xai
v0.1.0
XAI是一個機器學習庫,其核心設計具有AI的解釋性。 XAI包含各種工具,可用於分析和評估數據和模型。 XAI圖書館由道德AI和ML研究所維護,它是根據負責任的機器學習原理開發的。
您可以在https://ethicalml.github.io/xai/index.html上找到文檔。您還可以在倫敦Tensorflow倫敦查看我們的演講,該想法首先是構思的 - 該談話還包含了有關此庫中的定義和原理的見解。
| 這場演講的視頻在倫敦Pydata 2019會議上介紹,該視頻概述了機器學習的動機解釋性以及使用XAI庫介紹解釋性和減輕不想要的偏見的技術。 | 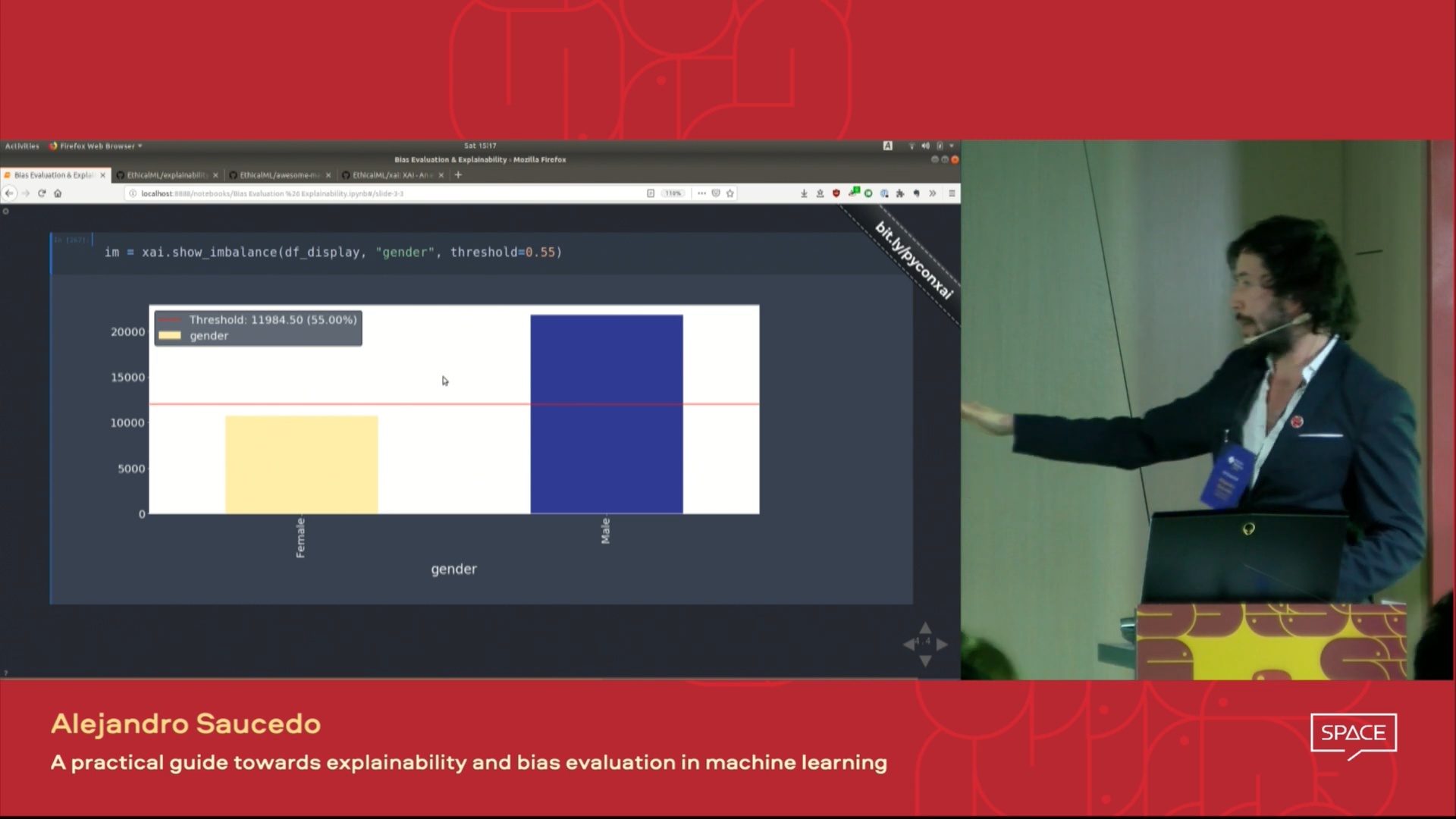 |
| 您想了解更多令人敬畏的機器學習解釋性工具嗎?查看我們社區建造的“令人敬畏的機器學習生產和操作”列表,其中包含大量的解釋性,隱私,編排以及其他工具的列表。 |  |
如果您想查看一個功能齊全的演示,則該倉庫並在示例文件夾中運行示例jupyter筆記本。
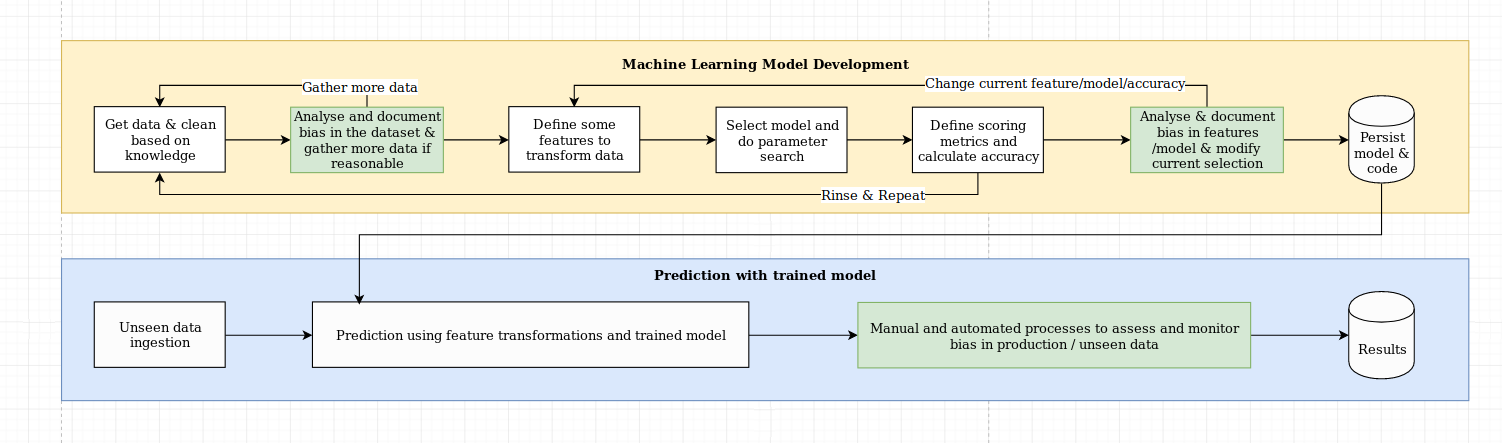
我們認為解釋性的挑戰不僅僅是算法挑戰,它需要將數據科學的最佳實踐與特定於領域的知識相結合。 XAI庫旨在授權機器學習工程師和相關領域專家分析端到端解決方案並確定可能導致相對於所需目標而導致優勢性能的差異。更廣泛地說,XAI庫是使用可解釋的機器學習的三個步驟設計的,其中涉及1)數據分析,2)模型評估和3)生產監控。
我們提供了上圖上面提到的以下三個步驟的視覺概述:
XAI包在PYPI上。要安裝您可以運行:
pip install xai
另外,您可以通過克隆回購和運行來從源安裝:
python setup.py install
您可以在示例文件夾中找到示例用法。
使用XAI,您可以識別數據中的不平衡。為此,我們將從XAI庫中加載人口普查數據集。
import xai . data
df = xai . data . load_census ()
df . head ()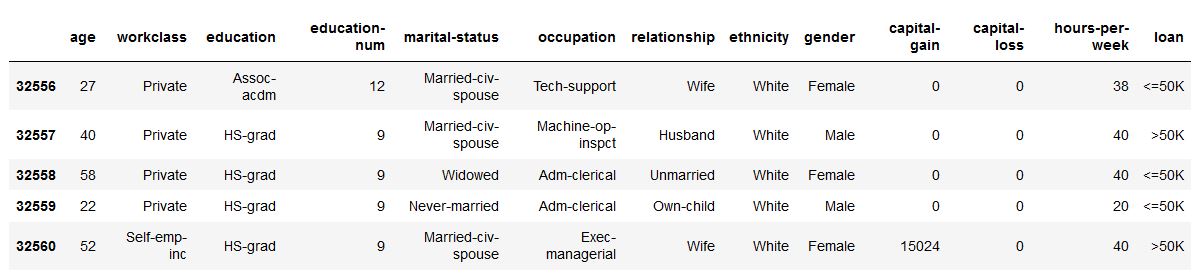
ims = xai . imbalance_plot ( df , "gender" )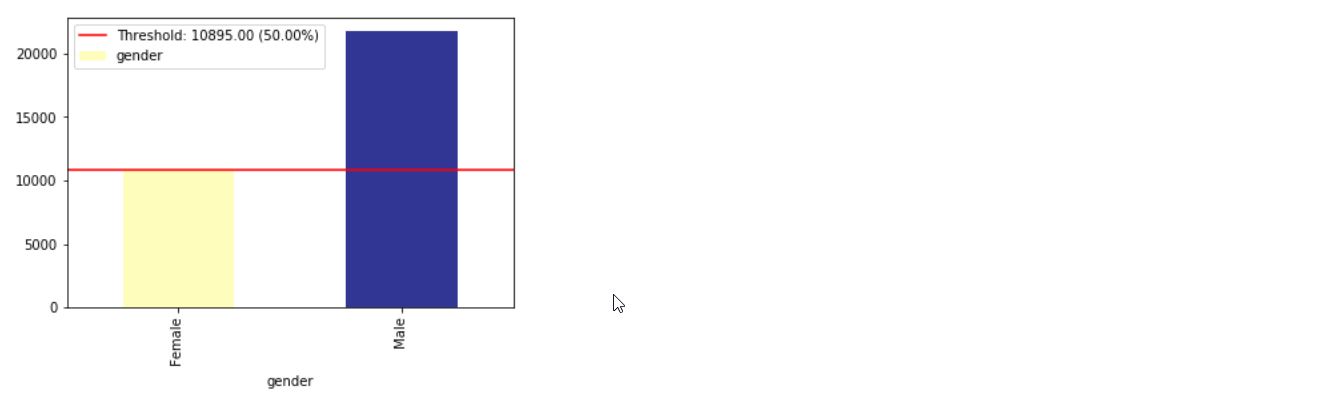
im = xai . imbalance_plot ( df , "gender" , "loan" )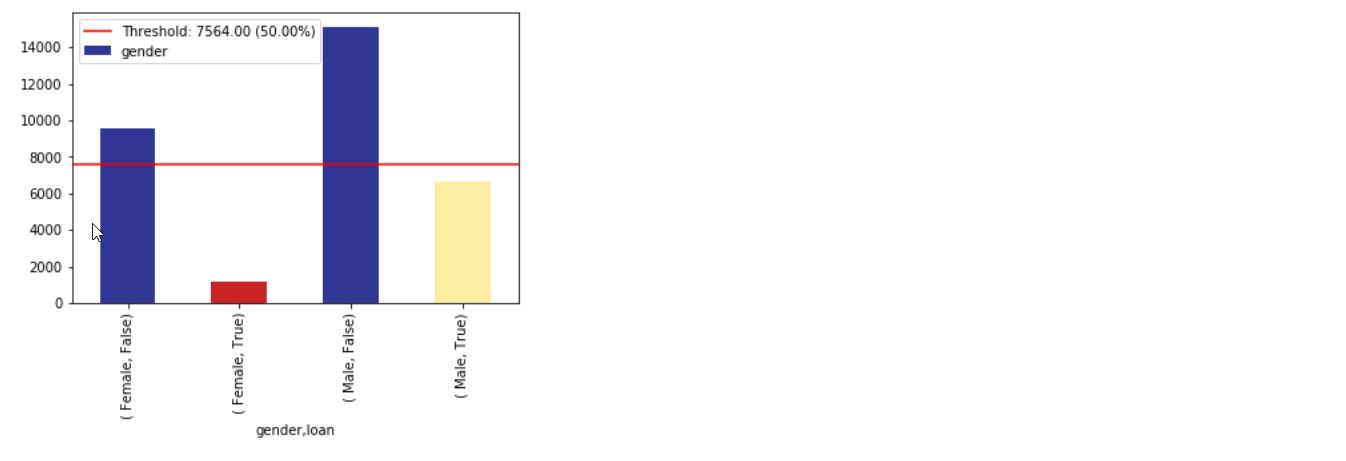
bal_df = xai . balance ( df , "gender" , "loan" , upsample = 0.8 )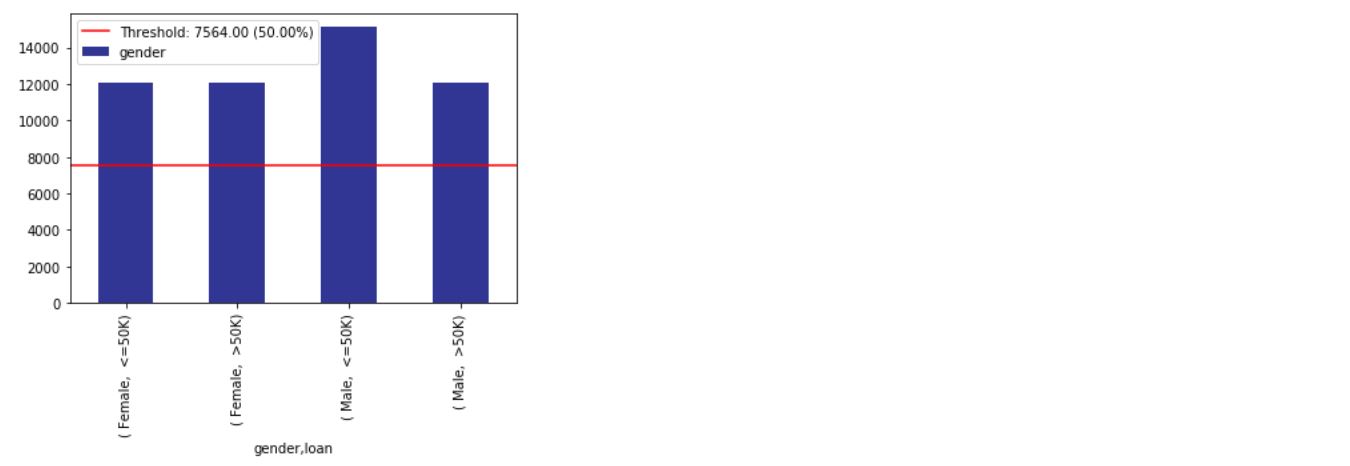
groups = xai . group_by_columns ( df , [ "gender" , "loan" ])
for group , group_df in groups :
print ( group )
print ( group_df [ "loan" ]. head (), " n " )
_ = xai . correlations ( df , include_categorical = True , plot_type = "matrix" )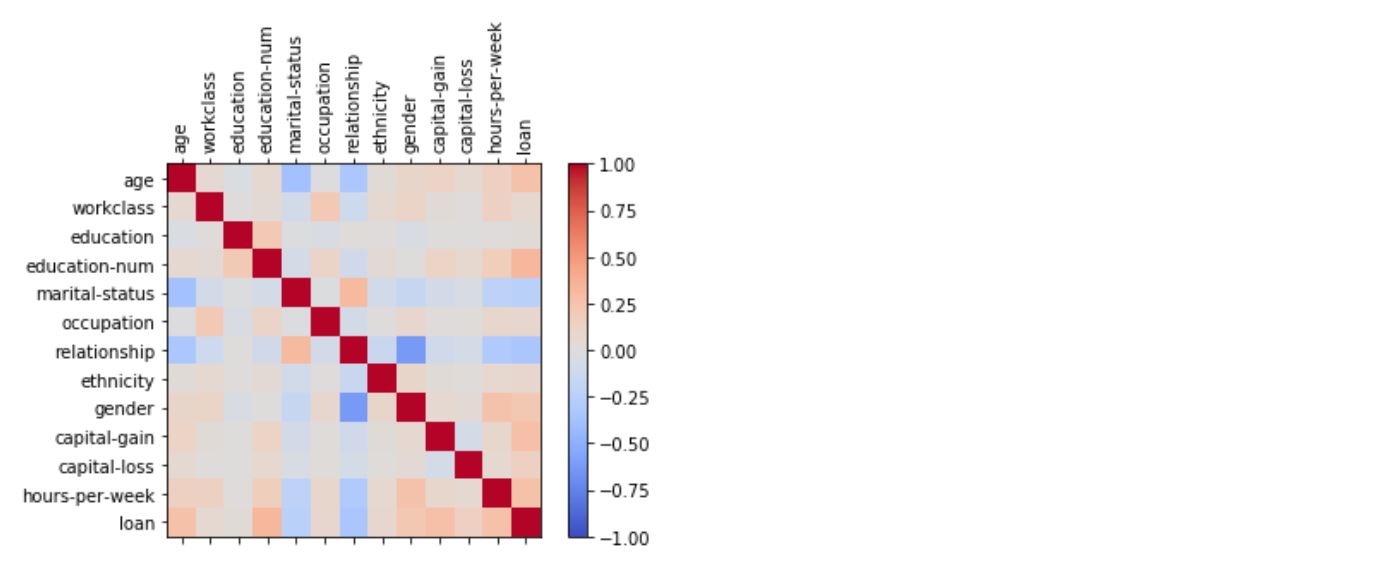
_ = xai . correlations ( df , include_categorical = True )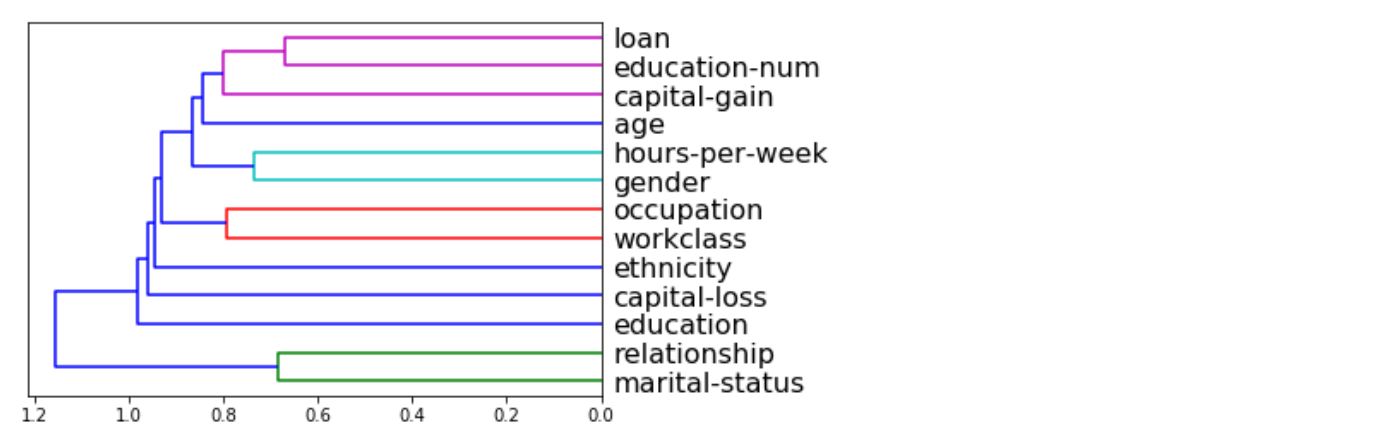
# Balanced train-test split with minimum 300 examples of
# the cross of the target y and the column gender
x_train , y_train , x_test , y_test , train_idx , test_idx =
xai . balanced_train_test_split (
x , y , "gender" ,
min_per_group = 300 ,
max_per_group = 300 ,
categorical_cols = categorical_cols )
x_train_display = bal_df [ train_idx ]
x_test_display = bal_df [ test_idx ]
print ( "Total number of examples: " , x_test . shape [ 0 ])
df_test = x_test_display . copy ()
df_test [ "loan" ] = y_test
_ = xai . imbalance_plot ( df_test , "gender" , "loan" , categorical_cols = categorical_cols )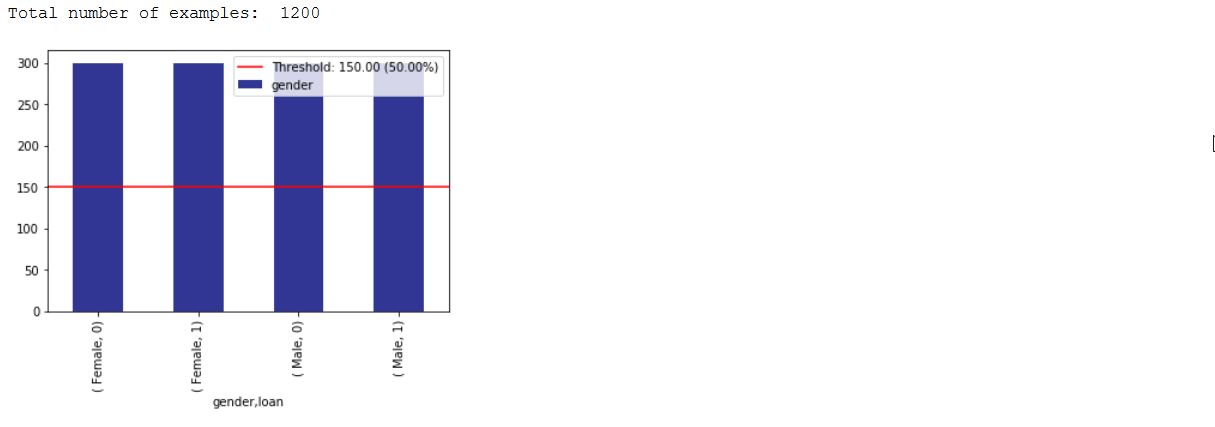
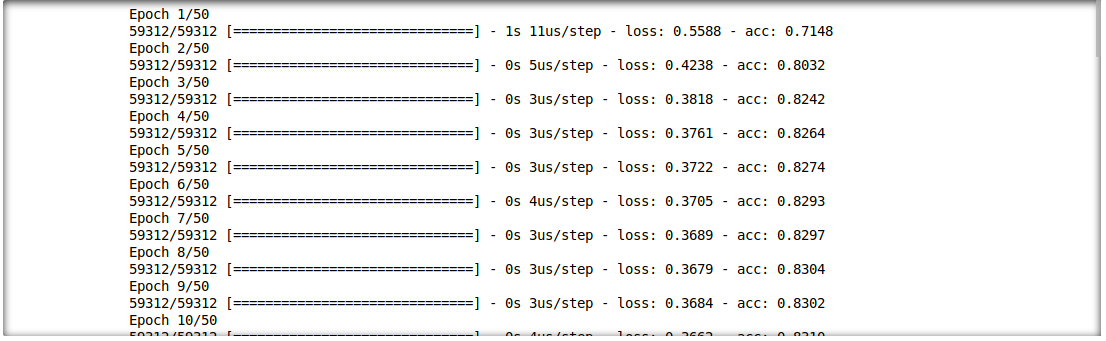
我們還能夠分析推理結果和輸入特徵之間的相互作用。為此,我們將訓練單層深度學習模型。
model = build_model(proc_df.drop("loan", axis=1))
model.fit(f_in(x_train), y_train, epochs=50, batch_size=512)
probabilities = model.predict(f_in(x_test))
predictions = list((probabilities >= 0.5).astype(int).T[0])
def get_avg ( x , y ):
return model . evaluate ( f_in ( x ), y , verbose = 0 )[ 1 ]
imp = xai . feature_importance ( x_test , y_test , get_avg )
imp . head ()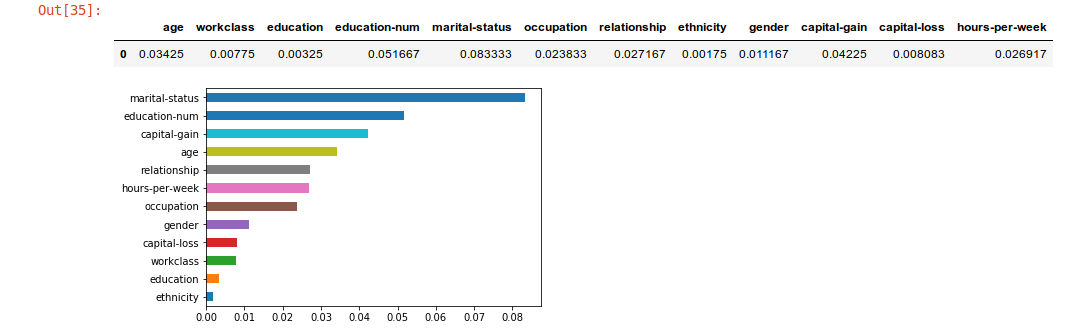
_ = xai . metrics_plot (
y_test ,
probabilities )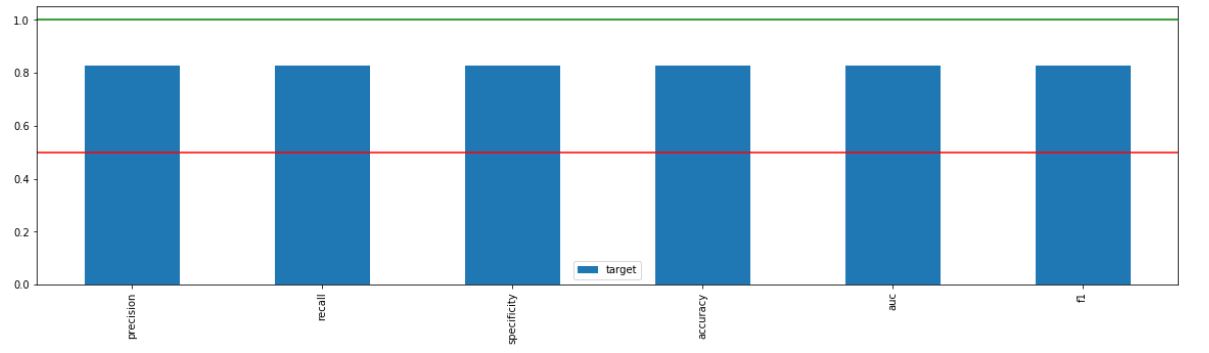
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" ],
categorical_cols = categorical_cols )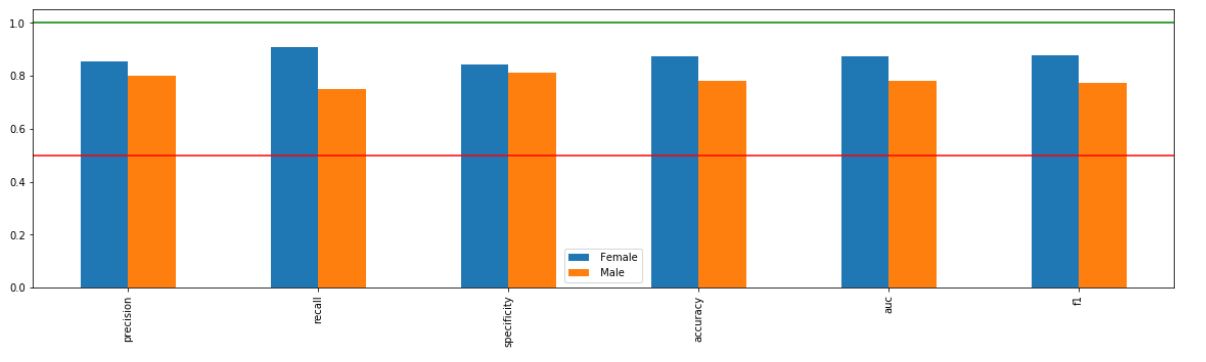
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" , "ethnicity" ],
categorical_cols = categorical_cols )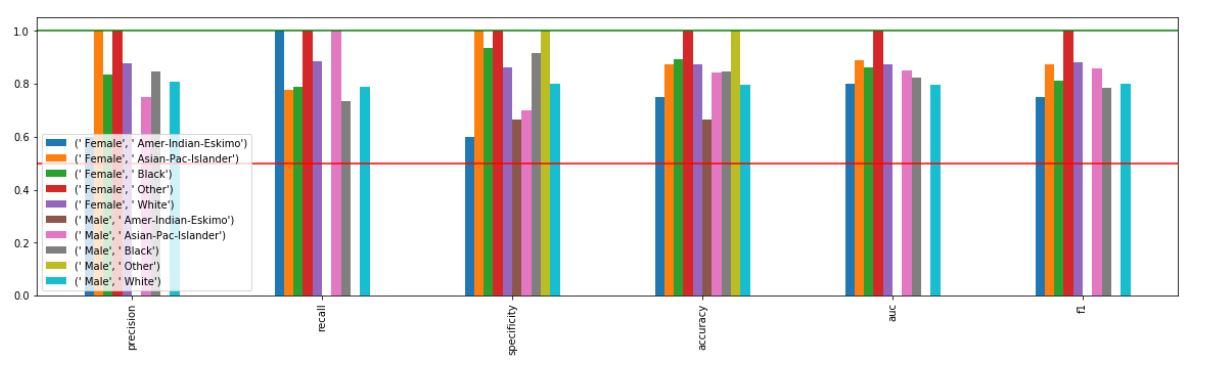
xai . confusion_matrix_plot ( y_test , pred )
_ = xai . roc_plot ( y_test , probabilities )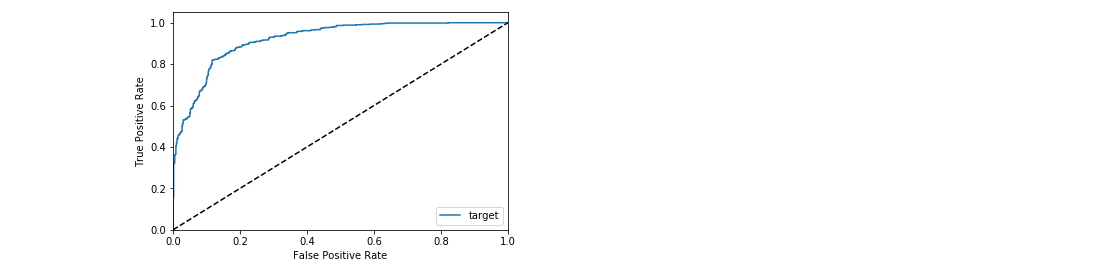
protected = [ "gender" , "ethnicity" , "age" ]
_ = [ xai . roc_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ p ],
categorical_cols = categorical_cols ) for p in protected ]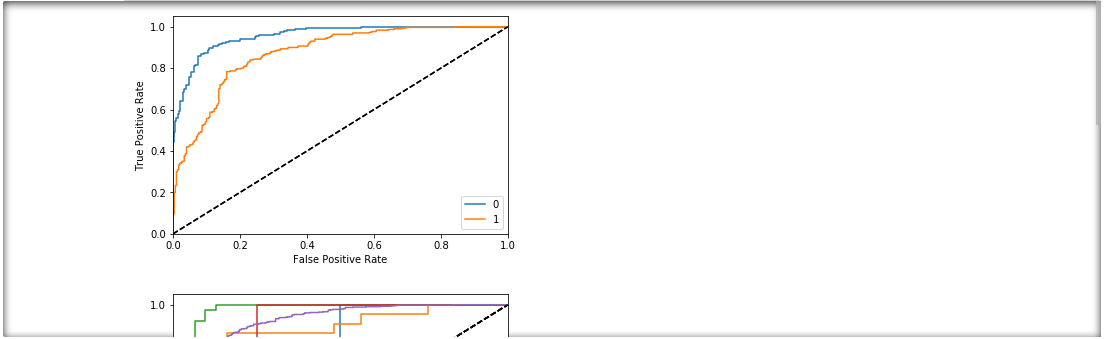
d = xai . smile_imbalance (
y_test ,
probabilities )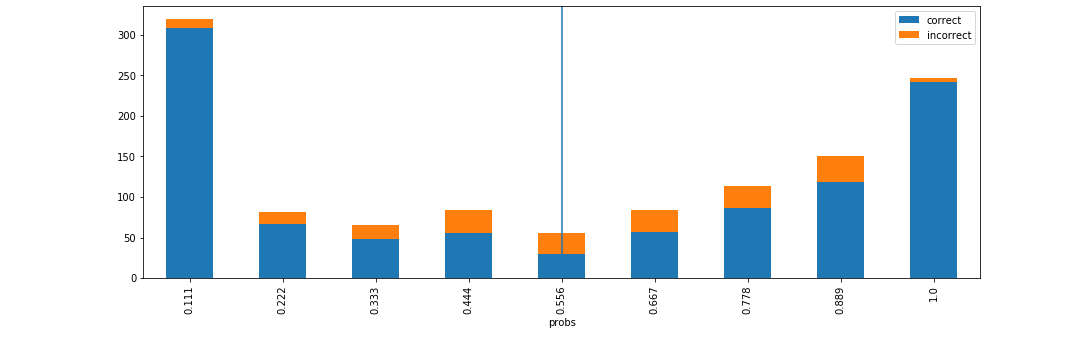
d = xai . smile_imbalance (
y_test ,
probabilities ,
display_breakdown = True )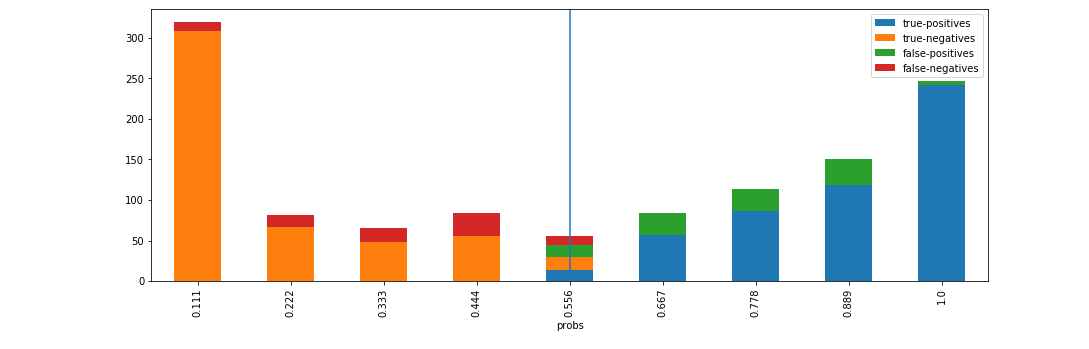
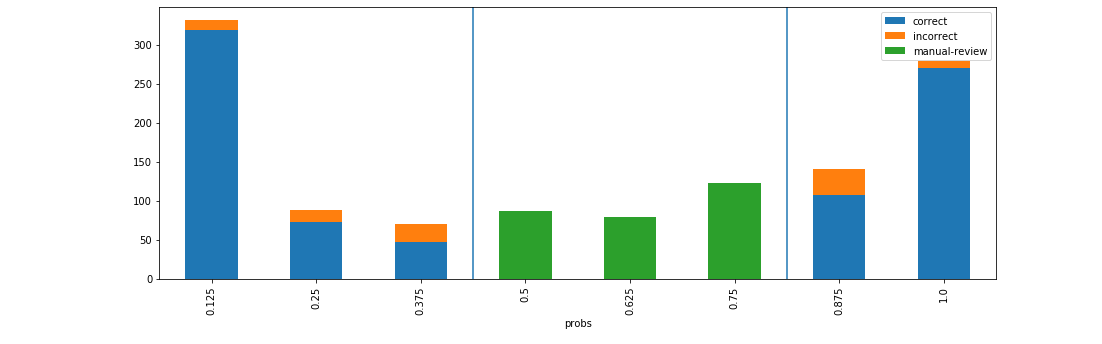
d = xai . smile_imbalance (
y_test ,
probabilities ,
bins = 9 ,
threshold = 0.75 ,
manual_review = 0.375 ,
display_breakdown = False )