xai
v0.1.0
XAI ist eine Bibliothek für maschinelles Lernen, die mit KI -Erklärung in seinem Kern entworfen wurde. XAI enthält verschiedene Tools, die für die Analyse und Bewertung von Daten und Modellen ermöglicht werden. Die XAI -Bibliothek wird vom Institute for Ethical AI & ML gepflegt und wurde auf der Grundlage der 8 Grundsätze für verantwortungsbewusstes maschinelles Lernen entwickelt.
Die Dokumentation finden Sie unter https://ethicalml.github.io/xai/index.html. Sie können auch unseren Vortrag bei TensorFlow London überprüfen, wo die Idee zum ersten Mal konzipiert wurde - das Vortrag enthält auch einen Einblick in die Definitionen und Prinzipien in dieser Bibliothek.
| Dieses Video des Vortrags auf der Pydata London 2019 -Konferenz, das einen Überblick über die Motivationen für die Erklärung des maschinellen Lernens sowie Techniken zur Einführung von Erklärung und Minderung unerwünschter Verzerrungen mithilfe der XAI -Bibliothek bietet. |  |
| Möchten Sie mehr fantastische Erklärbarkeitstools für maschinelles Lernen kennenlernen? Schauen Sie sich unsere Community-Liste "Awesome Machine Learning Production & Operations" an, die eine umfangreiche Liste von Tools für Erklärung, Privatsphäre, Orchestrierung und darüber hinaus enthält. |  |
Wenn Sie eine voll funktionsfähige Demo in Aktion sehen möchten, klonen Sie dieses Repo und führen Sie das Beispiel -Jupyter -Notizbuch im Beispiele -Ordner aus.
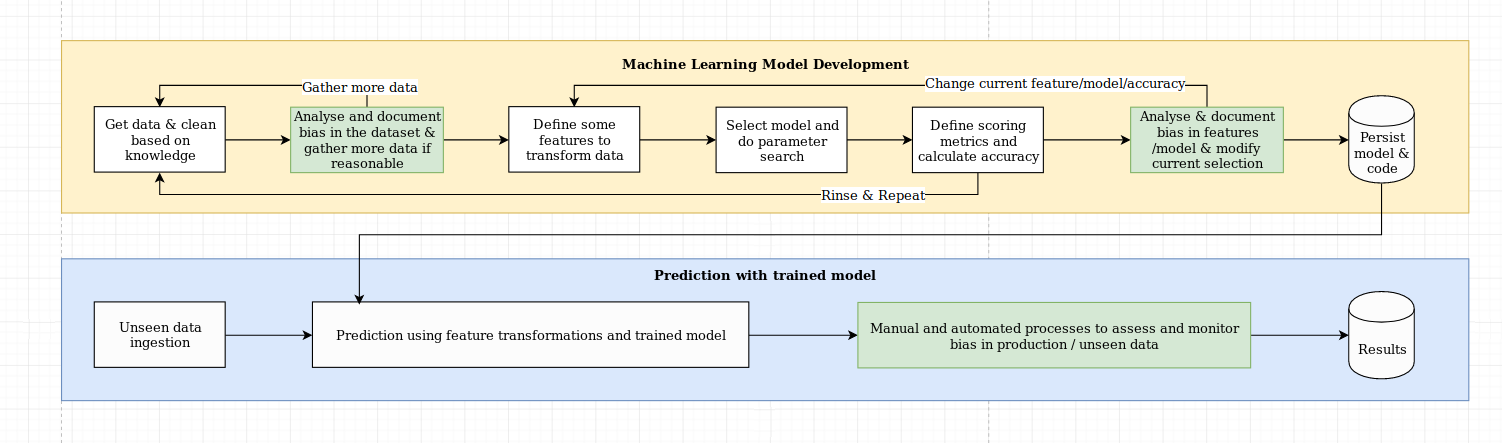
Wir sehen die Herausforderung der Erklärung als mehr als nur eine algorithmische Herausforderung an, die eine Kombination aus Best Practices mit domänenspezifischem Wissen erfordert. Die XAI-Bibliothek soll maschinelles Lernen und relevante Domänenexperten befähigen, die End-to-End-Lösung zu analysieren und Diskrepanzen zu identifizieren, die zu einer suboptimalen Leistung im Vergleich zu den erforderlichen Zielen führen können. Im weiteren Sinne wurde die XAI-Bibliothek unter Verwendung der 3 Schritte des erklärbaren maschinellen Lernens entwickelt, die 1) Datenanalyse, 2) Modellbewertung und 3) Produktionsüberwachung umfassen.
Wir geben einen visuellen Überblick über diese drei oben genannten Schritte in diesem Diagramm:
Das XAI -Paket ist auf PYPI. Zum Installieren können Sie ausführen:
pip install xai
Alternativ können Sie aus der Quelle installieren, indem Sie das Repo klonen und ausführen:
python setup.py install
Sie können die Beispielverwendung im Beispiel -Ordner finden.
Mit XAI können Sie Ungleichgewichte in den Daten identifizieren. Dafür laden wir den Volkszählungsdatensatz aus der XAI -Bibliothek.
import xai . data
df = xai . data . load_census ()
df . head ()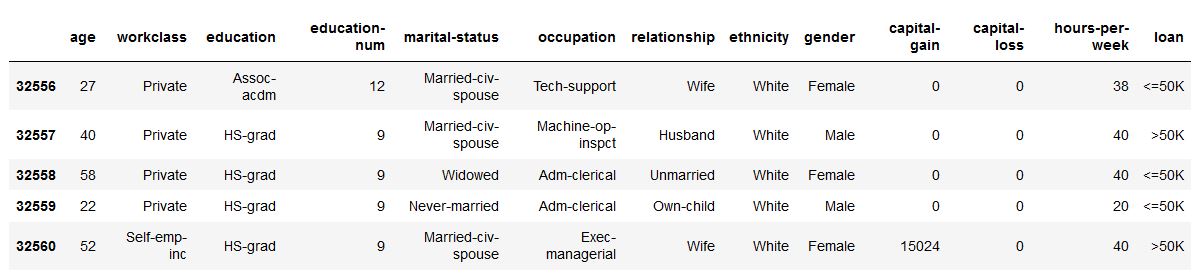
ims = xai . imbalance_plot ( df , "gender" )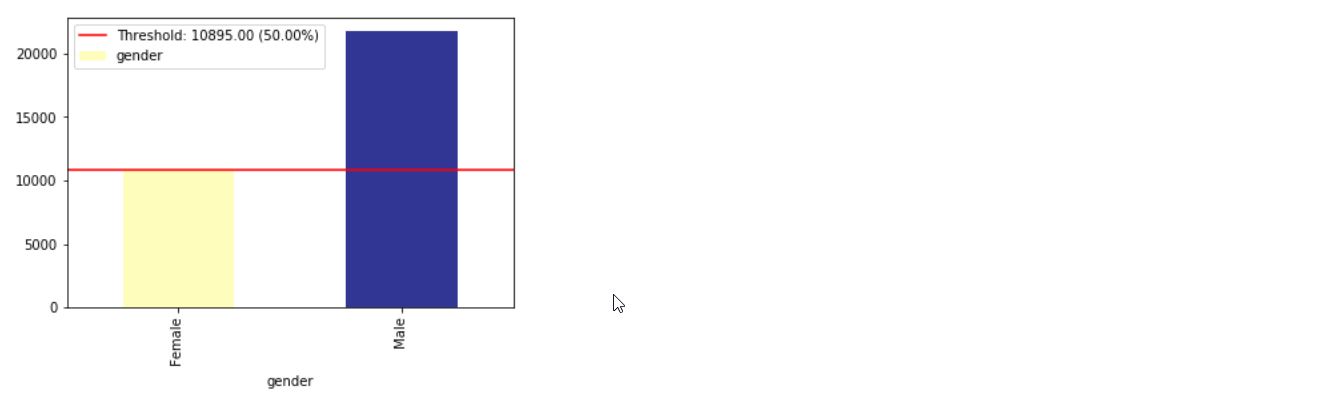
im = xai . imbalance_plot ( df , "gender" , "loan" )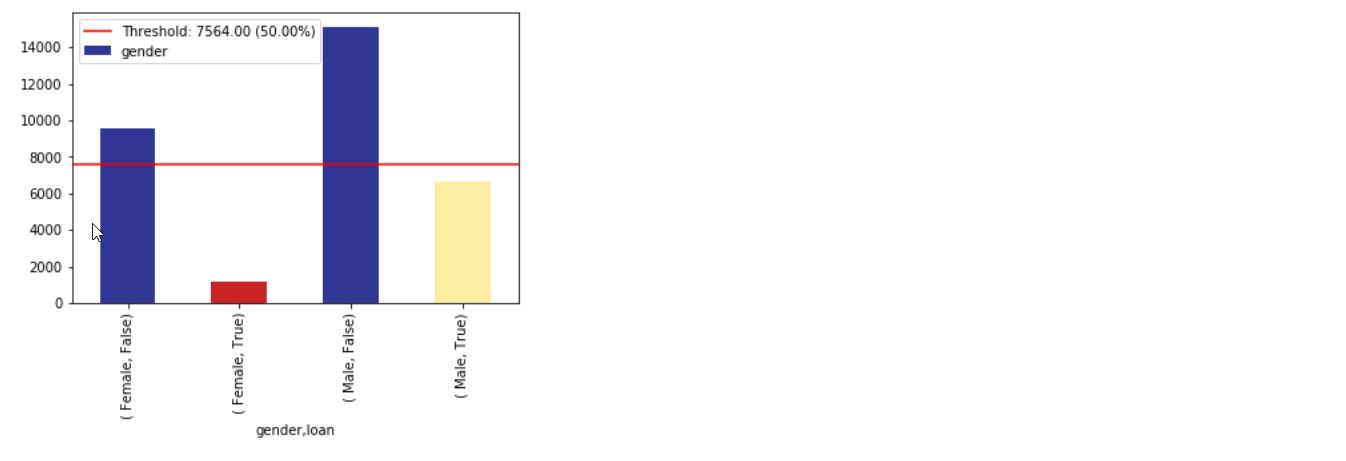
bal_df = xai . balance ( df , "gender" , "loan" , upsample = 0.8 )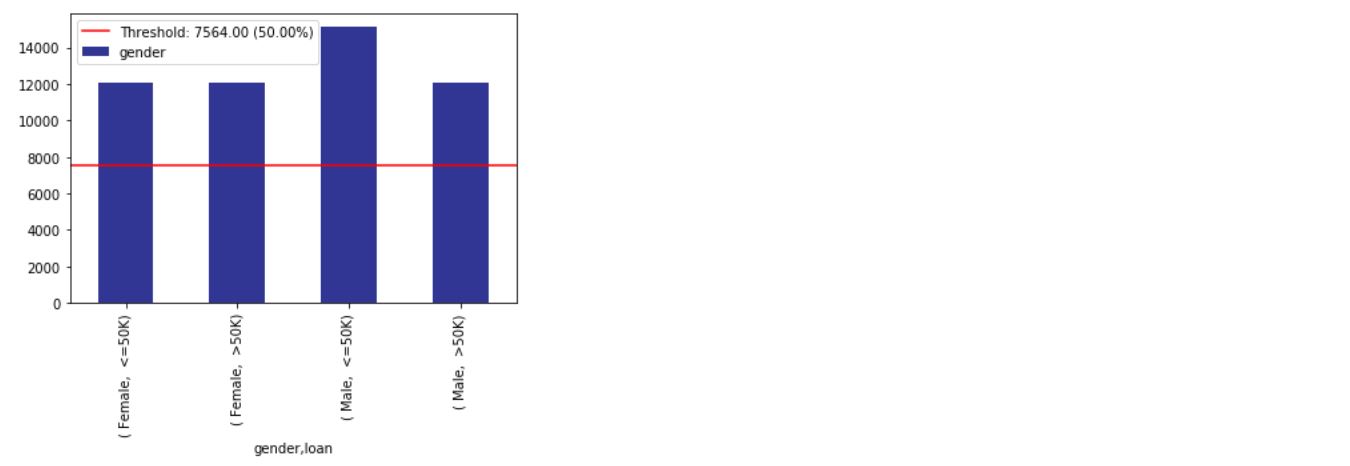
groups = xai . group_by_columns ( df , [ "gender" , "loan" ])
for group , group_df in groups :
print ( group )
print ( group_df [ "loan" ]. head (), " n " )
_ = xai . correlations ( df , include_categorical = True , plot_type = "matrix" )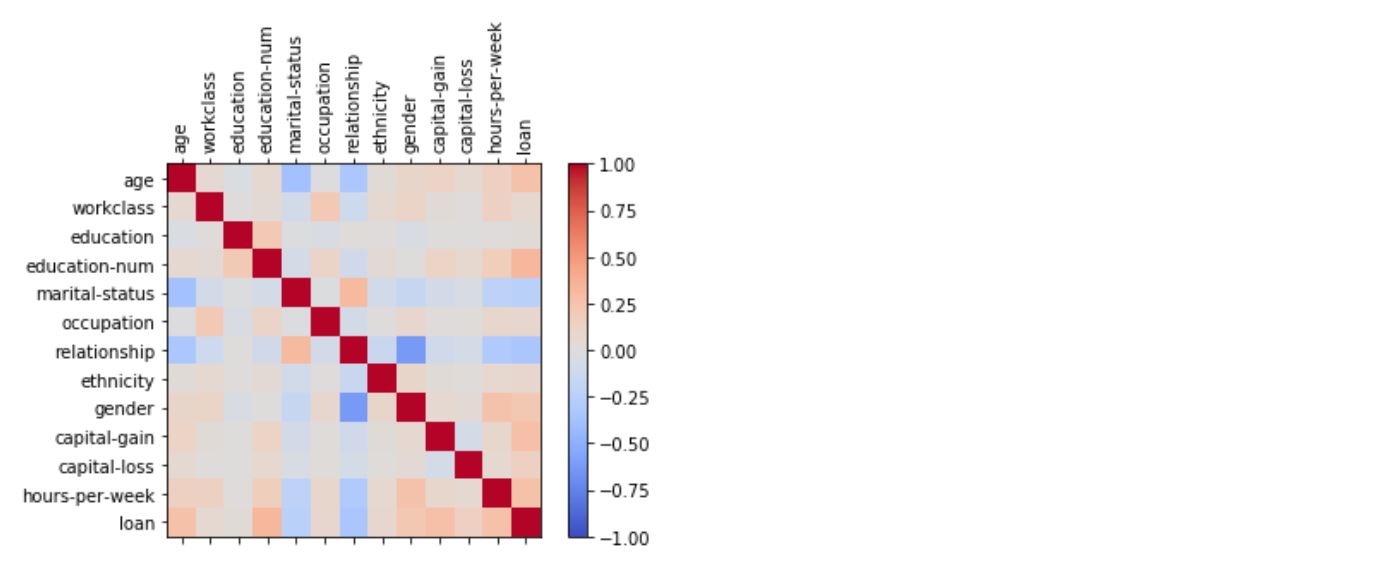
_ = xai . correlations ( df , include_categorical = True )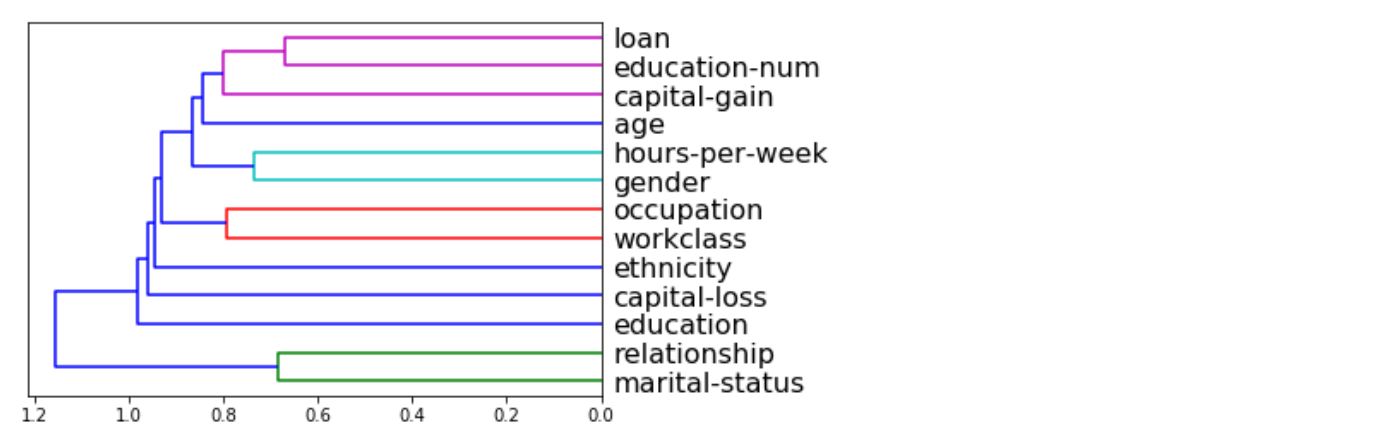
# Balanced train-test split with minimum 300 examples of
# the cross of the target y and the column gender
x_train , y_train , x_test , y_test , train_idx , test_idx =
xai . balanced_train_test_split (
x , y , "gender" ,
min_per_group = 300 ,
max_per_group = 300 ,
categorical_cols = categorical_cols )
x_train_display = bal_df [ train_idx ]
x_test_display = bal_df [ test_idx ]
print ( "Total number of examples: " , x_test . shape [ 0 ])
df_test = x_test_display . copy ()
df_test [ "loan" ] = y_test
_ = xai . imbalance_plot ( df_test , "gender" , "loan" , categorical_cols = categorical_cols )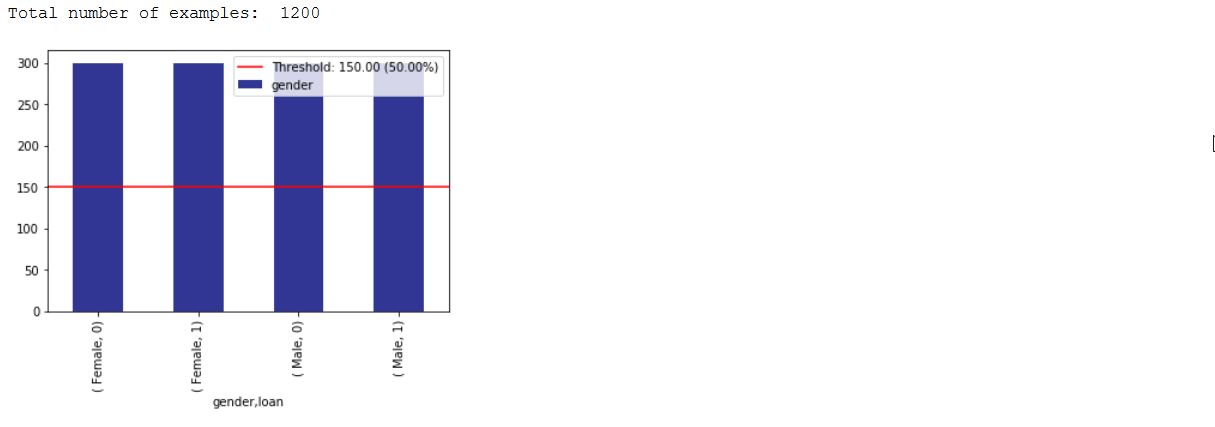
Wir können auch die Wechselwirkung zwischen Inferenzergebnissen und Eingabefunktionen analysieren. Dafür trainieren wir ein einzelnes Deep -Learning -Modell.
model = build_model(proc_df.drop("loan", axis=1))
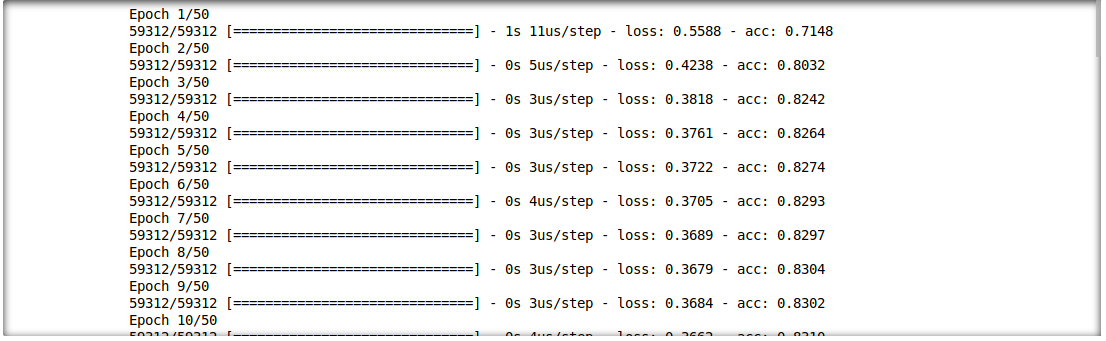
model.fit(f_in(x_train), y_train, epochs=50, batch_size=512)
probabilities = model.predict(f_in(x_test))
predictions = list((probabilities >= 0.5).astype(int).T[0])
def get_avg ( x , y ):
return model . evaluate ( f_in ( x ), y , verbose = 0 )[ 1 ]
imp = xai . feature_importance ( x_test , y_test , get_avg )
imp . head ()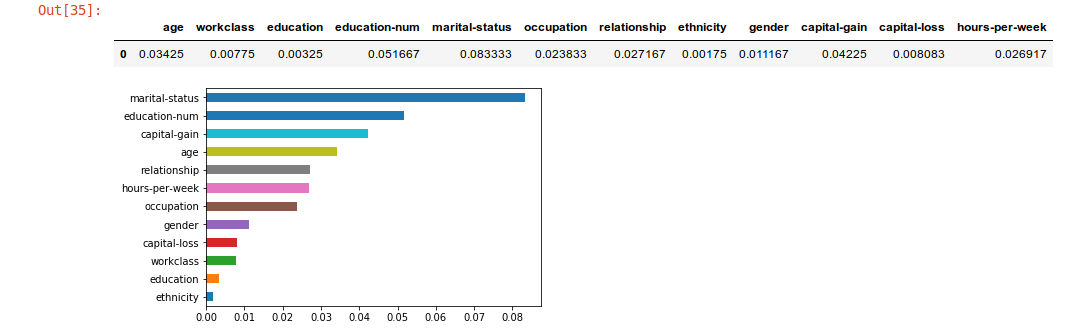
_ = xai . metrics_plot (
y_test ,
probabilities )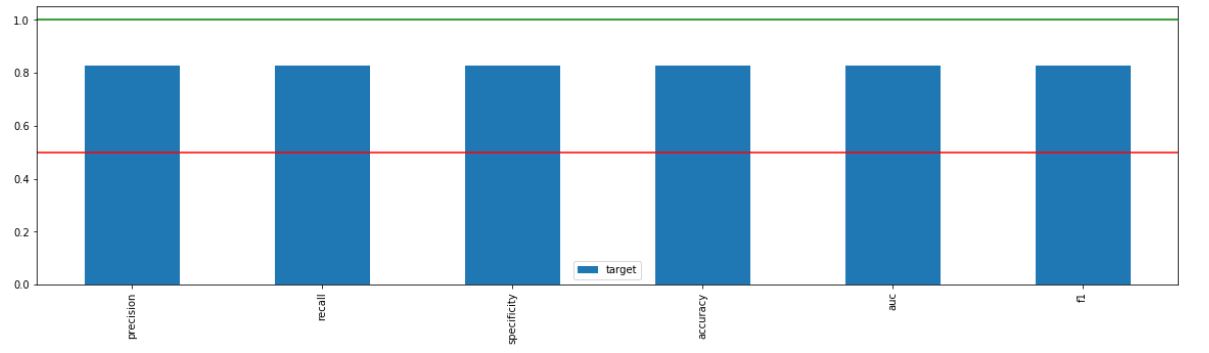
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" ],
categorical_cols = categorical_cols )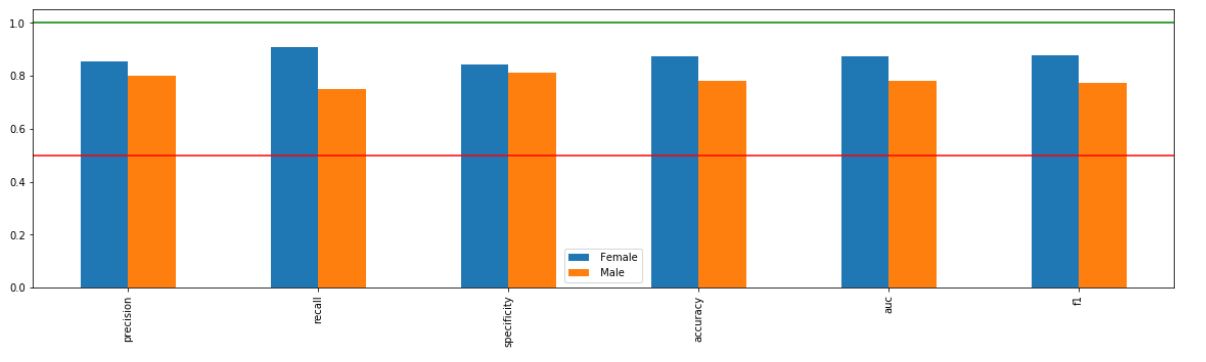
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" , "ethnicity" ],
categorical_cols = categorical_cols )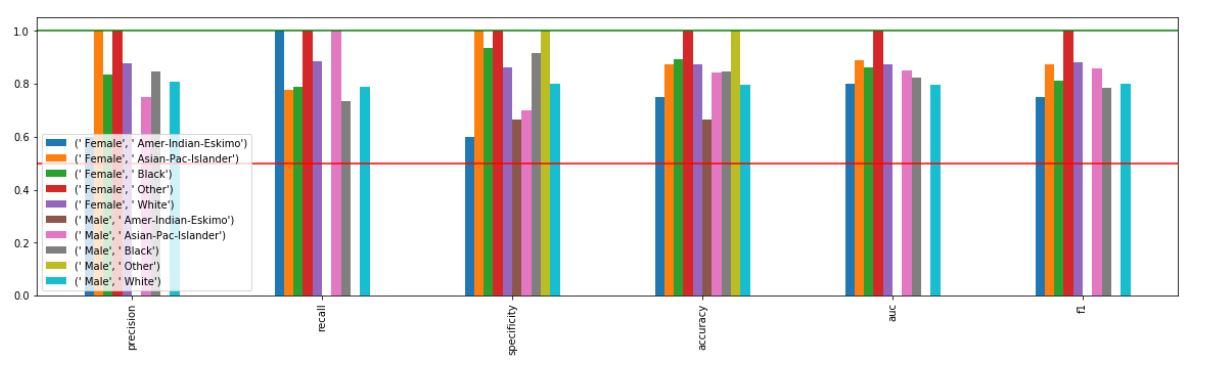
xai . confusion_matrix_plot ( y_test , pred )
_ = xai . roc_plot ( y_test , probabilities )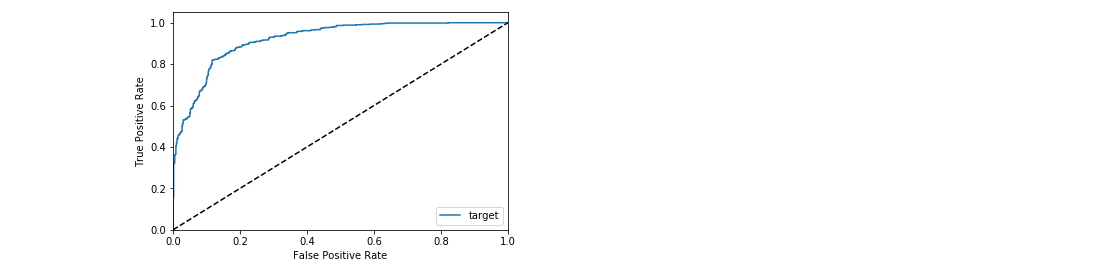
protected = [ "gender" , "ethnicity" , "age" ]
_ = [ xai . roc_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ p ],
categorical_cols = categorical_cols ) for p in protected ]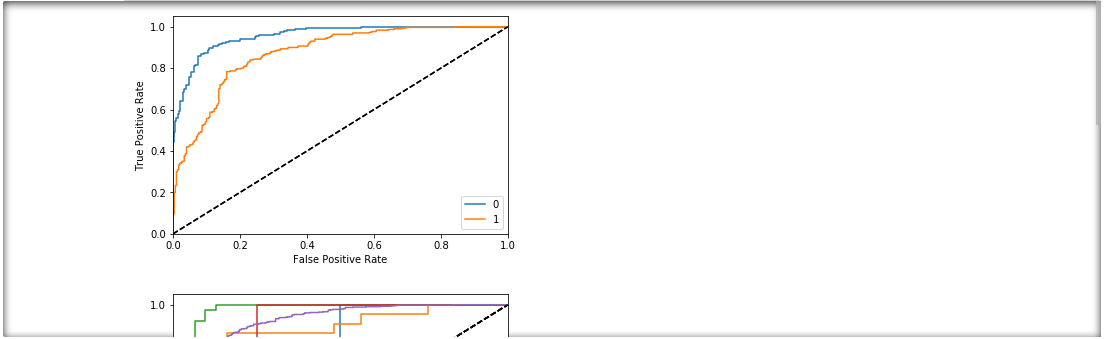
d = xai . smile_imbalance (
y_test ,
probabilities )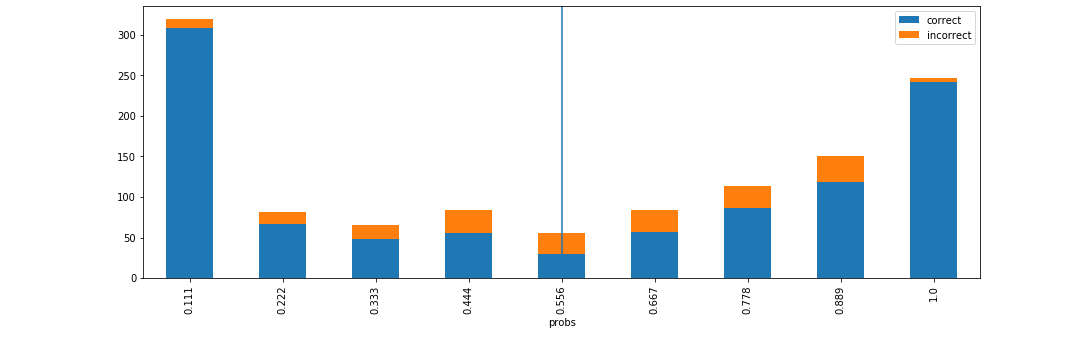
d = xai . smile_imbalance (
y_test ,
probabilities ,
display_breakdown = True )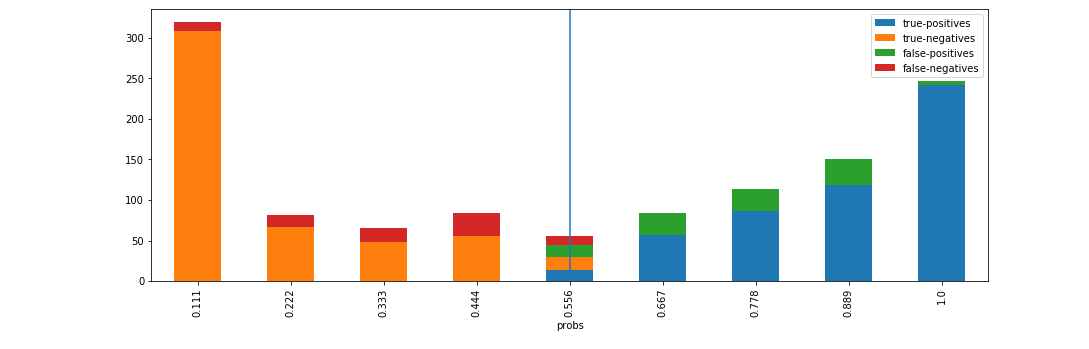
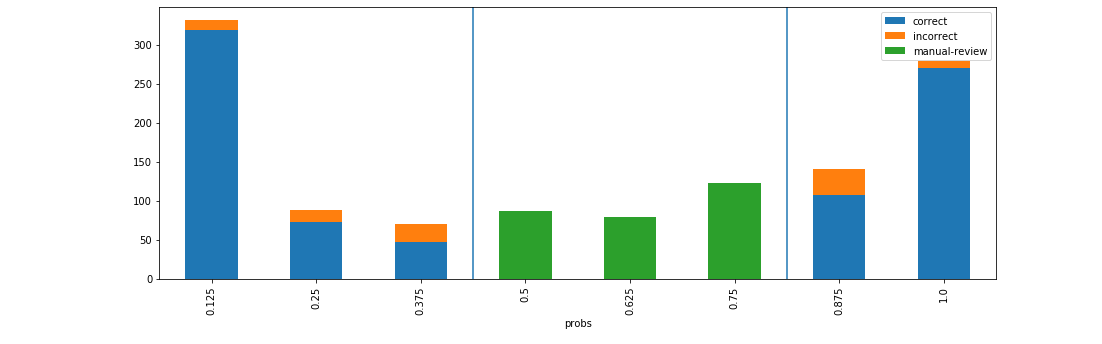
d = xai . smile_imbalance (
y_test ,
probabilities ,
bins = 9 ,
threshold = 0.75 ,
manual_review = 0.375 ,
display_breakdown = False )