xai
v0.1.0
O XAI é uma biblioteca de aprendizado de máquina projetada com a explicação da IA em seu núcleo. O XAI contém várias ferramentas que permitem a análise e avaliação de dados e modelos. A Biblioteca XAI é mantida pelo Instituto de AI e ML ética e foi desenvolvida com base nos 8 princípios para o aprendizado de máquina responsável.
Você pode encontrar a documentação em https://ethicalml.github.io/xai/index.html. Você também pode conferir nossa palestra no Tensorflow London, onde a idéia foi concebida pela primeira vez - a palestra também contém uma visão das definições e princípios nesta biblioteca.
| Este vídeo da palestra apresentada na Conferência Pydata London 2019, que fornece uma visão geral sobre as motivações para a explicação da aprendizagem de máquina, bem como as técnicas para introduzir a explicação e mitigar vieses indesejados usando a biblioteca XAI. |  |
| Você quer aprender sobre mais impressionantes ferramentas de explicação de aprendizado de máquina? Confira nossa lista "Awesome Awesome Learning Learning Production & Operations", criada pela comunidade, que contém uma extensa lista de ferramentas para explicar, privacidade, orquestração e além. |  |
Se você deseja ver uma demonstração totalmente funcional no clone de ação este repo e executar o exemplo de notebook Jupyter na pasta Exemplos.
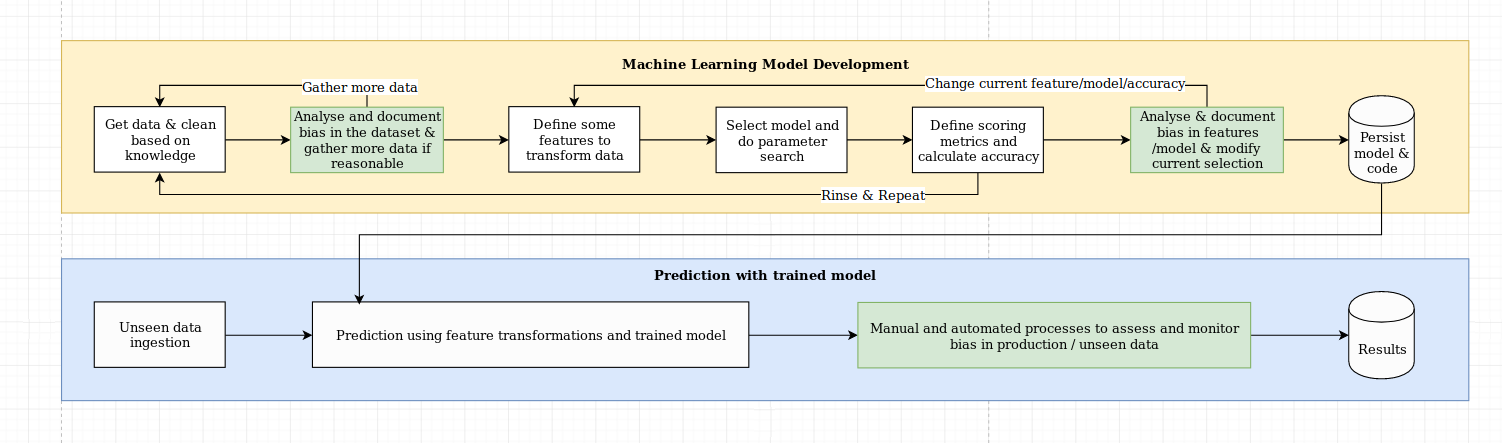
Vemos o desafio da explicação como mais do que apenas um desafio algorítmico, que requer uma combinação de melhores práticas de ciência de dados com conhecimento específico do domínio. A biblioteca XAI foi projetada para capacitar engenheiros de aprendizado de máquina e especialistas relevantes de domínio para analisar a solução de ponta a ponta e identificar discrepâncias que podem resultar em desempenho subótimo em relação aos objetivos necessários. De maneira mais ampla, a biblioteca XAI foi projetada usando os 3 etapas do aprendizado de máquina explicável, que envolve 1) análise de dados, 2) avaliação do modelo e 3) monitoramento da produção.
Fornecemos uma visão geral visual dessas três etapas mencionadas acima neste diagrama:
O pacote XAI está no Pypi. Para instalar você pode executar:
pip install xai
Como alternativa, você pode instalar a partir da fonte clonando o repositório e executando:
python setup.py install
Você pode encontrar um exemplo de uso na pasta Exemplos.
Com o XAI, você pode identificar desequilíbrios nos dados. Para isso, carregaremos o conjunto de dados do censo na biblioteca XAI.
import xai . data
df = xai . data . load_census ()
df . head ()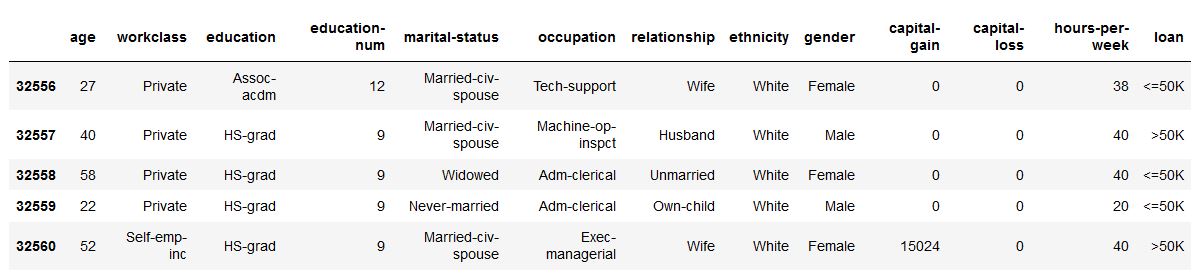
ims = xai . imbalance_plot ( df , "gender" )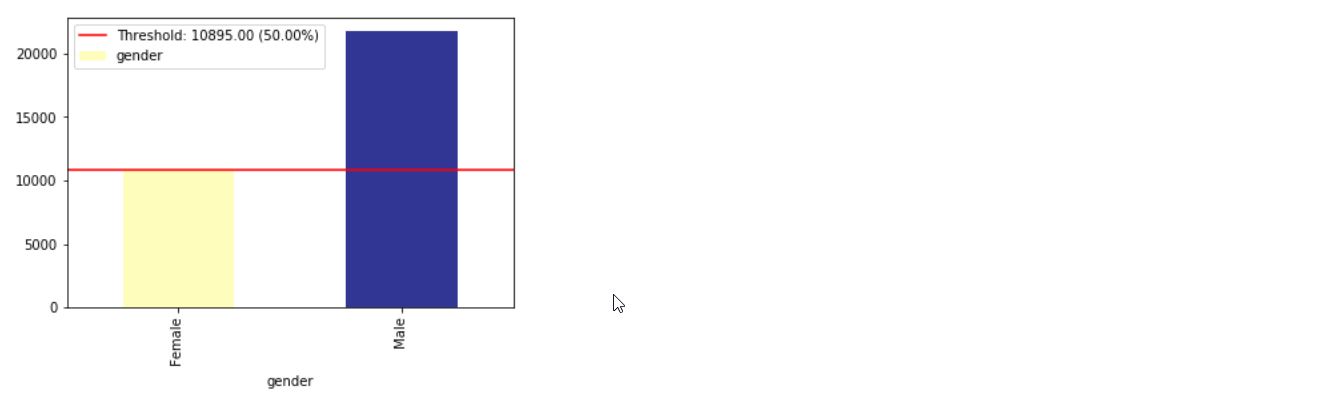
im = xai . imbalance_plot ( df , "gender" , "loan" )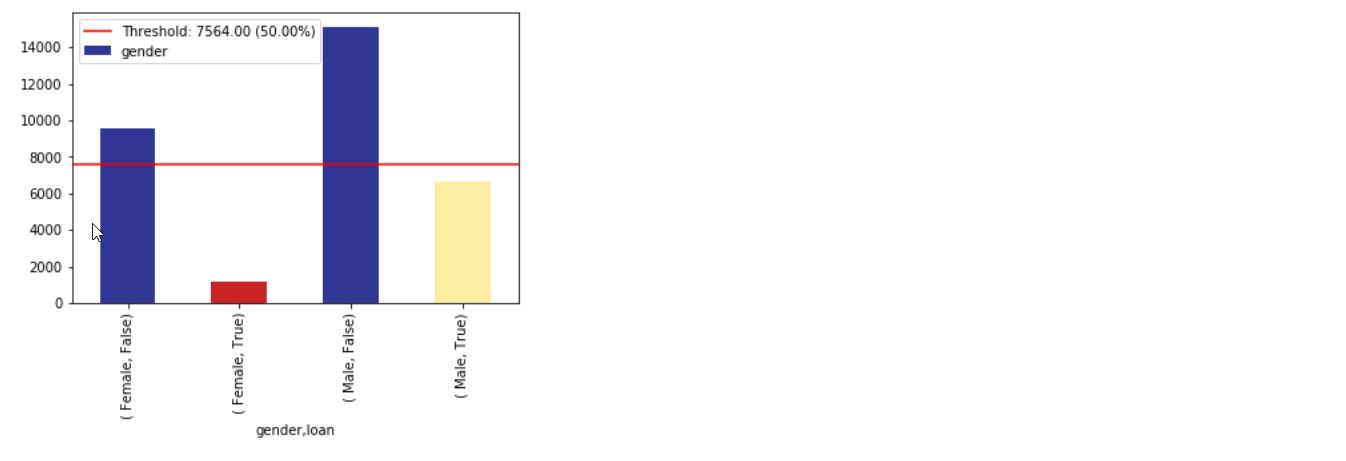
bal_df = xai . balance ( df , "gender" , "loan" , upsample = 0.8 )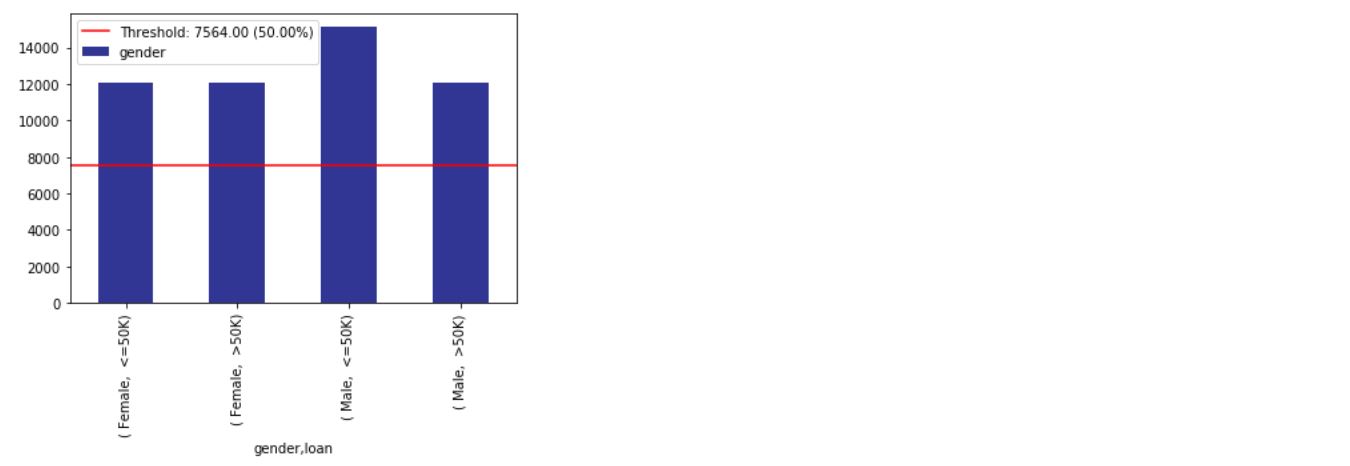
groups = xai . group_by_columns ( df , [ "gender" , "loan" ])
for group , group_df in groups :
print ( group )
print ( group_df [ "loan" ]. head (), " n " )
_ = xai . correlations ( df , include_categorical = True , plot_type = "matrix" )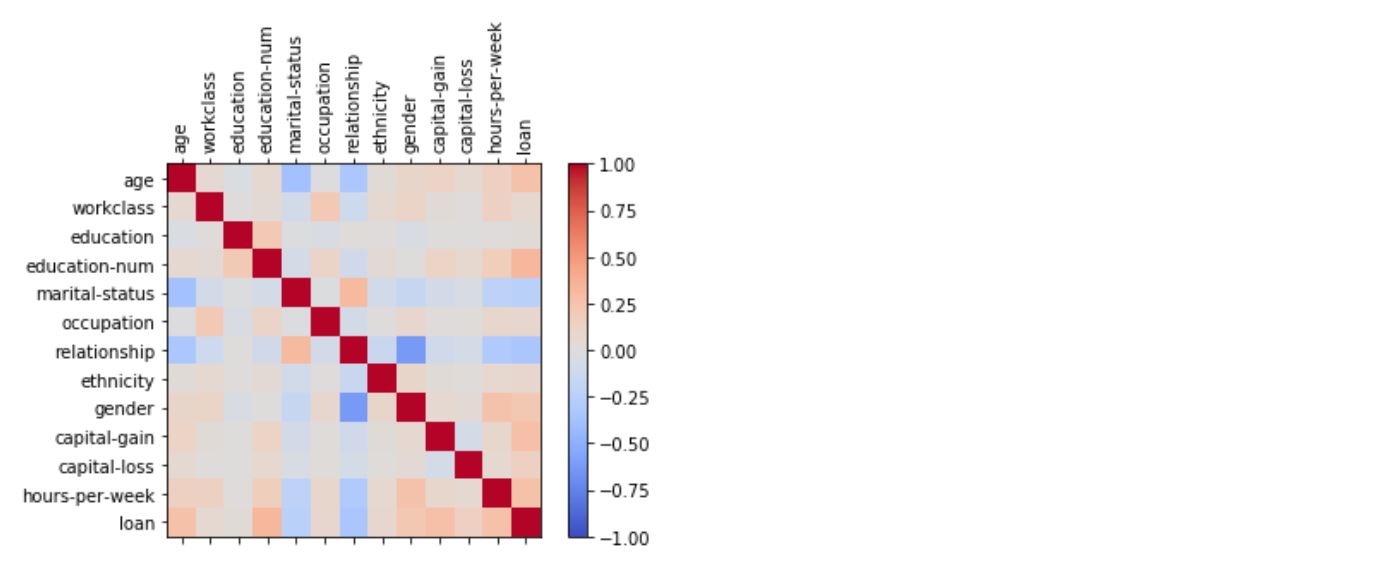
_ = xai . correlations ( df , include_categorical = True )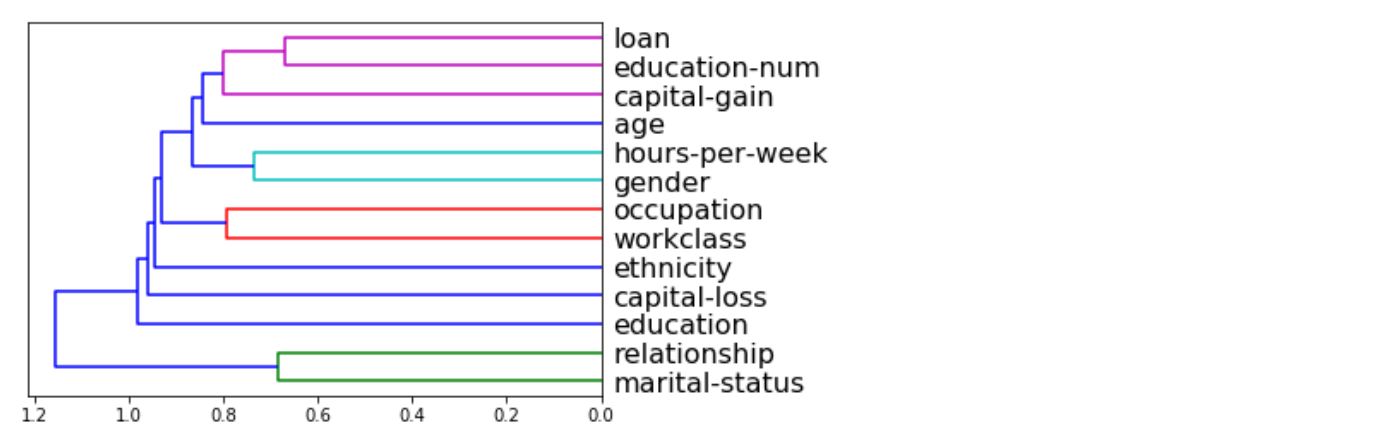
# Balanced train-test split with minimum 300 examples of
# the cross of the target y and the column gender
x_train , y_train , x_test , y_test , train_idx , test_idx =
xai . balanced_train_test_split (
x , y , "gender" ,
min_per_group = 300 ,
max_per_group = 300 ,
categorical_cols = categorical_cols )
x_train_display = bal_df [ train_idx ]
x_test_display = bal_df [ test_idx ]
print ( "Total number of examples: " , x_test . shape [ 0 ])
df_test = x_test_display . copy ()
df_test [ "loan" ] = y_test
_ = xai . imbalance_plot ( df_test , "gender" , "loan" , categorical_cols = categorical_cols )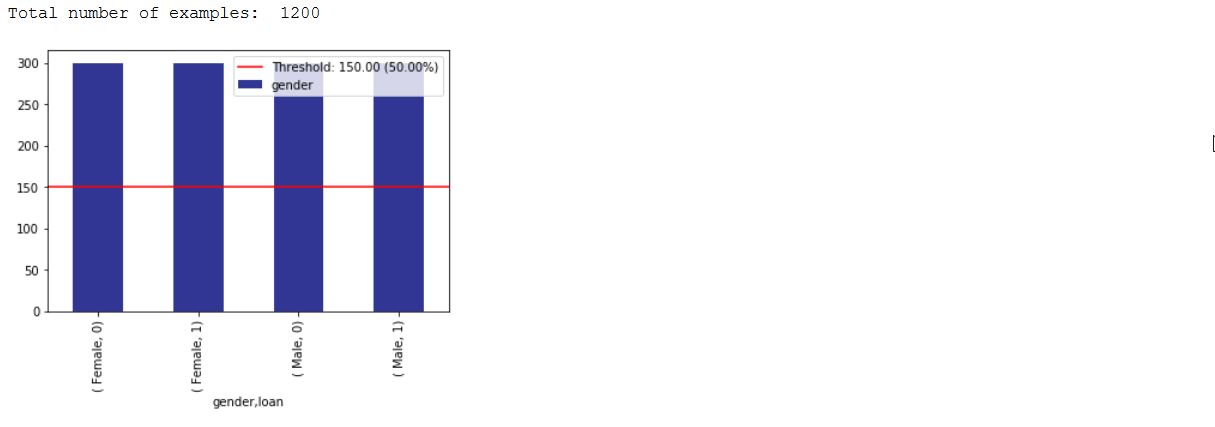
Também podemos analisar a interação entre os resultados da inferência e os recursos de entrada. Para isso, treinaremos um modelo de aprendizado profundo de camada única.
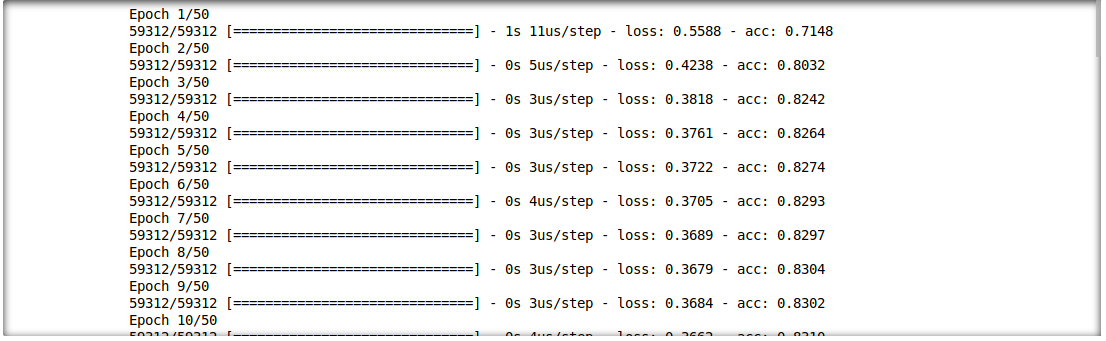
model = build_model(proc_df.drop("loan", axis=1))
model.fit(f_in(x_train), y_train, epochs=50, batch_size=512)
probabilities = model.predict(f_in(x_test))
predictions = list((probabilities >= 0.5).astype(int).T[0])
def get_avg ( x , y ):
return model . evaluate ( f_in ( x ), y , verbose = 0 )[ 1 ]
imp = xai . feature_importance ( x_test , y_test , get_avg )
imp . head ()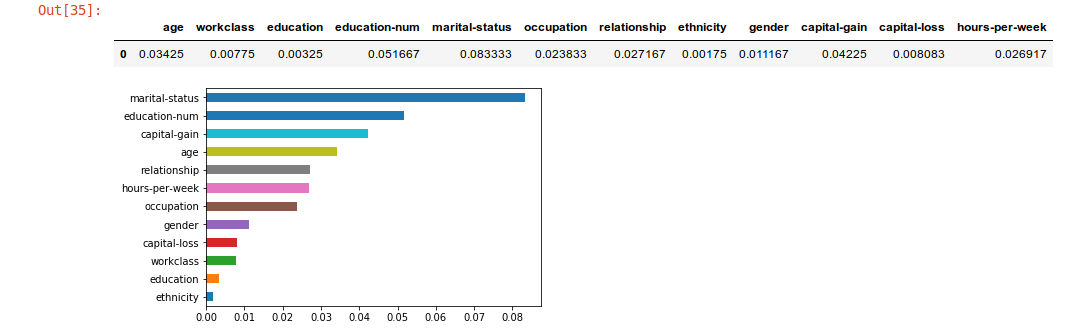
_ = xai . metrics_plot (
y_test ,
probabilities )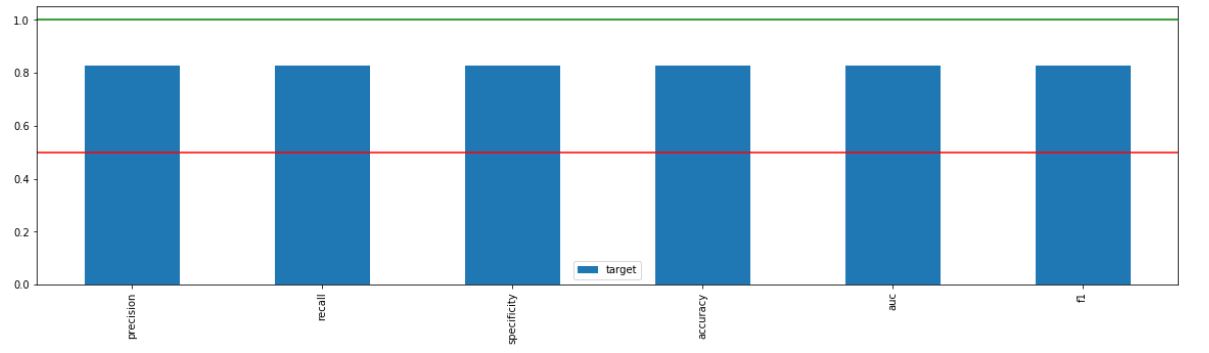
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" ],
categorical_cols = categorical_cols )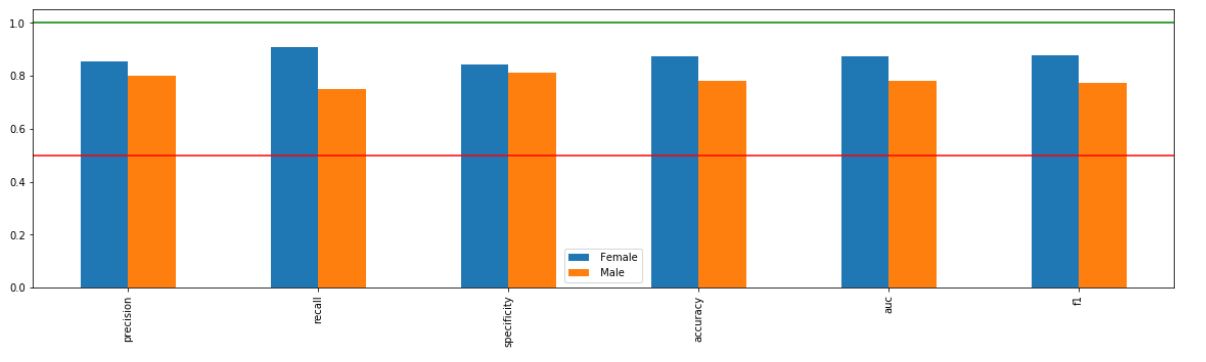
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" , "ethnicity" ],
categorical_cols = categorical_cols )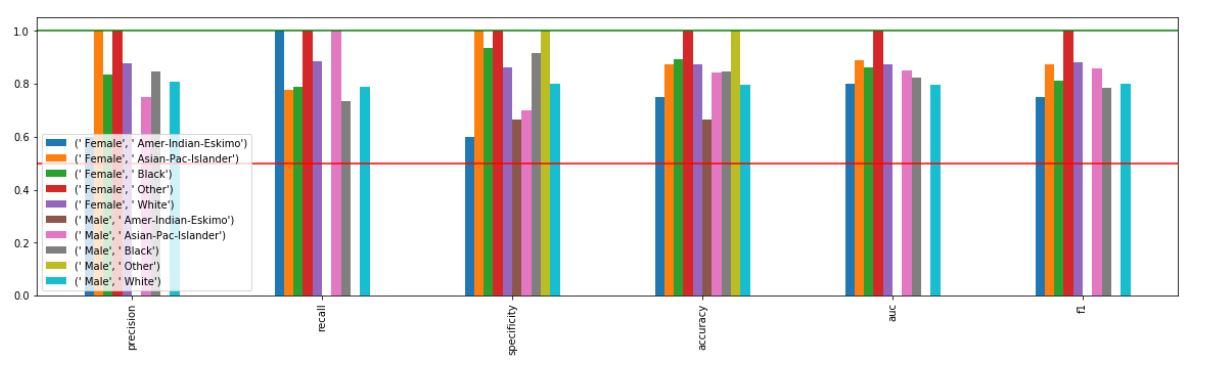
xai . confusion_matrix_plot ( y_test , pred )
_ = xai . roc_plot ( y_test , probabilities )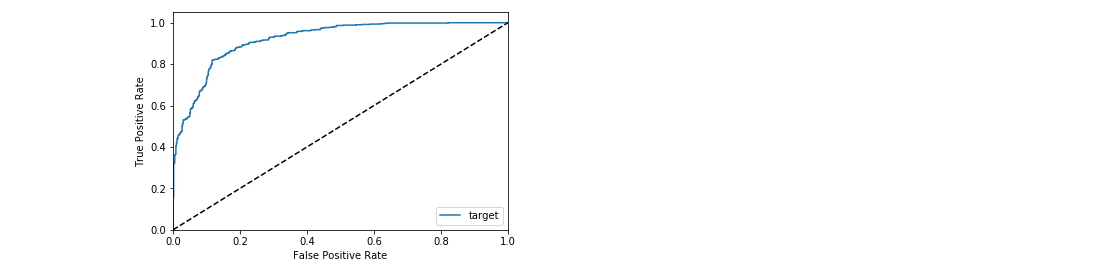
protected = [ "gender" , "ethnicity" , "age" ]
_ = [ xai . roc_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ p ],
categorical_cols = categorical_cols ) for p in protected ]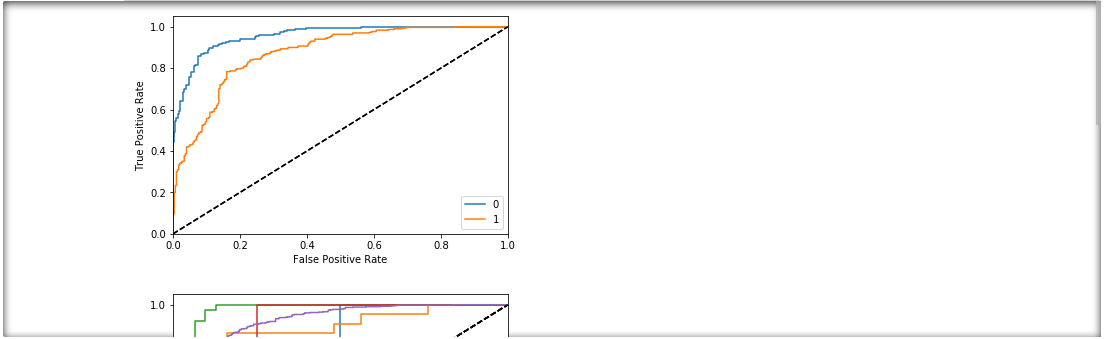
d = xai . smile_imbalance (
y_test ,
probabilities )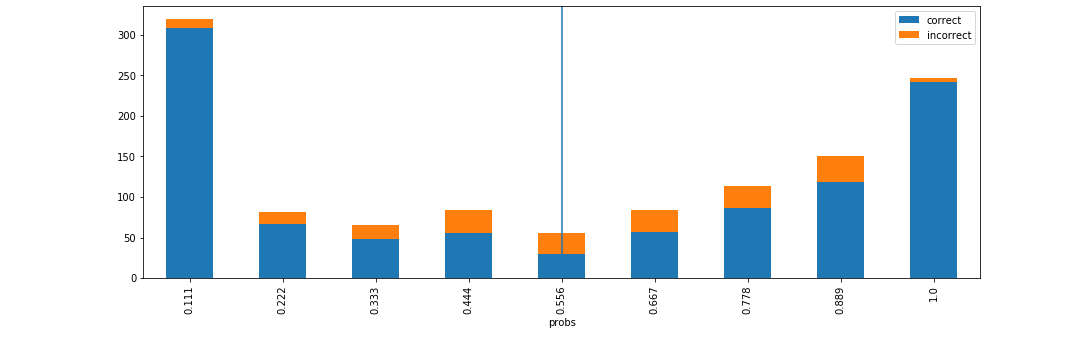
d = xai . smile_imbalance (
y_test ,
probabilities ,
display_breakdown = True )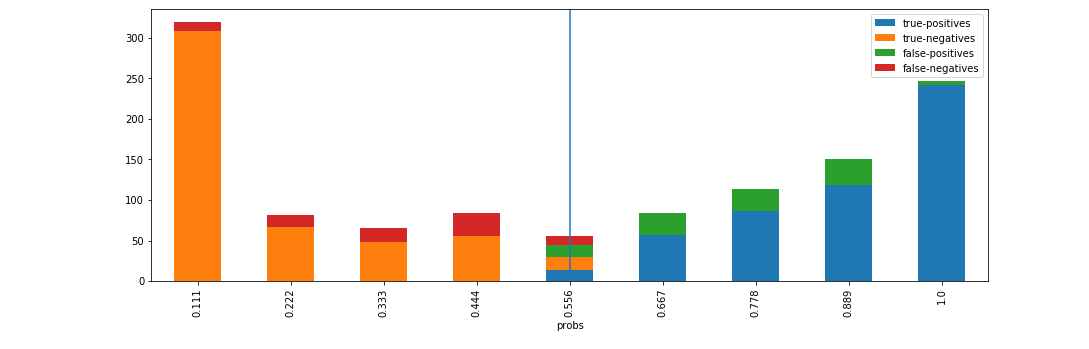
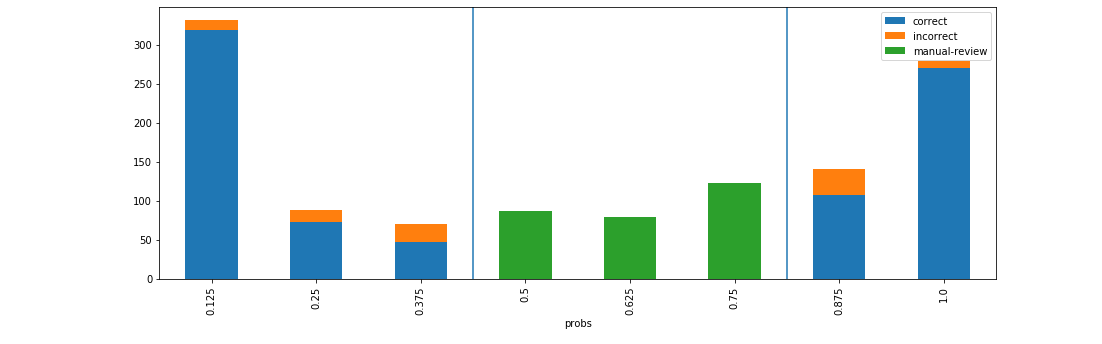
d = xai . smile_imbalance (
y_test ,
probabilities ,
bins = 9 ,
threshold = 0.75 ,
manual_review = 0.375 ,
display_breakdown = False )