xai
v0.1.0
XAI est une bibliothèque d'apprentissage automatique conçue avec l'explication de l'IA dans son cœur. XAI contient divers outils qui permettent une analyse et une évaluation des données et des modèles. La bibliothèque XAI est maintenue par l'Institute for Ethical AI & ML, et elle a été développée sur la base des 8 principes pour l'apprentissage automatique responsable.
Vous pouvez trouver la documentation sur https://ethicalml.github.io/xai/index.html. Vous pouvez également consulter notre discours à Tensorflow London où l'idée a été conçue pour la première fois - le discours contient également un aperçu des définitions et des principes de cette bibliothèque.
| Cette vidéo de la conférence présentée à la conférence Pydata London 2019 qui donne un aperçu des motivations de l'explication de l'apprentissage automatique ainsi que des techniques pour introduire l'explication et atténuer les biais indésirables à l'aide de la bibliothèque XAI. |  |
| Voulez-vous en savoir plus sur les outils d'explication de l'apprentissage automatique plus impressionnants? Consultez notre liste de «production et opérations d'apprentissage automatique impressionnantes» qui contient une vaste liste d'outils d'explication, de confidentialité, d'orchestration et au-delà. |  |
Si vous souhaitez voir une démo entièrement fonctionnelle en action clone ce dépôt et exécuter l'exemple de cahier Jupyter dans le dossier Exemples.
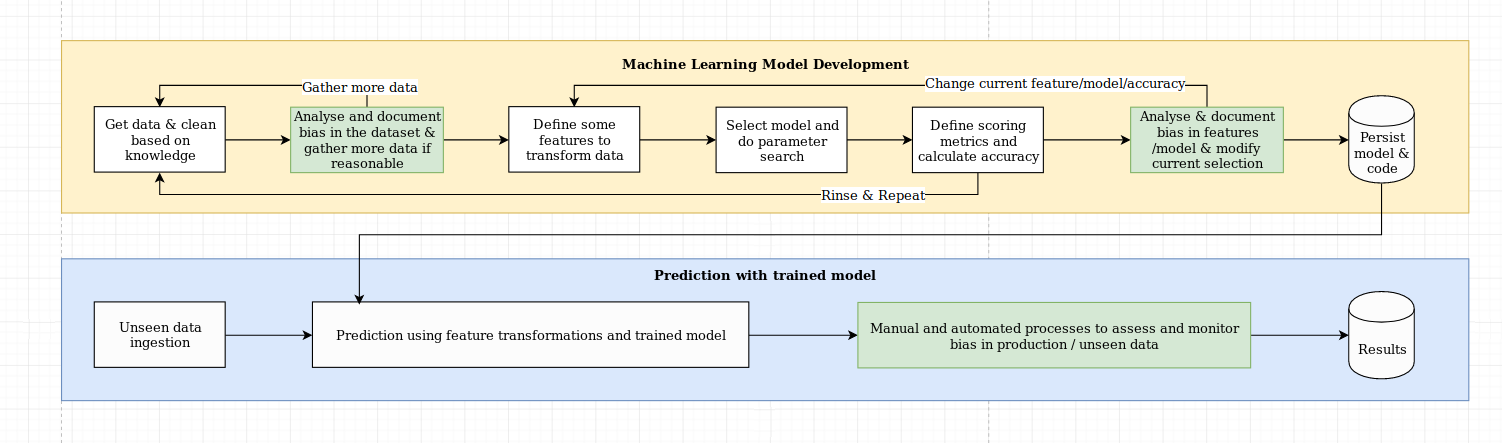
Nous considérons le défi de l'explication comme plus qu'un simple défi algorithmique, qui nécessite une combinaison de meilleures pratiques de science des données avec des connaissances spécifiques au domaine. La bibliothèque XAI est conçue pour autonomiser les ingénieurs d'apprentissage automatique et les experts du domaine pertinents pour analyser la solution de bout en bout et identifier les écarts qui peuvent entraîner des performances sous-optimales par rapport aux objectifs requis. Plus largement, la bibliothèque XAI est conçue en utilisant les 3 étapes de l'apprentissage automatique explicable, qui implique 1) l'analyse des données, 2) l'évaluation du modèle et 3) le suivi de la production.
Nous fournissons un aperçu visuel de ces trois étapes mentionnées ci-dessus dans ce diagramme:
Le package XAI est sur PYPI. Pour installer, vous pouvez exécuter:
pip install xai
Vous pouvez également installer à partir de la source en clonage le repo et en cours d'exécution:
python setup.py install
Vous pouvez trouver des exemples d'utilisation dans le dossier Exemples.
Avec XAI, vous pouvez identifier les déséquilibres dans les données. Pour cela, nous chargerons l'ensemble de données de recensement de la bibliothèque XAI.
import xai . data
df = xai . data . load_census ()
df . head ()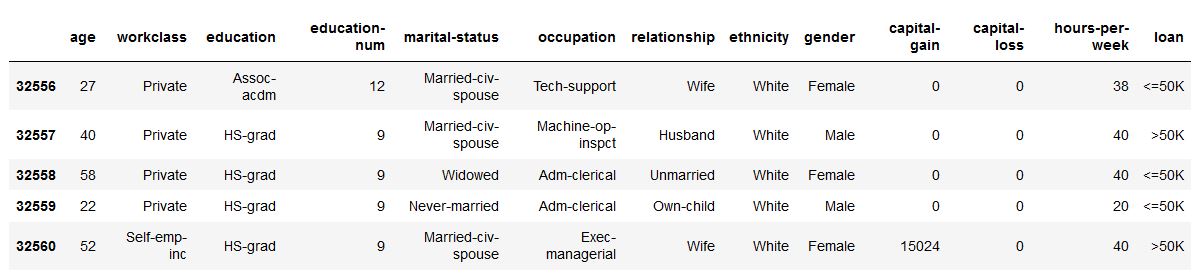
ims = xai . imbalance_plot ( df , "gender" )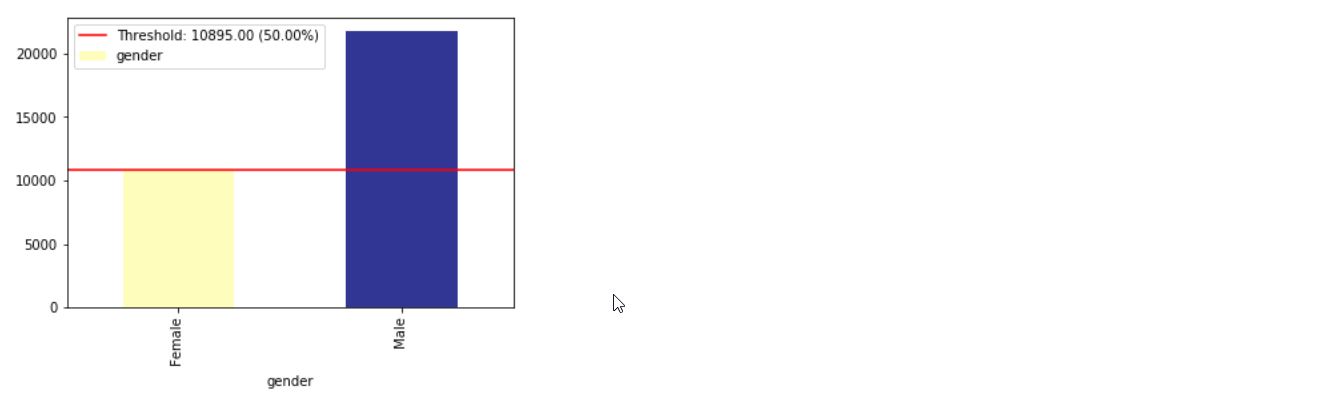
im = xai . imbalance_plot ( df , "gender" , "loan" )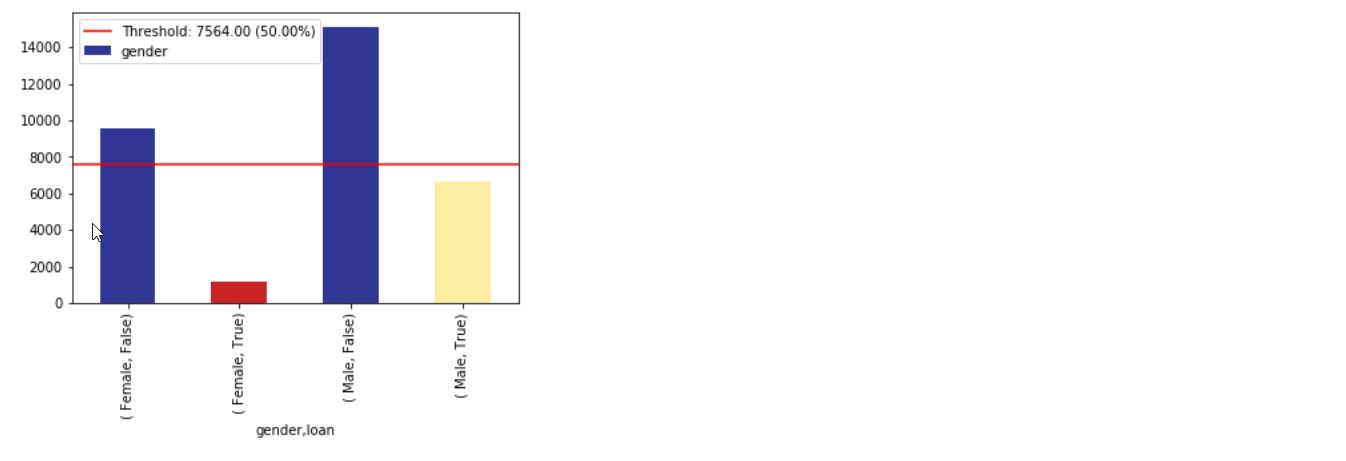
bal_df = xai . balance ( df , "gender" , "loan" , upsample = 0.8 )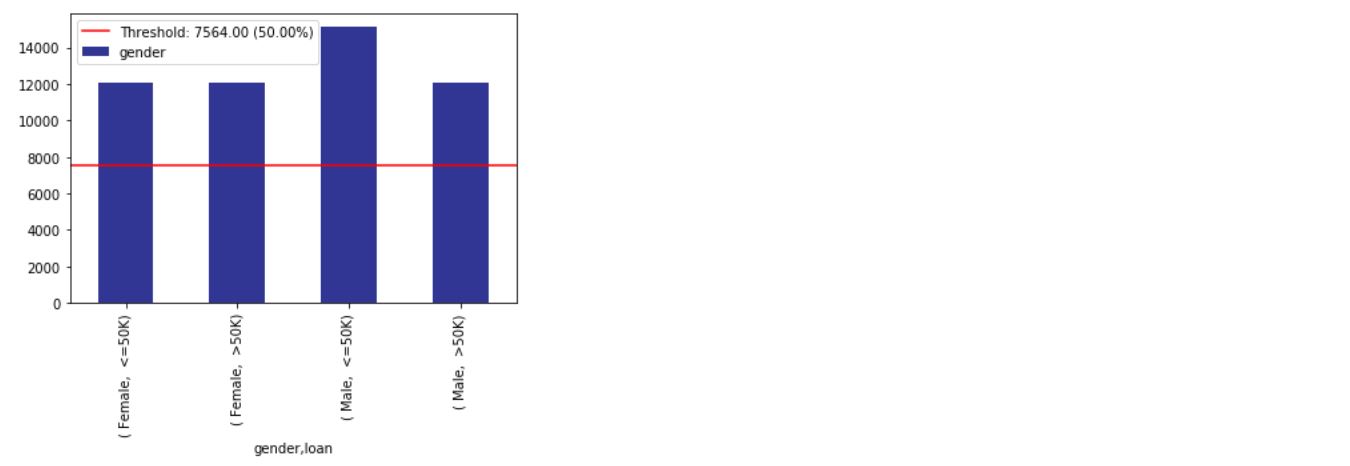
groups = xai . group_by_columns ( df , [ "gender" , "loan" ])
for group , group_df in groups :
print ( group )
print ( group_df [ "loan" ]. head (), " n " )
_ = xai . correlations ( df , include_categorical = True , plot_type = "matrix" )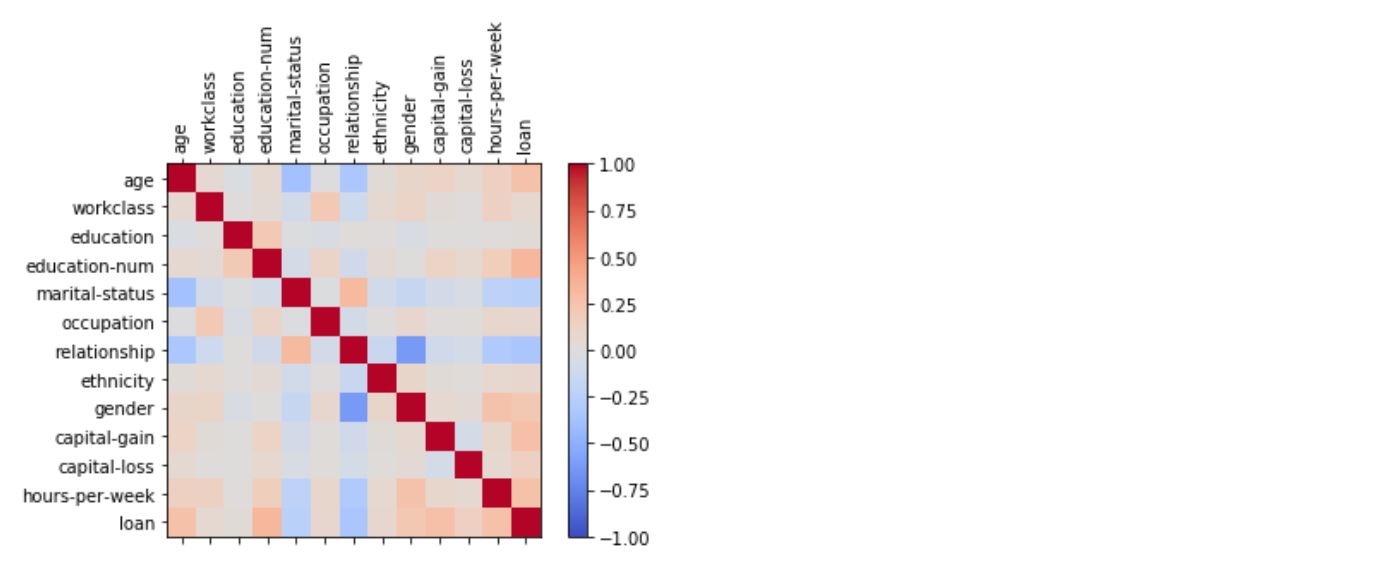
_ = xai . correlations ( df , include_categorical = True )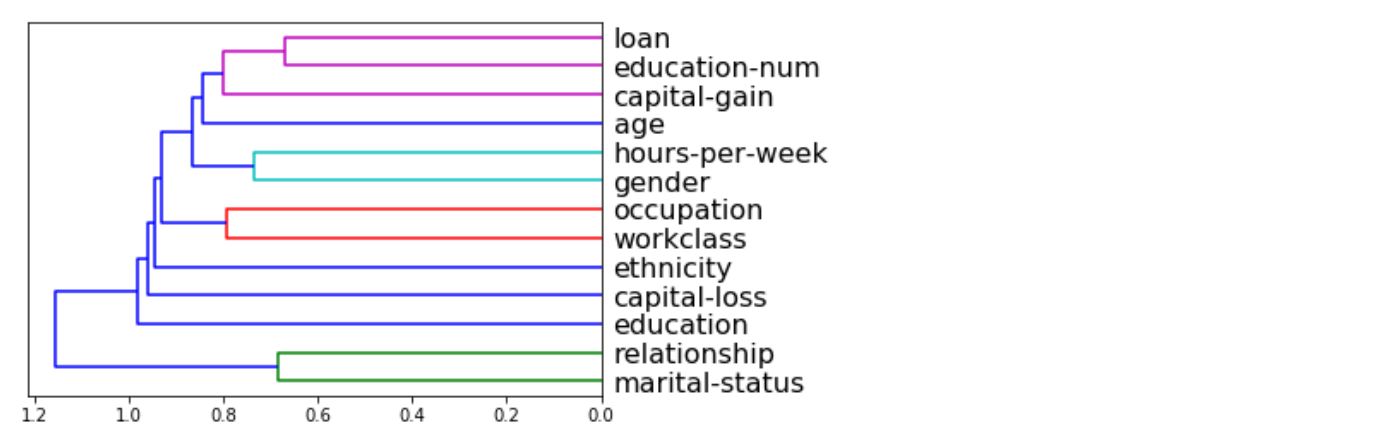
# Balanced train-test split with minimum 300 examples of
# the cross of the target y and the column gender
x_train , y_train , x_test , y_test , train_idx , test_idx =
xai . balanced_train_test_split (
x , y , "gender" ,
min_per_group = 300 ,
max_per_group = 300 ,
categorical_cols = categorical_cols )
x_train_display = bal_df [ train_idx ]
x_test_display = bal_df [ test_idx ]
print ( "Total number of examples: " , x_test . shape [ 0 ])
df_test = x_test_display . copy ()
df_test [ "loan" ] = y_test
_ = xai . imbalance_plot ( df_test , "gender" , "loan" , categorical_cols = categorical_cols )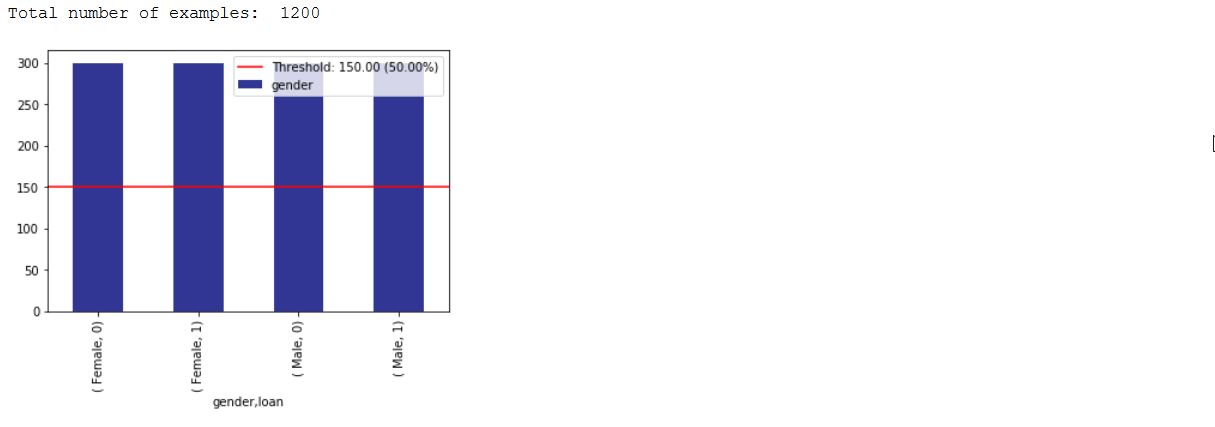
Nous sommes en mesure d'analyser également l'interaction entre les résultats d'inférence et les caractéristiques d'entrée. Pour cela, nous allons former un modèle d'apprentissage en profondeur unique.
model = build_model(proc_df.drop("loan", axis=1))
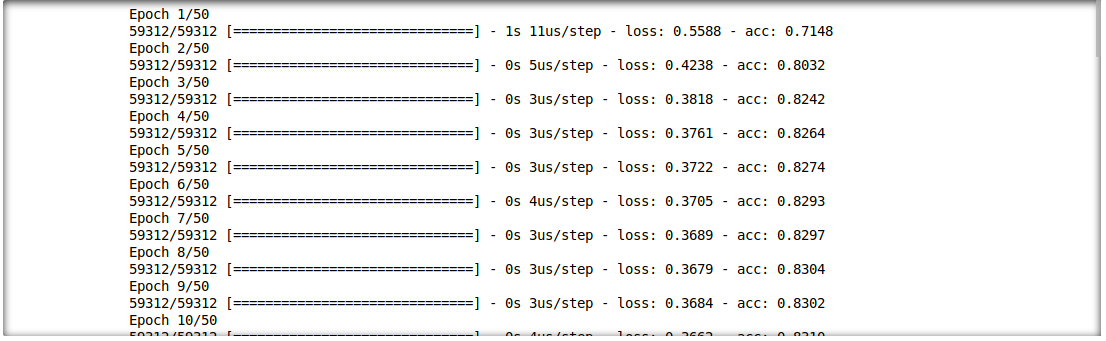
model.fit(f_in(x_train), y_train, epochs=50, batch_size=512)
probabilities = model.predict(f_in(x_test))
predictions = list((probabilities >= 0.5).astype(int).T[0])
def get_avg ( x , y ):
return model . evaluate ( f_in ( x ), y , verbose = 0 )[ 1 ]
imp = xai . feature_importance ( x_test , y_test , get_avg )
imp . head ()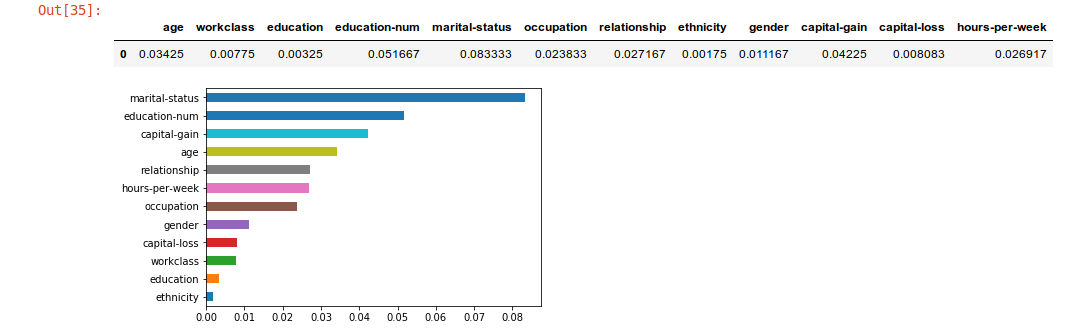
_ = xai . metrics_plot (
y_test ,
probabilities )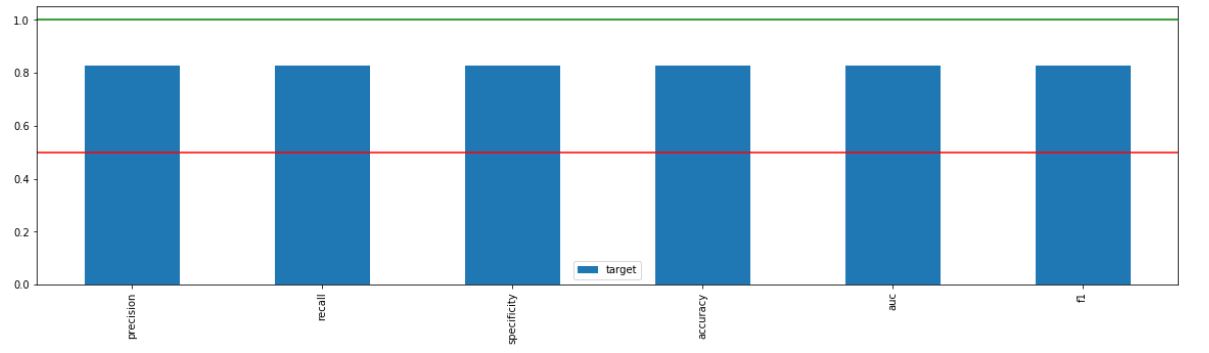
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" ],
categorical_cols = categorical_cols )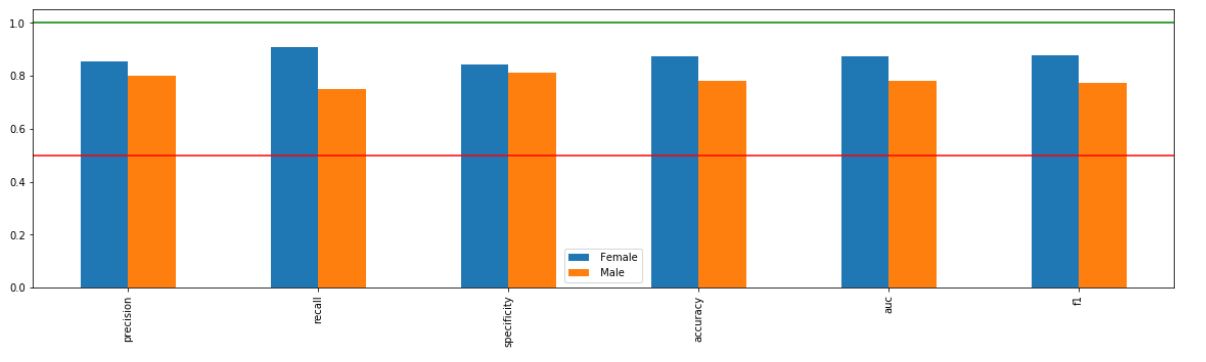
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" , "ethnicity" ],
categorical_cols = categorical_cols )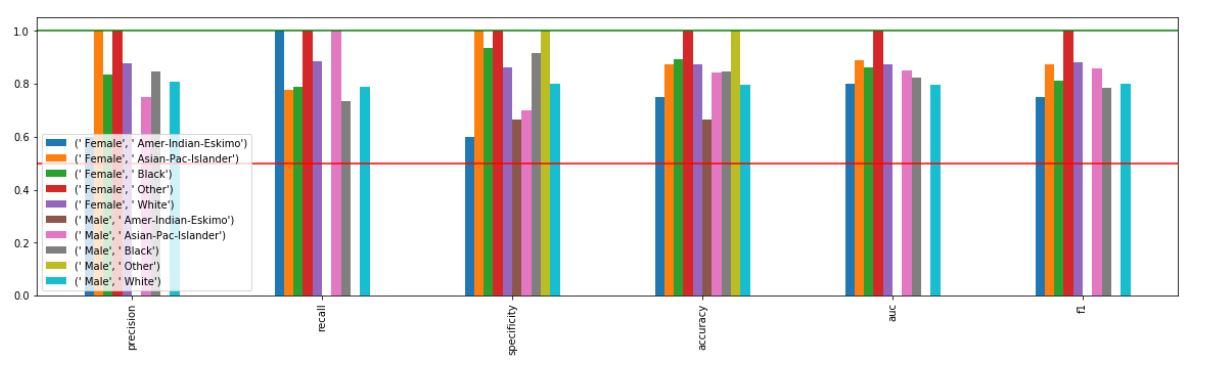
xai . confusion_matrix_plot ( y_test , pred )
_ = xai . roc_plot ( y_test , probabilities )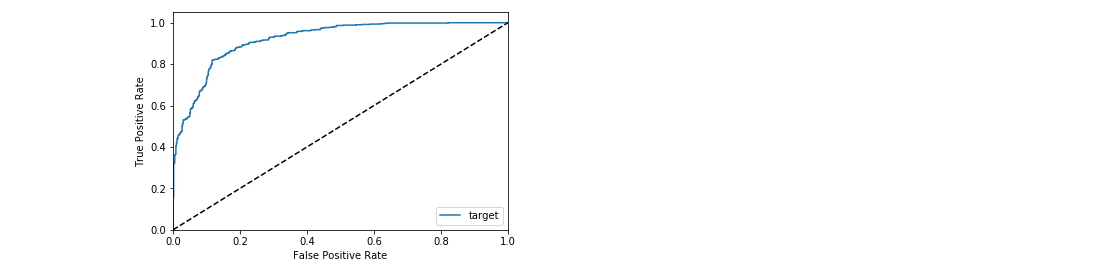
protected = [ "gender" , "ethnicity" , "age" ]
_ = [ xai . roc_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ p ],
categorical_cols = categorical_cols ) for p in protected ]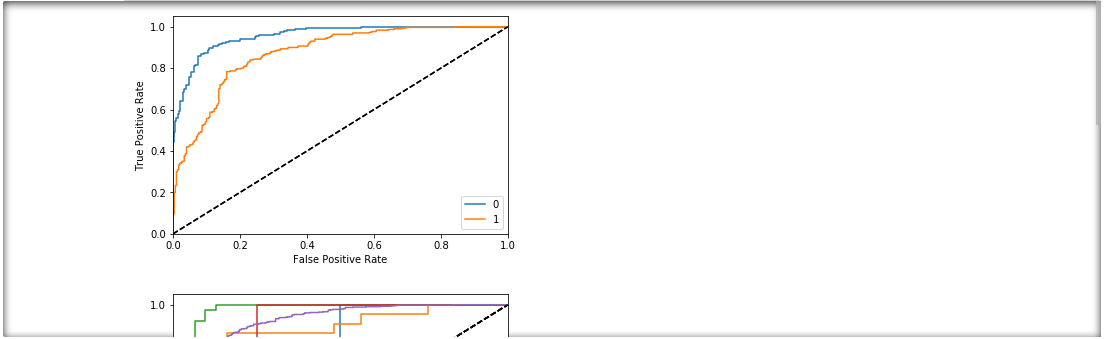
d = xai . smile_imbalance (
y_test ,
probabilities )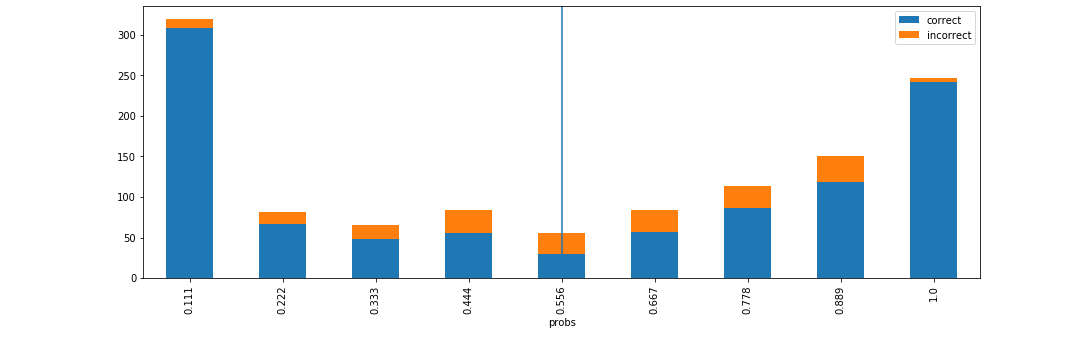
d = xai . smile_imbalance (
y_test ,
probabilities ,
display_breakdown = True )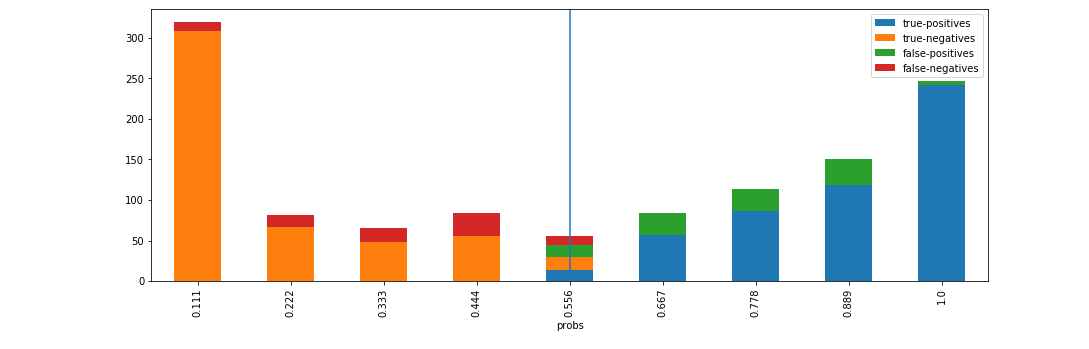
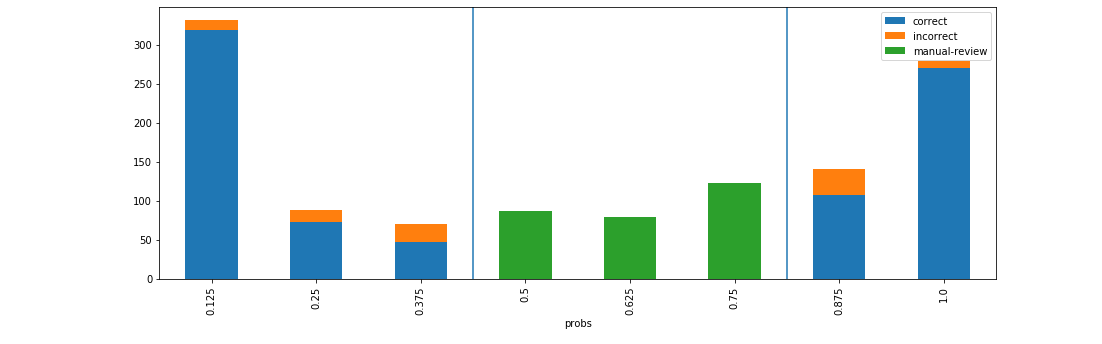
d = xai . smile_imbalance (
y_test ,
probabilities ,
bins = 9 ,
threshold = 0.75 ,
manual_review = 0.375 ,
display_breakdown = False )