xai
v0.1.0
XAI es una biblioteca de aprendizaje automático que está diseñada con AI Explicabilidad en su núcleo. XAI contiene varias herramientas que permiten el análisis y la evaluación de datos y modelos. La Biblioteca XAI es mantenida por el Instituto de AI y ML ética, y se desarrolló en base a los 8 principios para el aprendizaje automático responsable.
Puede encontrar la documentación en https://ethicalml.github.io/xai/index.html. También puede consultar nuestra charla en Tensorflow London donde se concibió la idea por primera vez: la charla también contiene una idea de las definiciones y principios en esta biblioteca.
| Este video de la charla presentada en la conferencia Pydata London 2019 que proporciona una visión general de las motivaciones para el aprendizaje automático, la explicabilidad, así como las técnicas para introducir la explicabilidad y mitigar los sesgos no deseados utilizando la Biblioteca XAI. |  |
| ¿Quieres aprender sobre más impresionantes herramientas de explicación de aprendizaje automático? Consulte nuestra lista de "producción y operaciones de aprendizaje automático impresionante" construida en la comunidad que contiene una extensa lista de herramientas para explicar, privacidad, orquestación y más allá. |  |
Si desea ver una demostración completamente funcional en clon de acción este repositorio y ejecute el cuaderno de ejemplo de Jupyter en la carpeta de ejemplos.
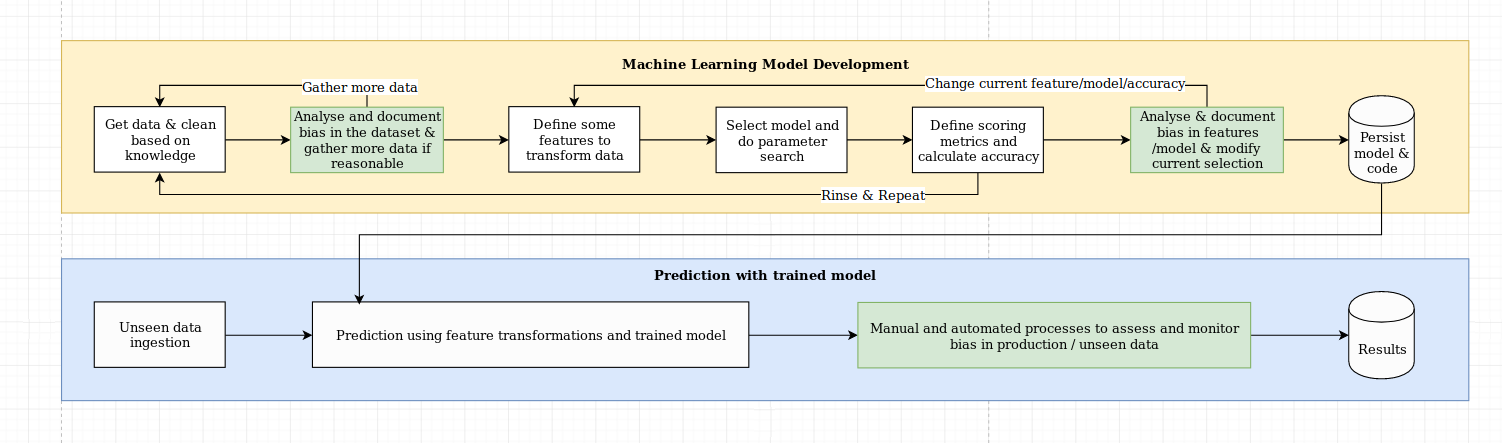
Vemos el desafío de la explicabilidad como algo más que un desafío algorítmico, que requiere una combinación de las mejores prácticas de ciencia de datos con conocimiento específico del dominio. La Biblioteca XAI está diseñada para capacitar a los ingenieros de aprendizaje automático y a los expertos en dominio relevantes para analizar la solución de extremo a extremo e identificar discrepancias que pueden dar como resultado un rendimiento subóptimo en relación con los objetivos requeridos. En términos más generales, la biblioteca XAI está diseñada utilizando 3 pasos de aprendizaje automático explicable, que implican 1) análisis de datos, 2) evaluación del modelo y 3) monitoreo de producción.
Proporcionamos una descripción visual de estos tres pasos mencionados anteriormente en este diagrama:
El paquete XAI está en PYPI. Para instalar puede ejecutar:
pip install xai
Alternativamente, puede instalar desde la fuente clonando el repositorio y en ejecución:
python setup.py install
Puede encontrar un uso de ejemplo en la carpeta de ejemplos.
Con XAI puede identificar desequilibrios en los datos. Para esto, cargaremos el conjunto de datos del censo de la Biblioteca XAI.
import xai . data
df = xai . data . load_census ()
df . head ()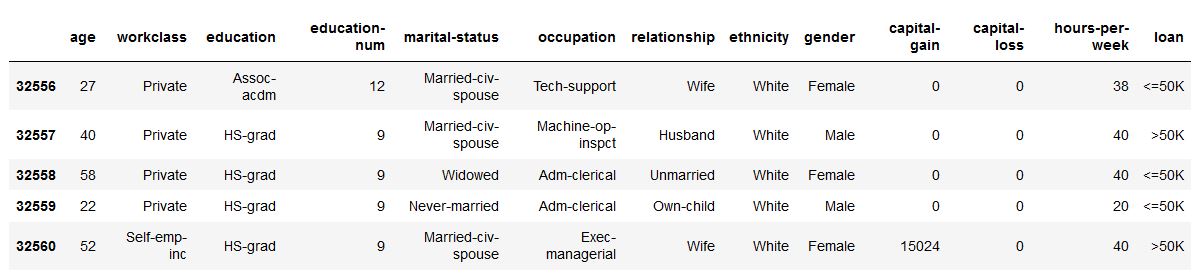
ims = xai . imbalance_plot ( df , "gender" )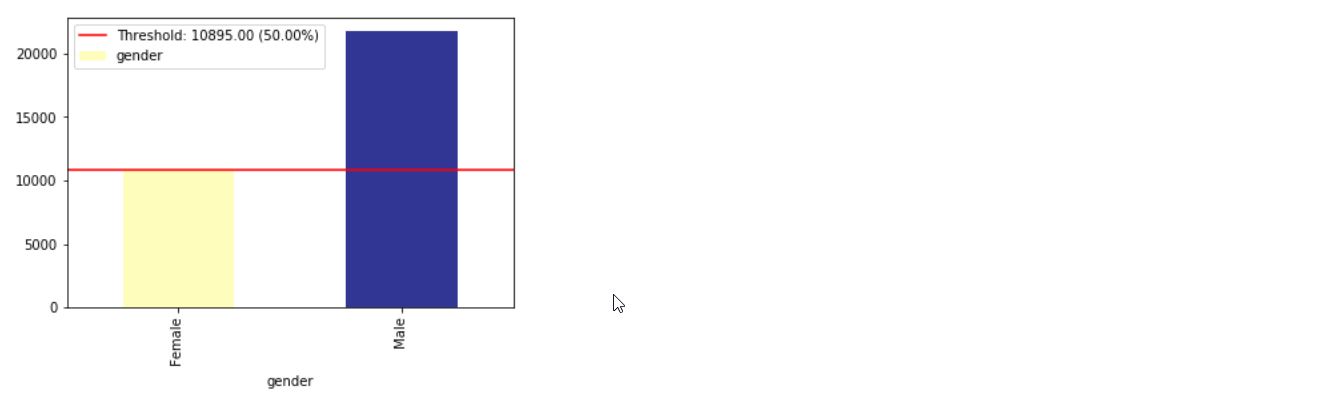
im = xai . imbalance_plot ( df , "gender" , "loan" )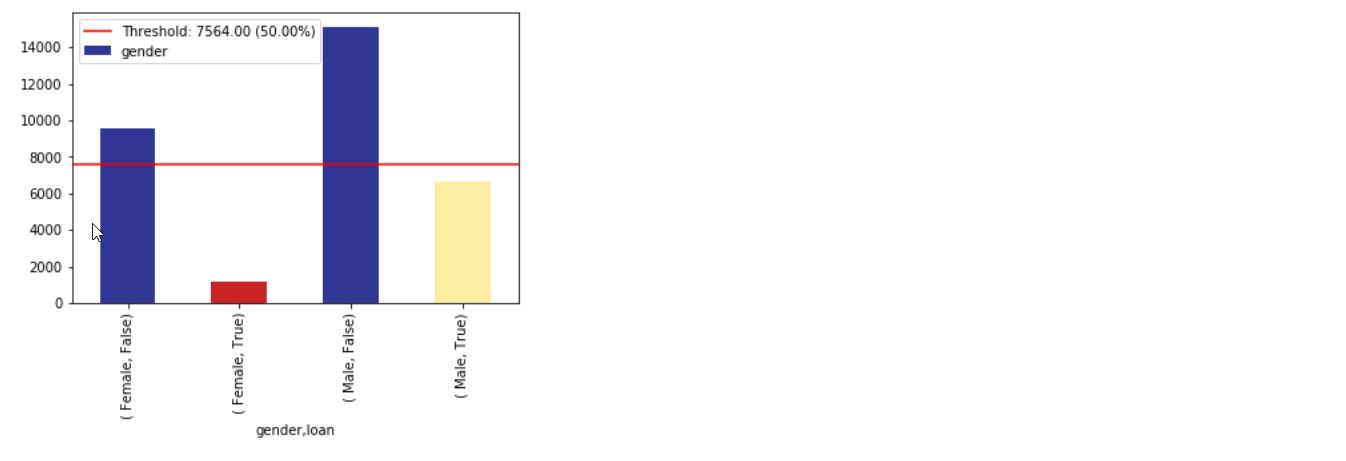
bal_df = xai . balance ( df , "gender" , "loan" , upsample = 0.8 )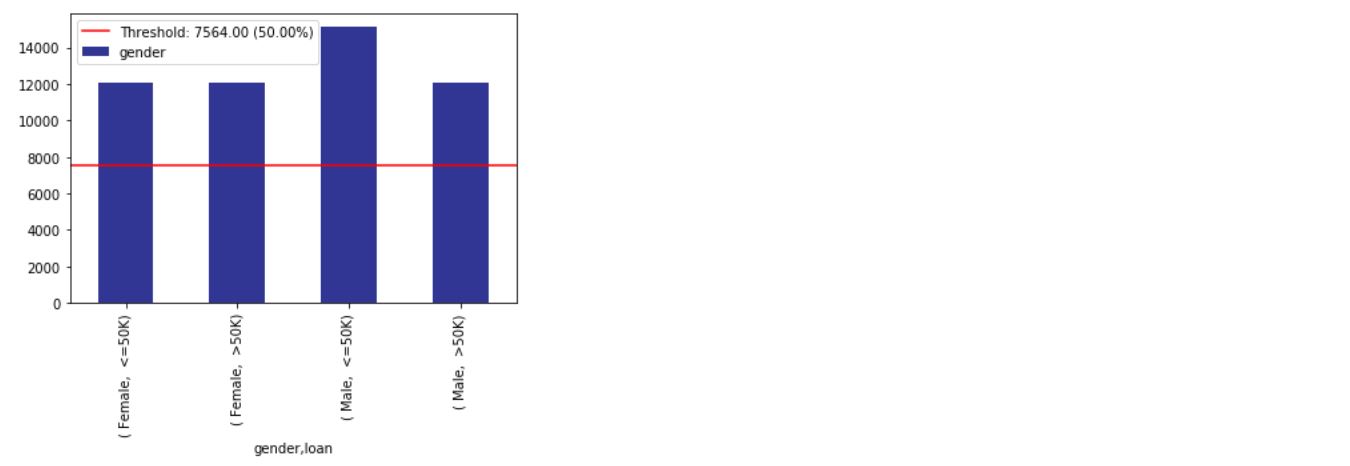
groups = xai . group_by_columns ( df , [ "gender" , "loan" ])
for group , group_df in groups :
print ( group )
print ( group_df [ "loan" ]. head (), " n " )
_ = xai . correlations ( df , include_categorical = True , plot_type = "matrix" )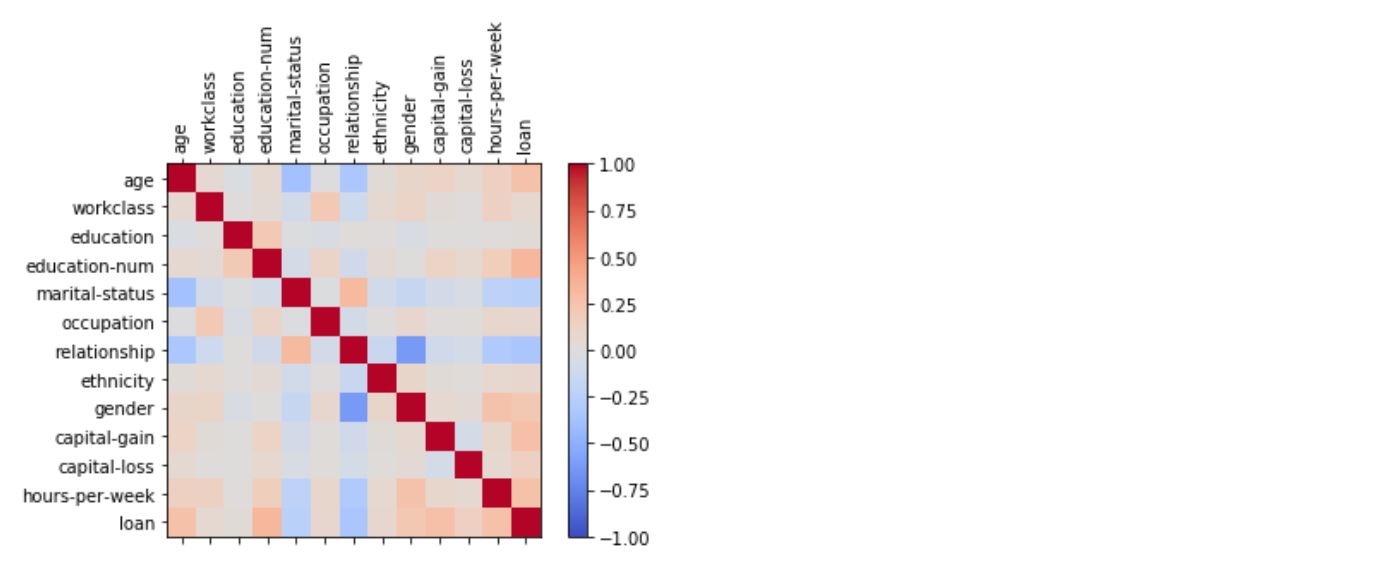
_ = xai . correlations ( df , include_categorical = True )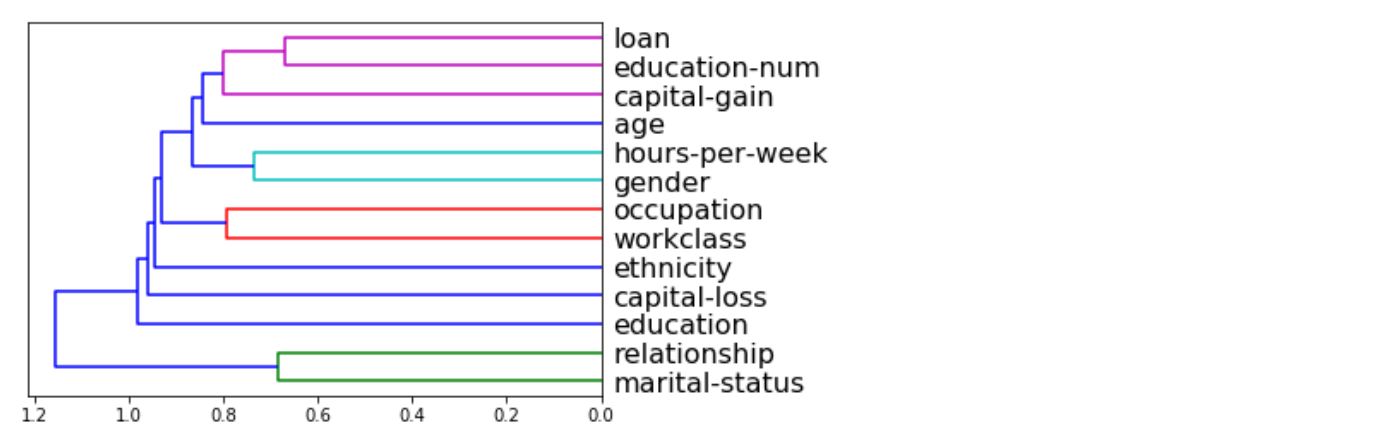
# Balanced train-test split with minimum 300 examples of
# the cross of the target y and the column gender
x_train , y_train , x_test , y_test , train_idx , test_idx =
xai . balanced_train_test_split (
x , y , "gender" ,
min_per_group = 300 ,
max_per_group = 300 ,
categorical_cols = categorical_cols )
x_train_display = bal_df [ train_idx ]
x_test_display = bal_df [ test_idx ]
print ( "Total number of examples: " , x_test . shape [ 0 ])
df_test = x_test_display . copy ()
df_test [ "loan" ] = y_test
_ = xai . imbalance_plot ( df_test , "gender" , "loan" , categorical_cols = categorical_cols )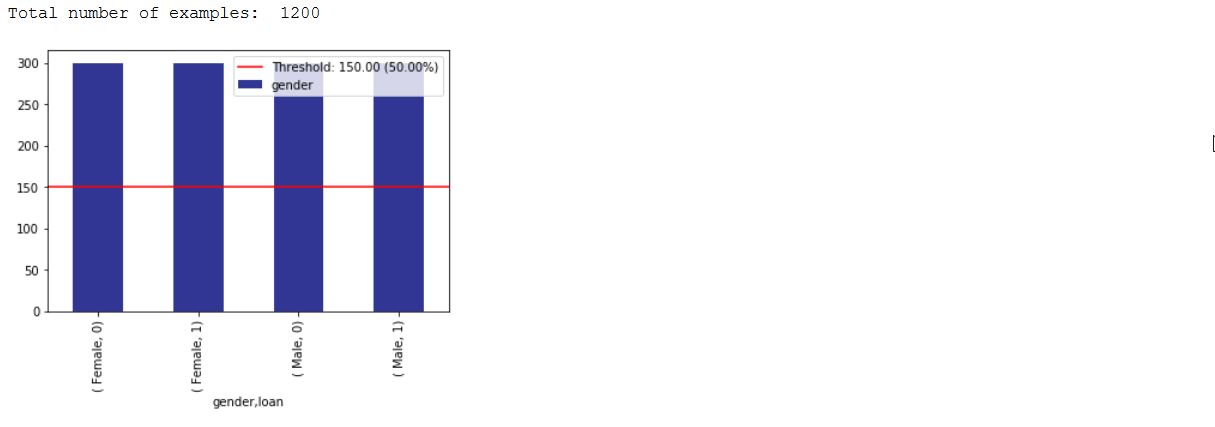
También podemos analizar la interacción entre los resultados de la inferencia y las características de entrada. Para esto, entrenaremos un modelo de aprendizaje profundo de una sola capa.
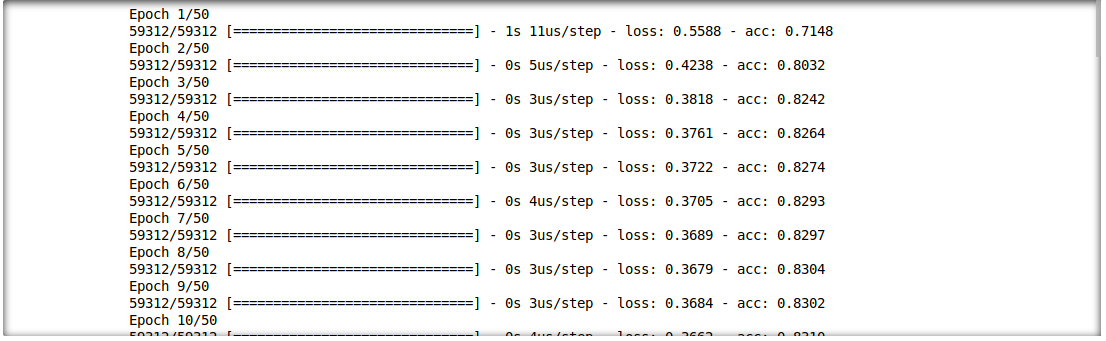
model = build_model(proc_df.drop("loan", axis=1))
model.fit(f_in(x_train), y_train, epochs=50, batch_size=512)
probabilities = model.predict(f_in(x_test))
predictions = list((probabilities >= 0.5).astype(int).T[0])
def get_avg ( x , y ):
return model . evaluate ( f_in ( x ), y , verbose = 0 )[ 1 ]
imp = xai . feature_importance ( x_test , y_test , get_avg )
imp . head ()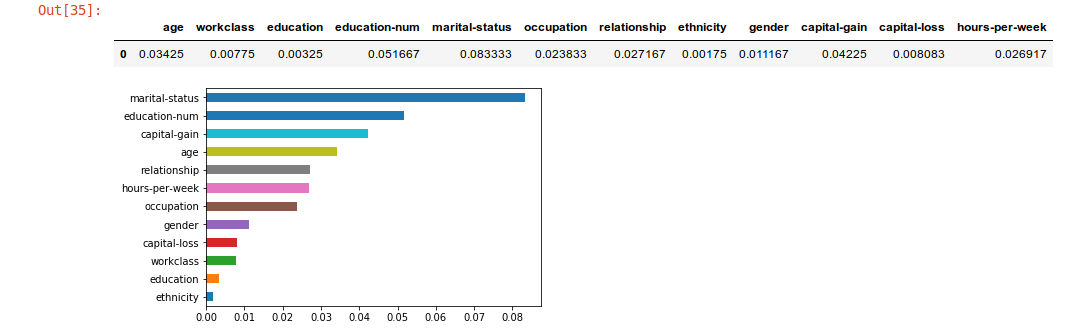
_ = xai . metrics_plot (
y_test ,
probabilities )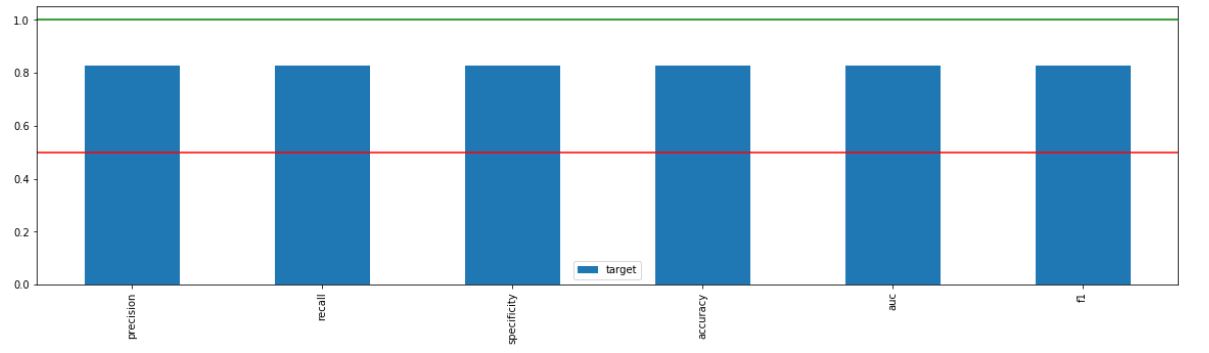
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" ],
categorical_cols = categorical_cols )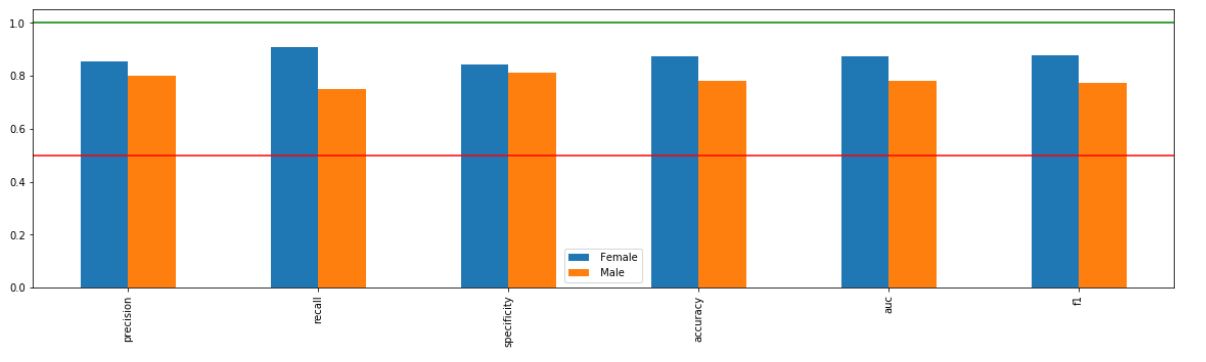
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" , "ethnicity" ],
categorical_cols = categorical_cols )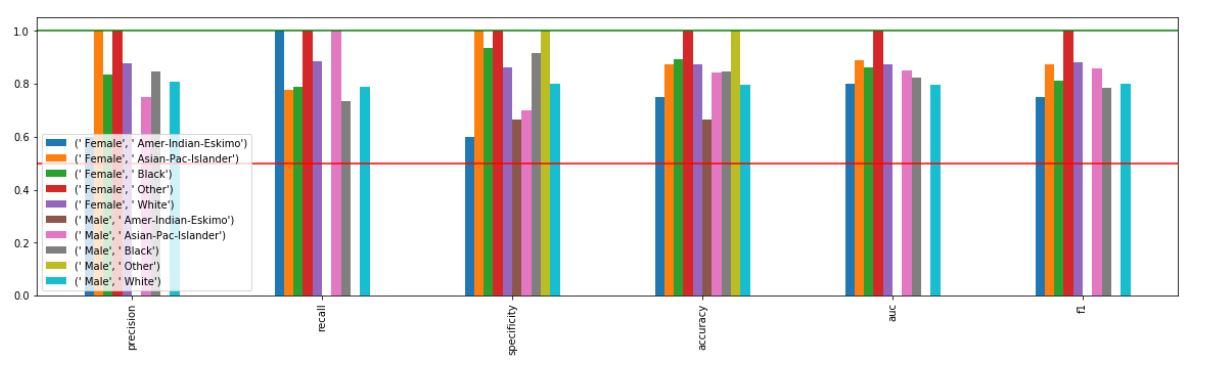
xai . confusion_matrix_plot ( y_test , pred )
_ = xai . roc_plot ( y_test , probabilities )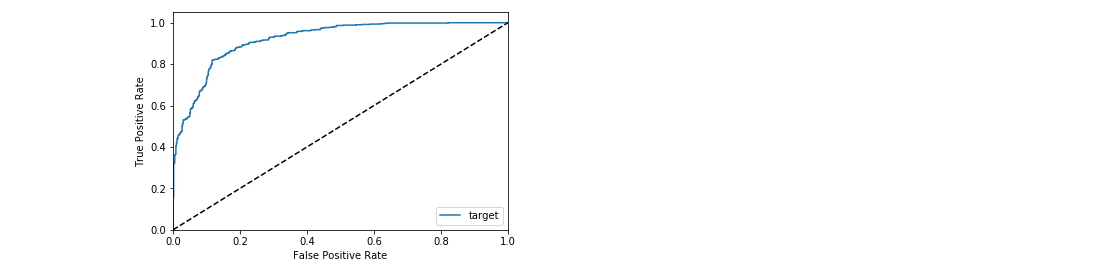
protected = [ "gender" , "ethnicity" , "age" ]
_ = [ xai . roc_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ p ],
categorical_cols = categorical_cols ) for p in protected ]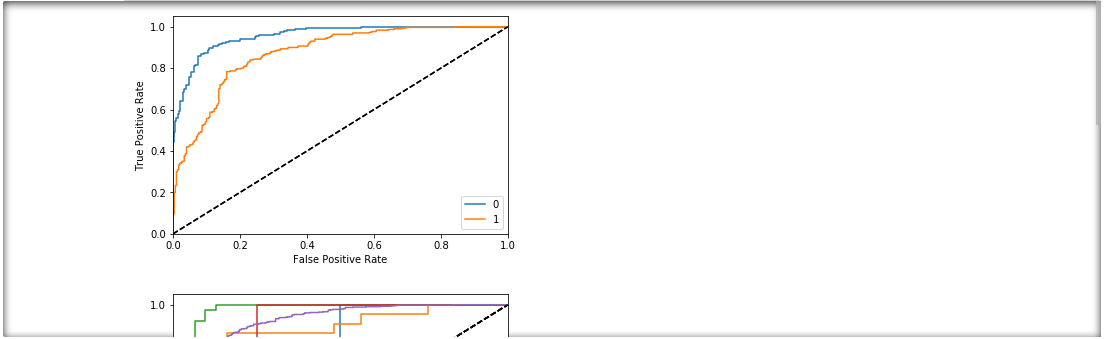
d = xai . smile_imbalance (
y_test ,
probabilities )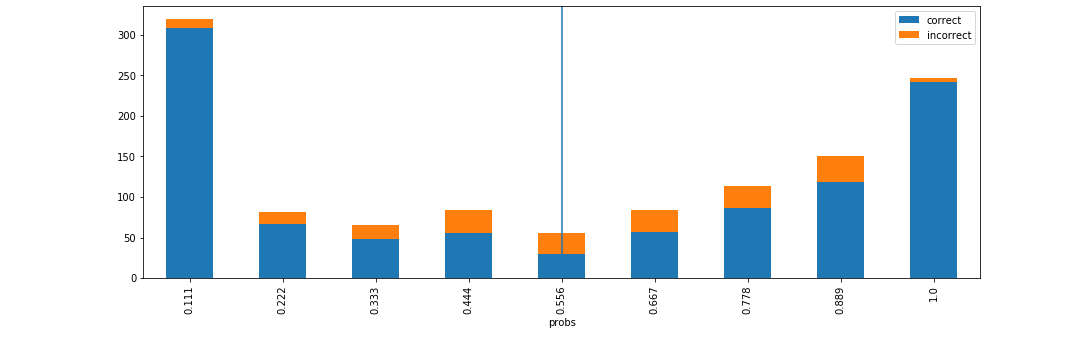
d = xai . smile_imbalance (
y_test ,
probabilities ,
display_breakdown = True )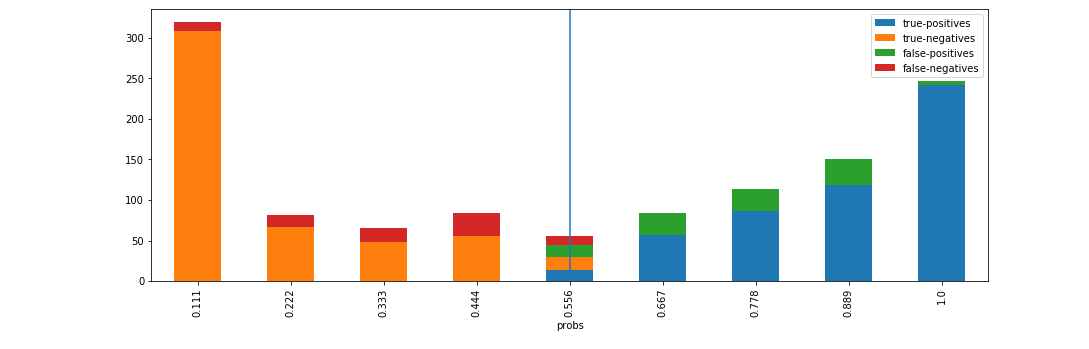
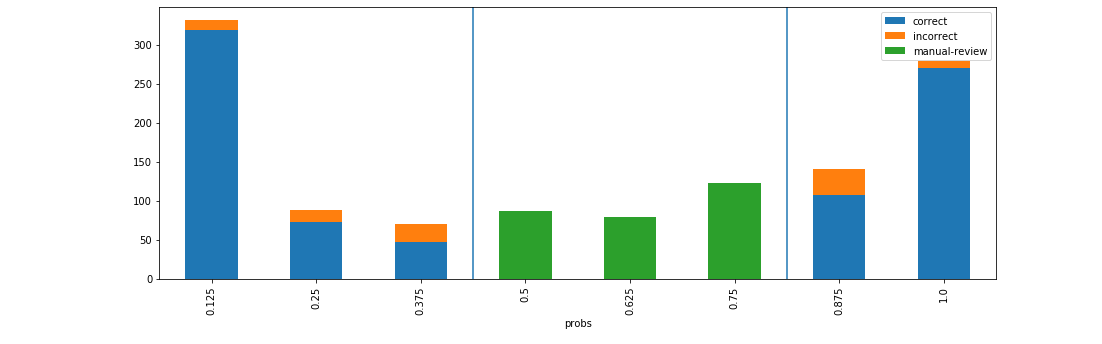
d = xai . smile_imbalance (
y_test ,
probabilities ,
bins = 9 ,
threshold = 0.75 ,
manual_review = 0.375 ,
display_breakdown = False )