大型语言模型(LLM)的评估一直是自然语言处理领域的关键挑战。传统的人工评估方法费时费力,难以应对LLM快速发展的步伐。为此,Salesforce AI研究团队开发了SFR-Judge,一个由三个不同规模的LLM组成的评估家族,旨在提供更快速、更高效的自动化评估解决方案。 Downcodes小编将带你深入了解SFR-Judge的创新之处以及它如何解决LLM评估中的难题。
在自然语言处理领域,大型语言模型(LLMs)的发展迅速,已经在多个领域取得了显着的进展。不过,随着模型的复杂性增加,如何准确评估它们的输出就变得至关重要。传统上,我们依赖人类来进行评估,但这种方式既耗时又难以规模化,无法跟上模型快速发展的步伐。
为了改变这种现状,Salesforce AI 研究团队推出了SFR-Judge,这是一个由三个大型语言模型组成的评估家族。这些模型分别拥有80亿、120亿和700亿个参数,基于Meta Llama3和Mistral NeMO 构建。 SFR-Judge 能够执行多种评估任务,包括成对比较、单一评分和二分类评估,旨在帮助研究团队快速高效地评估新模型的表现。
传统的LLM 评估模型往往存在一些偏差问题,比如位置偏差和长度偏差,这会影响它们的判断。为了克服这些问题,SFR-Judge 采用了直接偏好优化(DPO)训练方法,让模型从正负例中学习,从而提升其评估任务的理解能力,减少偏差,确保判断的一致性。
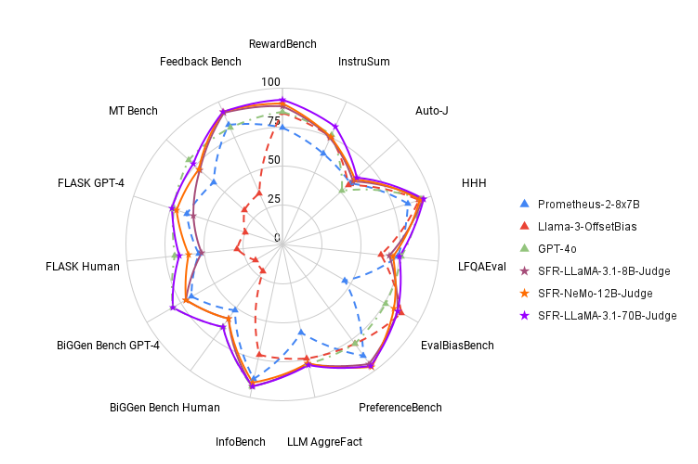
在测试中,SFR-Judge 在13个基准测试上表现优异,超过了许多现有的评估模型,包括一些私有模型。特别是在RewardBench 排行榜上,SFR-Judge 的准确率达到了92.7%,这是生成型评估模型首次和第二次超越90% 的门槛,展现出其在评估模型中的卓越表现。
SFR-Judge 的训练方法涵盖三种不同的数据格式。首先是“思维链批评”,帮助模型生成对评估响应的结构化分析。其次是“标准评判”,简化评估过程,直接反馈响应是否符合标准。最后,“响应推导” 则帮助模型理解高质量回应的特征,强化其判断能力。这三种数据格式的结合,使得SFR-Judge 的评估能力得到了极大提升。
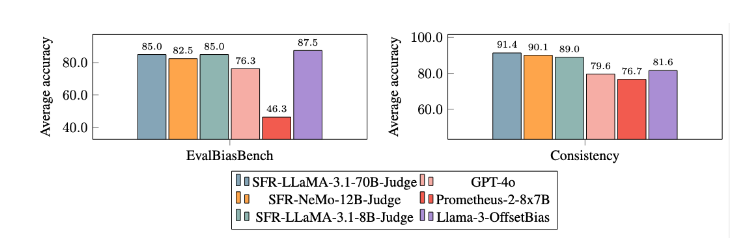
经过大量实验,SFR-Judge 模型在减少偏差方面表现显着优于其他模型。在EvalBiasBench 基准测试中,它们展现了高度的成对顺序一致性,这表明即便响应顺序发生变化,模型的判断依然保持稳定。这使得SFR-Judge 成为一种可靠的自动化评估解决方案,减少了对人工标注的依赖,为模型评估提供了更可扩展的选择。
论文入口:https://arxiv.org/abs/2409.14664
划重点:
? 高准确率:SFR-Judge 在13个基准测试中取得了10个最佳成绩,尤其是在RewardBench 上达到了92.7% 的高准确率。
偏差缓解:该模型显示出比其他评估模型更低的偏差,特别是在长度和位置偏差方面。
多功能应用:SFR-Judge 支持成对比较、单一评分和二分类评估,能够适应多种评估场景。
SFR-Judge 的出现为大型语言模型的评估带来了新的希望,其高准确率、低偏差和多功能性使其成为一种强大的自动化评估工具。这项研究为LLM领域的发展提供了重要的技术支持,也预示着未来LLM评估将更加高效和可靠。 Downcodes小编期待未来有更多类似的创新成果出现!