cadquery untuk mengimplementasikan cangkir." Ini juga merupakan upaya yang sangat menarik. Cadquery adalah paket Python yang menggunakan pemrograman Python untuk pemodelan CAD. Kami mencoba menggunakan Ailice untuk secara otomatis membangun model 3D! Ini dapat memberi kita sekilas tentang bagaimana intuisi geometris yang matang dalam pandangan dunia LLM. Tentu saja, setelah menerapkan dukungan multimodal, kami dapat memungkinkan Ailice untuk melihat model yang ia buat, memungkinkan penyesuaian lebih lanjut dan membangun loop umpan balik yang sangat efektif. Dengan cara ini, dimungkinkan untuk mencapai pemodelan 3D yang dikendalikan bahasa yang benar-benar dapat digunakan.
"Silakan cari di internet untuk 100 tutorial di berbagai cabang fisika dan unduh file PDF yang Anda temukan ke folder bernama 'Fisika'. Tidak perlu memverifikasi konten PDF, kami hanya perlu koleksi kasar untuk saat ini." Memanfaatkan Ailice untuk mencapai pengumpulan dan konstruksi set data otomatis adalah salah satu tujuan kami yang berkelanjutan. Saat ini, peneliti yang dipekerjakan untuk fungsi ini masih memiliki beberapa kekurangan, tetapi sudah mampu memberikan beberapa hasil yang menarik.
"Harap lakukan penyelidikan pada alat OPR open-source PDF OCR, dengan fokus pada mereka yang mampu mengenali formula matematika dan mengubahnya menjadi kode lateks. Konsolidasikan temuan menjadi laporan."
1. Temukan video kuliah Feynmann di YouTube dan unduh ke Feynmann/ Subdir. Anda perlu membuat folder terlebih dahulu. 2. Ekstrak audio dari video ini dan simpan ke Feynmann/audio. 3. Konversi file audio ini ke teks dan gabungkan menjadi dokumen teks. Anda harus terlebih dahulu pergi ke memeluk wajah dan menemukan halaman untuk Whisper-Large-V3, menemukan kode contoh, dan merujuk ke kode sampel untuk menyelesaikannya. 4. Temukan jawaban untuk pertanyaan ini dari file teks yang baru saja Anda ekstrak: Mengapa kami membutuhkan antipartikel? Ini adalah tugas berbasis prompt multi-langkah di mana Anda perlu berinteraksi dengan Ailice langkah demi langkah untuk menyelesaikan tugas. Secara alami, mungkin ada peristiwa tak terduga di sepanjang jalan, jadi Anda harus menjaga komunikasi yang baik dengan Ailice untuk menyelesaikan masalah apa pun yang Anda temui ( menggunakan tombol "interupsi" untuk mengganggu Ailice kapan saja dan memberikan prompt adalah pilihan yang baik! ). Akhirnya, berdasarkan konten video yang diunduh, Anda dapat mengajukan pertanyaan terkait fisika. Setelah Anda menerima jawabannya, Anda dapat melihat ke belakang dan melihat seberapa jauh Anda berkumpul.
1. Gunakan SDXL untuk menghasilkan gambar "kucing oranye gemuk". Anda perlu menemukan kode sampel di halaman Huggingface sebagai referensi untuk menyelesaikan pemrograman dan pekerjaan pembuatan gambar. Simpan gambar ke direktori saat ini dan tampilkan. 2. Sekarang mari kita terapkan situs web satu halaman. Fungsi halaman web adalah untuk mengonversi deskripsi teks yang dimasukkan oleh pengguna menjadi gambar dan menampilkannya. Lihat kode teks-ke-gambar dari sebelumnya. Situs web berjalan di 127.0.0.1:59102. Simpan kode ke ./image_gen sebelum Anda menjalankannya; Anda mungkin perlu membuat folder terlebih dahulu.
"Silakan tulis modul ext. Fungsi modul adalah untuk mendapatkan konten halaman terkait pada wiki melalui kata kunci." Ailice dapat membangun modul interaksi eksternal (kami menyebutnya Ext-modules) sendirian, sehingga memberinya dengan ekstensibilitas tanpa batas. Yang diperlukan hanyalah beberapa petunjuk dari Anda. Setelah modul dibangun, Anda dapat menginstruksikan Ailice dengan mengatakan, "Harap muat modul wiki yang baru diimplementasikan dan gunakan untuk meminta entri pada relativitas."
Agen perlu berinteraksi dengan berbagai aspek lingkungan sekitarnya, lingkungan operasinya seringkali lebih kompleks daripada perangkat lunak khas. Butuh waktu lama bagi kita untuk menginstal dependensi, tetapi untungnya, ini pada dasarnya dilakukan secara otomatis.
Untuk menjalankan Ailice, Anda perlu memastikan bahwa Chrome dipasang dengan benar. Jika Anda perlu menjalankan kode di lingkungan virtual yang aman, Anda juga perlu menginstal Docker .
Jika Anda ingin menjalankan ailice di mesin virtual, pastikan Hyper-V dimatikan (jika tidak llama.cpp tidak dapat diinstal). Dalam lingkungan VirtualBox, Anda dapat menonaktifkannya dengan mengikuti langkah-langkah ini: Nonaktifkan PAE/NX dan VT-X/AMD-V (Hyper-V) pada pengaturan VirtualBox untuk VM. Atur antarmuka paravirtualisasi ke default, nonaktifkan paging bersarang.
Anda dapat menggunakan perintah berikut untuk menginstal ailice (sangat disarankan untuk menggunakan alat seperti Conda untuk membuat lingkungan virtual baru untuk menginstal ailice, sehingga menghindari konflik ketergantungan):
git clone https://github.com/myshell-ai/AIlice.git
cd AIlice
pip install -e .Ailice yang diinstal secara default akan berjalan perlahan karena menggunakan CPU sebagai perangkat keras inferensi dari modul memori jangka panjang. Oleh karena itu, sangat disarankan untuk memasang dukungan akselerasi GPU:
ailice_turboUntuk pengguna yang perlu menggunakan fungsi HuggingFace Model/Voice Dialogoge/Model Fine-Tuning/PDF, Anda dapat menggunakan salah satu dari perintah berikut (menginstal terlalu banyak fitur meningkatkan kemungkinan konflik ketergantungan, jadi disarankan untuk menginstal hanya bagian yang diperlukan):
pip install -e .[huggingface]
pip install -e .[speech]
pip install -e .[finetuning]
pip install -e .[pdf-reading]Anda dapat menjalankan Ailice sekarang! Gunakan perintah dalam penggunaan.
Secara default, modul Google di Ailice dibatasi, dan penggunaan berulang dapat menyebabkan kesalahan yang membutuhkan waktu untuk menyelesaikannya. Ini adalah kenyataan canggung di era AI; Mesin pencari tradisional hanya memungkinkan akses ke pengguna asli, dan agen AI saat ini tidak termasuk dalam kategori 'pengguna asli'. Meskipun kami memiliki solusi alternatif, mereka semua membutuhkan mengkonfigurasi kunci API, yang menetapkan penghalang tinggi untuk masuk untuk pengguna biasa. Namun, untuk pengguna yang sering membutuhkan akses ke Google, saya berasumsi Anda akan bersedia untuk mengalami kerumitan mengajukan permohonan kunci API resmi Google (kami mengacu pada pencarian kustom JSON API, yang mengharuskan Anda untuk menentukan pencarian seluruh internet di waktu penciptaan) untuk tugas pencarian. Untuk pengguna ini, buka config.json dan gunakan konfigurasi berikut:
{
...
"services": {
...
"google": {
"cmd": "python3 -m ailice.modules.AGoogleAPI --addr=ipc:///tmp/AGoogle.ipc --api_key=YOUR_API_KEY --cse_id=YOUR_CSE_ID",
"addr": "ipc:///tmp/AGoogle.ipc"
},
...
}
}
dan instal Google-API-PYTHON-CLIENT:
pip install google-api-python-clientKemudian cukup restart ailice.
Secara default, eksekusi kode menggunakan lingkungan lokal. Untuk mencegah kesalahan AI potensial yang menyebabkan kerugian yang tidak dapat diubah, disarankan untuk menginstal Docker, membangun wadah, dan memodifikasi file konfigurasi Ailice (Ailice akan menyediakan lokasi file konfigurasi saat startup). Konfigurasikan modul eksekusi kode (ascripter) untuk beroperasi dalam lingkungan virtual.
docker build -t env4scripter .
docker run -d -p 127.0.0.1:59000-59200:59000-59200 --name scripter env4scripterDalam kasus saya, ketika Ailice dimulai, itu memberi tahu saya bahwa file konfigurasi terletak di ~/.config/ailice/config.json, jadi saya memodifikasinya dengan cara berikut
nano ~ /.config/ailice/config.jsonModifikasi "Scripter" di bawah "Layanan":
{
...
"services": {
...
"scripter": {"cmd": "docker start scripter",
"addr": "tcp://127.0.0.1:59000"},
}
}
Sekarang konfigurasi lingkungan telah dilakukan.
Karena status pengembangan AILICE yang sedang berlangsung, memperbarui kode dapat mengakibatkan masalah ketidakcocokan antara file konfigurasi yang ada dan wadah buruh pelabuhan dengan kode baru. Solusi paling menyeluruh untuk skenario ini adalah menghapus file konfigurasi (pastikan untuk menyimpan tombol API apa pun sebelumnya) dan wadah, dan kemudian melakukan instal ulang lengkap. Namun, untuk sebagian besar situasi, Anda dapat mengatasi masalah ini dengan hanya menghapus file konfigurasi dan memperbarui modul ailice di dalam wadah .
rm ~ /.config/ailice/config.json
cd Ailice
docker cp ailice/__init__.py scripter:scripter/ailice/__init__.py
docker cp ailice/common/__init__.py scripter:scripter/ailice/common/__init__.py
docker cp ailice/common/ADataType.py scripter:scripter/ailice/common/ADataType.py
docker cp ailice/common/lightRPC.py scripter:scripter/ailice/common/lightRPC.py
docker cp ailice/modules/__init__.py scripter:scripter/ailice/modules/__init__.py
docker cp ailice/modules/AScripter.py scripter:scripter/ailice/modules/AScripter.py
docker cp ailice/modules/AScrollablePage.py scripter:scripter/ailice/modules/AScrollablePage.py
docker restart scripterAnda dapat secara langsung menyalin perintah dari kasus penggunaan khas di bawah ini untuk menjalankan ailice.
ailice_web --modelID=oai:gpt-4o --contextWindowRatio=0.2
ailice_web --modelID=anthropic:claude-3-5-sonnet-20240620 --contextWindowRatio=0.1
ailice_web --modelID=oai:gpt-4-1106-preview --chatHistoryPath=./chat_history
ailice_web --modelID=anthropic:claude-3-opus-20240229 --prompt= " researcher "
ailice_web --modelID=mistral:mistral-large-latest
ailice_web --modelID=deepseek:deepseek-chat
ailice_web --modelID=hf:Open-Orca/Mistral-7B-OpenOrca --quantization=8bit --contextWindowRatio=0.6
ailice_web --modelID=hf:NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO --quantization=4bit --contextWindowRatio=0.3
ailice_web --modelID=hf:Phind/Phind-CodeLlama-34B-v2 --prompt= " coder-proxy " --quantization=4bit --contextWindowRatio=0.6
ailice_web --modelID=groq:llama3-70b-8192
ailice_web # Use models configured individually for different agents under the agentModelConfig field in config.json.
ailice_web --modelID=openrouter:openrouter/auto
ailice_web --modelID=openrouter:mistralai/mixtral-8x22b-instruct
ailice_web --modelID=openrouter:qwen/qwen-2-72b-instruct
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5Perlu dicatat bahwa kasus penggunaan terakhir mengharuskan Anda untuk mengkonfigurasi layanan inferensi LLM terlebih dahulu, silakan merujuk cara menambahkan dukungan LLM. Menggunakan kerangka kerja inferensi seperti LM Studio dapat menggunakan sumber daya perangkat keras terbatas untuk mendukung model yang lebih besar, memberikan kecepatan inferensi yang lebih cepat dan kecepatan startup ailice yang lebih cepat, membuatnya lebih cocok untuk pengguna biasa.
Saat Anda menjalankannya untuk pertama kalinya, Anda akan diminta untuk memasuki API-Key of Openai. Jika Anda hanya ingin menggunakan Open Source LLM, Anda tidak perlu memasukkannya. Anda juga dapat memodifikasi API-key dengan mengedit file config.json. Harap dicatat bahwa pertama kali saat menggunakan Open Source LLM, perlu waktu lama untuk mengunduh bobot model, pastikan Anda memiliki cukup waktu dan ruang disk.
Saat Anda menyalakan sakelar Pidato untuk pertama kalinya, Anda mungkin perlu menunggu lama di startup. Ini karena bobot pengenalan suara dan model TTS sedang diunduh di latar belakang.
Seperti yang ditunjukkan dalam contoh, Anda dapat menggunakan agen melalui Ailice_web, ini menyediakan antarmuka dialog web. Anda dapat melihat nilai default dari setiap parameter dengan menggunakan
ailice_web --helpNilai default untuk semua argumen baris perintah dapat disesuaikan dengan memodifikasi parameter yang sesuai di config.json.
File konfigurasi ailice bernama config.json, dan lokasinya akan output ke baris perintah saat ailice dimulai. Di bagian ini, kami akan memperkenalkan cara mengkonfigurasi modul interaksi eksternal melalui file konfigurasi.
Di Ailice, kami menggunakan istilah "modul" untuk secara khusus merujuk pada komponen yang menyediakan fungsi untuk berinteraksi dengan dunia eksternal. Setiap modul berjalan sebagai proses independen; Mereka dapat berjalan di lingkungan perangkat lunak atau perangkat keras yang berbeda dari proses inti, membuat ailice mampu didistribusikan. Kami menyediakan serangkaian konfigurasi modul dasar dalam file konfigurasi yang diperlukan untuk operasi Ailice (seperti database vektor, pencarian, browser, eksekusi kode, dll.). Anda juga dapat menambahkan konfigurasi untuk modul pihak ketiga mana pun dan memberikan alamat runtime modul dan port setelah Ailice siap dan berjalan untuk mengaktifkan pemuatan otomatis. Konfigurasi modul sangat sederhana, hanya terdiri dari dua item:
"services" : {
...
"scripter" : { "cmd" : " python3 -m ailice.modules.AScripter --addr=tcp://127.0.0.1:59000 " ,
"addr" : " tcp://127.0.0.1:59000 " },
...
}Di antaranya, di bawah "CMD" adalah baris perintah yang digunakan untuk memulai proses modul. Ketika Ailice dimulai, secara otomatis menjalankan perintah ini untuk meluncurkan modul. Pengguna dapat menentukan perintah apa pun, memberikan fleksibilitas yang signifikan. Anda dapat memulai proses modul secara lokal atau menggunakan Docker untuk memulai proses di lingkungan virtual, atau bahkan memulai proses jarak jauh. Beberapa modul memiliki banyak implementasi (seperti Google/Storage), dan Anda dapat mengonfigurasi di sini untuk beralih ke implementasi lain.
"Addr" mengacu pada alamat dan nomor port dari proses modul. Pengguna mungkin bingung dengan fakta bahwa banyak modul dalam konfigurasi default memiliki "CMD" dan "AddR" yang berisi alamat dan nomor port, menyebabkan redundansi. Ini karena "CMD" dapat, pada prinsipnya, berisi perintah apa pun (yang mungkin termasuk alamat dan nomor port, atau tidak sama sekali). Oleh karena itu, item "addr" terpisah diperlukan untuk memberi tahu Ailice cara mengakses proses modul.
Interupsi. Interupsi adalah mode interaksi kedua yang didukung oleh Ailice, yang memungkinkan Anda untuk mengganggu dan memberikan petunjuk kepada agen Ailice kapan saja untuk memperbaiki kesalahan atau memberikan panduan . Di ailice_web, selama eksekusi tugas Ailice, tombol interupsi muncul di sisi kanan kotak input. Menekannya jeda eksekusi Ailice dan menunggu pesan cepat Anda. Anda dapat memasukkan prompt Anda ke dalam kotak Input dan tekan Enter untuk mengirim pesan ke agen yang saat ini menjalankan subtugas. Penggunaan fitur ini dengan mahir membutuhkan pemahaman yang baik tentang cara kerja Ailice, terutama agen memanggil arsitektur pohon. Ini juga melibatkan lebih banyak fokus pada jendela baris perintah daripada antarmuka dialog selama eksekusi tugas Ailice. Secara keseluruhan, ini adalah fitur yang sangat berguna, terutama pada pengaturan model bahasa yang kurang kuat.
Pertama gunakan GPT-4 untuk berhasil menjalankan beberapa kasus penggunaan sederhana, kemudian restart ailice dengan model yang kurang kuat (tetapi lebih murah/open-source) untuk terus menjalankan tugas baru berdasarkan riwayat percakapan sebelumnya . Dengan cara ini, sejarah yang disediakan oleh GPT-4 berfungsi sebagai contoh yang berhasil, menawarkan referensi berharga untuk model lain dan secara signifikan meningkatkan peluang keberhasilan.
Diperbarui pada 23 Agustus 2024.
Saat ini, Ailice dapat menangani tugas yang lebih kompleks menggunakan model sumber terbuka 72B yang dijalankan secara lokal (QWEN-2-72B-instruct berjalan pada 4090x2) , dengan kinerja mendekati model level GPT-4. Mempertimbangkan biaya rendah model open-source, kami sangat menyarankan pengguna untuk mulai menggunakannya. Selain itu, melokalisasi operasi LLM memastikan perlindungan privasi absolut, kualitas langka dalam aplikasi AI di zaman kita. Klik di sini untuk mempelajari cara menjalankan model ini secara lokal. Untuk pengguna yang kondisi GPU tidak cukup untuk menjalankan model besar, ini bukan masalah. Anda dapat menggunakan layanan inferensi online (seperti OpenRouter, ini akan disebutkan selanjutnya) untuk mengakses model open-source ini (meskipun ini mengorbankan privasi). Meskipun model open-source belum dapat sepenuhnya menyaingi model level GPT-4 komersial, Anda dapat membuat agen unggul dengan memanfaatkan model yang berbeda sesuai dengan kekuatan dan kelemahan mereka. Untuk detailnya, silakan merujuk menggunakan model yang berbeda di berbagai agen.
Claude-3-5-Sonnet-20240620 memberikan kinerja terbaik.
GPT-4O dan GPT-4-1106-preview juga menawarkan kinerja tingkat atas. Tetapi karena waktu yang lama dari agen dan konsumsi token yang hebat, silakan gunakan model komersial dengan hati -hati. GPT-4O-Mini bekerja dengan sangat baik, dan meskipun tidak ternak, harganya yang murah membuat model ini sangat menarik. GPT-4-Turbo / GPT-3.5-Turbo secara mengejutkan malas, dan kami tidak pernah dapat menemukan ekspresi cepat yang stabil.
Di antara model open-source, yang biasanya berkinerja baik termasuk:
Meta-llama-3.1-405b-instruct itu bagus, tetapi terlalu besar untuk menjadi praktis di PC.
Untuk pengguna yang kemampuan perangkat kerasnya tidak cukup untuk menjalankan model open-source secara lokal dan yang tidak dapat memperoleh kunci API untuk model komersial, mereka dapat mencoba opsi berikut:
OpenRouter Layanan ini dapat merutekan permintaan inferensi Anda ke berbagai model open-source atau komersial tanpa perlu menggunakan model open-source secara lokal atau mengajukan kunci API untuk berbagai model komersial. Itu pilihan yang fantastis. Ailice secara otomatis mendukung semua model di OpenRouter. Anda dapat memilih Autorouter: OpenRouter/Auto untuk membiarkan autorouter secara otomatis merutekan untuk Anda, atau Anda dapat menentukan model spesifik apa pun yang dikonfigurasi dalam file config.json. Terima kasih @babybirdprd karena telah merekomendasikan OpenRouter kepada saya.
GROQ: LLAMA3-70B-8192 Tentu saja, Ailice juga mendukung model lain di bawah GROQ. Salah satu masalah dengan berjalan di bawah GROQ adalah mudah melebihi batas laju, sehingga hanya dapat digunakan untuk percobaan sederhana.
Kami akan memilih model open-source yang berkinerja terbaik untuk memberikan referensi bagi pengguna model open-source.
Yang terbaik di antara semua model: Qwen-2-72b-instruct . Ini adalah model sumber terbuka pertama dengan nilai praktis . Ini adalah kemajuan yang hebat! Ini memiliki kemampuan penalaran yang dekat dengan GPT-4, meskipun belum cukup di sana. Dengan intervensi pengguna aktif melalui fitur interupsi, banyak tugas yang lebih kompleks dapat berhasil diselesaikan.
Model berkinerja terbaik kedua: Mixtral-8x22b-instruct dan meta-llama/meta-llama-3-70b-instruct . Perlu dicatat bahwa model seri LLAMA3 tampaknya menunjukkan penurunan kinerja yang signifikan setelah kuantisasi, yang mengurangi nilai praktisnya. Anda dapat menggunakannya dengan Groq.
Jika Anda menemukan model yang lebih baik, beri tahu saya.
Untuk pemain tingkat lanjut, tidak dapat dihindari untuk mencoba lebih banyak model. Untungnya, ini tidak sulit untuk dicapai.
Untuk model Openai/Mistral/Anthropic/GroQ, Anda tidak perlu melakukan apa pun. Cukup gunakan ModelID yang terdiri dari nama model resmi yang ditambahkan ke "Oai:"/"Mistral:"/"Anthropic:"/"Groq:" awalan. Jika Anda perlu menggunakan model yang tidak termasuk dalam daftar yang didukung Ailice, Anda dapat menyelesaikannya dengan menambahkan entri untuk model ini dalam file config.json. Metode untuk menambahkan adalah untuk secara langsung merujuk entri dari model yang sama, memodifikasi ContextWindow ke nilai aktual, menjaga SystemAsUser konsisten dengan model serupa, dan mengatur args ke diktikir kosong.
Anda dapat menggunakan server inferensi pihak ketiga yang kompatibel dengan API OpenAI untuk menggantikan fungsionalitas inferensi LLM bawaan di Ailice. Cukup gunakan format konfigurasi yang sama dengan model OpenAI dan memodifikasi BaseUrl, Apikey, ContextWindow dan parameter lainnya (sebenarnya, beginilah cara Ailice mendukung model GROQ).
Untuk server inferensi yang tidak mendukung API OpenAI, Anda dapat mencoba menggunakan Litellm untuk mengubahnya menjadi API yang kompatibel dengan Openai (kami memiliki contoh di bawah).
Penting untuk dicatat bahwa karena adanya banyak pesan sistem dalam catatan percakapan Ailice, yang bukan merupakan kasus penggunaan umum untuk LLM, tingkat dukungan untuk ini tergantung pada implementasi spesifik dari server inferensi ini. Dalam hal ini, Anda dapat mengatur parameter SystemAsUser untuk benar untuk menghindari masalah. Meskipun ini dapat mencegah model menjalankan ailice pada kinerja optimalnya, itu juga memungkinkan kita untuk kompatibel dengan berbagai server inferensi yang efisien. Untuk pengguna rata -rata, manfaatnya lebih besar daripada kelemahannya.
Kami menggunakan Ollama sebagai contoh untuk menjelaskan cara menambahkan dukungan untuk layanan tersebut. Pertama, kita perlu menggunakan Litellm untuk mengubah antarmuka Ollama menjadi format yang kompatibel dengan openai.
pip install litellm
ollama pull mistral-openorca
litellm --model ollama/mistral-openorca --api_base http://localhost:11434 --temperature 0.0 --max_tokens 8192Kemudian, tambahkan dukungan untuk layanan ini di file config.json (lokasi file ini akan diminta saat ailice diluncurkan).
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"ollama" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fake-key " ,
"baseURL" : " http://localhost:8000 " ,
"modelList" : {
"mistral-openorca" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 8192 ,
"systemAsUser" : false ,
"args" : {}
}
}
},
...
},
...
}Sekarang kita bisa menjalankan Ailice:
ailice_web --modelID=ollama:mistral-openorcaDalam contoh ini, kami akan menggunakan LM Studio untuk menjalankan model sumber paling terbuka yang pernah saya lihat: QWEN2-72B-INSTRUCT-Q3_K_S.GGUF , Powering Ailice untuk dijalankan pada mesin lokal.
Unduh Bobot Model QWEN2-72B-INSTRUCT-Q3_K_S.GGUF Menggunakan LM Studio.
Di jendela LM Studio "LocalServer", atur n_gpu_layers ke -1 jika Anda ingin menggunakan GPU saja. Sesuaikan parameter 'Panjang Konteks' di sebelah kiri ke 16384 (atau nilai yang lebih kecil berdasarkan memori Anda yang tersedia), dan ubah 'Konteks Kebijakan Overflow' menjadi 'menjaga sistem tetap dan pesan pengguna pertama, truncate middle'.
Jalankan layanan. Kami menganggap alamat layanan ini adalah "http: // localhost: 1234/v1/".
Kemudian, kami membuka config.json dan membuat modifikasi berikut:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"qwen2-72b" : {
"formatter" : " AFormatterGPT " ,
"contextWindow" : 32764 ,
"systemAsUser" : true ,
"args" : {}
}
}
},
...
},
...
}Akhirnya, jalankan Ailice. Anda dapat menyesuaikan parameter 'ContextWindowRatio' berdasarkan VRAM atau ruang memori yang tersedia. Semakin besar parameter, semakin banyak ruang VRAM diperlukan.
ailice_web --modelID=lm-studio:qwen2-72b --contextWindowRatio=0.5Mirip dengan apa yang kami lakukan di bagian sebelumnya, setelah kami menggunakan LM Studio untuk mengunduh dan menjalankan LLAVA, kami memodifikasi file konfigurasi sebagai berikut:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"oai" : {
...
},
"lm-studio" : {
"modelWrapper" : " AModelChatGPT " ,
"apikey" : " fakekey " ,
"baseURL" : " http://localhost:1234/v1/ " ,
"modelList" : {
"llava-1.6-34b" : {
"formatter" : " AFormatterGPTVision " ,
"contextWindow" : 4096 ,
"systemAsUser" : true ,
"args" : {}
}
},
},
...
},
...
}Namun, perlu dicatat bahwa model multi-modal open source saat ini jauh dari cukup untuk melakukan tugas agen, jadi contoh ini untuk pengembang daripada pengguna.
Untuk model open source di HuggingFace, Anda hanya perlu mengetahui informasi berikut untuk menambahkan dukungan untuk model baru: alamat huggingface dari model, format cepat model, dan panjang jendela konteks. Biasanya satu baris kode sudah cukup untuk menambahkan model baru, tetapi kadang -kadang Anda tidak beruntung dan Anda membutuhkan sekitar selusin baris kode.
Berikut adalah metode lengkap untuk menambahkan dukungan LLM baru:
Buka config.json, Anda harus menambahkan konfigurasi LLM baru ke dalam model.hf.modellist, yang terlihat seperti berikut:
{
"maxMemory" : {},
"quantization" : null ,
"models" : {
"hf" : {
"modelWrapper" : " AModelCausalLM " ,
"modelList" : {
"meta-llama/Llama-2-13b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
"meta-llama/Llama-2-70b-chat-hf" : {
"formatter" : " AFormatterLLAMA2 " ,
"contextWindow" : 4096 ,
"systemAsUser" : false ,
"args" : {}
},
...
}
},
...
}
...
}"Formatter" adalah kelas yang mendefinisikan format cepat LLM. Anda dapat menemukan definisi mereka di Core/LLM/Aformatter. Anda dapat membaca kode -kode ini untuk menentukan format mana yang diperlukan untuk model yang ingin Anda tambahkan. Jika Anda tidak menemukannya, Anda perlu menulis sendiri. Untungnya, Formatter adalah hal yang sangat sederhana dan dapat diselesaikan dalam lebih dari selusin baris kode. Saya yakin Anda akan mengerti bagaimana melakukannya setelah membaca beberapa kode sumber formatter.
Jendela konteks adalah properti yang biasanya dimiliki oleh LLM dari arsitektur transformator. Ini menentukan panjang teks yang dapat diproses oleh model pada satu waktu. Anda perlu mengatur jendela konteks model baru ke kunci "ContextWindow".
"SystemAsUser": Kami menggunakan peran "sistem" sebagai pengirim pesan yang dikembalikan oleh fungsi panggilan. Namun, tidak semua LLM memiliki definisi yang jelas tentang peran sistem, dan tidak ada jaminan bahwa LLM dapat beradaptasi dengan pendekatan ini. Jadi kita perlu menggunakan SystemAser untuk mengatur apakah akan menempatkan teks yang dikembalikan oleh fungsi panggilan dalam pesan pengguna. Coba atur ke false terlebih dahulu.
Semuanya selesai! Gunakan "HF:" sebagai awalan nama model untuk membentuk ModelID, dan gunakan modelID dari model baru sebagai parameter perintah untuk memulai ailice!
Ailice memiliki dua mode operasi. Satu mode menggunakan LLM tunggal untuk menggerakkan semua agen, sementara yang lain memungkinkan setiap jenis agen untuk menentukan LLM yang sesuai. Mode terakhir memungkinkan kita untuk menggabungkan kemampuan model open-source dan model komersial, mencapai kinerja yang lebih baik dengan biaya yang lebih rendah. Untuk menggunakan mode kedua, Anda perlu mengonfigurasi item AgentModelConfig di config.json terlebih dahulu:
"modelID" : " " ,
"agentModelConfig" : {
"DEFAULT" : " openrouter:qwen/qwen-2-72b-instruct " ,
"coder" : " openrouter:deepseek/deepseek-coder "
},Pertama, pastikan bahwa nilai default untuk ModelID diatur ke string kosong, kemudian konfigurasikan LLM yang sesuai untuk setiap jenis agen di AgentModelConfig.
Akhirnya, Anda dapat mencapai mode operasi kedua dengan tidak menentukan ModelID:
ailice_webPrinsip -prinsip dasar saat merancang Ailice adalah:
Mari kita jelaskan secara singkat prinsip -prinsip mendasar ini.
Mulai dari level yang paling jelas, konstruksi cepat yang sangat dinamis membuatnya lebih kecil kemungkinannya bagi agen untuk jatuh ke dalam satu lingkaran. Masuknya variabel baru dari lingkungan eksternal terus berdampak pada LLM, membantunya menghindari jebakan itu. Selain itu, memberi makan LLM dengan semua informasi yang tersedia saat ini dapat sangat meningkatkan outputnya. For example, in automated programming, error messages from interpreters or command lines assist the LLM in continuously modifying the code until the correct result is achieved. Lastly, in dynamic prompt construction, new information in the prompts may also come from other agents, which acts as a form of linked inference computation, making the system's computational mechanisms more complex, varied, and capable of producing richer behaviors.
Separating computational tasks is, from a practical standpoint, due to our limited context window. We cannot expect to complete a complex task within a window of a few thousand tokens. If we can decompose a complex task so that each subtask is solved within limited resources, that would be an ideal outcome. In traditional computing models, we have always taken advantage of this, but in new computing centered around LLMs, this is not easy to achieve. The issue is that if one subtask fails, the entire task is at risk of failure. Recursion is even more challenging: how do you ensure that with each call, the LLM solves a part of the subproblem rather than passing the entire burden to the next level of the call? We have solved the first problem with the IACT architecture in Ailice, and the second problem is theoretically not difficult to solve, but it likely requires a smarter LLM.
The third principle is what everyone is currently working on: having multiple intelligent agents interact and cooperate to complete more complex tasks. The implementation of this principle actually addresses the aforementioned issue of subtask failure. Multi-agent collaboration is crucial for the fault tolerance of agents in operation. In fact, this may be one of the biggest differences between the new computational paradigm and traditional computing: traditional computing is precise and error-free, assigning subtasks only through unidirectional communication (function calls), whereas the new computational paradigm is error-prone and requires bidirectional communication between computing units to correct errors. This will be explained in detail in the following section on the IACT framework.
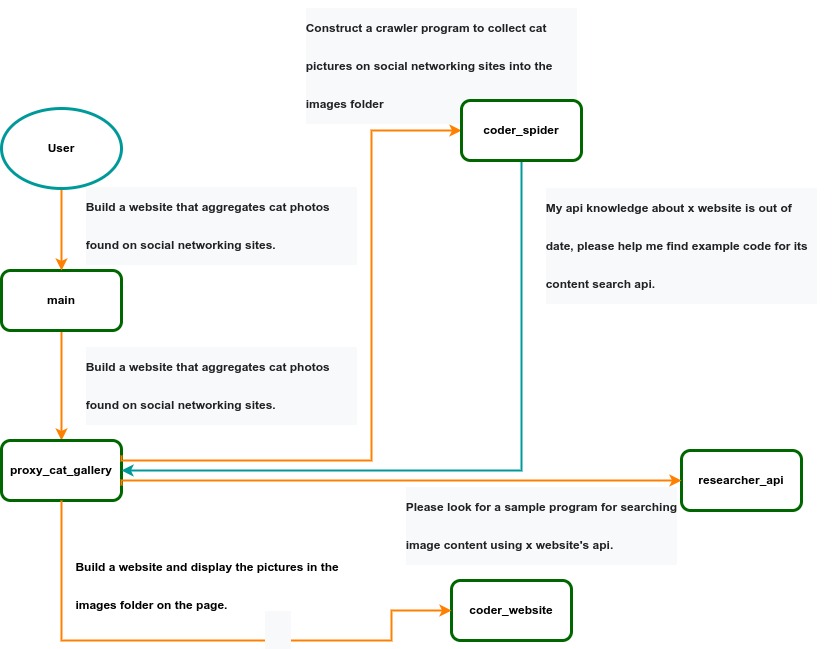 IACT Architecture Diagram. A user requirement to build a page for image collection and display is dynamically decomposed into two tasks: coder_spider and coder_website. When coder_spider encounters difficulties, it proactively seeks assistance from its caller, proxy_cat_gallery. Proxy_cat_gallery then creates another agent, researcher_api, and employs it to address the issue.
IACT Architecture Diagram. A user requirement to build a page for image collection and display is dynamically decomposed into two tasks: coder_spider and coder_website. When coder_spider encounters difficulties, it proactively seeks assistance from its caller, proxy_cat_gallery. Proxy_cat_gallery then creates another agent, researcher_api, and employs it to address the issue.
Ailice can be regarded as a computer powered by a LLM , and its features include:
Representing input, output, programs, and data in text form.
Using LLM as the processor.
Breaking down computational tasks through successive calls to basic computing units (analogous to functions in traditional computing), which are essentially various functional agents.
Therefore, user-input text commands are executed as a kind of program, decomposed into various "subprograms", and addressed by different agents , forming the fundamental architecture of Ailice. In the following, we will provide a detailed explanation of the nature of these basic computing units.
A natural idea is to let LLM solve certain problems (such as information retrieval, document understanding, etc.) through multi-round dialogues with external callers and peripheral modules in the simplest computational unit. We temporarily call this computational unit a "function". Then, by analogy with traditional computing, we allow functions to call each other, and finally add the concept of threads to implement multi-agent interaction. However, we can have a much simpler and more elegant computational model than this.
The key here is that the "function" that wraps LLM reasoning can actually be called and returned multiple times. A "function" with coder functionality can pause work and return a query statement to its caller when it encounters unclear requirements during coding. If the caller is still unclear about the answer, it continues to ask the next higher level caller. This process can even go all the way to the final user's chat window. When new information is added, the caller will reactivate the coder's execution process by passing in the supplementary information. It can be seen that this "function" is not a traditional function, but an object that can be called multiple times. The high intelligence of LLM makes this interesting property possible. You can also see it as agents strung together by calling relationships, where each agent can create and call more sub-agents, and can also dialogue with its caller to obtain supplementary information or report its progress . In Ailice, we call this computational unit "AProcessor" (essentially what we referred to as an agent). Its code is located in core/AProcessor.py.
Next, we will elaborate on the structure inside AProcessor. The interior of AProcessor is a multi-round dialogue. The "program" that defines the function of AProcessor is a prompt generation mechanism, which generates the prompt for each round of dialogue from the dialogue history. The dialogue is one-to-many. After the external caller inputs the request, LLM will have multiple rounds of dialogue with the peripheral modules (we call them SYSTEM), LLM outputs function calls in various grammatical forms, and the system calls the peripheral modules to generate results and puts the results in the reply message. LLM finally gets the answer and responds to the external caller, ending this call. But because the dialogue history is still preserved, the caller can call in again to continue executing more tasks.
The last part we want to introduce is the parsing module for LLM output. In fact, we regard the output text of LLM as a "script" of semi-natural language and semi-formal language, and use a simple interpreter to execute it . We can use regular expressions to express a carefully designed grammatical structure, parse it into a function call and execute it. Under this design, we can design more flexible function call grammar forms, such as a section with a certain fixed title (such as "UPDATE MEMORY"), which can also be directly parsed out and trigger the execution of an action. This implicit function call does not need to make LLM aware of its existence, but only needs to make it strictly follow a certain format convention. For the most hardcore possibility, we have left room. The interpreter here can not only use regular expressions for pattern matching, its Eval function is recursive. We don't know what this will be used for, but it seems not bad to leave a cool possibility, right? Therefore, inside AProcessor, the calculation is alternately completed by LLM and the interpreter, their outputs are each other's inputs, forming a cycle.
In Ailice, the interpreter is one of the most crucial components within an agent. We use the interpreter to map texts from the LLM output that match specific patterns to actions, including function calls, variable definitions and references, and any user-defined actions. Sometimes these actions directly interact with peripheral modules, affecting the external world; other times, they are used to modify the agent's internal state, thereby influencing its future prompts.
The basic structure of the interpreter is straightforward: a list of pattern-action pairs. Patterns are defined by regular expressions, and actions are specified by a Python function with type annotations. Given that syntactic structures can be nested, we refer to the overarching structure as the entry pattern. During runtime, the interpreter actively detects these entry patterns in the LLM output text. Upon detecting an entry pattern (and if the corresponding action returns data), it immediately terminates the LLM generation to execute the relevant action.
The design of agents in Ailice encompasses two fundamental aspects: the logic for generating prompts based on dialogue history and the agent's internal state, and a set of pattern-action pairs. Essentially, the agent implements the interpreter framework with a set of pattern-action pairs; it becomes an integral part of the interpreter. The agent's internal state is one of the targets for the interpreter's actions, with changes to the agent's internal state influencing the direction of future prompts.
Generating prompts from dialogue history and the internal state is nearly a standardized process, although developers still have the freedom to choose entirely different generation logic. The primary challenge for developers is to create a system prompt template, which is pivotal for the agent and often demands the most effort to perfect. However, this task revolves entirely around crafting natural language prompts.
Ailice utilizes a simple scripting language embedded within text to map the text-based capabilities of LLMs to the real world. This straightforward scripting language includes non-nested function calls and mechanisms for creating and referencing variables, as well as operations for concatenating text content . Its purpose is to enable LLMs to exert influence on the world more naturally: from smoother text manipulation abilities to simple function invocation mechanisms, and multimodal variable operation capabilities. Finally, it should be noted that for the designers of agents, they always have the freedom to extend new syntax for this scripting language. What is introduced here is a minimal standard syntax structure.
The basic syntax is as follows:
Variable Definition: VAR_NAME := <!|"SOME_CONTENT"|!>
Function Calls/Variable References/Text Concatenation: !FUNC-NAME<!|"...", '...', VAR_NAME1, "Execute the following code: n" + VAR_NAME2, ...|!>
The basic variable types are str/AImage/various multimodal types. The str type is consistent with Python's string syntax, supporting triple quotes and escape characters.
This constitutes the entirety of the embedded scripting language.
The variable definition mechanism introduces a way to extend the context window, allowing LLMs to record important content into variables to prevent forgetting. During system operation, various variables are automatically defined. For example, if a block of code wrapped in triple backticks is detected within a text message, a variable is automatically created to store the code, enabling the LLM to reference the variable to execute the code, thus avoiding the time and token costs associated with copying the code in full. Furthermore, some module functions may return data in multimodal types rather than text. In such cases, the system automatically defines these as variables of the corresponding multimodal type, allowing the LLM to reference them (the LLM might send them to another module for processing).
In the long run, LLMs are bound to evolve into multimodal models capable of seeing and hearing. Therefore, the exchanges between Ailice's agents should be in rich text , not just plain text. While Markdown provides some capability for marking up multimodal content, it is insufficient. Hence, we will need an extended version of Markdown in the future to include various embedded multimodal data such as videos and audio.
Let's take images as an example to illustrate the multimodal mechanism in Ailice. When agents receive text containing Markdown-marked images, the system automatically inputs them into a multimodal model to ensure the model can see these contents. Markdown typically uses paths or URLs for marking, so we have expanded the Markdown syntax to allow the use of variable names to reference multimodal content.
Another minor issue is how different agents with their own internal variable lists exchange multimodal variables. This is simple: the system automatically checks whether a message sent from one agent to another contains internal variable names. If it does, the variable content is passed along to the next agent.
Why do we go to the trouble of implementing an additional multimodal variable mechanism when marking multimodal content with paths and URLs is much more convenient? This is because marking multimodal content based on local file paths is only feasible when Ailice runs entirely in a local environment, which is not the design intent. Ailice is meant to be distributed, with the core and modules potentially running on different computers, and it might even load services running on the internet to provide certain computations. This makes returning complete multimodal data more attractive. Of course, these designs made for the future might be over-engineering, and if so, we will modify them in the future.
One of the goals of Ailice is to achieve introspection and self-expansion (which is why our logo features a butterfly with its reflection in the water). This would enable her to understand her own code and build new functionalities, including new external interaction modules (ie new functions) and new types of agents (APrompt class) . As a result, the knowledge and capabilities of LLMs would be more thoroughly unleashed.
Implementing self-expansion involves two parts. On one hand, new modules and new types of agents (APrompt class) need to be dynamically loaded during runtime and naturally integrated into the computational system to participate in processing, which we refer to as dynamic loading. On the other hand, Ailice needs the ability to construct new modules and agent types.
The dynamic loading mechanism itself is of great significance: it represents a novel software update mechanism . We can allow Ailice to search for its own extension code on the internet, check the code for security, fix bugs and compatibility issues, and ultimately run the extension as part of itself. Therefore, Ailice developers only need to place their contributed code on the internet, without the need to merge into the main codebase or consider any other installation methods. The implementation of the dynamic loading mechanism is continuously improving. Its core lies in the extension packages providing some text describing their functions. During runtime, each agent in Ailice finds suitable functions or agent types to solve sub-problems for itself through semantic matching and other means.
Building new modules is a relatively simple task, as the interface constraints that modules need to meet are very straightforward. We can teach LLMs to construct new modules through an example. The more complex task is the self-construction of new agent types (APrompt class), which requires a good understanding of Ailice's overall architecture. The construction of system prompts is particularly delicate and is a challenging task even for humans. Therefore, we pin our hopes on more powerful LLMs in the future to achieve introspection, allowing Ailice to understand herself by reading her own source code (for something as complex as a program, the best way to introduce it is to present itself), thereby constructing better new agents .
For developing Agents, the main loop of Ailice is located in the AiliceMain.py or ui/app.py files. To further understand the construction of an agent, you need to read the code in the "prompts" folder, by reading these code you can understand how an agent's prompts are dynamically constructed.
For developers who want to understand the internal operation logic of Ailice, please read core/AProcessor.py and core/Interpreter.py. These two files contain approximately three hundred lines of code in total, but they contain the basic framework of Ailice.
In this project, achieving the desired functionality of the AI Agent is the primary goal. The secondary goal is code clarity and simplicity . The implementation of the AI Agent is still an exploratory topic, so we aim to minimize rigid components in the software (such as architecture/interfaces imposing constraints on future development) and provide maximum flexibility for the application layer (eg, prompt classes) . Abstraction, deduplication, and decoupling are not immediate priorities.
When implementing a feature, always choose the best method rather than the most obvious one . The metric for "best" often includes traits such as trivializing the problem from a higher perspective, maintaining code clarity and simplicity, and ensuring that changes do not significantly increase overall complexity or limit the software's future possibilities.
Adding comments is not mandatory unless absolutely necessary; strive to make the code clear enough to be self-explanatory . While this may not be an issue for developers who appreciate comments, in the AI era, we can generate detailed code explanations at any time, eliminating the need for unstructured, hard-to-maintain comments.
Follow the principle of Occam's razor when adding code; never add unnecessary lines .
Functions or methods in the core should not exceed 60 lines .
While there are no explicit coding style constraints, maintain consistency or similarity with the original code in terms of naming and case usage to avoid readability burdens.
Ailice aims to achieve multimodal and self-expanding features within a scale of less than 5000 lines, reaching its final form at the current stage. The pursuit of concise code is not only because succinct code often represents a better implementation, but also because it enables AI to develop introspective capabilities early on and facilitates better self-expansion. Please adhere to the above rules and approach each line of code with diligence.
Ailice's fundamental tasks are twofold: one is to fully unleash the capabilities of LLM based on text into the real world; the other is to explore better mechanisms for long-term memory and forming a coherent understanding of vast amounts of text . Our development efforts revolve around these two focal points.
If you are interested in the development of Ailice itself, you may consider the following directions:
Explore improved long-term memory mechanisms to enhance the capabilities of each Agent. We need a long-term memory mechanism that enables consistent understanding of large amounts of content and facilitates association . The most feasible option at the moment is to replace vector database with knowledge graph, which will greatly benefit the comprehension of long texts/codes and enable us to build genuine personal AI assistants.
Multimodal support. The support for the multimodal model has been completed, and the current development focus is shifting towards the multimodal support of peripheral modules. We need a module that operates computers based on screenshots and simulates mouse/keyboard actions.
Self-expanding support. Our goal is to enable language models to autonomously code and implement new peripheral modules/agent types and dynamically load them for immediate use . This capability will enable self-expansion, empowering the system to seamlessly integrate new functionalities. We've completed most of the functionality, but we still need to develop the capability to construct new types of agents.
Richer UI interface . We need to organize the agents output into a tree structure in dialog window and dynamically update the output of all agents. And accept user input on the web interface and transfer it to scripter's standard input, which is especially needed when using sudo.
Develop Agents with various functionalities based on the current framework.
Explore the application of IACT architecture on complex tasks. By utilizing an interactive agents call tree, we can break down large documents for improved reading comprehension, as well as decompose complex software engineering tasks into smaller modules, completing the entire project build and testing through iterations. This requires a series of intricate prompt designs and testing efforts, but it holds an exciting promise for the future. The IACT architecture significantly alleviates the resource constraints imposed by the context window, allowing us to dynamically adapt to more intricate tasks.
Build rich external interaction modules using self-expansion mechanisms! This will be accomplished in AiliceEVO.
In addition to the tasks mentioned above, we should also start actively contemplating the possibility of creating a smaller LLM that possesses lower knowledge content but higher reasoning abilities .


