xai
v0.1.0
XAI هي مكتبة تعلم الآلة تم تصميمها مع توضيح الذكاء الاصطناعي في جوهرها. يحتوي XAI على أدوات مختلفة تتيح لتحليل وتقييم البيانات والنماذج. يتم الحفاظ على مكتبة XAI من قبل معهد AI & ML الأخلاقي ، وتم تطويره بناءً على مبادئ التعلم الآلي المسؤول 8.
يمكنك العثور على الوثائق في https://ethicalml.github.io/xai/index.html. يمكنك أيضًا الاطلاع على حديثنا في TensorFlow London حيث تم تصور الفكرة لأول مرة - يحتوي الحديث أيضًا على نظرة ثاقبة على التعاريف والمبادئ في هذه المكتبة.
| هذا الفيديو للمتحدث المقدم في مؤتمر Pydata London 2019 الذي يوفر نظرة عامة على دوافع التعلم الآلي ، بالإضافة إلى تقنيات لتقديم قابلية التوضيح والتخفيف من التحيزات غير المرغوب فيها باستخدام مكتبة XAI. |  |
| هل تريد التعرف على المزيد من أدوات توضيح التعلم الآلي؟ تحقق من قائمة "إنتاج وعمليات التعلم الآلي الرائع" الذي يحتوي على قائمة واسعة من الأدوات للشرح والخصوصية والأداء وما بعده. |  |
إذا كنت ترغب في رؤية عرض تجريبي يعمل بكامل طاقته في عملية استنساخ هذا الريبو وقم بتشغيل مثال Jupyter Notebook في مجلد الأمثلة.
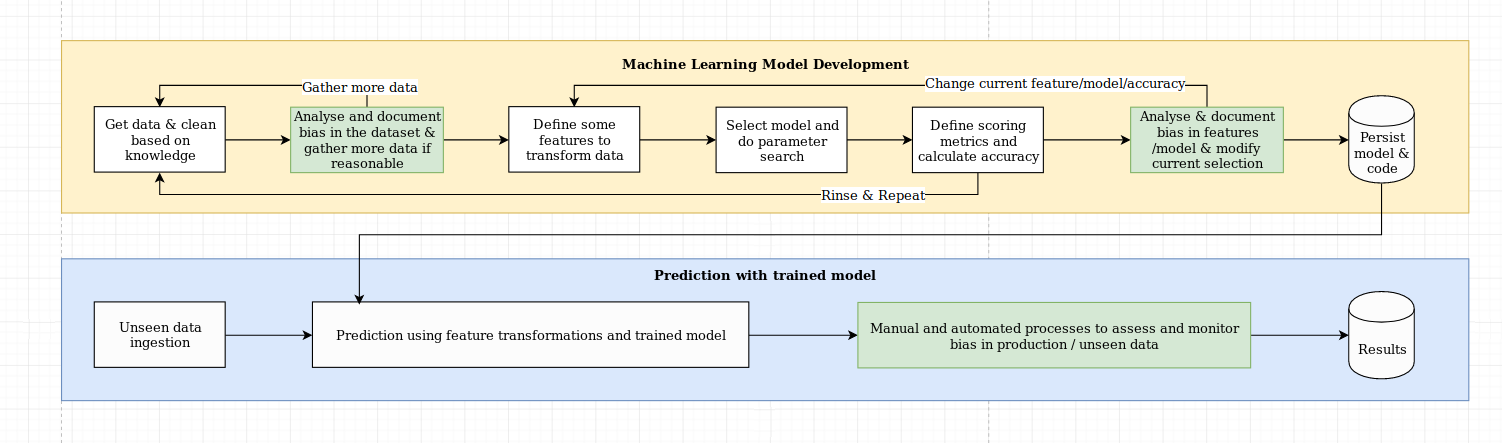
نرى التحدي المتمثل في التوضيح أكثر من مجرد تحدٍ خوارزمي ، والذي يتطلب مزيجًا من أفضل ممارسات علوم البيانات ذات المعرفة الخاصة بالمجال. تم تصميم مكتبة XAI لتمكين مهندسي التعلم الآلي وخبراء المجالين ذوي الصلة من تحليل الحل الشامل وتحديد التناقضات التي قد تؤدي إلى أداء دون المستوى الأمثل بالنسبة للأهداف المطلوبة. على نطاق أوسع ، تم تصميم مكتبة XAI باستخدام 3 خطوات للتعلم الآلي القابل للشرح ، والتي تتضمن 1) تحليل البيانات ، 2) تقييم النموذج ، و 3) مراقبة الإنتاج.
نحن نقدم نظرة عامة مرئية على هذه الخطوات الثلاث المذكورة أعلاه في هذا المخطط:
حزمة XAI على PYPI. للتثبيت ، يمكنك تشغيل:
pip install xai
بدلاً من ذلك ، يمكنك التثبيت من المصدر عن طريق استنساخ الريبو والتشغيل:
python setup.py install
يمكنك العثور على مثال الاستخدام في مجلد الأمثلة.
مع XAI ، يمكنك تحديد الاختلالات في البيانات. لهذا ، سنقوم بتحميل مجموعة بيانات التعداد من مكتبة XAI.
import xai . data
df = xai . data . load_census ()
df . head ()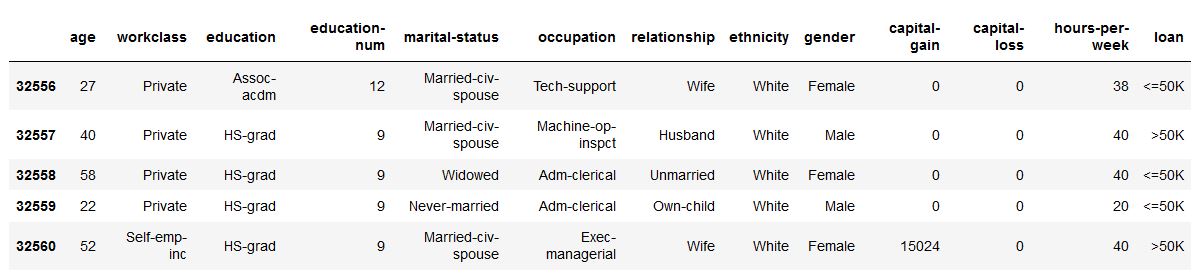
ims = xai . imbalance_plot ( df , "gender" )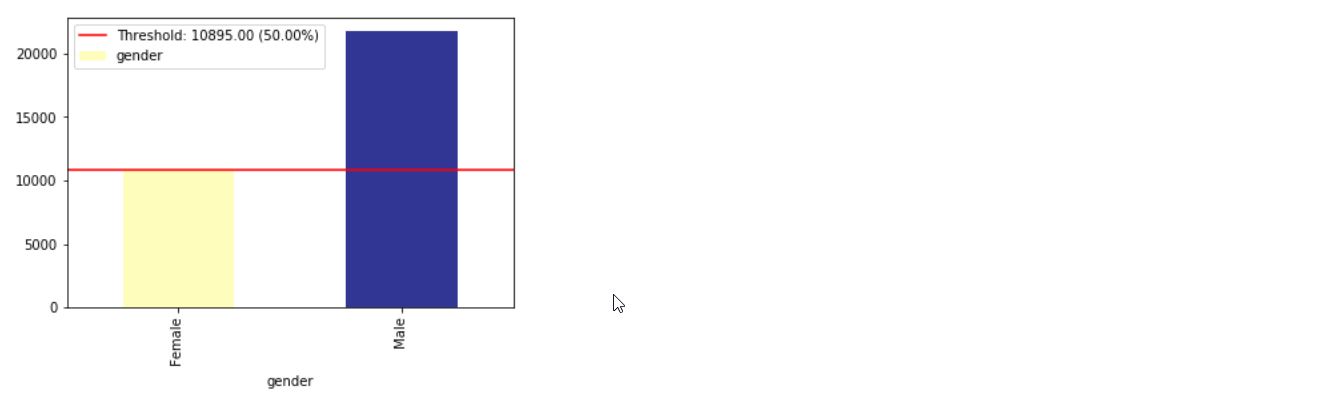
im = xai . imbalance_plot ( df , "gender" , "loan" )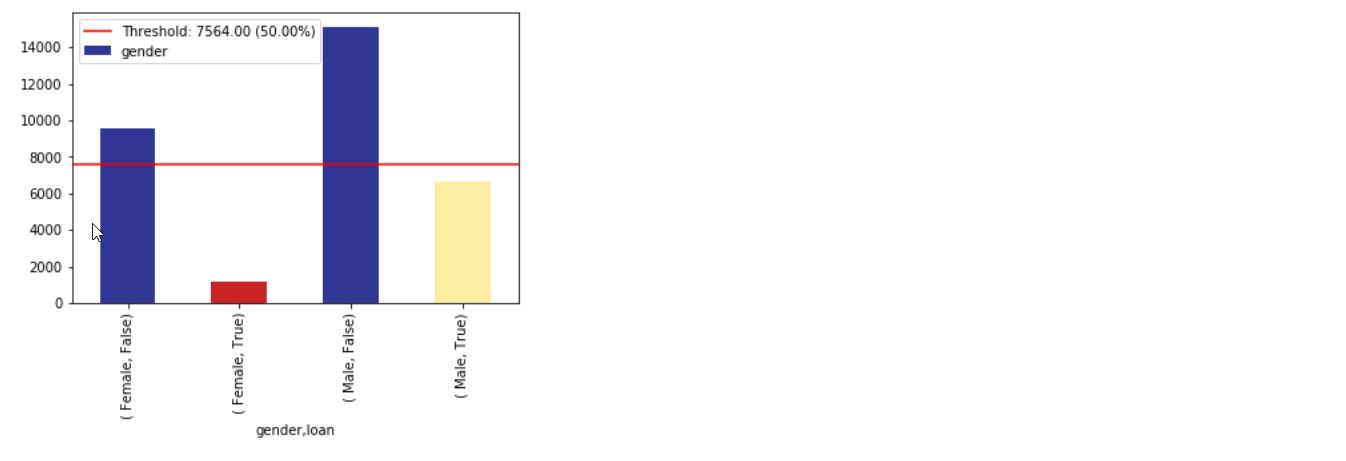
bal_df = xai . balance ( df , "gender" , "loan" , upsample = 0.8 )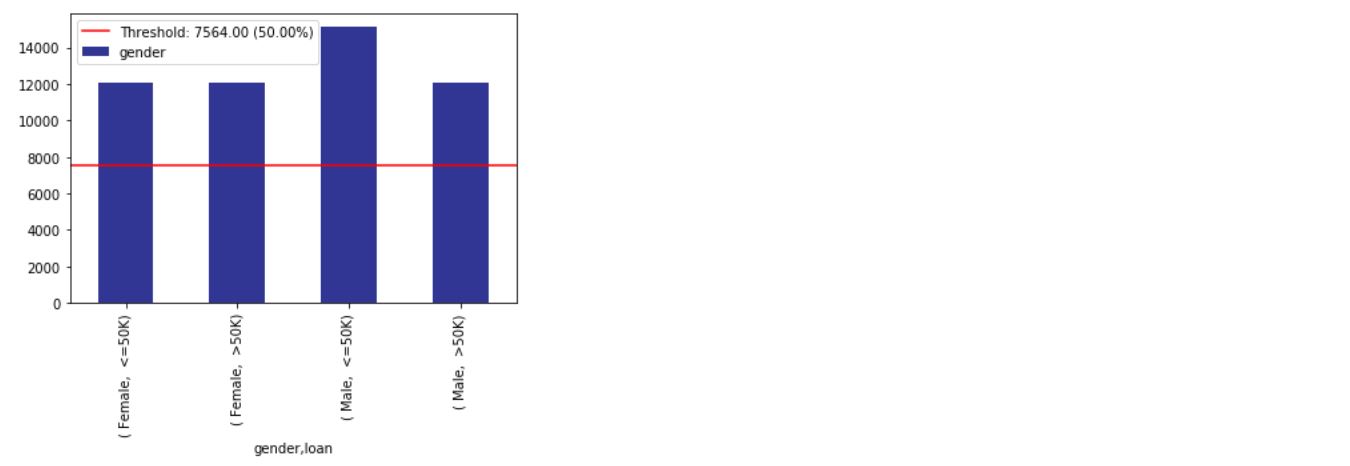
groups = xai . group_by_columns ( df , [ "gender" , "loan" ])
for group , group_df in groups :
print ( group )
print ( group_df [ "loan" ]. head (), " n " )
_ = xai . correlations ( df , include_categorical = True , plot_type = "matrix" )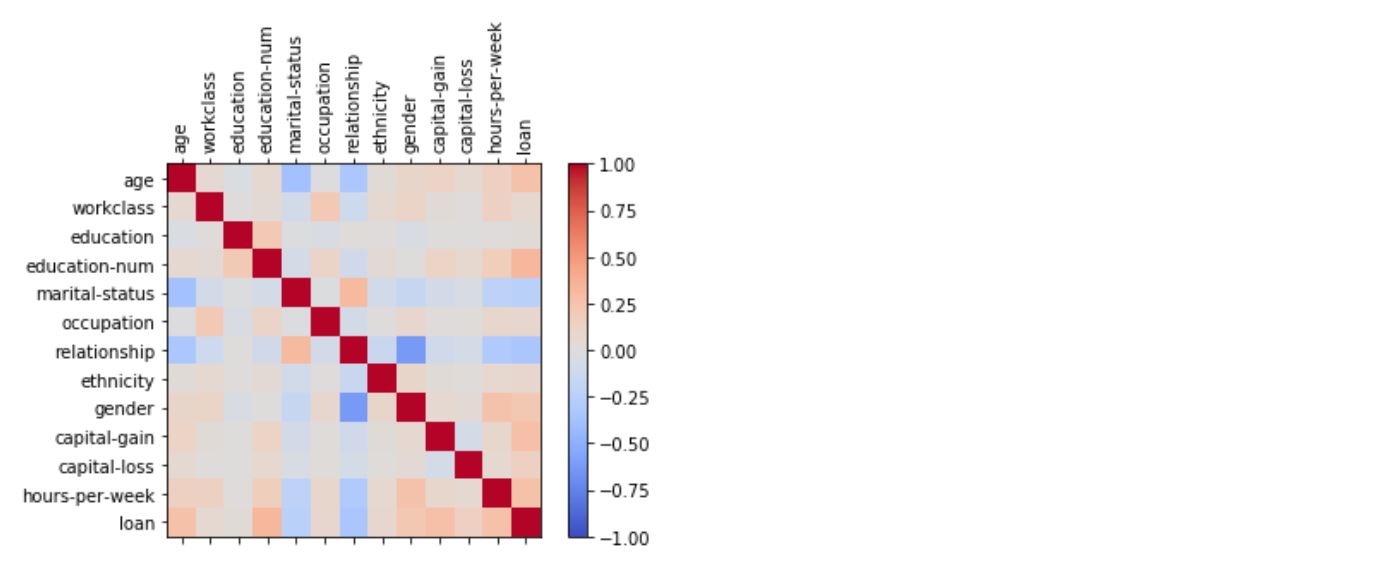
_ = xai . correlations ( df , include_categorical = True )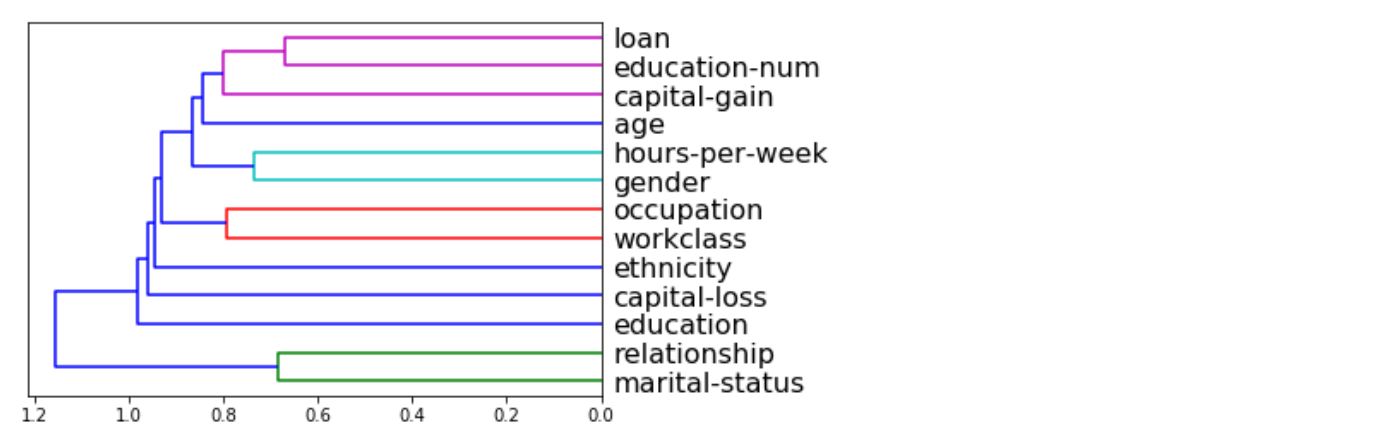
# Balanced train-test split with minimum 300 examples of
# the cross of the target y and the column gender
x_train , y_train , x_test , y_test , train_idx , test_idx =
xai . balanced_train_test_split (
x , y , "gender" ,
min_per_group = 300 ,
max_per_group = 300 ,
categorical_cols = categorical_cols )
x_train_display = bal_df [ train_idx ]
x_test_display = bal_df [ test_idx ]
print ( "Total number of examples: " , x_test . shape [ 0 ])
df_test = x_test_display . copy ()
df_test [ "loan" ] = y_test
_ = xai . imbalance_plot ( df_test , "gender" , "loan" , categorical_cols = categorical_cols )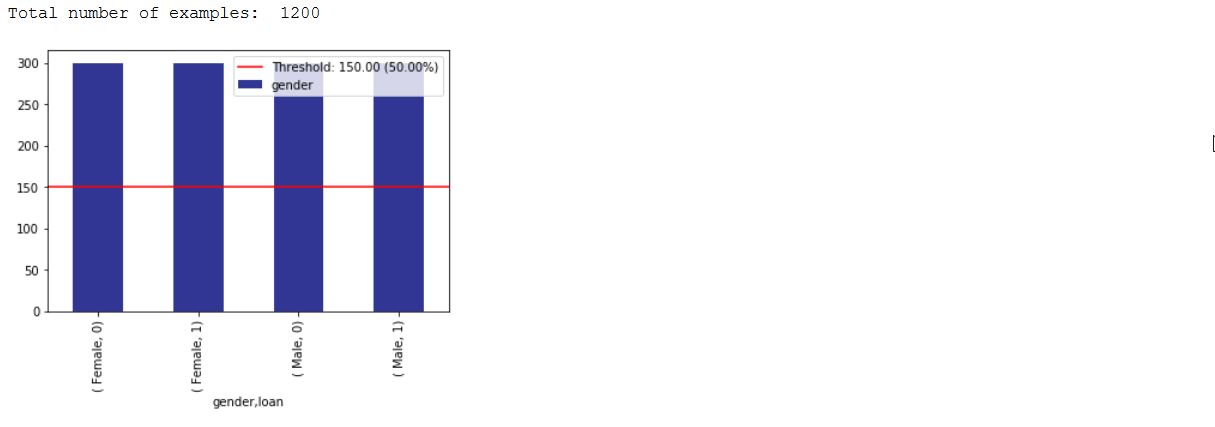
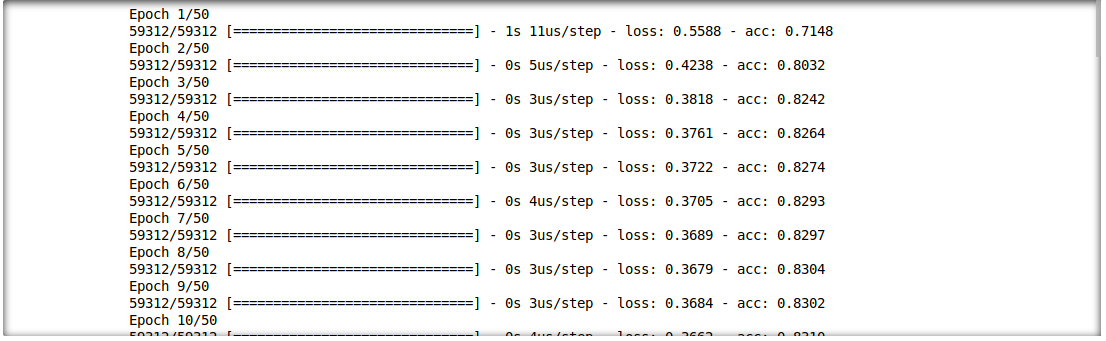
نحن قادرون أيضًا على تحليل التفاعل بين نتائج الاستدلال وميزات الإدخال. لهذا ، سنقوم بتدريب نموذج التعلم العميق طبقة واحدة.
model = build_model(proc_df.drop("loan", axis=1))
model.fit(f_in(x_train), y_train, epochs=50, batch_size=512)
probabilities = model.predict(f_in(x_test))
predictions = list((probabilities >= 0.5).astype(int).T[0])
def get_avg ( x , y ):
return model . evaluate ( f_in ( x ), y , verbose = 0 )[ 1 ]
imp = xai . feature_importance ( x_test , y_test , get_avg )
imp . head ()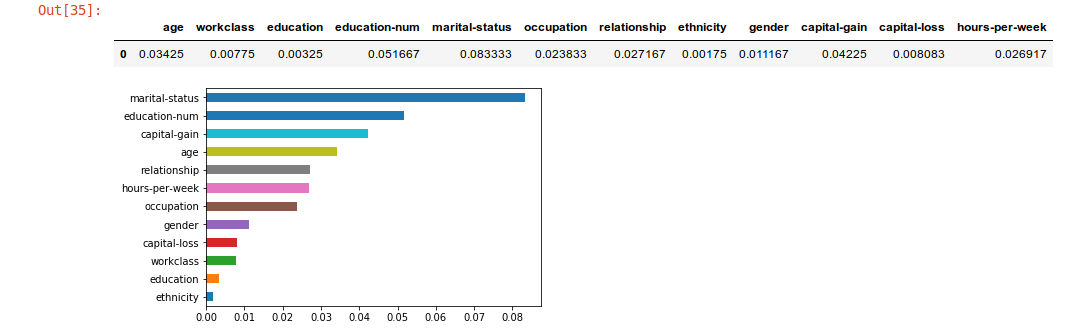
_ = xai . metrics_plot (
y_test ,
probabilities )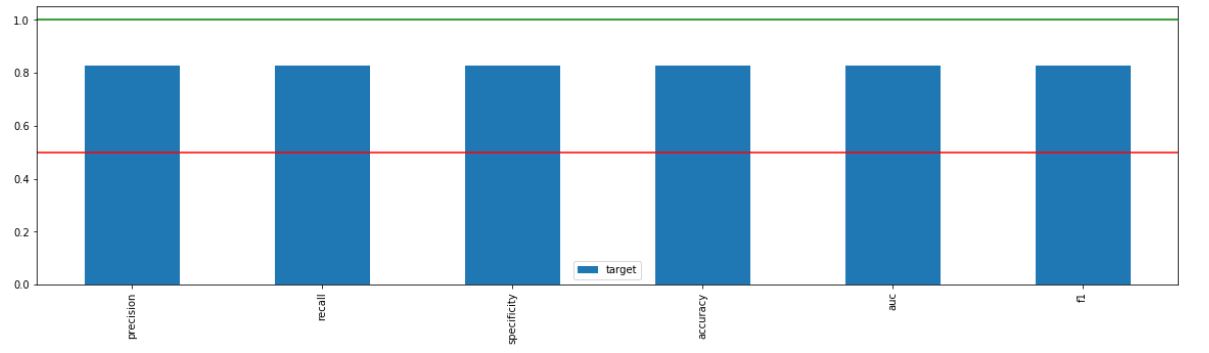
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" ],
categorical_cols = categorical_cols )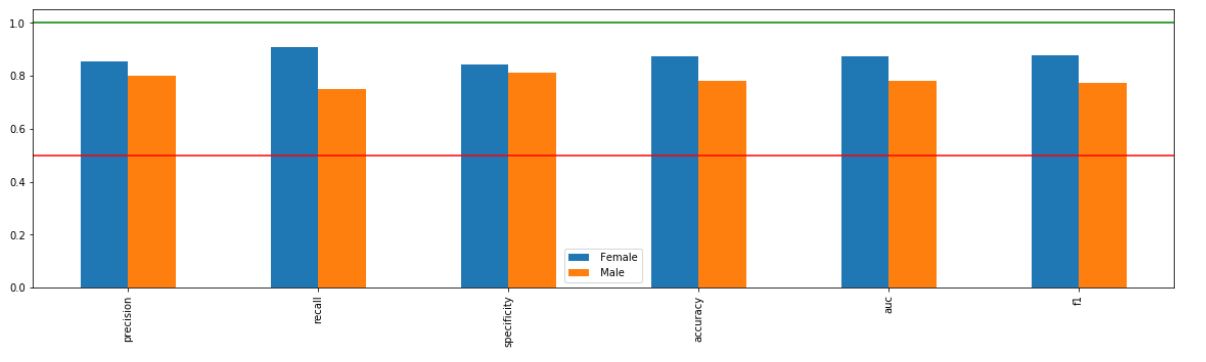
_ = xai . metrics_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ "gender" , "ethnicity" ],
categorical_cols = categorical_cols )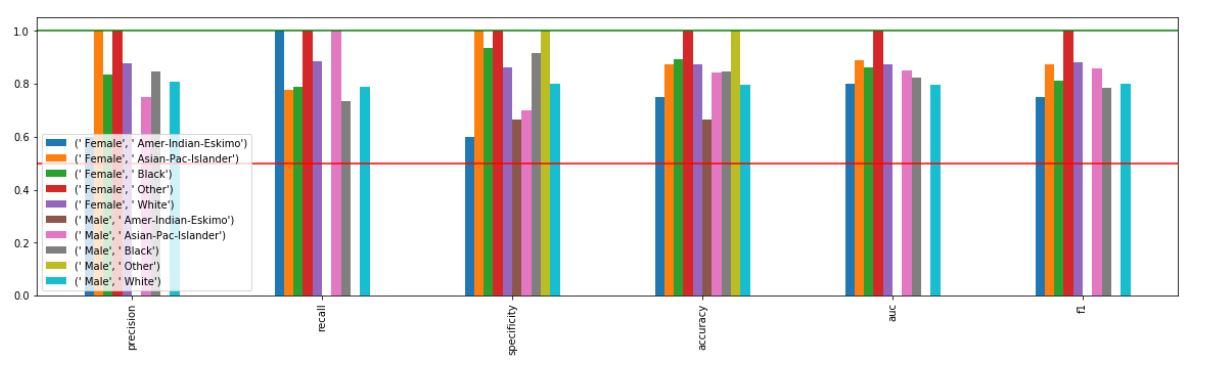
xai . confusion_matrix_plot ( y_test , pred )
_ = xai . roc_plot ( y_test , probabilities )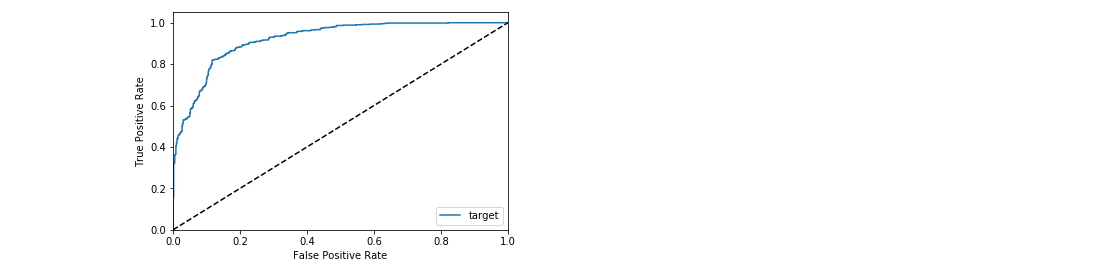
protected = [ "gender" , "ethnicity" , "age" ]
_ = [ xai . roc_plot (
y_test ,
probabilities ,
df = x_test_display ,
cross_cols = [ p ],
categorical_cols = categorical_cols ) for p in protected ]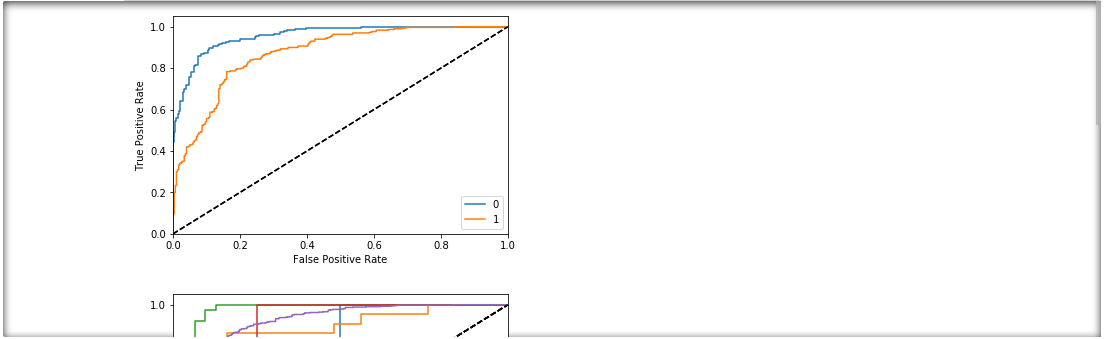
d = xai . smile_imbalance (
y_test ,
probabilities )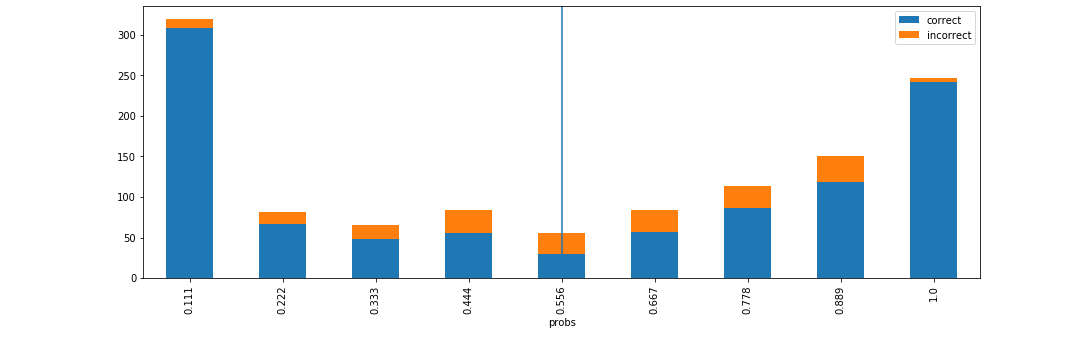
d = xai . smile_imbalance (
y_test ,
probabilities ,
display_breakdown = True )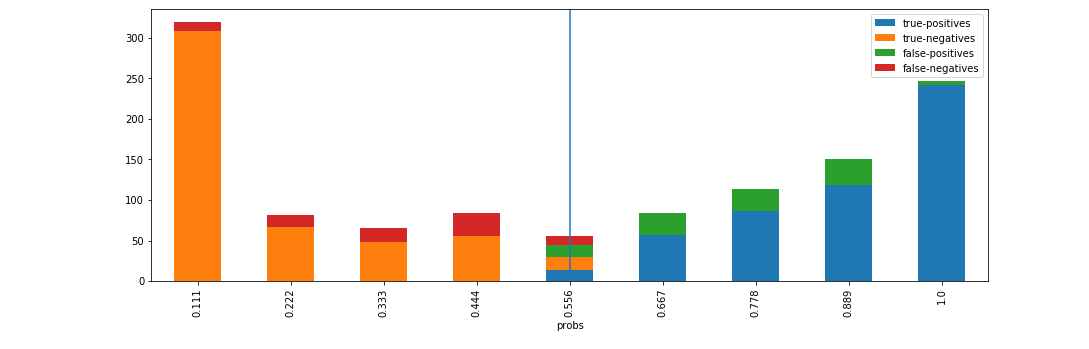
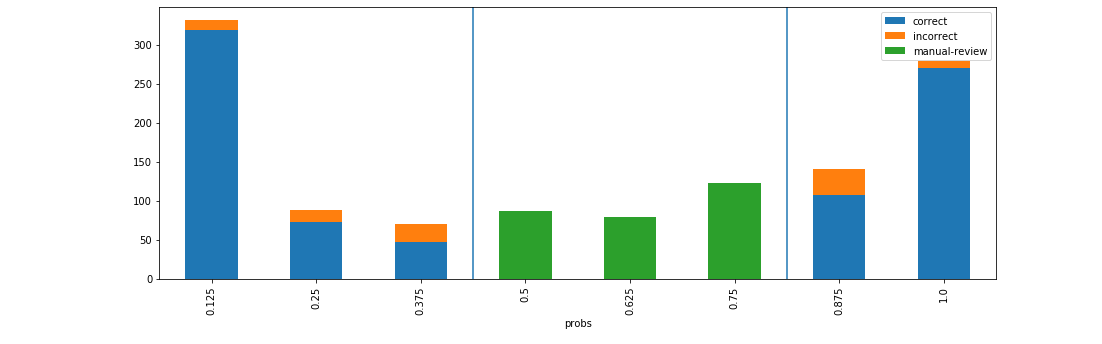
d = xai . smile_imbalance (
y_test ,
probabilities ,
bins = 9 ,
threshold = 0.75 ,
manual_review = 0.375 ,
display_breakdown = False )